
MySql系列整体栏目
内容链接地址【一】深入理解mysql索引本质https://blog.csdn.net/zhenghuishengq/article/details/121027025【二】深入理解mysql索引优化以及explain关键字https://blog.csdn.net/zhenghuishengq/article/details/124552080【三】深入理解mysql的索引分类,覆盖索引(失效),回表,MRRhttps://blog.csdn.net/zhenghuishengq/article/details/128273593【四】深入理解mysql事务本质https://blog.csdn.net/zhenghuishengq/article/details/127753772【五】深入理解mvcc机制https://blog.csdn.net/zhenghuishengq/article/details/127889365【六】深入理解mysql的内核查询成本计算https://blog.csdn.net/zhenghuishengq/article/details/128820477【七】深入理解mysql性能优化以及解决慢查询问题https://blog.csdn.net/zhenghuishengq/article/details/128854433【八】深入理解mysql执行的底层机制https://blog.csdn.net/zhenghuishengq/article/details/128100377【九】深入理解mysql集群的高可用机制https://blog.csdn.net/zhenghuishengq/article/details/126239652
深入理解mysql的内核查询成本计算
一,mysql的内核查询成本
1,mysql单表查询成本计算
在mysql中,无论是innodb存储引擎还是MyIsam存储引擎,主要是由两种时间成本组成,分别是io成本 和 CPU成本 。io成本就是数据从磁盘加载到内存时,需要花费的时间成本;cpu成本就是需要去判定里面的where语句,或者其他的范围查询,in查询等是否符合要求所需要的时间成本。
在mysql中,IO成本默认需要花费1个单位的成本,CPU成本默认需要花费0.2个单位成本(不管是否存在需要过滤的条件)。因此在计算一个成本时,其基本公式如下,然后mysql内部会考虑一些微调值,这里暂不考虑。
T(i/o): 总页数 *1.0T(cpu): 总条数 *0.2T(总)=T(i/o)+T(cpu)
这些都是默认值,mysql也可以对这些值进行调整。这里的1个单位指的是:innodb存储引擎读取一页数据所花费的时间
1.1,建表
接下来新建一张订单表,其各个字段如下
CREATETABLE `order_exp` (
`id` bigint(22)NOTNULLAUTO_INCREMENTCOMMENT'订单的主键',
`order_no` varchar(50)NOTNULLCOMMENT'订单的编号',
`order_note` varchar(100)NOTNULLCOMMENT'订单的说明',
`insert_time` datetime(0)NOTNULLCOMMENT '插入订单的时间',
`expire_duration` bigint(22)NOTNULLCOMMENT '订单的过期时长,单位秒',
`expire_time` datetime(0)NOTNULLCOMMENT '订单的过期时间',
`order_status` smallint(6)NOTNULLDEFAULT0COMMENT '订单的状态,0:未支付;1:已支付;-1:已过期,关闭',PRIMARYKEY(`id`)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=10819CHARACTERSET= utf8 COLLATE= utf8_general_ci ROW_FORMAT=Dynamic;
需要里面的表结构以及数据的话,可以直接在百度网盘下载即可,提取码为1234:https://pan.baidu.com/s/12Py6QwzlZ7CXGuwNKp_bsA
接下来分析下面这句简单的sql语句
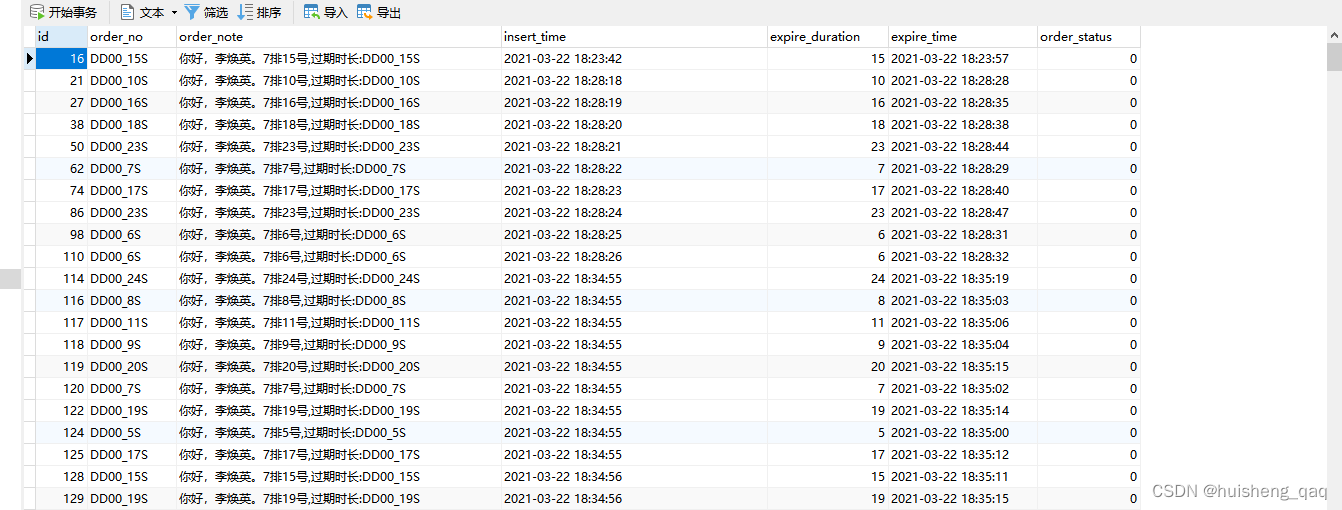
SELECT*FROM order_exp WHERE order_no IN('DD00_6S', 'DD00_9S', 'DD00_10S')AND expire_time> '2021-03-2218:28:28' AND expire_time<= '2021-03-2218:35:09' AND insert_time> expire_time AND order_note LIKE'%7排1%'AND order_status =0;
因此通过分析可知,可以给order_no字段添加一个索引,expire_time字段添加一个索引,这两个字段都缩小了范围,符合之前所说的一星索引;而这个like由于%在前面,根据B+树的原则,like添加索引的话会失效,因此order_note字段不添加索引;order_status这个字段只有0,1和 -1,离散性太低,肯定不走索引,因此也不添加索引;这个insert_time由于和这个expire_time都是变量,而索引是一个变量跟常量进行比较的,因此这里肯定也不走索引,因此不在这个字段上加索引。
alter table order_exp add index idx_order_no (order_no);
alter table idx_expire_time add index idx_expire_time (expire_time);
可以通过以下命令来查看当前表中存在的所有索引
show keys from order_exp;
1.2,Optimizer Trace
在获取底层如何是优化这个sql语句之前,需要先了解一个工具,就是这个 Optimizer Trace 。可以通过开启这个 Optimizer Trace 指令,来查看底层优化器的执行过程,可以查看mysql是如何选择的最佳的优化路线的。Trace工具可以从细节上分析MySQL是如何选择索引。
其开启的命令如下
SET optimizer_trace="enabled=on";
开启完之后,就可以输入需要查询的sql语句,再输入具体需要查询的sql语句,如下
SELECT*FROM order_exp WHERE order_no IN('DD00_6S', 'DD00_9S', 'DD00_10S')AND expire_time> '2021-03-2218:28:28' AND expire_time<= '2021-03-2218:35:09' AND insert_time> expire_time AND order_note LIKE'%7排1%'AND order_status =0;
可以再通过输入以下的命令,就可以看到底层分析的过程以及结果了。
SELECT*FROM information_schema.OPTIMIZER_TRACE\G
最后就可以出现一下的一大堆东西的界面,有了这个结果之后,就可以通过上面的结果来验证,innodb底层的这个成本优化思路了。
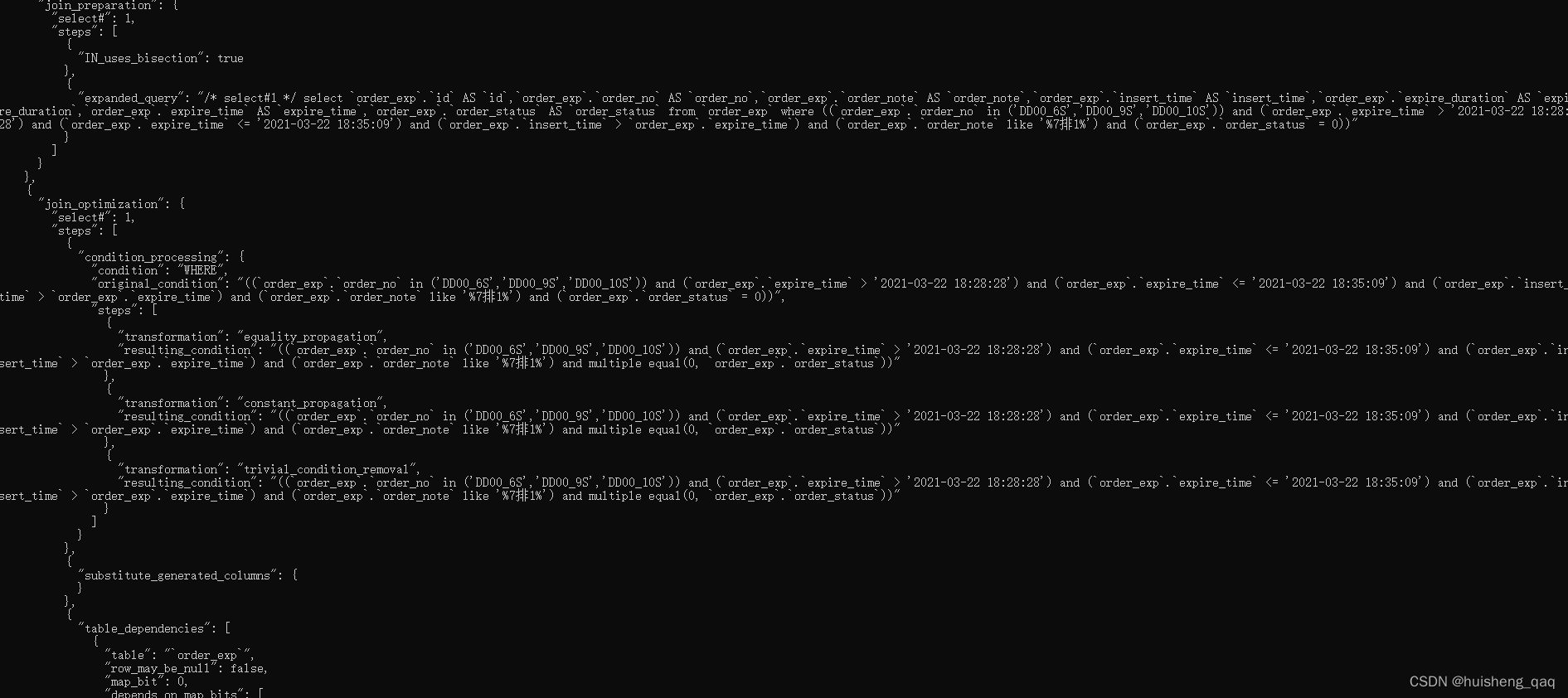
1.3,单表成本优化思路
基于成本的优化步骤主要由四个步骤组成。一是根据搜索条件,找出所有可能使用到的索引;二是先计算全表扫描的代价;三是使用不同索引执行查询的代价;四是对比各种执行的方案代价,找出成本最低的那个
1.3.1,找出所有可能使用到的索引
一条sql语句中找出全部可能使用到的索引,主要是使用关键字 explain ,在查询的sql语句之前加上explain这个关键字即可分析出可能会使用哪些索引
explain SELECT*FROM order_exp WHERE order_no IN('DD00_6S', 'DD00_9S', 'DD00_10S')AND expire_time> '2021-03-2218:28:28' AND expire_time<= '2021-03-2218:35:09' AND insert_time> expire_time AND order_note LIKE'%7排1%'AND order_status =0;
其具体分析结果如下,type类型是range的范围查询,然后可能使用到的key就是建立的那两个索引。

1.3.2,计算全表扫描的代价
接下来就是先计算这个全表扫描的代价。全表扫描就是直接扫描聚簇索引的叶子结点,由于所有的数据都在聚簇索引的叶子结点上,因此就会通过这个遍历上面的每一个结点,然后对每一个结点进行匹配,看是否满足这个全部的要求
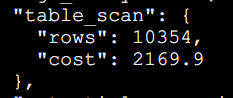
接下来就通过这个Optimizer Trace 工具获取到的里面的数据分析(上面已打开),然后找到全表扫描所花费的这个单位。如下,全表扫描大概10354行,并且通过这个Trace工具得知的,大概需要花费2169.9个页单位。
由于这里计算的是全表扫描,那么就需要知道总行数以及总页数,因此可以使用下面这个命令
SHOW TABLE STATUS LIKE 'order_exp'\G
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vnB1kKLN-1675155949965)(img/1672906699366.png)]](https://img-blog.csdnimg.cn/37c842c48bd7476883b6e38a3695ae12.png)
其结果如上图,从图中可知 data_length 的长度为 1589248,因此可以得知总页数为97,这个长度就是数据的总字节数。
1589248 ÷ 16 ÷ 1024=97
总条数为Rows 10343,因此可以利用这个成本计算的公式,这里会涉及到一个微调数,这里的微调数是mysql底层的硬编码,因此是必加的。因此和上面的这个全表扫描的成本对上了。
T(I/O):97*1.0+1.1(微调数)=98.1T(CPU):10354*0.2+1.0(微调数)=2071.8T(总)=T(I/O)+T(CPU)=2169.9
1.3.3,分别计算其他索引的查询代价
在使用完主键索引之后,那么就会计算二级索引的代价,唯一索引会优先普通索引。接下来可以先查看这个 order_note 列所对应的索引,这个索引是一个普通索引。
order_note 索引
由于这个 order_note 字段总涉及到三个范围,那么在二级索引查询时,需要查询三次,那么只需要三次IO,由于在使用该字段时查询的结果只有58行,那么需要进行58次的cpu的判断;最后涉及到回表,在聚簇索引中也要花费一定的时间,则整体成本代价如下
T(I/O二级索引):3*1.0=3T(I/O回表):58*1.0=58T(CPU):58*0.2+0.01(微调数)=11.61T(CPU回表):58*0.2=11.6T(总)=T(I/O二级索引)+T(I/O回表)+T(CPU)+T(CPU回表)=84.21
如下图可知这个cost花费的成本是84.21,那是因为在mysql内部,将这个回表时的CPU所花费的这个时间成本给省去了,如果84.21 - 11.6 ,那么刚好就是这个72.61这个值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dvpxjVLQ-1675155949966)(img/1675128067751.png)]](https://img-blog.csdnimg.cn/0fc70cc722ed4ea1945e45bae3fce4f0.png)
expire_time索引
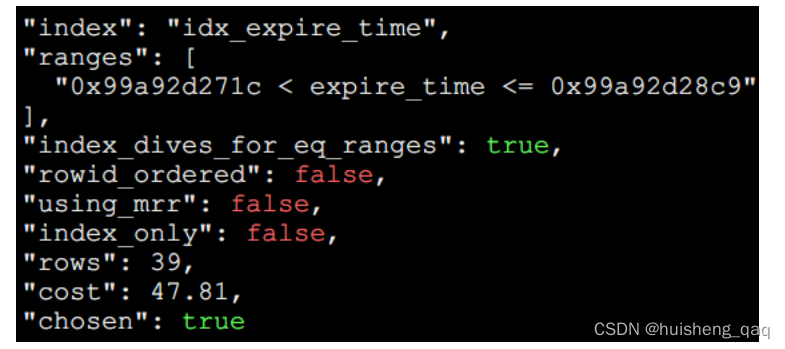
再计算这个expire_time这列索引的成本代价,这里由于就一个范围时间,因此只需要一次IO,在单独使用这个字段作为索引时,发现只涉及到39行数据,因此这个需要进行39次cpu的判断;同时在这个二级索引结束之后,需要回表到一级索引里面,通过一级索引去找到对应的值,因此一级索引也需要一定的IO和CPU,由于二级索引找到的值有39行数据,那么需要回表39次,其IO和CPU成本如下
T(I/O二级索引):1*1.0=1T(I/O回表):39*1=39T(CPU):39*0.2+0.01(微调数)=7.81T(CPU回表):39*0.2=7.8T(总)=T(I/O二级索引)+T(I/O回表)+T(CPU)+T(CPU回表)=55.61
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-82krlCGh-1675155949966)(img/1675128183273.png)]
系统显示是47.81,而实际计算是 55.61 ,那是由于在进行这个比较计算的时候,mysql内部会扣掉这个CPU回表的时间,即55.61 - 7.8 = 47.81 ,那么就对上了。
1.3.4,对比全部扫描的代价和其他单个索引的代价
因此在极端完上面这几个成本之后,就可以进行一个最终的比较了,通过这个cost成本比较得知,这个expire_time索引花费的时间最小,因此最终选择的是使用这个 expire_time 字段作为最终的选择的索引。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kxwO6Is7-1675155949967)(img/1672901244598.png)]](https://img-blog.csdnimg.cn/66a299d07e0748edb3c680624ac18eee.png)
2,in查询内核成本分析
在mysql中,其内部对in这个关键字也做了相应的优化
select * from user where user_no in ('123',xxx,xxx,...);
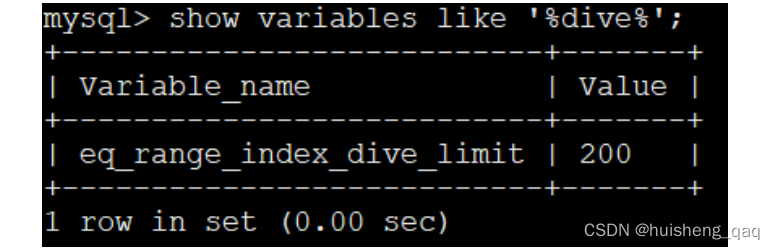
在使用这个in查询时,如果出现很多的这个单点区间的时候,那么就会触发这个 index dive,就是会有一个最大值去控制,可以发现这个默认的最大值为200,如果括号中的值是小于200的话,就会进行一个精确的计算,如果值大于200的话,就会进行一个估算。
show variables like '%dive%'
3,连接查询成本计算
在使用这个连接查询时,需要遵循一个原则就是:小表驱动大表。其主要通过这个嵌套循环连接算法实现这个连接查询,即驱动表查询一次,被驱动表则需要查询多次。 而多次查询被驱动表的成本,主要是取决于对驱动表查询的结果集中有多少条记录,即驱动表看的不是表中有多少数据,而是看查出来的结果集中的数据条数,谁的结果集的数据小则用哪张表作为结果集。
如果是使用这个左连接右连接,mysql内部很少做优化的东西,如果是内连接,那么mysql内部会做一个计算,去统计结果集的数据,然后区分谁做这个驱动表。
其成本计算的方式就是:表1的成本 + 表2的扇出 x 表1的成本 。因此这个优化手段就是两个部分,分别是 尽量减少驱动表的扇出,对被驱动表的访问成本尽量低。 并且在这个《阿里最新Java编程规范泰山版》的规定当中,
规定其超过三个表禁止join,需要join的字段,其数据类型保持绝对的一致,在多表关联查询时,保证被关联的字段走索引。
版权归原作者 huisheng_qaq 所有, 如有侵权,请联系我们删除。