
案例需求分析
直播公司每日都会产生海量的直播数据,为了更好地服务主播与用户,提高直播质量与用户粘性,往往会对大量的数据进行分析与统计,从中挖掘商业价值,我们将通过一个实战案例,来使用Hadoop技术来实现对直播数据的统计与分析。下面是简化的日志文件,详细的我会更新在Gitee hadoop_study/hadoopDemo1 · Huathy/study-all/
{"id":"1580089010000","uid":"12001002543","nickname":"jack2543","gold":561,"watchnumpv":1697,"follower":1509,"gifter":2920,"watchnumuv":5410,"length":3542,"exp":183}{"id":"1580089010001","uid":"12001001853","nickname":"jack1853","gold":660,"watchnumpv":8160,"follower":1781,"gifter":551,"watchnumuv":4798,"length":189,"exp":89}{"id":"1580089010002","uid":"12001003786","nickname":"jack3786","gold":14,"watchnumpv":577,"follower":1759,"gifter":2643,"watchnumuv":8910,"length":1203,"exp":54}
原始数据清洗代码
- 清理无效记录:由于原始数据是通过日志方式进行记录的,在使用日志采集工具采集到HDFS后,还需要对数据进行清洗过滤,丢弃缺失字段的数据,针对异常字段值进行标准化处理。
- 清除多余字段:由于计算时不会用到所有的字段。
编码
DataCleanMap
packagedataClean;importcom.alibaba.fastjson.JSON;importcom.alibaba.fastjson.JSONObject;importorg.apache.commons.lang3.StringUtils;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importjava.io.IOException;/**
* @author Huathy
* @date 2023-10-22 22:15
* @description 实现自定义map类,在里面实现具体的清洗逻辑
*/publicclassDataCleanMapextendsMapper<LongWritable,Text,Text,Text>{/**
* 1. 从原始数据中过滤出来需要的字段
* 2. 针对核心字段进行异常值判断
*
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/@Overrideprotectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{String valStr = value.toString();// 将json字符串数据转换成对象JSONObject jsonObj =JSON.parseObject(valStr);String uid = jsonObj.getString("uid");// 这里建议使用getIntValue(返回0)而不是getInt(异常)。int gold = jsonObj.getIntValue("gold");int watchnumpv = jsonObj.getIntValue("watchnumpv");int follower = jsonObj.getIntValue("follower");int length = jsonObj.getIntValue("length");// 过滤异常数据if(StringUtils.isNotBlank(valStr)&&(gold * watchnumpv * follower * length)>=0){// 组装k2,v2Text k2 =newText();
k2.set(uid);Text v2 =newText();
v2.set(gold +"\t"+ watchnumpv +"\t"+ follower +"\t"+ length);
context.write(k2, v2);}}}
DataCleanJob
packagedataClean;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/**
* @author Huathy
* @date 2023-10-22 22:02
* @description 数据清洗作业
* 1. 从原始数据中过滤出来需要的字段
* uid gold watchnumpv(总观看)、follower(粉丝关注数量)、length(总时长)
* 2. 针对以上五个字段进行判断,都不应该丢失或为空,否则任务是异常记录,丢弃。
* 若个别字段丢失,则设置为0.
* <p>
* 分析:
* 1. 由于原始数据是json格式,可以使用fastjson对原始数据进行解析,获取指定字段的内容
* 2. 然后对获取到的数据进行判断,只保留满足条件的数据
* 3. 由于不需要聚合过程,只是一个简单的过滤操作,所以只需要map阶段即可,不需要reduce阶段
* 4. 其中map阶段的k1,v1的数据类型是固定的<LongWritable,Text>,k2,v2的数据类型是<Text,Text>k2存储主播ID,v2存储核心字段
* 中间用\t制表符分隔即可
*/publicclassDataCleanJob{publicstaticvoidmain(String[] args)throwsException{System.out.println("inputPath => "+ args[0]);System.out.println("outputPath => "+ args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration =newConfiguration();// 创建jobJob job =Job.getInstance(configuration,"wordCountJob");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类
job.setJarByClass(DataCleanJob.class);// 指定输入文件FileInputFormat.setInputPaths(job,newPath(path));FileOutputFormat.setOutputPath(job,newPath(path2));// 指定map相关配置
job.setMapperClass(DataCleanMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);// 指定reduce 数量0,表示禁用reduce
job.setNumReduceTasks(0);// 提交任务
job.waitForCompletion(true);}}
运行
## 运行命令[root@cent7-1 hadoop-3.2.4]# hadoop jar hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar dataClean.DataCleanJob hdfs://cent7-1:9000/data/videoinfo/231022 hdfs://cent7-1:9000/data/res231022
inputPath => hdfs://cent7-1:9000/data/videoinfo/231022
outputPath => hdfs://cent7-1:9000/data/res231022
2023-10-22 23:16:15,845 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2023-10-22 23:16:16,856 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2023-10-22 23:16:17,041 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1697985525421_0002
2023-10-22 23:16:17,967 INFO input.FileInputFormat: Total input files to process :12023-10-22 23:16:18,167 INFO mapreduce.JobSubmitter: number of splits:1
2023-10-22 23:16:18,873 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1697985525421_0002
2023-10-22 23:16:18,874 INFO mapreduce.JobSubmitter: Executing with tokens: []2023-10-22 23:16:19,157 INFO conf.Configuration: resource-types.xml not found
2023-10-22 23:16:19,158 INFO resource.ResourceUtils: Unable to find'resource-types.xml'.2023-10-22 23:16:19,285 INFO impl.YarnClientImpl: Submitted application application_1697985525421_0002
2023-10-22 23:16:19,345 INFO mapreduce.Job: The url to track the job: http://cent7-1:8088/proxy/application_1697985525421_0002/
2023-10-22 23:16:19,346 INFO mapreduce.Job: Running job: job_1697985525421_0002
2023-10-22 23:16:31,683 INFO mapreduce.Job: Job job_1697985525421_0002 running in uber mode :false2023-10-22 23:16:31,689 INFO mapreduce.Job: map 0% reduce 0%
2023-10-22 23:16:40,955 INFO mapreduce.Job: map 100% reduce 0%
2023-10-22 23:16:43,012 INFO mapreduce.Job: Job job_1697985525421_0002 completed successfully
2023-10-22 23:16:43,153 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=238970
FILE: Number of readoperations=0
FILE: Number of large readoperations=0
FILE: Number of writeoperations=0
HDFS: Number of bytes read=24410767
HDFS: Number of bytes written=1455064
HDFS: Number of readoperations=7
HDFS: Number of large readoperations=0
HDFS: Number of writeoperations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7678
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=7678
Total vcore-milliseconds taken by all map tasks=7678
Total megabyte-milliseconds taken by all map tasks=7862272
Map-Reduce Framework
Map input records=90000
Map output records=46990
Input splitbytes=123
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=195
CPU time spent (ms)=5360
Physical memory (bytes)snapshot=302153728
Virtual memory (bytes)snapshot=2588925952
Total committed heap usage (bytes)=214958080
Peak Map Physical memory (bytes)=302153728
Peak Map Virtual memory (bytes)=2588925952
File Input Format Counters
Bytes Read=24410644
File Output Format Counters
Bytes Written=1455064[root@cent7-1 hadoop-3.2.4]# ## 统计输出文件行数[root@cent7-1 hadoop-3.2.4]# hdfs dfs -cat hdfs://cent7-1:9000/data/res231022/* | wc -l46990## 查看原始数据记录数[root@cent7-1 hadoop-3.2.4]# hdfs dfs -cat hdfs://cent7-1:9000/data/videoinfo/231022/* | wc -l90000
数据指标统计
- 对数据中的金币数量,总观看PV,粉丝关注数量,视频总时长等指标进行统计(涉及四个字段为了后续方便,可以自定义Writable)
- 统计每天开播时长最长的前10名主播以及对应的开播时长
自定义Writeable代码实现
由于原始数据涉及多个需要统计的字段,可以将这些字段统一的记录在一个自定义的数据类型中,方便使用
packagevideoinfo;importorg.apache.hadoop.io.Writable;importjava.io.DataInput;importjava.io.DataOutput;importjava.io.IOException;/**
* @author Huathy
* @date 2023-10-22 23:32
* @description 自定义数据类型,为了保存主播相关核心字段,方便后期维护
*/publicclassVideoInfoWriteableimplementsWritable{privatelong gold;privatelong watchnumpv;privatelong follower;privatelong length;publicvoidset(long gold,long watchnumpv,long follower,long length){this.gold = gold;this.watchnumpv = watchnumpv;this.follower = follower;this.length = length;}publiclonggetGold(){return gold;}publiclonggetWatchnumpv(){return watchnumpv;}publiclonggetFollower(){return follower;}publiclonggetLength(){return length;}@Overridepublicvoidwrite(DataOutput dataOutput)throwsIOException{
dataOutput.writeLong(gold);
dataOutput.writeLong(watchnumpv);
dataOutput.writeLong(follower);
dataOutput.writeLong(length);}@OverridepublicvoidreadFields(DataInput dataInput)throwsIOException{this.gold = dataInput.readLong();this.watchnumpv = dataInput.readLong();this.follower = dataInput.readLong();this.length = dataInput.readLong();}@OverridepublicStringtoString(){return gold +"\t"+ watchnumpv +"\t"+ follower +"\t"+ length;}}
基于主播维度 videoinfo
VideoInfoJob
packagevideoinfo;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/**
* @author Huathy
* @date 2023-10-22 23:27
* @description 数据指标统计作业
* 1. 基于主播进行统计,统计每个主播在当天收到的总金币数量,总观看PV,总粉丝关注量,总视频开播市场
* 分析
* 1. 为了方便统计主播的指标数据吗,最好是把这些字段整合到一个对象中,这样维护方便
* 这样就需要自定义Writeable
* 2. 由于在这里需要以主播维度进行数据的聚合,所以需要以主播ID作为KEY,进行聚合统计
* 3. 所以Map节点的<k2,v2>是<Text,自定义Writeable>
* 4. 由于需要聚合,所以Reduce阶段也需要
*/publicclassVideoInfoJob{publicstaticvoidmain(String[] args)throwsException{System.out.println("inputPath => "+ args[0]);System.out.println("outputPath => "+ args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration =newConfiguration();// 创建jobJob job =Job.getInstance(configuration,"VideoInfoJob");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类
job.setJarByClass(VideoInfoJob.class);// 指定输入文件FileInputFormat.setInputPaths(job,newPath(path));FileOutputFormat.setOutputPath(job,newPath(path2));// 指定map相关配置
job.setMapperClass(VideoInfoMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);// 指定reduce
job.setReducerClass(VideoInfoReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);// 提交任务
job.waitForCompletion(true);}}
VideoInfoMap
packagevideoinfo;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importjava.io.IOException;/**
* @author Huathy
* @date 2023-10-22 23:31
* @description 实现自定义Map类,在这里实现核心字段的拼接
*/publicclassVideoInfoMapextendsMapper<LongWritable,Text,Text,VideoInfoWriteable>{@Overrideprotectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{// 读取清洗后的每一行数据String line = value.toString();String[] fields = line.split("\t");String uid = fields[0];long gold =Long.parseLong(fields[1]);long watchnumpv =Long.parseLong(fields[1]);long follower =Long.parseLong(fields[1]);long length =Long.parseLong(fields[1]);// 组装K2 V2Text k2 =newText();
k2.set(uid);VideoInfoWriteable v2 =newVideoInfoWriteable();
v2.set(gold, watchnumpv, follower, length);
context.write(k2, v2);}}
VideoInfoReduce
packagevideoinfo;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importorg.apache.hadoop.mapreduce.Reducer;importjava.io.IOException;/**
* @author Huathy
* @date 2023-10-22 23:31
* @description 实现自定义Map类,在这里实现核心字段的拼接
*/publicclassVideoInfoReduceextendsReducer<Text,VideoInfoWriteable,Text,VideoInfoWriteable>{@Overrideprotectedvoidreduce(Text key,Iterable<VideoInfoWriteable> values,Context context)throwsIOException,InterruptedException{// 从v2s中把相同key的value取出来,进行累加求和long goldSum =0;long watchNumPvSum =0;long followerSum =0;long lengthSum =0;for(VideoInfoWriteable v2 : values){
goldSum += v2.getGold();
watchNumPvSum += v2.getWatchnumpv();
followerSum += v2.getFollower();
lengthSum += v2.getLength();}// 组装k3 v3VideoInfoWriteable videoInfoWriteable =newVideoInfoWriteable();
videoInfoWriteable.set(goldSum, watchNumPvSum, followerSum, lengthSum);
context.write(key, videoInfoWriteable);}}
基于主播的TOPN计算
VideoInfoTop10Job
packagetop10;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Job;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/**
* @author Huathy
* @date 2023-10-23 21:27
* @description 数据指标统计作业
* 需求:统计每天开播时长最长的前10名主播以及时长信息
* 分析:
* 1. 为了统计每天开播时长最长的前10名主播信息,需要在map阶段获取数据中每个主播的ID和直播时长
* 2. 所以map阶段的k2 v2 为Text LongWriteable
* 3. 在reduce阶段对相同主播的时长进行累加求和,将这些数据存储到一个临时的map中
* 4. 在reduce阶段的cleanup函数(最后执行)中,对map集合的数据进行排序处理
* 5. 在cleanup函数中把直播时长最长的前10名主播信息写出到文件中
* setup函数在reduce函数开始执行一次,而cleanup在结束时执行一次
*/publicclassVideoInfoTop10Job{publicstaticvoidmain(String[] args)throwsException{System.out.println("inputPath => "+ args[0]);System.out.println("outputPath => "+ args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration =newConfiguration();// 从输入路径来获取日期String[] fields = path.split("/");String tmpdt = fields[fields.length -1];System.out.println("日期:"+ tmpdt);// 生命周期的配置
configuration.set("dt", tmpdt);// 创建jobJob job =Job.getInstance(configuration,"VideoInfoTop10Job");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类
job.setJarByClass(VideoInfoTop10Job.class);// 指定输入文件FileInputFormat.setInputPaths(job,newPath(path));FileOutputFormat.setOutputPath(job,newPath(path2));
job.setMapperClass(VideoInfoTop10Map.class);
job.setReducerClass(VideoInfoTop10Reduce.class);// 指定map相关配置
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);// 指定reduce
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);// 提交任务
job.waitForCompletion(true);}}
VideoInfoTop10Map
packagetop10;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Mapper;importjava.io.IOException;/**
* @author Huathy
* @date 2023-10-23 21:32
* @description 自定义map类,在这里实现核心字段的拼接
*/publicclassVideoInfoTop10MapextendsMapper<LongWritable,Text,Text,LongWritable>{@Overrideprotectedvoidmap(LongWritable key,Text value,Context context)throwsIOException,InterruptedException{// 读取清洗之后的每一行数据String line = key.toString();String[] fields = line.split("\t");String uid = fields[0];long length =Long.parseLong(fields[4]);Text k2 =newText();
k2.set(uid);LongWritable v2 =newLongWritable();
v2.set(length);
context.write(k2, v2);}}
VideoInfoTop10Reduce
packagetop10;importcn.hutool.core.collection.CollUtil;importorg.apache.commons.collections.CollectionUtils;importorg.apache.commons.collections.MapUtils;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.io.LongWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.Reducer;importjava.io.IOException;importjava.util.*;/**
* @author Huathy
* @date 2023-10-23 21:37
* @description
*/publicclassVideoInfoTop10ReduceextendsReducer<Text,LongWritable,Text,LongWritable>{// 保存主播ID和开播时长Map<String,Long> map =newHashMap<>();@Overrideprotectedvoidreduce(Text key,Iterable<LongWritable> values,Context context)throwsIOException,InterruptedException{String k2 = key.toString();long lengthSum =0;for(LongWritable v2 : values){
lengthSum += v2.get();}
map.put(k2, lengthSum);}/**
* 任务初始化的时候执行一次,一般在里面做一些初始化资源连接的操作。(mysql、redis连接操作)
*
* @param context
* @throws IOException
* @throws InterruptedException
*/@Overrideprotectedvoidsetup(Context context)throwsIOException,InterruptedException{System.out.println("setup method running...");System.out.println("context: "+ context);super.setup(context);}/**
* 任务结束的时候执行一次,做关闭资源连接操作
*
* @param context
* @throws IOException
* @throws InterruptedException
*/@Overrideprotectedvoidcleanup(Context context)throwsIOException,InterruptedException{// 获取日期Configuration configuration = context.getConfiguration();String date = configuration.get("dt");// 排序LinkedHashMap<String,Long> sortMap =CollUtil.sortByEntry(map,newComparator<Map.Entry<String,Long>>(){@Overridepublicintcompare(Map.Entry<String,Long> o1,Map.Entry<String,Long> o2){return-o1.getValue().compareTo(o2.getValue());}});Set<Map.Entry<String,Long>> entries = sortMap.entrySet();Iterator<Map.Entry<String,Long>> iterator = entries.iterator();// 输出int count =1;while(count <=10&& iterator.hasNext()){Map.Entry<String,Long> entry = iterator.next();String key = entry.getKey();Long value = entry.getValue();// 封装K3 V3Text k3 =newText(date +"\t"+ key);LongWritable v3 =newLongWritable(value);// 统计的时候还应该传入日期来用来输出统计的时间,而不是获取当前时间(可能是统计历史)!
context.write(k3, v3);
count++;}}}
任务定时脚本封装
任务依赖关系:数据指标统计(top10统计以及播放数据统计)依赖数据清洗作业
将任务提交命令进行封装,方便调用,便于定时任务调度
编写任务脚本,并以debug模式执行:
sh -x data_clean.sh
任务执行结果监控
针对任务执行的结果进行检测,如果执行失败,则重试任务,同时发送告警信息。
#!/bin/bash
# 建议使用bin/bash形式
# 判读用户是否输入日期,如果没有则默认获取昨天日期。(需要隔几天重跑,灵活的指定日期)
if [ "x$1" = "x" ]; then
yes_time=$(date +%y%m%d --date="1 days ago")
else
yes_time=$1
fi
jobs_home=/home/jobs
cleanjob_input=hdfs://cent7-1:9000/data/videoinfo/${yes_time}
cleanjob_output=hdfs://cent7-1:9000/data/videoinfo_clean/${yes_time}
videoinfojob_input=${cleanjob_output}
videoinfojob_output=hdfs://cent7-1:9000/res/videoinfoJob/${yes_time}
top10job_input=${cleanjob_output}
top10job_output=hdfs://cent7-1:9000/res/top10/${yes_time}
# 删除输出目录,为了兼容脚本重跑
hdfs dfs -rm -r ${cleanjob_output}
# 执行数据清洗任务
hadoop jar ${jobs_home}/hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
dataClean.DataCleanJob \
${cleanjob_input} ${cleanjob_output}
# 判断数据清洗任务是否成功
hdfs dfs -ls ${cleanjob_output}/_SUCCESS
# echo $? 可以获取上一个命令的执行结果0成功,否则失败
if [ "$?" = "0" ]; then
echo "clean job execute success ...."
# 删除输出目录,为了兼容脚本重跑
hdfs dfs -rm -r ${videoinfojob_output}
hdfs dfs -rm -r ${top10job_output}
# 执行指标统计任务1
echo " execute VideoInfoJob ...."
hadoop jar ${jobs_home}/hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
videoinfo.VideoInfoJob \
${videoinfojob_input} ${videoinfojob_output}
hdfs dfs -ls ${videoinfojob_output}/_SUCCESS
if [ "$?" != "0" ]
then
echo " VideoInfoJob execute failed .... "
fi
# 指定指标统计任务2
echo " execute VideoInfoTop10Job ...."
hadoop jar ${jobs_home}/hadoopDemo1-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
top10.VideoInfoTop10Job \
${top10job_input} ${top10job_output}
hdfs dfs -ls ${top10job_output}/_SUCCESS
if [ "$?" != "0" ]
then
echo " VideoInfoJob execute failed .... "
fi
else
echo "clean job execute failed ... date time is ${yes_time}"
# 给管理员发送短信、邮件
# 可以在while进行重试
fi
使用Sqoop将计算结果导出到MySQL
Sqoop可以快速的实现hdfs-mysql的导入导出
快速安装Sqoop工具
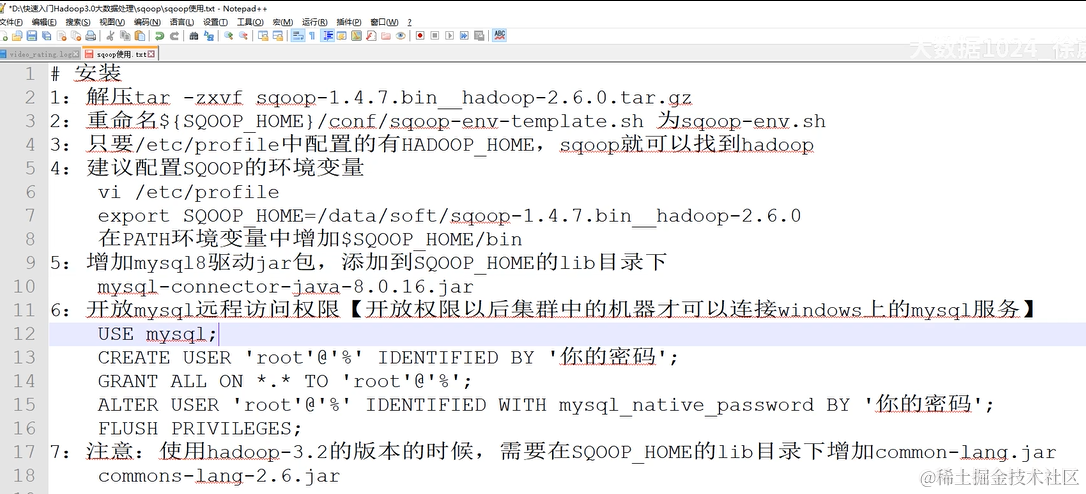
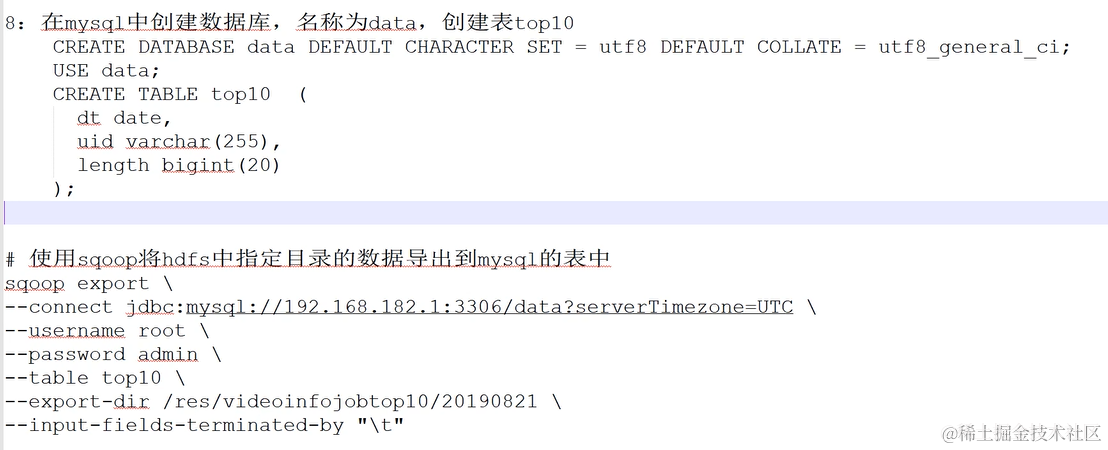
数据导出功能开发,使用Sqoop将MapReduce计算的结果导出到Mysql中
- 导出命令
sqoop export \
--connect 'jdbc:mysql://192.168.56.101:3306/data?serverTimezone=UTC&useSSL=false' \
--username 'hdp' \
--password 'admin' \
--table 'top10' \
--export-dir '/res/top10/231022' \
--input-fields-terminated-by "\t"
- 导出日志
[root@cent7-1 sqoop-1.4.7.bin_hadoop-2.6.0]# sqoop export \>--connect'jdbc:mysql://192.168.56.101:3306/data?serverTimezone=UTC&useSSL=false'\>--username'hdp'\>--password'admin'\>--table'top10'\> --export-dir '/res/top10/231022'\> --input-fields-terminated-by "\t"
Warning: /home/sqoop-1.4.7.bin_hadoop-2.6.0//../hcatalog does not exist! HCatalog jobs will fail.
Please set$HCAT_HOME to the root of your HCatalog installation.
Warning: /home/sqoop-1.4.7.bin_hadoop-2.6.0//../accumulo does not exist! Accumulo imports will fail.
Please set$ACCUMULO_HOME to the root of your Accumulo installation.
2023-10-24 23:42:09,452 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
2023-10-24 23:42:09,684 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
2023-10-24 23:42:09,997 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
2023-10-24 23:42:10,022 INFO tool.CodeGenTool: Beginning code generation
Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.
2023-10-24 23:42:10,921 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `top10` AS t LIMIT 1
2023-10-24 23:42:11,061 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `top10` AS t LIMIT 1
2023-10-24 23:42:11,084 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /home/hadoop-3.2.4
注: /tmp/sqoop-root/compile/6d507cd9a1a751990abfd7eef20a60c2/top10.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
2023-10-24 23:42:23,932 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-root/compile/6d507cd9a1a751990abfd7eef20a60c2/top10.jar
2023-10-24 23:42:23,972 INFO mapreduce.ExportJobBase: Beginning export of top10
2023-10-24 23:42:23,972 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2023-10-24 23:42:24,237 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
2023-10-24 23:42:27,318 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
2023-10-24 23:42:27,325 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-10-24 23:42:27,326 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2023-10-24 23:42:27,641 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2023-10-24 23:42:29,161 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1698153196891_0015
2023-10-24 23:42:39,216 INFO input.FileInputFormat: Total input files to process : 1
2023-10-24 23:42:39,231 INFO input.FileInputFormat: Total input files to process : 1
2023-10-24 23:42:39,387 INFO mapreduce.JobSubmitter: number of splits:4
2023-10-24 23:42:39,475 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
2023-10-24 23:42:40,171 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1698153196891_0015
2023-10-24 23:42:40,173 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-10-24 23:42:40,660 INFO conf.Configuration: resource-types.xml not found
2023-10-24 23:42:40,660 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-10-24 23:42:41,073 INFO impl.YarnClientImpl: Submitted application application_1698153196891_0015
2023-10-24 23:42:41,163 INFO mapreduce.Job: The url to track the job: http://cent7-1:8088/proxy/application_1698153196891_0015/
2023-10-24 23:42:41,164 INFO mapreduce.Job: Running job: job_1698153196891_0015
2023-10-24 23:43:02,755 INFO mapreduce.Job: Job job_1698153196891_0015 running in uber mode :false2023-10-24 23:43:02,760 INFO mapreduce.Job: map 0% reduce 0%
2023-10-24 23:43:23,821 INFO mapreduce.Job: map 25% reduce 0%
2023-10-24 23:43:25,047 INFO mapreduce.Job: map 50% reduce 0%
2023-10-24 23:43:26,069 INFO mapreduce.Job: map 75% reduce 0%
2023-10-24 23:43:27,088 INFO mapreduce.Job: map 100% reduce 0%
2023-10-24 23:43:28,112 INFO mapreduce.Job: Job job_1698153196891_0015 completed successfully
2023-10-24 23:43:28,266 INFO mapreduce.Job: Counters: 33
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=993808
FILE: Number of readoperations=0
FILE: Number of large readoperations=0
FILE: Number of writeoperations=0
HDFS: Number of bytes read=1297
HDFS: Number of bytes written=0
HDFS: Number of readoperations=19
HDFS: Number of large readoperations=0
HDFS: Number of writeoperations=0
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=4
Data-local map tasks=4
Total time spent by all maps in occupied slots (ms)=79661
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=79661
Total vcore-milliseconds taken by all map tasks=79661
Total megabyte-milliseconds taken by all map tasks=81572864
Map-Reduce Framework
Map input records=10
Map output records=10
Input splitbytes=586
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=3053
CPU time spent (ms)=11530
Physical memory (bytes)snapshot=911597568
Virtual memory (bytes)snapshot=10326462464
Total committed heap usage (bytes)=584056832
Peak Map Physical memory (bytes)=238632960
Peak Map Virtual memory (bytes)=2584969216
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=02023-10-24 23:43:28,282 INFO mapreduce.ExportJobBase: Transferred 1.2666 KB in60.9011 seconds (21.2968 bytes/sec)2023-10-24 23:43:28,291 INFO mapreduce.ExportJobBase: Exported 10 records.
本文转载自: https://blog.csdn.net/qq_40366738/article/details/134044167
版权归原作者 Huathy-雨落江南,浮生若梦 所有, 如有侵权,请联系我们删除。
版权归原作者 Huathy-雨落江南,浮生若梦 所有, 如有侵权,请联系我们删除。