
TEZ介绍及使用
TEZ是什么?
Tez是支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG 作业的性能。
Tez源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
TEZ的运行过程:
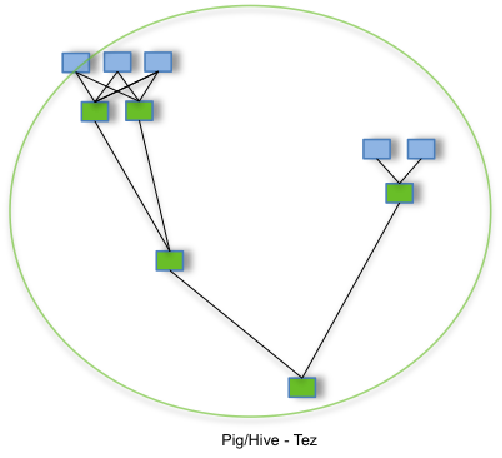
下图为MR和TEZ两个计算框架在处理任务时的运行过程图(也可以理解为有子查询的任务)
通过允许诸如Apache Hive和Apache Pig之类的项目运行复杂的 DAG(运行计算的有向无环图)任务,Tez 可以用于处理数据,该数据以前需要执行多个MR作业,而现在在单个Tez作业中。
第一个图表展示的流程包含多个MR任务,每个任务都将中间结果存储到HDFS上——前一个步骤中的reducer为下一个步骤中的mapper提供数据。第二个图表展示了使用Tez时的流程,仅在一个任务中就能完成同样的处理过程,任务之间不需要访问HDFS。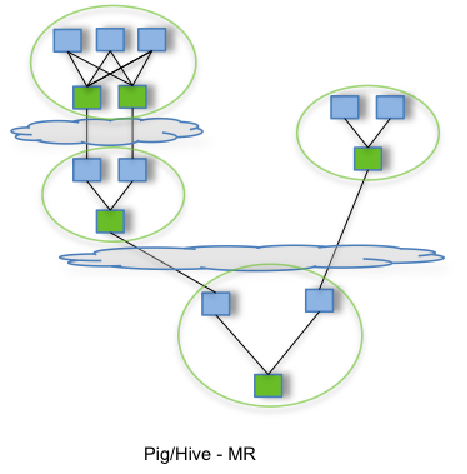
MR,TEZ,SPARK都解决了什么问题?
MR,TEZ,SPARK都是计算框架,又可以共同存在,肯定各有各的特长。
MR:MR的初衷是让廉价的,配置低的服务器运行任务。核心思想是分而治之。大任务分解成小任务。这样就造成了MR比较慢。任务多申请资源耗时,跑任务中间结果要落磁盘耗时。
TEZ:MapReduce模型虽然很厉害,但是它不够的灵活,一个简单的join都需要很多操作才能完成,又是加标签又是笛卡尔积。 Tez采用了DAG(有向无环图)来组织MR任务(DAG中一个节点就是一个RDD,边表示对RDD的操作)。它的核心思想是把将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。有了DAG执行图,才能将任务重组。
SPARK:Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark拥有Hadoop MapReduce所具有的优点,Spark在Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark性能以及运算速度高于MapReduce。Spark也拥有DAG,也可以根据依赖关系优化任务,也充分运用内存避免中间结果落盘。但Spark集群是一个大的解决方案,如果有很多大的,很重要的任务跑在Spark集群。再将Spark集成在Hive上处理比较多的查询任务。对Spark集群的维护不利。
TEZ的优缺点
优点
1.避免中间数据写回HDFS,减小任务执行时间
2.vertex management模块使runtime动态修改执行计划变成可能
3.input/processor/output编程模型,大大提高了任务模型的灵活性
4.提供container复用机制与Tez Session,减少资源消耗
缺点
1.Tez与Hive捆绑,在其他领域应用较少
2.社区不活跃(官网的文档少的可怜,最近更新2019年)
3.完全基于内存。注意:如果数据量特别大,慎重使用,容易OOM。一般用于快速出结果,数据量小的场景。适合用于查询。
TEZ与HIVE的集成
1.将tar.gz文件拷贝到HDFS上,不需要解压。
2.在hive的conf里创建一个tez.xml文件同时 hiveserver2 和 hive metastore服务里都要有这个xml
3.把所有tez的jar包都拷贝到hive的lib里
4.重启服务。就可以用TEZ计算引擎来运行hive的任务。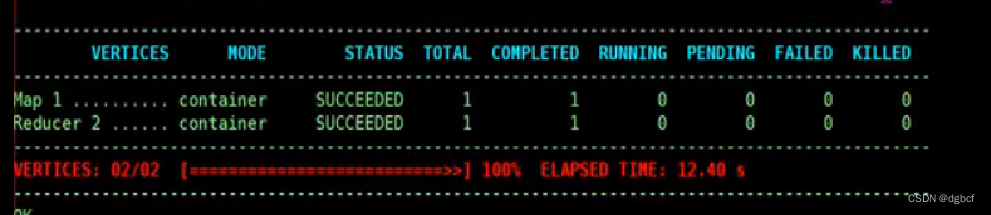
版权归原作者 dgbcf 所有, 如有侵权,请联系我们删除。