
哈喽!!各位看官老爷,多日不见。各位还好吗?反正对方我很不好(在没有更新的时间,对方我啊!真的太忙碌了),到现在才有一点点的时间进行创作。以下内容是对于在虚拟机中配置Hadoop的文件系统配置。希望可以帮到各位,以下内容是只有配置的思路和具体的配置过程。有一些内容还需要各位看官老爷自行手动进行。如若有帮助还望支持对于后续的Hadoop系类如(mapreduce\yarn等都可以进行讲解)因为这一系类的都是以动手为主,所有不多说废话进入正题。
- 在虚拟机中将的虚拟网络编辑器中将虚拟网卡设置为:
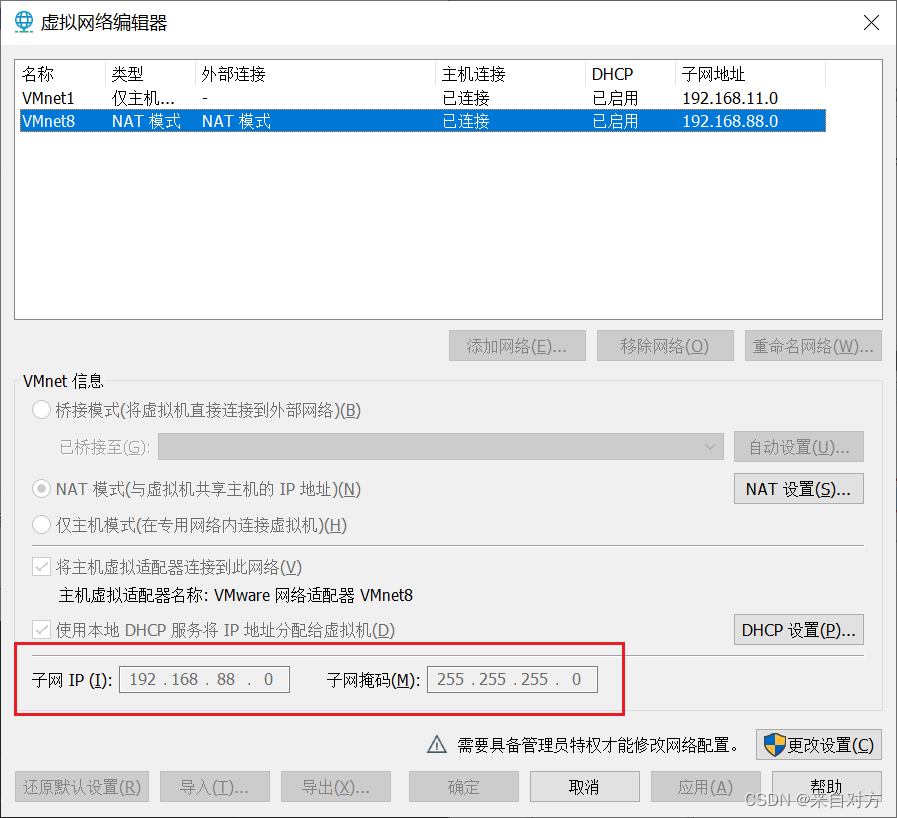
子网:192.168.88.0
子网掩码:255.255.255.0
NAT****设置为:192.168.88.2

- 安装虚拟机:
这一部分不做展示:如需请自行上网查找。
- 克隆虚拟机为3台:
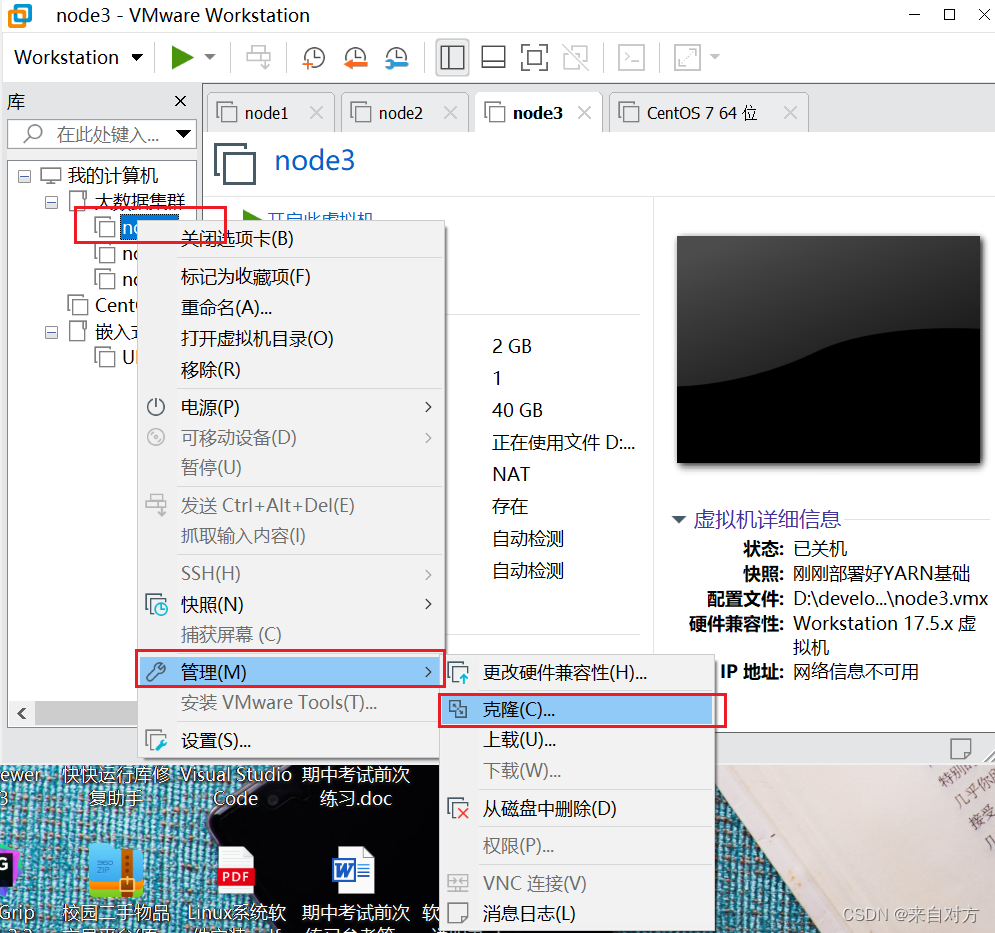
点击下一步即可:但要注意选择第二个

最后克隆完成为:

最后对CPU和内存进行如下配置:

- 修改主机名(root):
通过以下方法修改3台虚拟机名

修改IP地址:

并修改成图所示
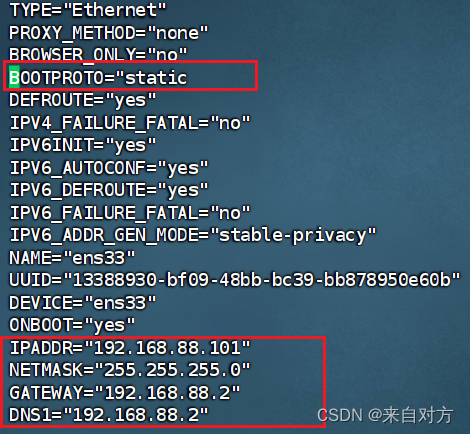
重启网卡并通过ifconfig进行查看:

同样的操作执行到剩下的虚拟机中
- 配置主机名映射
在Windows系统中修改hosts文件,填入图中内容:
通过记事本打开填入内容:

如果看不见记得勾选如下内容:
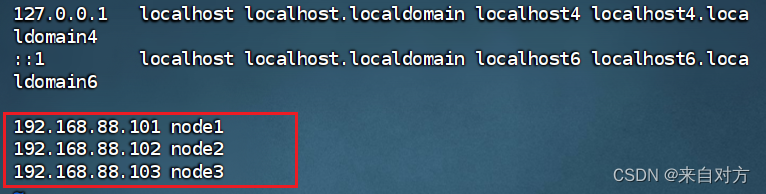
在3台linux的/etc/hosts中配置如下内容:

- 配置SSH免密登录
在每台虚拟机中使用ssh-keygen -t ras -b 4096,一路回车通用即可

通过如下内容进行验证
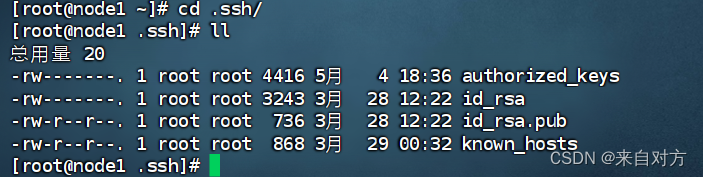
验证成功后在每台虚拟机汇总执行如下内容

可以通过ssh 进行验证
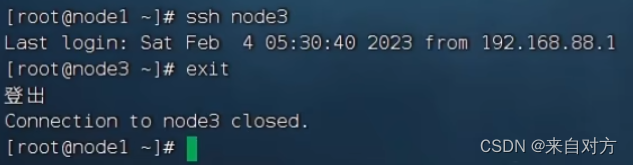
- 创建hadoop用户并配置免密登录
在每台3虚拟机中执行:useradd hadoop,创建hadoop用户
在每台3虚拟机中执行passwd hadoop,设置hadoop用户密码为:(自行设置)
在每一台虚拟机中进行却换到hadoop用户:su – Hadoop,并 执行ssh-keygen -t rsa -b 4096,创建ssh密钥
每一台虚拟机都执行
最后的展示结果为:

- 配置JDK环境
进入官网下载JDK

创建文件夹用于部署JDK

解压JDK文件到上述文件地
Tar -zxvf jdk-8u351-linux-x64.tar.gz -C /export/server
配置JDK软连接
Ln -s /export/server/jdk1.8.0_351 /export/server/jdk
最后的显示为
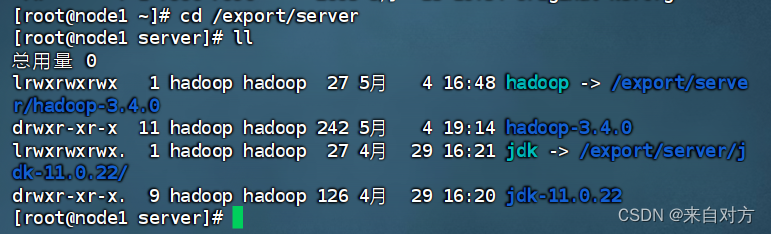
配置JAVA_home环境变量,添加到PATH环境变量中

最后的展示结果为
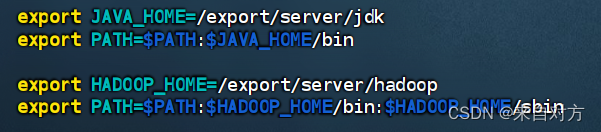
生效环境变量

配置java执行程序的软连接

验证展示

运用scp指令将部署好的jdk部署到其他虚拟机中

进行到其他虚拟机中进行软连接
重复以上软连接和创建文件夹即可
然后将之间的环境复制到虚拟机中并生效环境变量
重复以上步骤即可
- 关闭防火墙和SElinux
在每台虚拟机中执行
避免出现网络不通的问题


然后关闭SElinux功能,避免导致后面软件运行出现问题
在每台虚拟机中进行如下内容



最后重启虚拟机
- 修改时区配置制动时间同步
每台虚拟机都要修改配置
安装ntp软件

删除旧的时间

更新时区

同步时间

开启ntp服务并设置开机自启


最后如果以上没有出现问题,记得要进行虚拟机快照拍摄
- 开始进行虚拟机部署HDFS(下载hadoop安装包)
进入到https://hadoop.apache.org进行下载tar.gz安装包
部署规则为:
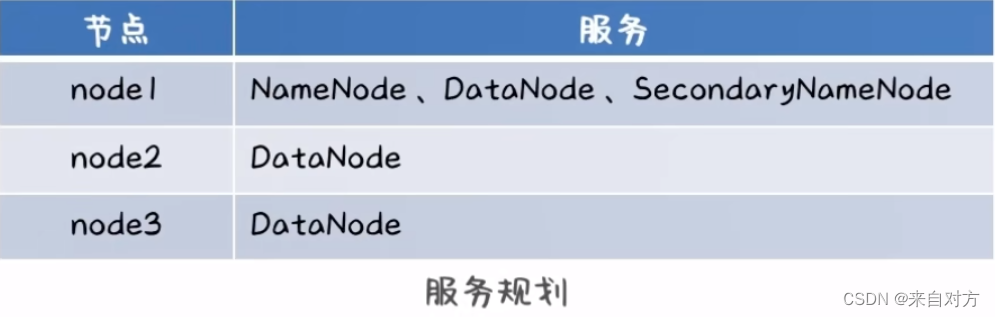
- 上传与解压
上传hadoop安装包到node1节点中
解压压缩包安装包到/export/server/中

构建软连接

最后的结果如下:

进入到hadoop安装包内

- 进入到hadoop修改配置文件,


- 配置workers文件,应用自定义设置

进行到workers文件中进行如下内容配置
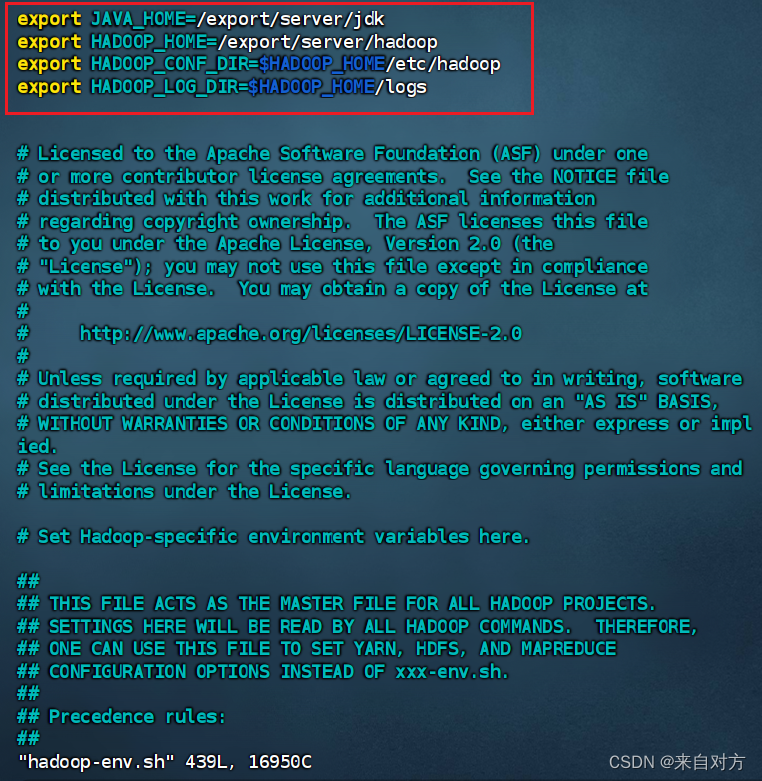
- 配置hadoop-env.sh
进入到hadooop-env.sh

配置如下内容
- 配置core-site.xml文件
进入到core-site.xml

配置如下内容

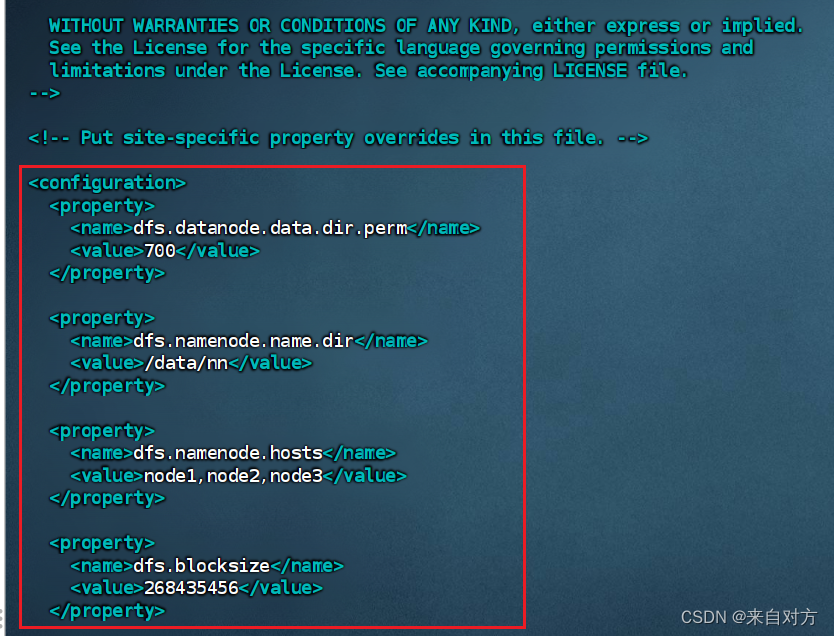
- 配置hdfs-site.xml(配置较大,如果不对,还请到网上自行搜索)
进行到hdfs-site.xml
配置如下内容
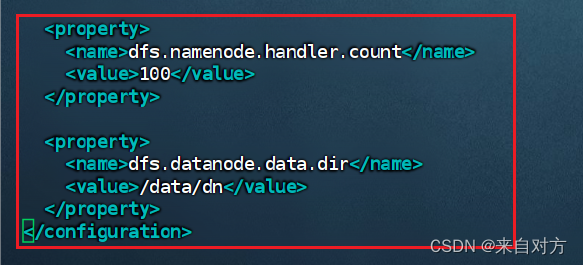
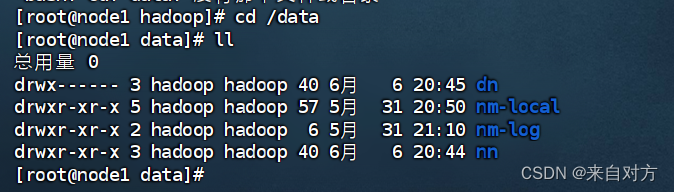
- 准备数据目录
用于存放节点数据

- 分发haadoop文件夹
使用远程复制到node2和node3

结果如下:
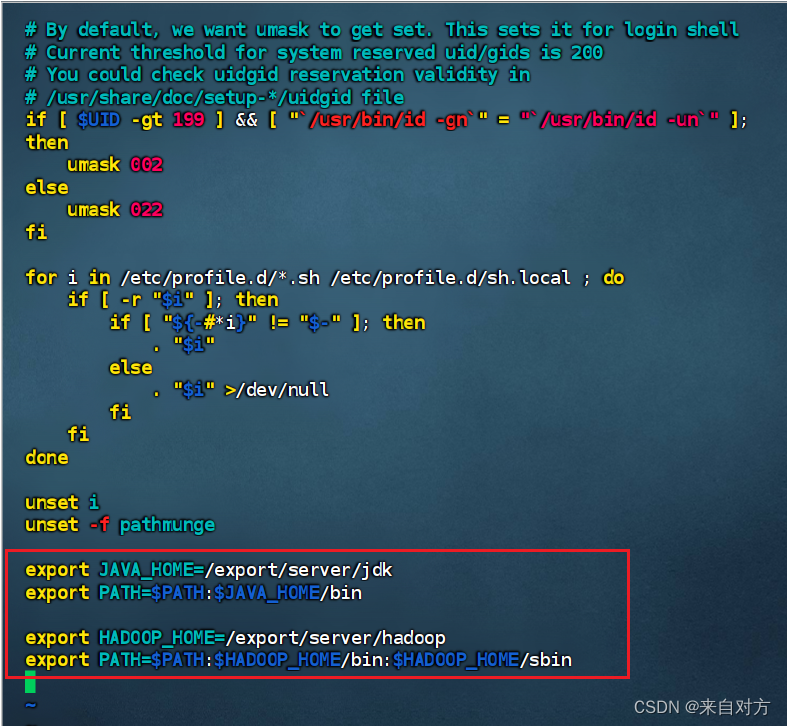
- 配置环境变量
进入到/etc/profile

配置内容如下
刷新/etc/profile

进入到其他虚拟机中进行上述操作即可
- 授权为hadoop用户

进入到其他虚拟机中进行上述操作即可
- 格式化整个文件系统
在hadoop用户中进行格式化(不要格式出错了)
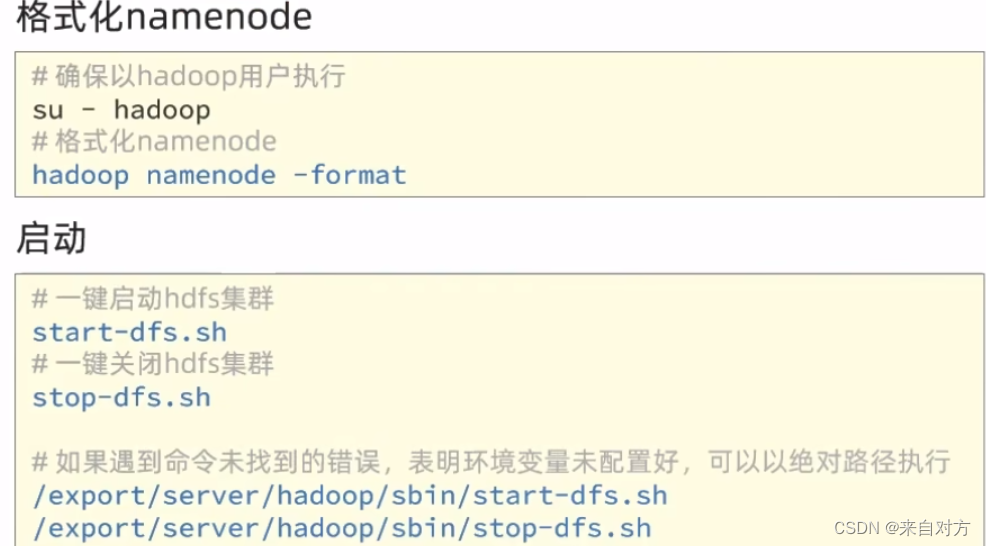
验证是否格式化成功(有数据就是才成功了)

- 启动hdfs

- 查看hdfs webui
https://nide1:9870,即可查看hdfs文件系统的管理网页


到了这里,就说明hdfs的文件系统成功了!!!
---------------------------------------------------------------------------------------------------------------------------------如果各位看官老爷都可以配置到最后一步了,那么各位看官老爷可以对于HDFS文件系统有了一个深刻的了解。
版权归原作者 来自对方 所有, 如有侵权,请联系我们删除。