
在本文中,我想分享我使用 GraalVM 为 EmbeddedKafka 创建本机映像的经验。在集成测试中使用此映像不仅可以加快测试场景的执行速度,还可以减少内存消耗。有趣的是,与在 Testcontainers 中使用 **confluentinc/cp-kafka** 相比,在速度和内存使用方面存在明显差异

EmbeddedKafka、Testcontainers 和 GraalVM
项目中使用的关键组件的简要概述:
EmbeddedKafka
EmbeddedKafka 是一种允许将 Kafka 服务器直接嵌入到 JVM 应用程序或测试环境中的工具。这对于使用 Apache Kafka 进行数据流处理或作为消息传递系统的应用程序的集成测试非常有用。EmbeddedKafka 主要用于与 Kafka 交互的隔离测试,由于其快速启动和关闭,因此简化了测试的设置和管理。这确保了测试在不同环境中的可重复性,并提供了对 Kafka 配置的控制。但是,由于 Kafka 的资源密集型特性和对数据存储的需求,在 JVM 应用程序中运行嵌入式 Kafka 会增加内存使用量。这是在开发便利性和额外内存负载之间的权衡,使得外部 Kafka 服务器(相对于 JVM 应用程序)更适合生产环境或内存资源有限的情况。
Testcontainers
Testcontainers 是一个框架,用于支持使用 Docker 容器的自动集成测试。它允许在测试执行期间创建、管理和删除容器。使用 Docker 容器可确保测试环境在不同机器和平台上的一致性,从而简化本地开发和测试。在 Testcontainers 中使用 Kafka 有几个优点,尤其是在更真实、更灵活的环境中进行测试时。Testcontainers 基于官方 Confluent OSS 平台镜像运行 Kafka 实例。
GraalVM
GraalVM是一个用于运行程序的平台,支持各种编程语言和技术。除其他外,它还允许将 Java 应用程序编译为静态链接的可执行文件(本机二进制文件)。这些本机可执行文件运行速度更快,需要更少的内存,并且不需要安装 JVM。
测试场景
为了说明编写测试的方法,我准备了与一个简单的测试场景相对应的代码示例:
- 向主题 topic1 发送消息 value1。
- 阅读主题 topic1 中的消息。
- 验证该值是否等于 value1。
示例可以在项目存储库中找到:
- 使用 EmbeddedKafka 的测试位于 example-spring-embedded-kafka 模块中。
- 使用 Testcontainers 的测试位于 example-testcontainers 模块中。
存储库结构有助于比较模块,以评估使用每种方法时代码结构和组合的差异。
将 EmbeddedKafka 包装在容器中
第一个任务是在单独的容器中实现 EmbeddedKafka 的启动。为此,我采取了以下简单步骤:
- 使用 Spring Initializr 创建了标准的 Spring Boot 应用程序。
- 在应用程序中,我设置了具有必要参数的类实例的启动。
org.springframework.kafka.test.EmbeddedKafkaZKBroker - 描述了 Dockerfile 并构建了映像
以上所有操作都反映在项目仓库中 emk-application 模块的代码中。
在容器中启动 EmbeddedKafka
Testcontainers 文档提供了使用以下类启动 Kafka 容器的指南:
KafkaContainer
KafkaContainer kafka = new KafkaContainer(DockerImageName.parse("confluentinc/cp-kafka:6.2.1"))
但是,这个类不适合我的需求,因为它旨在与 **confluentinc/cp-kafka** 兼容映像一起使用。尽管如此,检查它是有益的,因为它揭示了围绕参数处理的有趣逻辑:
KAFKA_ADVERTISED_LISTENERS
- 在容器开始时,执行 / 指令的替换。
ENTRYPOINT``````COMMAND - 启动后,参数将与启动 Kafka 的说明一起传递到容器。
KAFKA_ADVERTISED_LISTENERS
此过程在附图中进行了详细说明。
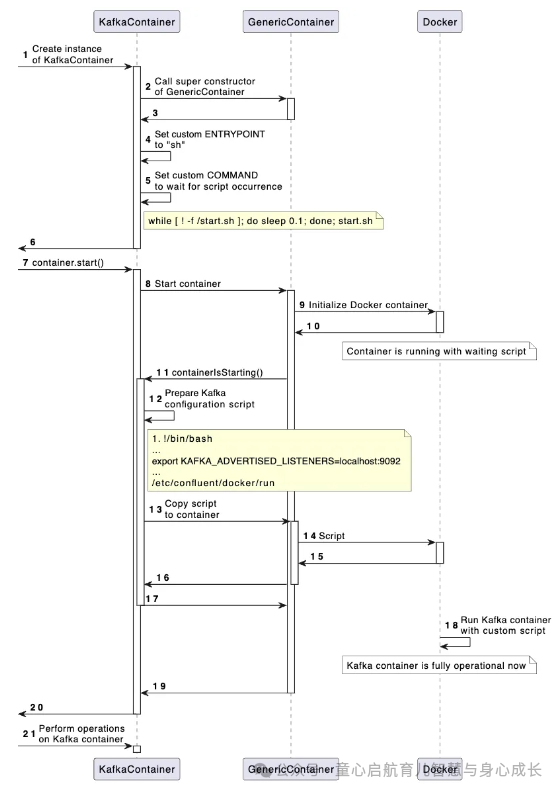
为什么有必要这样做?在运行过程中,客户端可以连接到任何 Kafka 节点以获取执行读/写操作的地址,即使 Kafka 由单个节点表示。外部用户需要外部地址,内部用户也需要内部地址。通过指定 ,我们向代理提供有关其外部地址的信息,然后代理将其传达给客户端。客户端相对于代理而言是外部的,因为代理在容器中运行。
KAFKA_ADVERTISED_LISTENERS
我在一个新类中实现了上面描述的逻辑:EmbeddedKafkaContainer.java。
为 EmbeddedKafka 创建本机映像
为 GraalVM 启动新的 Spring Boot 项目的最简单方法是访问站点 start.spring.io,添加“GraalVM Native Support”依赖项,然后生成项目。该项目附带一个 HELP.md 文件,它提供了有用的入门提示。
元数据收集
用于构建本机映像的工具依赖于在应用程序代码执行期间可用的静态分析。但是,这种分析并不总是能够完全预测 Java 本机接口 (JNI)、Java 反射、动态代理对象等的所有用例。因此,需要以元数据的形式向原生映像构建工具显式指定动态函数的这些用例。提供此类元数据的一种方法是通过放置在项目目录 **META-INF/native-image/<group.id>/<artifact.id>** 中的 JSON 文件。
GraalVM 提供了一个跟踪代理,用于方便地收集元数据和准备配置文件。此代理跟踪应用程序在标准 Java VM 上执行期间动态函数使用的所有实例。
我的方法如下:
- 我在 JVM 下启动了一个带有嵌入式 Kafka 的 Spring 应用程序实例,并带有跟踪代理。
- 我从我的一个项目中运行了大量测试,使用已启动的应用程序作为主要的 Kafka 代理。
在此过程中生成的文件被放置在项目目录 META-INF/native-image 中。
启动和使用
为了演示结果,我准备了以下工件:
- 类为:pw.avvero:emk-testcontainers:1.0.1 的库
EmbeddedKafkaContainer - Docker 镜像:(JVM) 和 (native, platform=linux/arm64)
avvero/emk``````avvero/emk-native - 可以在 example-embedded-kafka-container 模块中找到与测试场景相对应的示例用法。
KafkaContainerConfiguration 的配置如下:
@TestConfiguration(proxyBeanMethods = false)
public class KafkaContainerConfiguration {
@Bean
@RestartScope
@ServiceConnection
EmbeddedKafkaContainer kafkaContainer() {
return new EmbeddedKafkaContainer("avvero/emk-native:1.0.0");
}
}
为了评估内存利用率,我从我的一个项目中运行了大约 7 分钟的测试。根据 **docker stats** 的观察,我注意到内存消耗的以下趋势:
confluentinc/cp-kafka:7.3.31.331GiBAVVERO/EMK677.3米Bavvero/emk-native126.4米B
使用GCeasy通过GC日志进行内存分析(Young + Old + Meta空间),结果如下:
confluentinc/cp-kafka:7.3.31.06 GB/866.92 MB(已分配/峰值)AVVERO/EMK567.62 MB/241.74 MB(已分配/峰值)avvero/emk-native20.00米 -> 15.50米?
分析本机映像的 GC 日志是一项更复杂的任务,因为数据的格式和组成与“标准”GC 日志不同。不幸的是,我找不到适合此目的的分析工具,可以提供现成的分析。因此,下面是日志的片段,它有助于估计我例中内存利用率的一般顺序。
[497.519s] GC(11371) Collect on allocation
[497.520s] GC(11371) Eden: 4.50M->0.00M
[497.520s] GC(11371) Survivor: 0.00M->0.00M
[497.520s] GC(11371) Old: 15.50M->15.50M
[497.520s] GC(11371) Free: 3.50M->8.00M
[497.520s] GC(11371) Incremental GC (Collect on allocation) 20.00M->15.50M 0.896ms
GC 日志文件附加到性能测试模块。
关于启动时间,我使用 JMH 进行了一系列性能测试,以评估不同 Kafka 容器配置的启动时间和操作准备情况:
testContainersKafkaStartAndReady- 使用 confluentinc/cp-kafka 测试容器:7.3.3emkJvmKafkaStartAndReady- avvero/emk (JVM)emkNativeKafkaStartAndReady- avvero/emk-native(原生,platform=linux/arm64)测试的重点是验证启动和准备情况。仅仅启动一个 Kafka 容器并不总是意味着它已准备好运行。就绪情况检查模拟了一个真实场景,在这个场景中,Kafka 不仅已启动,而且还已完全准备好运行。这样可以更全面地了解 Kafka 在各种容器化环境中完全运行所需的时间。
性能测试结果如下:
Benchmark Mode Cnt Score Error Units
TestContainersBenchmark.testContainersKafkaStartAndReady ss 10 3,091 ± 0,354 s/op
TestContainersBenchmark.emkJvmKafkaStartAndReady ss 10 2,659 ± 0,708 s/op
TestContainersBenchmark.emkNativeKafkaStartAndReady ss 10 0,521 ± 0,055 s/op
** avvero/emk-native:1.0.0** 容器表现出更高的性能,平均启动和就绪检查时间仅为 0.521 秒,偏差为 ±0,055
在集成测试中使用 EmbeddedKafka 和 GraalVM 的本机映像可以加快测试启动时间并减少内存消耗,与传统方法(例如在 Testcontainers 中使用 **confluentinc/cp-kafka**)相比,它是一种有效的解决方案。
GraalVM 的使用为旨在提高集成测试性能和效率的开发人员开辟了新的机会。这种方法可以针对其他类似的任务和技术进行调整和扩展,这突显了其在软件开发领域的多功能性和潜力。
版权归原作者 晨曦_子画 所有, 如有侵权,请联系我们删除。