
文章目录
前言
因为实验室研究方向是image caption,所以最近开始阅读一些image caption的综述。
一、什么是image caption?
图像描述技术,就是以图像为输入,通过数学模型和计算使计算机输出对应图像的自然语言描述文字,使计算机拥有 “看图说话”的能力,是图像处理领域中继图像识别、图像分割和目标跟踪之后的又一新型任务.。
在日常生活中,人们可以将图像中的场景、色彩、逻辑关系等低层视觉特征信息自动建立关系,从而感知图像的高层语义信息,但是计算机作为工具只能提取到数字图像的低层数据特征,而无法像人类大脑一样生成高层语义信息,这就是计算机视觉中的“语义鸿沟”问题.图像描述(字幕)技术(Image Caption Generation)的本质就是将计算机提取的图像视觉特征转化为高层语义信息,即解决“语义鸿沟”问题,使计算机生成与人类大脑理解相近的对图像的文字描述,从而可以对图像进行分类、检索、分析等处理任务。
二、基于深度学习的图像描述方法
近年来,随着深度学习技术的不断发展,神经网络在计算机视觉和自然语言处理领域得到了广泛应用.受机器翻译领域中编码器-解码器(Encoder-Decoder)模型的启发,图像描述可以通过端到端的学习方法直接实现图像和描述句子之间的映射,将图像描述过程转化成为图像到描述的“翻译”过程。深度学习方法可以直接从大量数据中学习图像到描述语句的映射,生成更加准确的描述,其性能远远超过传统方法。
1.基于编码器-解码器的方法
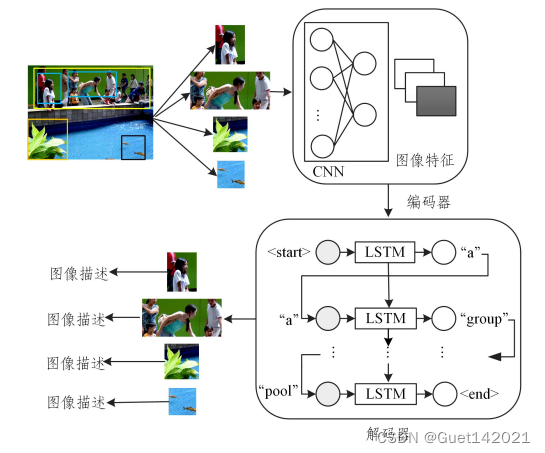
基于深度学习的图像描述生成方法大多采用以CNN-RNN为基本模型的编码器-解码器框架,CNN决定了整个模型的图像识别能力,其最后的隐藏层的输出被用作解码器的输入,RNN是用来读取编码后的图像并生成文本描述的网络模型,如图所示
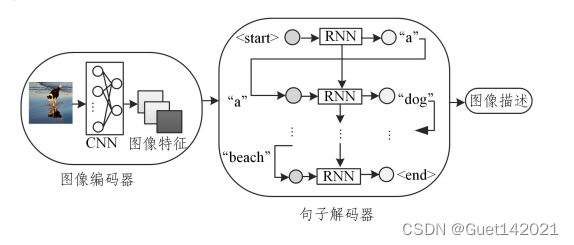
参考论文:MAOJH,XU W,YANG Y,etal.Deep captioning with multi-modal recurrent neural networks (m-RNN)
VINYALSO,TOSHEV A,BENGIOS,etal.Showandtell:A neural image caption generator
2.基于注意力机制的方法
随着深度学习的发展,注意力机制被广泛应用于计算机视觉领域,其本质是为了解决编码器-解码器在处理固定长度向量时的局限性.注意力机制并不是将输入序列编码成一个固定向量,而是通过增加一个上下文向量来对每个时间步的输入进行解码,以增强图像区域和单词的相关性,从而获取更多的图像语义细节。
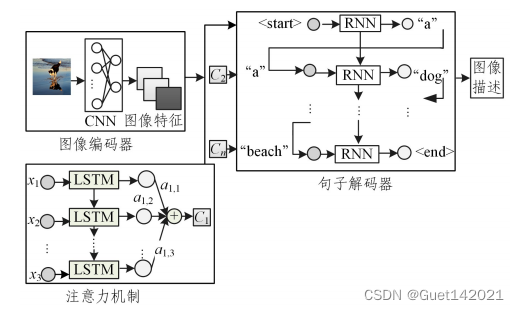
参考论文:XU K,BA JL,KIROS R,etal.Show,attendandtell:Neural image caption generation with visual attention
LU JS,XIONG C M,DEVIP,etal.Knowing whentolook: Adaptive attention via a visual sentinel for image captioning(自适应注意力机制)
3.基于生成对抗网络的方法
生成对抗网络模型中至少有两个模块:生成网络和判别网络.在训练过程中,生成网络生成尽量真实的数据以“欺骗”判别网络,并且通过判别网络的损失不断进行学习;而判别网络的任务就是区分生成的数据和真实数据.这两个网络通过动态的博弈学习,可以从无标签的数据中学习特征,从而生成新的数据.Dai等在2017年使用生成对抗网络通过控制随机噪声向量来生成多样化的描述.该模型分为两部分(如图所示):第一部分是句子生成部分,在该部分中依然使用CNN来提取图像特征,使用LSTM来生成句子,区别是在生成单词时加入了随机噪声,并在描述句生成完成后将其输入到第二部分的判别器进行评估.第二部分用来做句子评估,使用LSTM对句子进行编码,与图像特征一起处理获得一个概率值,评估该描述句是否与人类描述相似,是否符合图像内容,最后使用策略梯度方法反向传播更新参数,使其获得最大的概率值,直到输出理想的描述句。
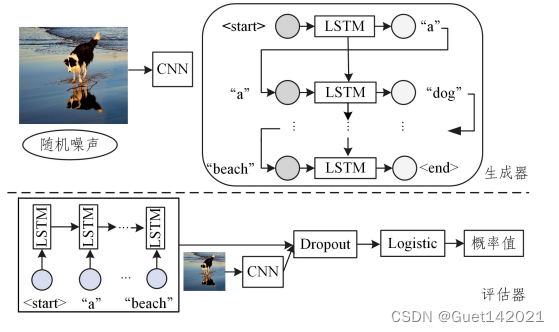
参考论文:DAIB,SANJAF,RAQUELU,etal.Towards Diverse and Natural Image Descriptions via a Conditional GAN
CHENF H,JIR R,SUN XS,etal.GroupCap:Group-Based Image Captioning with Structured Relevance and Diversity Constraint
4.基于强化学习的方法
强化学习也是机器学习领域中重要的方法之一。在强化学习中,智能体(Agent)以尝试的方式与环境之间不断交互,如图所示。在交互过程中,环境的状态由于智能体的动作而发生改变,并且环境将奖赏和当前时间的状态作为强化信号反馈到智能体,智能体在强化信号的作用下改变其在环境中的动作,可以针对具体的问题实施特定的动作策略,旨在获取最大的奖赏。在图像描述任务中,强化学习可以解决在训练和预测过程中解码器的不同参数带来的解码(曝光)偏差的问题,并且在训练时通过反向传播算法对模型进行训练优化,从而解决训练和测评指标不匹配的问题。
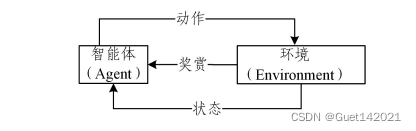
参考论文:LIUSQ,ZHUZH,YEN,etal.Improved Image Captioning via Policy Gradient optimization of SPIDE
5.基于密集描述的方法
基于密集描述的图像描述方法就是将图像描述分解为多个图像区域描述,当描述一个物体时,可以看作目标识别,当描述很多物体或一幅图像时,就是图像描述,如图所示。
参考论文:YANGLJ,TANG K,YANGJC,etal.Dense captioning with joint inference and visual context
总结
图像描述技术已被广泛应用于智能信息传播、智慧家居和智慧交通等领域,对人们的日常生活有着重要的实际意义,将来图像描述任务在深度学习和人工智能领域仍是一个重要的研究方向。
版权归原作者 詹姆斯德1 所有, 如有侵权,请联系我们删除。