
Hadoop集群简介
Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群。
(1)HDFS集群:负责海量数据的存储,集群中的主要角色有:NameNode(一个,master)、DataNode(若干,slave)和SecondaryNameNode(一个)。
(2)YARN集群:负责海量数据运算的资源调度,集群中的角色主要有:ResourceManager(一个,master)和NodeManager(若干,slave)。
Hadoop集群的部署方式分为三种,分别是单机模式、伪分布式模式和完全分布式模式。
(1)单机模式:又称为独立模式,在该模式下,无需运行任何守护进程,所有的程序都在单个JVM上执行。单机模式下调试Hadoop集群的MapReduce程序非常方便,所以一般情况下,该模式在学习或者开发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台主机节点上,通常使用伪分布式模式来调试Hadoop分布式程序的代码,以及程序执行是否正确,伪分布式是完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际应用开发中,通常使用该模式构建企业级Hadoop系统。
环境搭建
1.修改主机名
hostnamectl set-hostname hadoop000

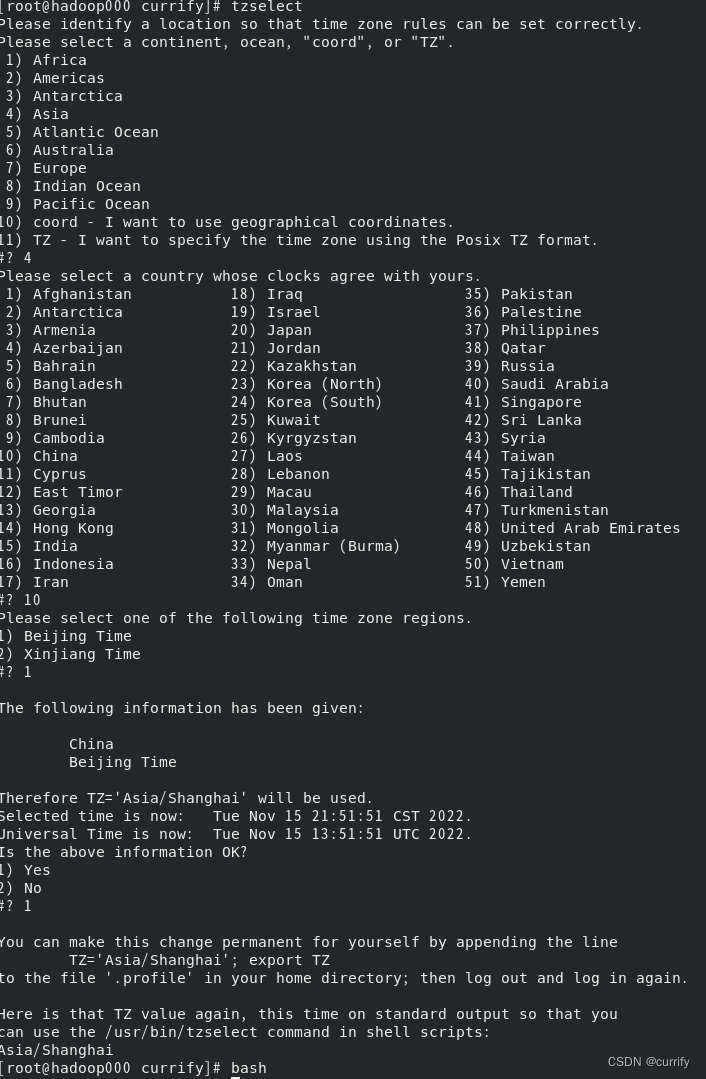
2.修改时区
tzselect
3.安装JDK
wget https://download.oracle.com/java/19/latest/jdk-19_linux-x64_bin.tar.gz
因为个人习惯故用 -C 参数选择解压到指定路径
tar -zxvf jdk-19_linux-x64_bin.tar.gz -C /home/currify/software/jdk
修改系统配置文件
vim /etc/profile
在结尾添加如下代码段(第二行JAVA_HOME后接JDK安装路径)
export PATH=$PATH:JAVA_HOME/bin
export JAVA_HOME=/home/currify/software/jdk/jdk-19.0.1
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
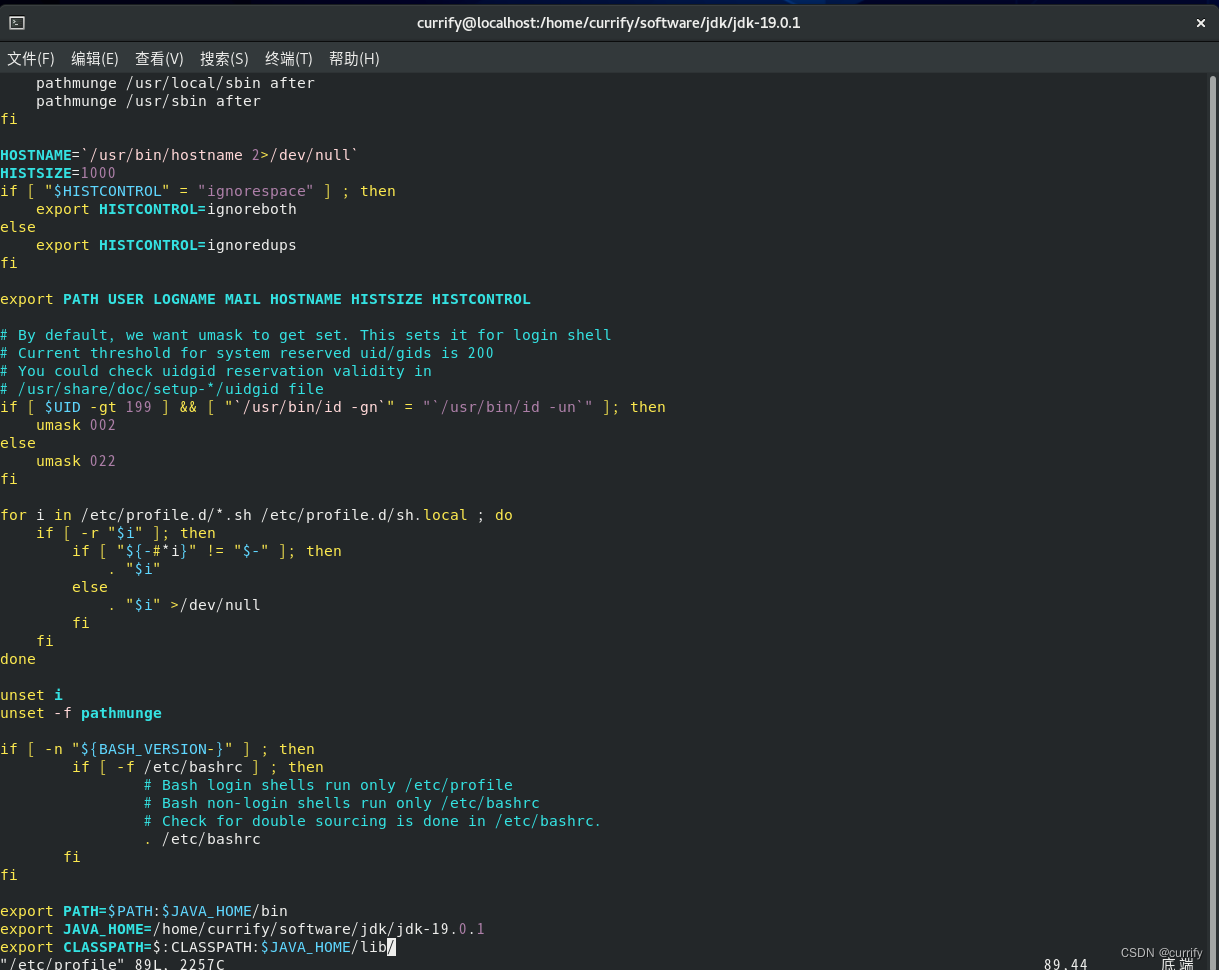
生效环境变量
source /etc/profile
检查JDK是否安装成功
java -version

4.配置ssh免密
SSH为Security Shell(安全外壳协议)的缩写。
SSH是一种网络协议,用于计算机之间的加密登录。很多ftp、pop和telent在本质上都是不安全的,因为它们在网络上用明文传送口令和数据,很多不法分子非常容易就可以截获这些口令和数据。
SSH就是专为远程登录会话和其他网络服务提供安全性的协议。
安装ssh服务
yum install openssh-server

开启ssh服务
systemctl start sshd
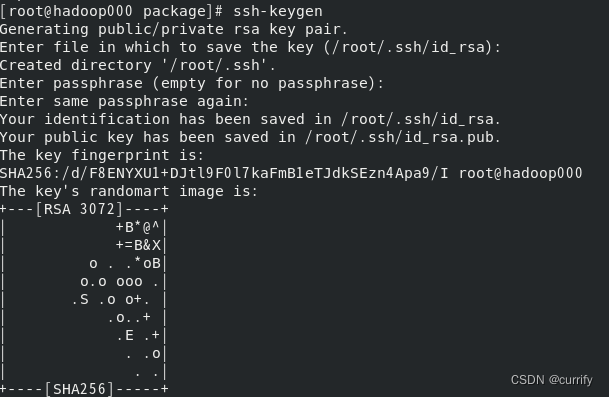
生成密钥对
ssh-keygen
或者
ssh-keygen -t rsa
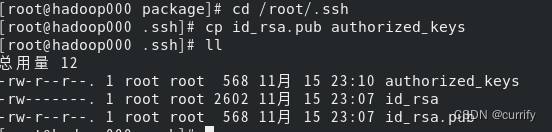
将公钥文件放置到授权列表文件authorized_keys中
cp id_rsa.pub authorized_keys
修改授权列表文件authorized_keys的权限
chmod 600 authorized_keys

验证是否成功配置ssh免密
ssh hadoop000

5.安装Hadoop
wget https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
tar -zxvf hadoop-3.3.4.tar.gz -C /home/currify/software/hadoop
目录结构
(1)bin:存放操作Hadoop相关服务(HDFS、YARN)的脚本,但是通常使用sbin目录下的脚本。
(2)etc:存放Hadoop配置文件。
(3)include:对外提供的编程库头文件(具体动态库和静态库在lib目录中)。
(4)lib:该目录包含了Hadoop对外提供的编程动态库和静态库。
(5)libexec:各个服务对应的shell配置文件所在的目录。
(6)sbin:该目录存放Hadoop管理脚本,主要包含HDFS和YARN中各类服务的启动/关闭脚本。
(7)share:Hadoop各个模块编译后的jar包所在的目录。
配置文件说明
(1)一种是只读的默认配置文件,包括core-default、hdfs-default.xml、mapred-default.xml和yarn-default.xml,这些文件包含了Hadoop系统各种默认配置参数。
(2)另一种是Hadoop集群自定义配置时编辑的配置文件,包括hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和slaves共7个文件,可以根据需要在这些文件中对默认配置文件中的参数进行修改,Hadoop会优先选择这些配置文件中的参数。
主要配置文件
配置文件功能描述hadoop-env.sh配置Hadoop运行所需的环境变量yarn-env.sh配置YARN运行所需的环境变量core-site.xmlHadoop核心全局配置文件,可在其它配置文件中引用该文件hdfs-site.xmlHDFS配置文件,继承core-site.xml配置文件mapred-site.xmlMapReduce配置文件,继承core-site.xml配置文件yarn-site.xmlYARN配置文件,继承core-site.xml配置文件slaves
Hadoop集群所有从节点(DataNode和NodeManager)列表
搭建HDFS伪分布式集群
设置 HADOOP 环境变量
vim ~/.bashrc
在最后添加
# Hadoop Environment Variables
export HADOOP_HOME=/home/currify/software/jdk/jdk-19.0.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
生效环境变量
source ~/.bashrc
配置环境变量hadoop-env.sh
vim /home/currify/software/hadoop/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/currify/software/jdk/jdk-19.0.1
配置核心组件core-site.xml
vim /home/currify/software/hadoop/hadoop-3.3.4/etc/hadoop/core-site.xml
将以下内容添加
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/soft/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

配置核心组件hdfs-site.xml
该文件主要用于配置HDFS相关的属性,例如复制因子(即数据块的副本数)、NameNode和DataNode用于存储数据的目录等。在完全分布式模式下,默认的块副本是3份。
vim /home/currify/software/hadoop/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
将以下内容加入
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/soft/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/soft/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<!--这里是你自己的ip,端口默认-->
<value>dfs://localhost:50070</value>
</property>
</configuration>

配置Hadoop系统环境变量
vim /etc/profile
在底部加入
export HADOOP_HOME=/home/currify/software/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效环境变量
source /etc/profile
检查是否安装成功
hadoop version

初次启动HDFS集群时,必须对主节点进行格式化处理
hdfs namenode -format
启动NameNode
hdfs namenode start
启动DataNode
hdfs datanode start
搭建YARN伪分布式集群
配置环境变量yarn-env.sh,加入JDK路径
export JAVA_HOME=/home/currify/software/jdk/jdk-19.0.1
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.admin.user.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME</value>
</property>
</configuration>
配置yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 自己的ip端口默认 -->
<value>hdfs://localhost:9000</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
单节点逐个启动YARN集群进行测试
yarn resourcemanager start
yarn nodemanager start
版权归原作者 currify--+ 所有, 如有侵权,请联系我们删除。