
一.引言
Flink 使用场景下,经常需要与 Mysql、Redis、Hbase 等数据库进行数据交互,对于高吞吐高并发的 Flink 实时任务而言,大量的网络 IO 将引起比较可观的背压,严重情况下导致程序运行失败,所以在某些变量可重复使用的场景,可以通过引入缓存减少网络 IO 请求,提高程序整体时效性与鲁棒性。下面主要介绍两类 Cache:
LRUCache:常用的 cahce,基于 LinkedHashMap 实现,可以控制 cache 容量
GuavaCache:Google 开发,在控制 cache 容量的基础上,新增了时间控制
二. LRUCache
1.源码浅析
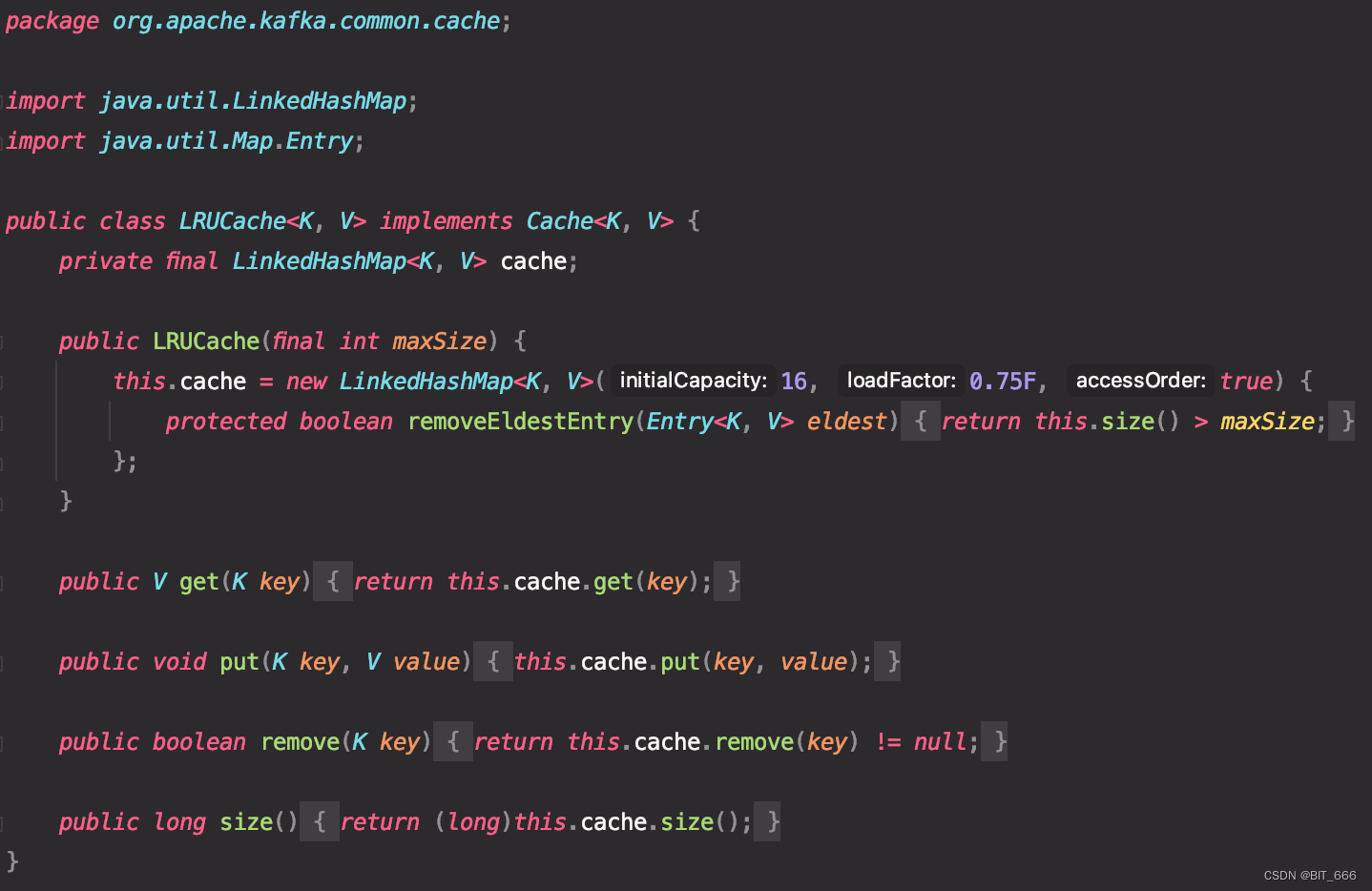
LRUcache 是最常用的 cache 类型,很多基于容量控制的 cache 都是基于 LinkedHashMap 进行改造,这里在 Map.Entry 的基础方法 put、get 下新增了 removeEldestEntry 方法,用于控制移除超出默认 capacity 的元素,所以 LRUcache 是先来先出的,即先来的元素先清除。
2.Flink 使用 Cache
Flink 一般在 ProcessFunction 处理数据流或者 Window 时可能用到缓存,这时需要在全局定义缓存并在 open 方法中初始化缓存,最终运用到 process 或者 invoke 方法内。
public class processFunction extends ProcessFunction<IN, OUT, KEY, WINDOW> {
// 定义缓存与Socket
LRUCacheKKV lrucache = null;
Jedis jedis = null;
String host = "";
int port = 0;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 初始化 缓存
int lruCapacity = 50000;
lrucache = new LRUCacheKKV(lruCapacity);
// 初始化 Jedis
jedis = new Jedis(host, port);
}
@Override
public void process(Integer key, Context context, Iterable<IN> iterable, Collector<OUT> collector) throws Exception {
try {
Iterator<IN> it = iterable.iterator();
// 自定义处理逻辑,并实现读取与更新缓存
processUdf(it, jedis, lrucache);
} catch (Exception e) {
e.printStackTrace();
}
}
}
要把缓存装冰箱,大致分三步:
默认值定义:class 内定义缓存与 Socket 类型
open 初始化:open 方法内将对应的缓存与 Socket 进行缓存,常见的 Redis + LRUCache
process 处理:在处理方法内用 Socket 读取信息,并用 LRUcache 完成缓存与复用,提高效率
3.LRUcache 测试
3.1.初始化 LRUCache
import org.apache.kafka.common.cache.LRUCache
val lruCache = new LRUCache[String, String](10)
(0 to 15).foreach(num => {
lruCache.put(num.toString, num.toString)
})
初始化 LRUCache,设定 KV 类型均为 String,容量为10。
3.2.LRUCache 容量检测
// 检测当前cache包含元素
val re = (0 to 15).map(num => {
lruCache.get(num.toString)
}).filter(_ != null).toArray
println(re.length)
println(re.mkString(","))
// 重新添加元素检测cache包含元素
lruCache.put("2", "2")
val re2 = (0 to 15).map(num => {
lruCache.get(num.toString)
}).filter(_ != null).toArray
println(re2.length)
println(re2.mkString(","))
可以看到 cache 元素始终为 10, 第一次 0 to 15,由于限制为 10 的原因,只剩下 6-15 保存在 cache 中,重新添加元素 2,最早的元素 6 被清出,按到达顺序剩余元素为 [7-15] + [2]。
10
6,7,8,9,10,11,12,13,14,15
10
2,7,8,9,10,11,12,13,14,15
三.GuavaCache
GuavaCache 通过 CacheBuilder 初始化,在 maximumSize 控制容量的基础上新增了 expireAfterWrite 与 expireAfterAccess 实现对缓存的时间控制,三者在本质上都是逐出策略,即何时将缓存从 Cache 中清除,差别是不在拘束于先后顺序,下面看下三种控制策略。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
<scope>provided</scope>
</dependency>
1.maximumSize
maximumSize 与 LRUCache 的 capacity 相同,通过数量控制 cache 的缓存容量。通过 build 方法完成 GuavaCache 实例的构建,这里初始化了容量为 10 的 [String, String] 类型的缓存。
// 表示按照写入时间过期
val cacheWithSize: Cache[String, String] = CacheBuilder.newBuilder()
.maximumSize(10)
.build[String, String]
(0 to 15).foreach(num => {
cacheWithSize.put(num.toString, num.toString)
})
val re = (0 to 15).map(num => {
cacheWithSize.getIfPresent(num.toString)
}).filter(_ != null).toArray
println(re.length)
println(re.mkString(","))
和 LinkedHashMap 原理相似,缓存元素先到先出:
10
6,7,8,9,10,11,12,13,14,15
2.expireAfterWrite
字面翻译为按照写入时间过期,这里的含义是每次写入缓存都会对 Key 设置过期时间,只要在规定时间内未重新写入该 Key,则到期后对应 KV 被清除,这里好处是一个 Key 不会存储过长时间,缺点是对于命中率高的缓存不能有效保存,所以适用于整体命中率相近,缓存数量更新相对稳定的场景。
// 表示按照写入时间过期
val cacheWithWriteTime: Cache[String, String] = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10000, TimeUnit.MILLISECONDS)
.recordStats()
.build[String, String]
cacheWithWriteTime.put("test", "test")
Thread.sleep(5000)
println("等待5s后数据:" + cacheWithWriteTime.getIfPresent("test"))
Thread.sleep(5000)
println("等待10s后数据:" + cacheWithWriteTime.getIfPresent("test"))
一般而言,expire 策略都和 maximumSize 策略配合使用,防止元素过多超出内存限制。这里初始化 1000 容量的 KV 缓存,并且规定 10000 ms 即 10s 的写入元素过期时间。
// 表示按照写入时间过期
val cacheWithWriteTime: Cache[String, String] = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10000, TimeUnit.MILLISECONDS)
.recordStats()
.build[String, String]
cacheWithWriteTime.put("test", "test")
Thread.sleep(5000)
println("等待5s后数据:" + cacheWithWriteTime.getIfPresent("test"))
Thread.sleep(5000)
println("等待10s后数据:" + cacheWithWriteTime.getIfPresent("test"))
可以看到 10s 内可以正常拿到数据,超过10s后再次获取缓存返回 null:
等待5s后数据:test
等待10s后数据:null
3.expireAfterAccess
按照访问频率过期,expireAfterWrite 针对每个元素都设定了固定的过期时间,保证每个 K 不会存储过长时间,expireAfterAccess 按访问频率过期,每次访问对应 K 元素都会重置其过期时间,如果对应时间内该元素未访问,则删除对应缓存。该方法的好处是针对访问频繁的数据可以做到减少缓存次数,但是也有一个问题,如果访问频率小于过期时间,将导致对应变量始终为旧变量,无法触发 socket 访问新元素,从而导致数据更新不及时。
val cacheWithAccessTime = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterAccess(5000, TimeUnit.MILLISECONDS)
.build[String, String]
cacheWithAccessTime.put("test", "test")
var epoch = 3
while (epoch > 0) {
Thread.sleep(4000)
println(cacheWithAccessTime.getIfPresent("test"))
epoch -= 1
}
Thread.sleep(5000)
println(cacheWithAccessTime.getIfPresent("test"))
这里设定 5000ms 即 5s 的访问过期时间,while 循环内控制间隔为 4000ms 即 4s,始终可以取到缓存值,但是当时间超过 5s 时,再访问对应缓存就无法得到值了:
test
test
test
null
4.More
4.1 组合使用
maximumSize 控制数量,expireAfterWrite 控制存活时长,expireAfterAccess 控制更新频率,可以结合三个方法的特点构造复合 GuavaCache:
val mixGuavaCache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(3000, TimeUnit.MICROSECONDS)
.expireAfterAccess(5000, TimeUnit.MILLISECONDS)
.build[String, String]
内部通过 isExpired 判断元素与当前 now 的时间戳判断元素状态并决定是否逐出元素是否逐出缓存:
boolean isExpired(LocalCache.ReferenceEntry<K, V> entry, long now) {
Preconditions.checkNotNull(entry);
if (this.expiresAfterAccess() && now - entry.getAccessTime() >= this.expireAfterAccessNanos) {
return true;
} else {
return this.expiresAfterWrite() && now - entry.getWriteTime() >= this.expireAfterWriteNanos;
}
}
4.2 recordStats 指标
recordStats 意在给 cache 增加统计指标,一般使用 cache 我们需要关注缓存的命中率,来了多少元素,逐出多少元素等等参数,使用 builder 构造时添加一列 .recordStats() 方法即可添加:
val cacheWithWriteTime: Cache[String, String] = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10000, TimeUnit.MILLISECONDS)
.recordStats()
.build[String, String]
println(cacheWithWriteTime.stats())
在需要的时候打印 statas() 即可,可以看到 cache 访问 hit 成功 1001 次,miss 失败 502 次,共逐出 502 个元素。
CacheStats{hitCount=1001, missCount=502, loadSuccessCount=0,
loadExceptionCount=0, totalLoadTime=0, evictionCount=502}
4.3 invalidate 清除元素
除了通过数量,时间等策略等待缓存清除外,也可以调用 invalidate 手动清除缓存:
public void invalidate(Object key) {
Preconditions.checkNotNull(key);
this.localCache.remove(key);
}
public void invalidateAll(Iterable<?> keys) {
this.localCache.invalidateAll(keys);
}
public void invalidateAll() {
this.localCache.clear();
invalidate 删除指定 K,invalidateAll 删除批量 keys 或者全部清除缓存。
4.4 asMap 本地化
除了使用 Cache<K, V> 外,也可以调用 asMap 方法获得一个 ConcurrentMap<K, V>,然后就可以像 map 一样操作 cache 了:
cacheWithWriteTime.asMap()
同时,对 asMap 后的 ConcurrentMap 对象对缓存 key 进行 get 或者 put 方法时,也会重置对应 key 的过期时间,但 containsKey 不会,所以 asMap 后也需要关注 key 的存活周期与对应的内存管理。
四.总结
Flink 可以基于上述 Cache 在 ProcessFunction 中应用缓存,由于缓存使用本地内存作为存储空间,因此需要注意 TaskManager 上的内存占用,适当情况下增加 TaskManager Heap,更详细的内存控制可参考:Flink - 内存模型详解。

版权归原作者 BIT_666 所有, 如有侵权,请联系我们删除。