
1.环境准备工作
(1)首先需要安装Anaconda,这个网上教程太多了,下载最新版本就行,在这里就不在赘述了。
(2)安装Pytorch
- 首先创建python3.6以上版本的conda环境,在这里我用的是python3.8,环境名称为mypytorch
conda create -n mypytorch python=3.8
- 激活创建好的conda环境
conda activate mypytorch
3.在PyTorch官网上选择指定版本安装Pytorch
Install PyTorch: https://pytorch.org/get-started/locally/ 我在这里安装的是cpu版本,如果安装GPU版网上也有很多详细的教程。
conda install pytorch torchvision torchaudio cpuonly -c pytorch
(3)安装YOLOv5
先在主页面创建一个文件夹名称为catkin_ws作为你的工作空间,在这个文件夹中再创建一个名为src的文件夹。下载YOLOv5安装文件,我将它放在了百度网盘里,
链接:https://pan.baidu.com/s/1FCCz1qs6CcMNQ62Ip5Tj5w?pwd=1234
提取码:1234
下载解压之后放在src文件夹中,在src文件夹中打开终端,执行以下命令。
python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
cd yolov5_ros/yolov5_ros/yolov5
sudo pip install -r requirements.txt
最后执行,安装opencv-python
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成!
注意每次使用YOLOv5都必须执行指令,来进入mytorch环境
conda activate mypytorch
2.第一步如果实在装不好
如果第一步中实在有报错不能解决,我准备了一个已经配置好的YOLOv5环境,放在了百度网盘里,链接如下
链接:https://pan.baidu.com/s/1FNtkV4igI5kco-qQU3g-6w?pwd=1234
提取码:1234
找到你安装anaconda的位置,下载好后把文件解压后放入/anaconda3/envs/文件夹下,然后在此文件夹下打开终端运行以下指令添加到conda环境中
conda config --add envs_dirs 加上下载好的环境文件夹的路径
最后通过指令,来激活conda环境
conda activate mypytorch
3.准备自己的数据集
创建数据集,数据集的文件分级如下所示
文件结构必须是这样的,train放训练集,val放测试集,images放图,labels放标签,数据集文件放哪都无所谓,但是一定要记得路径。
|————dataset
|————train
|————images
|————labels
|————val
|————images
|————labels
接下来我们就要进行图片的标注工作了,我参考了教程:超详细从零开始yolov5模型训练_yolo训练-CSDN博客中的方法。图片标注我们用到了一个名为labelimg的工具:https://github.com/tzutalin/labelImg
大家下载解压之后,首先要做的是删除labelImg-master\data\predefined_classes.txt
文件中的内容,不然等会标记的时候会自动添加一些奇怪的类别。
然后在labelImg-master文件夹下打开终端,进入我们的yolo环境中,然后我们还需要在yolo环境中安装一些labelImg运行需要的依赖,依次输入
conda install pyqt=5
conda install -c anaconda lxml
pyrcc5 -o libs/resources.py resources.qrc
现在,我们已经在yolo环境中安装好labelimg的依赖环境了,输入
python labelImg.py
即可进入我们的界面中来。进入之后,首先我们先把一些选项勾上,便于我们标记。然后,最重要的是把标记模式改为yolo。

之后我们点击打开目录(Open dir)选择我们图片所在的images文件夹,选择之后会弹窗(如果没有弹出就点击改变存放根目录,英文的话叫change save dir)让你选择labels所在的文件夹。当然如果选错了,也可以点存放根目录(change save dir)进行修改。期间容易闪退,可以多试几次,或者可以参考一下下边第六部分可能出现的报错中的第四小块。
然后点击左边的创建区块就可以点击左边创建区块分类拉框打标签了。
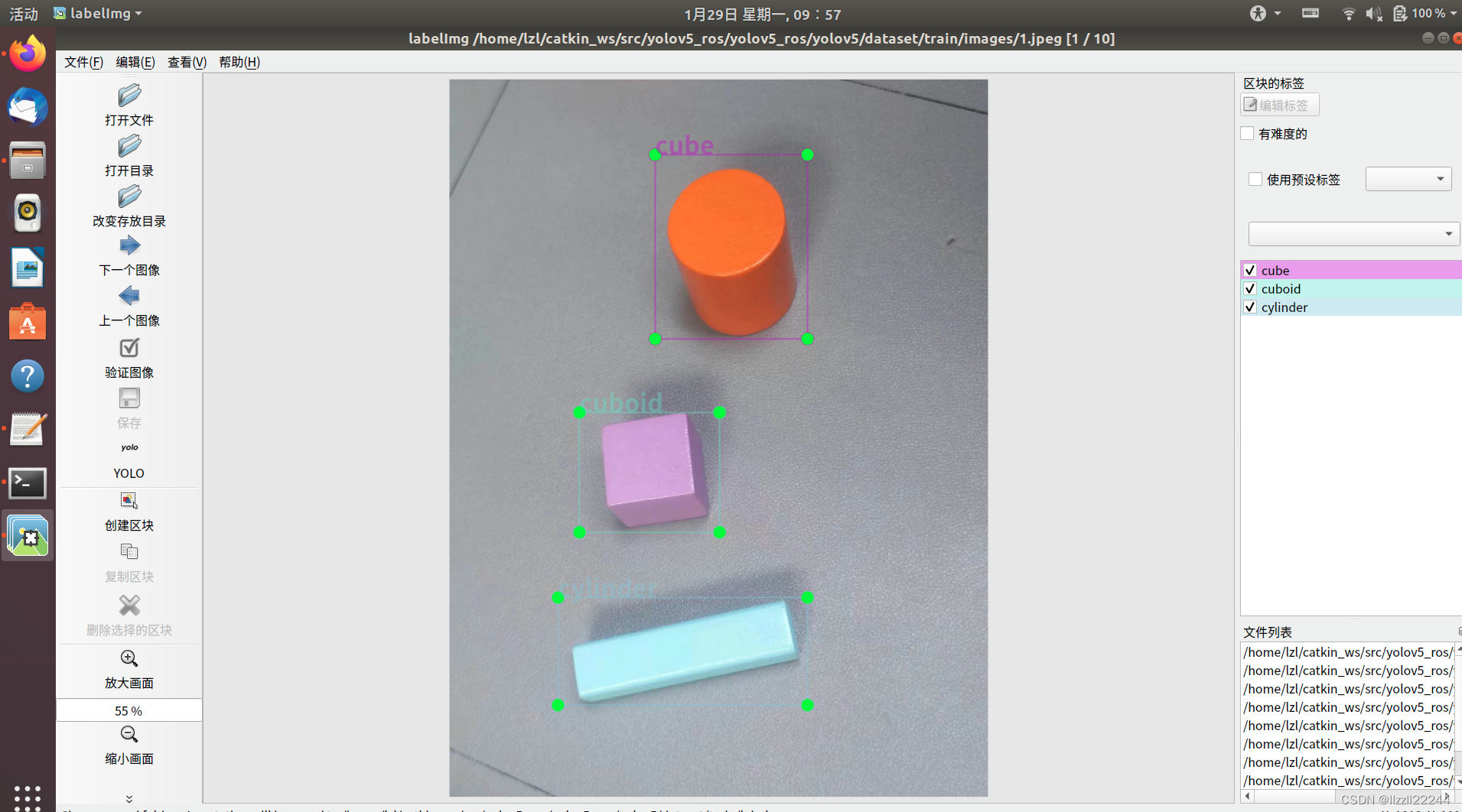
如果在拉框时闪退,并报错labelImg IndexError: list index out of range,可以查看第六部分可能出现的报错中的第六小块。在所有图片标注好之后,我们再来看我们的labels文件夹,可以看到很多txt文件。每个文件都对应着我们标记的类别和框的位置。

4.修改文件
(1)建立A.yaml文件,我放在了/home/lzl/catkin_ws/src/yolov5_ros/yolov5_ros/yolov5/data里边
touch A.yaml
文件里面内容如下,其中train和val都是我们images的目录,为训练集与验证集的图片,可以根据自己的实际情况改,labels的目录不用写进去,会自动识别。nc代表识别物体的种类数目,names代表种类名称,如果多个物体种类识别的话,可以自行增加。
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./dataset/train/images
val: ./dataset/val/images
# number of classes
nc: 3
# class names
names: ['cube','cuboid','cylinder']
(2)以下内容参考了Ubuntu使用官方Yolov5训练自己的数据集(小白向)_ubuntu使用yolov5训练自己的数据集-CSDN博客
models文件夹中的yaml文件记录了网络的配置信息,分为yolov5s、yolov5m、yolov5l、yolov5x四个,s是最轻量的版本网络深度最小,其他的依次增大,以yolov5s.yaml为例:
# parameters
nc: 3 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
nc是要类别数量,根据自己的数据集中的分类数修改nc即可,其他的无需改动。
(3)如果是使用cpu进行训练那就需要修改catkin_ws/src/yolov5_ros/yolov5_ros/yolov5中train.py的第107行改为
cuda = device.type != 'cpu'
5.进行训练
在catkin_ws/src/yolov5_ros/yolov5_ros/yolov5文件夹中打开终端输入
python train.py --help
可以查看可以传入的参数类型
其中weights是权重文件 .pt 格式,可以输入空格,代表使用随机权重,或者输入权重文件的路径
cfg是模型的yaml文件,一般存放在models文件夹里
data是数据集的yaml文件,一般存放在data文件夹里
epochs是训练轮数,默认300轮
batch-size是batch数,默认16
img是输入图片大小,网络会自动按参数进行resize,默认640X640
以上可以根据实际情况修改
之后运行,可能需要安装Arial.ttf字体,请看可能出现的报错(5)
python train.py --img 640 --batch 16 --epochs 6000 --data ./data/A.yaml --cfg ./models/yolov5s.yaml --weights ''
batch,epoch可以根据实际情况改
6.可能出现的报错
(1)在运行
python train.py --img 640 --batch 16 --epochs 6000 --data ./data/A.yaml --cfg ./models/yolov5s.yaml --weights ''
可能会出现RuntimeError: result type Float can't be cast to the desired output type long int
定位代码"/home/lzl/catkin_ws/src/yolov5_ros/yolov5_ros/yolov5/utils/loss.py", line 217在loss.py文件的第217行
原因:新版本的torch无法自动执行转换操作,而旧版本可以。
发现
gain
中元素为float类型,手动将其改为
long
。
改为
indices.append((b, a, gj.clamp_(0, gain[3].long() - 1), gi.clamp_(0, gain[2].long() - 1)))
(2)同样是运行这一句
python train.py --img 640 --batch 16 --epochs 6000 --data ./data/A.yaml --cfg ./models/yolov5s.yaml --weights ''
出现AttributeError: 'FreeTypeFont' object has no attribute 'getsize'
解决办法:
pip uninstall pillow
pip install Pillow==9.5 -i <https://pypi.tuna.tsinghua.edu.cn/simple>
(3) File "/home/lzl/catkin_ws/src/yolov5_ros/yolov5_ros/yolov5/utils/general.py", line 428, in check_dataset
raise Exception('Dataset not found.')
Exception: Dataset not found.
主要是因为路径的格式有问题,可以看一下这一篇
运行yolov5训练时遇到Exception: Dataset not found ❌_dataset not found , missing paths-CSDN博客
(4)在运行labelImg.py时如果出现报错 TypeError: expected str, bytes or os.PathLike object, not NoneType
直接在labelImg.py文件中1309行找到这行代码修改即可。
self.show_bounding_box_from_annotation_file(str(self.file_path))
(5) 在训练时,可能会出现无法下载Arial.ttf字体的问题,我将字体的安装包放在了网盘里,可以下载后点开ttf文件点击安装即可。
链接:https://pan.baidu.com/s/1snkvpkaC2lRLtjQHNMb2gA?pwd=1234
提取码:1234
(6)在拉框标注时出现labelImg IndexError: list index out of range报错
在这部分,我参考了解决labelimg闪退-CSDN博客的文章,问题的原因还是在labels文件夹中生成的classes.txt文件中类别不全的原因。

可以看到打开文件之后只有cube一个类,但是我们实际上有三个类别。 系统不知道有其他这个标签,就提示该闪退。
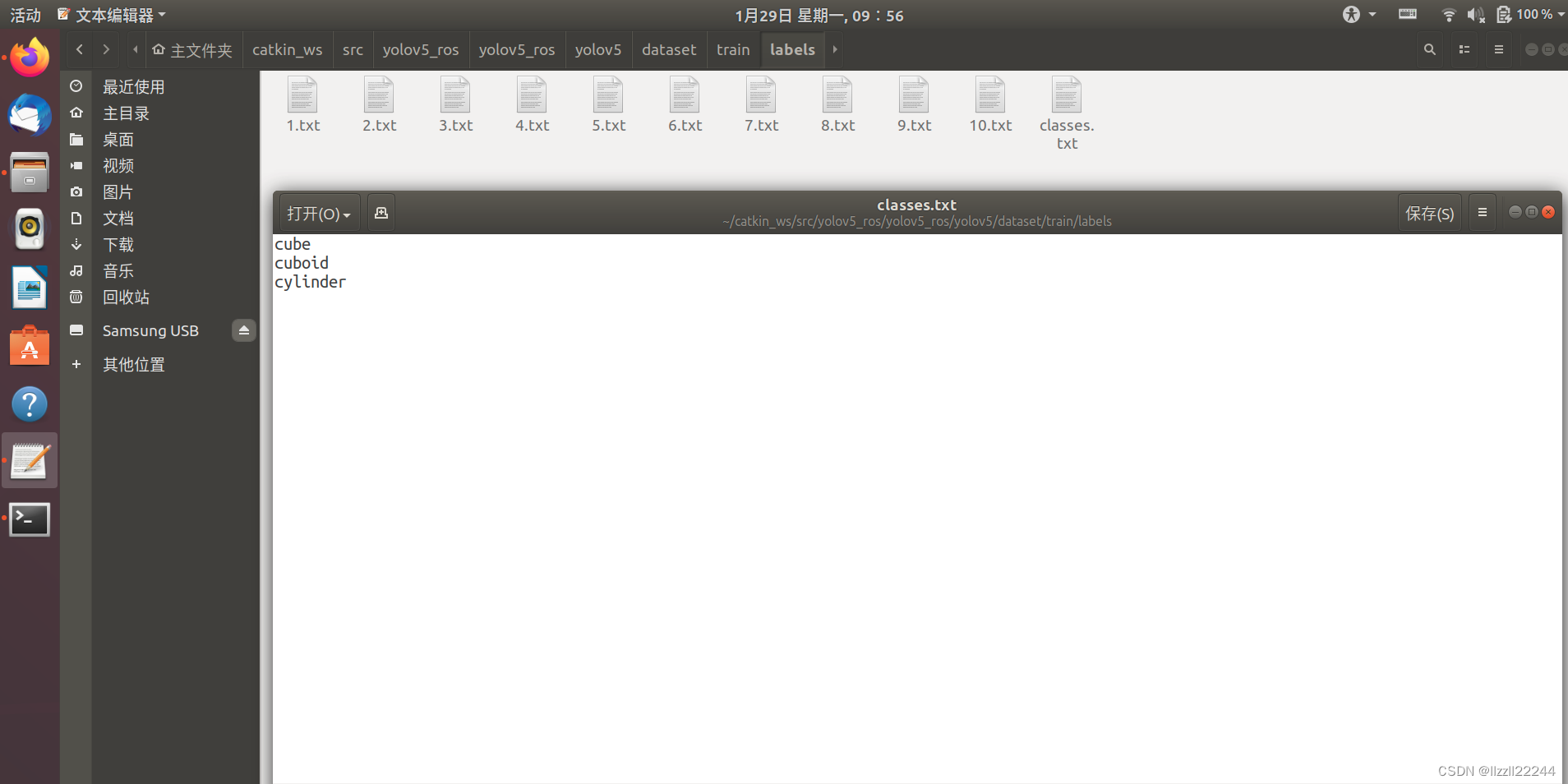
我们补上即可。
6.使用训练出的模型进行标注

在训练结束后可以看到训练好模型的存放位置,exp25中的weights 文件夹下就是通过训练出来的权重文件,best.pt 是最好的
执行命令,在此次一定要注意best.pt与待标注图片的路径
python detect.py --weights ./runs/train/exp25/weights/best.pt --source ./dataset/val/images/9.jpeg

可以看到结果存在了此处,打开文件夹可以看到标注结果

结束!
版权归原作者 llzzll22244 所有, 如有侵权,请联系我们删除。