
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
** ▲ 本章节目的**
⚪ 了解Spark的RDD结构;
⚪ 掌握Spark的RDD操作方法;
⚪ 掌握Spark的RDD常用变换方法、常用执行方法;
一、Spark最核心的数据结构——RDD弹性分布式数据集
1. 概述
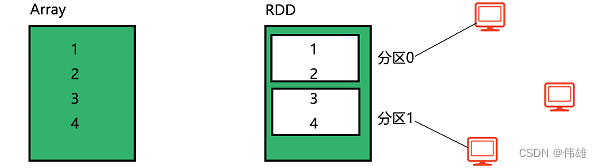
初学Spark时,把RDD看做是一个集合类型(类似于Array或List),用于存储数据和操作数据,但RDD和普通集合的区别:
RDD有分区机制,可以分布式,并行的处理同一个RDD数据集,从而极大提高处理效率。分区数量由程序员自己定。
RDD由容错机制。即数据丢失后,可以进行恢复。
2. 创建RDD方法
RDD就是带有分区的集合类型
弹性分布式数据集(RDD),特点是可以并行操作,并且是容错的。有两种方法可以创建RDD:
- 执行Transform操作(变换操作)。即将一个普通集合(Array或List)转变为一个RDD。
例如:val r1 = sc.parallelize(a1,2)
或 val r1 = sc.makeRDD(List(1,2,3,4),2)
查看分区数量:r1.partitions.size。
查看分区数据:r1.glom.collect。
查看RDD整体数据:r1.collect。
- 读取外部存储系统的数据集,如HDFS,HBase,或任何与Hadoop有关的数据源。
读取Linux本地文件:val r4 = sc.textFile("file:home/1.txt",2)
读取hds文件:val r5 = sc.textFile("hdfs://hadoop01:9000/1.txt",2)
3. RDD入门示例
案例一:
并行化集合可以通过调用 Spark Context 的并行化方法被创建,这个方法是在驱动程序(Scala-Seq)中的现有集合上的。集合里的参数会被拷贝到可以并行执行的分布式数据集里。如下例子就是如何创建一个包含了 1 到 5 的并行化集合。例如:
val data = Array(1, 2, 3, 4, 5)
val r1 = sc.parallelize(data)
valr2 = sc.parallelize(data,2)
你可以这样理解RDD:它是spark提供的一个特殊集合类。诸如普通的集合类型,如传统的Array:(1,2,3,4,5)是一个整体,但转换成RDD后,我们可以对数据进行Partition(分区)处理,这样做的目的就是为了分布式。
你可以让这个RDD有两个分区,那么有可能是这个形式:RDD(1,2) (3,4)。
这样设计的目的在于:可以进行分布式运算。
注:创建RDD的方式有多种,比如案例一中是基于一个基本的集合类型(Array)转换而来,像parallelize这样的方法还有很多,之后就会学到。此外,我们也可以在读取数据集时就创建RDD。
案例二:
Spark能够从任何基于Hadoop的存储资源,创建分布式数据集。包括本地文件系统、HDFS、Cassandra、HBase、Amazon S3等等。Spark支持TEXT文件格式、SequenceFiles文件格式和其他Hadoop的输入文件格式。
RDD的TEXT文件能够通过SparkContext的方法创建。这个方法获取一个文件的URI路径(可以是本地路径、或者是hdfs://, s3n://等),然后当作一条数据集读取其中内容。例如:
val distFile = sc.textFile("data.txt")
4. 查看RDD
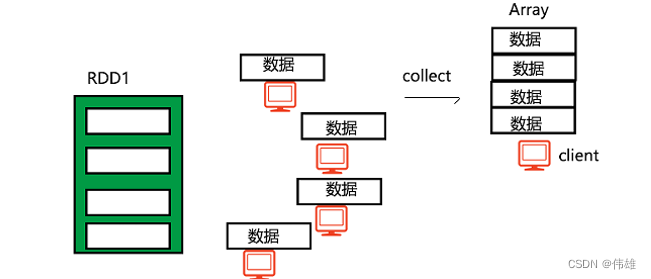
scala>rdd.collect
收集rdd中的数据组成Array返回,此方法将会把分布式存储的rdd中的数据集中到一台机器中组建Array。
在生产环境下一定要慎用这个方法,容易内存溢出。
查看RDD的分区数量:
scala>rdd.partitions.size
查看RDD每个分区的元素:
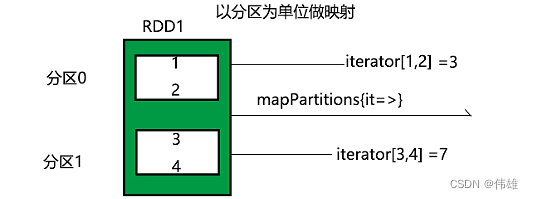
scala>rdd.glom.collect
此方法会将每个分区的元素以Array形式返回。
5. 分区概念
在下图所示, 一个RDD有item1~item25个数据,共5个分区,分别在3台机器上进行处理。
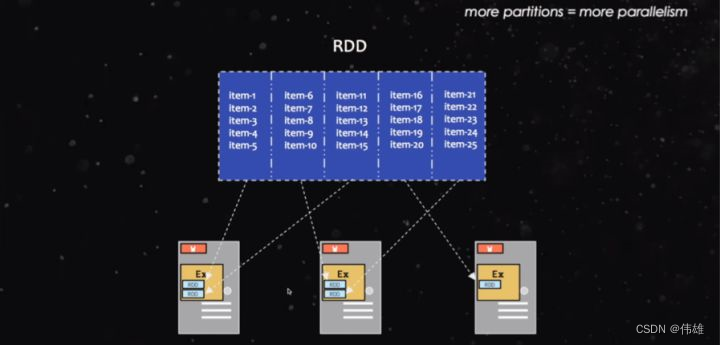
此外,spark并没有原生的提供rdd的分区查看工具我们可以自己来写一个。
案例三:
import org.apache.spark.rdd.RDD
import scala.reflect.ClassTag
object su {
def debug[T: ClassTag](rdd: RDD[T]) = {
rdd.mapPartitionsWithIndex((i: Int, iter: Iterator[T]) => {
val m = scala.collection.mutable.MapInt, List[T]
var list = ListT
while (iter.hasNext) {
list = list :+ iter.next
}
m(i) = list
m.iterator
}).collect().foreach((x: Tuple2[Int, List[T]]) => {
val i = x._1
println(s"partition:[$i]")
x._2.foreach { println }
})
}
}
二、RDD的操作
1. 概述
对于RDD的操作,总的来分有三种:
Transformation变化操作,特点是都是懒操作,调用后并不是马上执行,比如典型的textFile方法。此外,每当调用一次变化操作(懒操作),就会产生一个新的RDD。
Action执行操作,特点是会触发执行。
Controller控制操作。
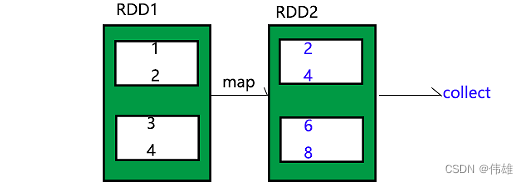
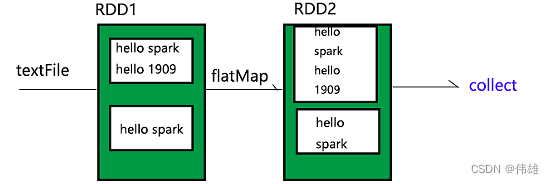
2. 常用的变化方法(懒方法):
Transformation****Meaning
map(func)
Return a new distributed dataset formed by passing each element of the source through a function func.
返回一个新的分布式数据集,通过函数应用于RDD每一个元素,该方法的参数是一个函数。
案例:
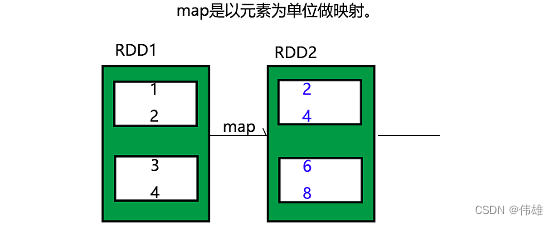
map 将函数应用到rdd的每个元素中
val rdd = sc.makeRDD(List(1,3,5,7,9)
版权归原作者 伟雄 所有, 如有侵权,请联系我们删除。