
By 远方时光原创,可转载,open
合作微信公众号:大数据左右手

本文是基于spark官网结构化流解读
Structured Streaming Programming Guide - Spark 3.5.1 Documentation (apache.org)
spark官网对结构化流解释
我浓缩了一些关键信息:
1.结构化流是基于SparkSQL引擎构建的可扩展且容错的流处理引擎。(也就是他摒弃了DStream)
2.可以像批数据一样处理流数据。可以使用Dataset/DataFrame API在Scala、Java、Python或R中流聚合、事件时窗口、流批数据join等操作。(sparksql处理的是静态的有界表,sparkstreaming 处理的是动态无界表)
3.通过检查点和预写日志确保端到端精确一次容错保证。(一条数据只被消费一次)
4.默认结构化流查询使用微批次处理作业引擎进行处理,并实现低至100毫秒的端到端延迟和精确一次的容错保证。
5.自Spark 2.3,引入了一种新的更低延迟处理模式,称为连续处理,它可以实现低至1毫秒的端到端延迟,并保证至少一次。(这个延迟基本和flink处理流无区别了)
基本概念:
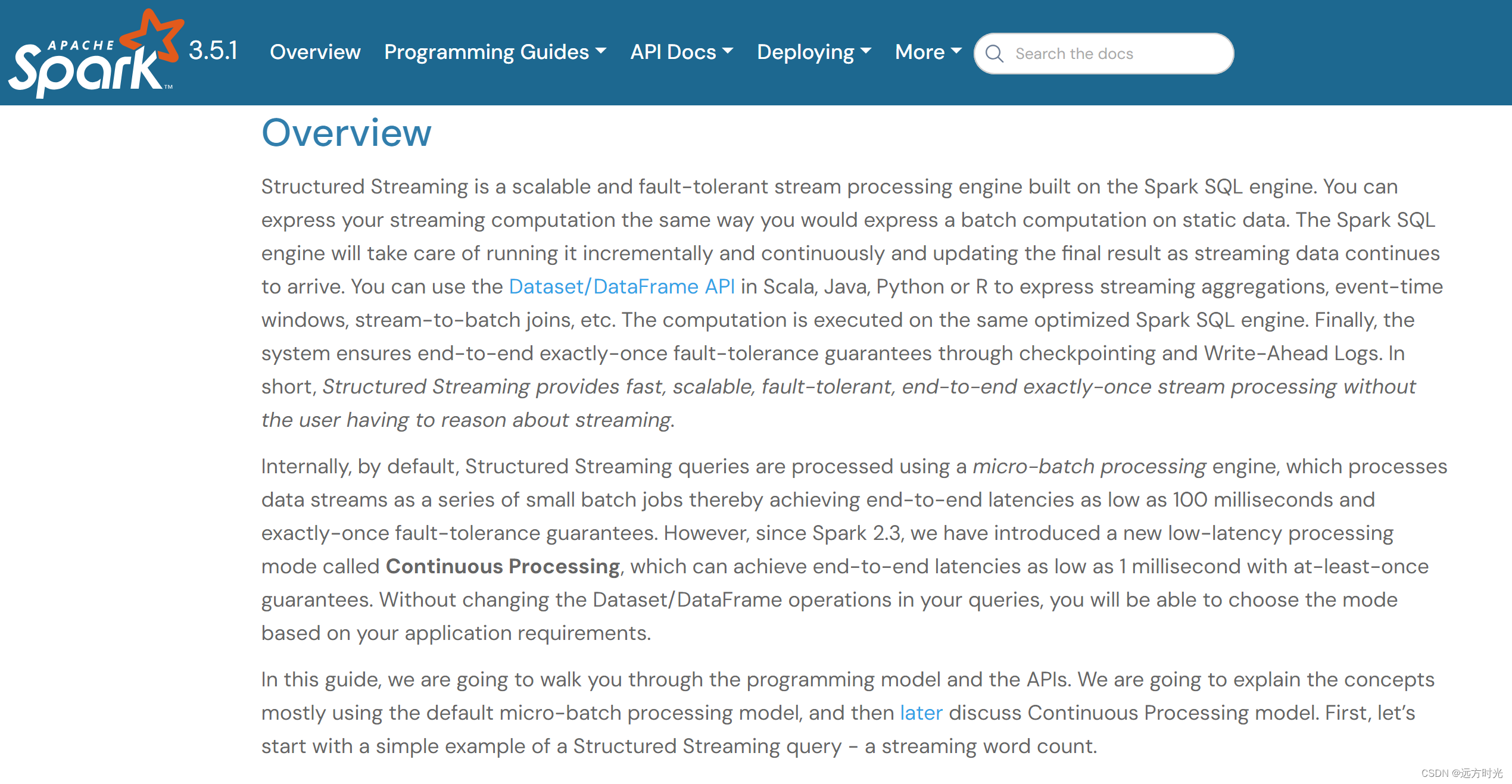
输入表
可以抽象的认为:消费的流数据,源源不断的追加到一张无界表中。
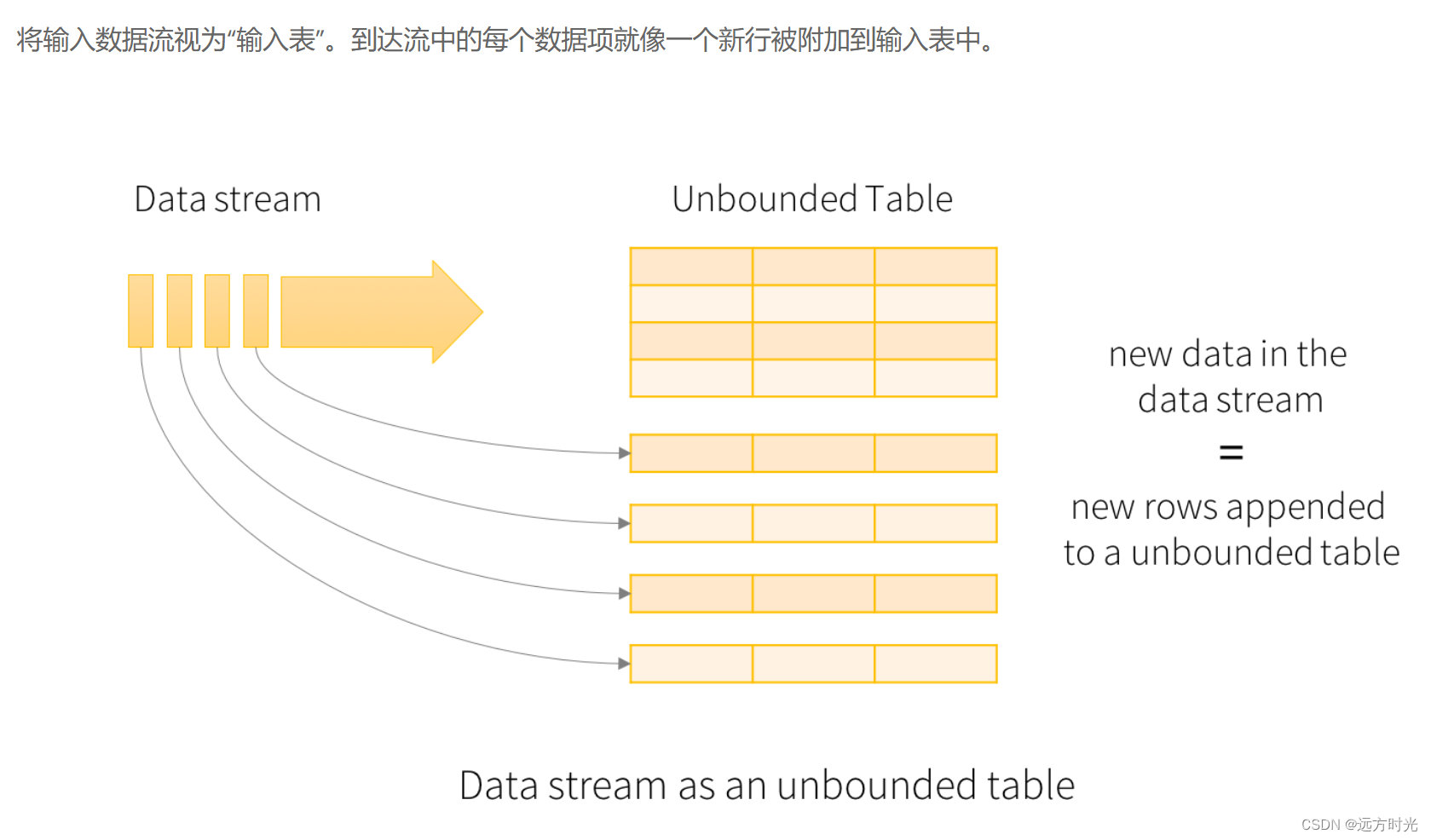
输出表
处理后的结果,比如下图中groupby($"word").count()
输出模式:
·完成模式(complete):整个更新的结果表将被写入外部存储。全部输出,必须要有聚合。
time1:
输入表:''cat dog dog dog''
-> groupby($"word").count()
-> 结果表输出:cat 1, dog 3
time2:
新增消息 "owl cat"
-> groupby($"word").count()
-> 结果表输出:cat 2, dog 3, owl 1
time3:
新增消息 "dog owl"
-> groupby($"word").count()
-> 结果表输出:cat 2, dog 4, owl 2
·追加模式(apend):自上次触发器以来,追加到结果表中的新增的行才会写入外部存储。仅适用于结果表中现有行预计不会更改。
time1:
输入表:''cat dog'' -> 不处理 -> 结果表输出:cat, dog
time2:
新增消息 ''fish'' -> 不处理 -> 结果表输出:fish
·更新模式(update):自上次触发器以来,在结果表中更新的行才会写入外部存储(自Spark2.1.1起可用)。如果查询不包含聚合,则相当于追加模式。
time1:
输入表:''cat dog dog dog''
-> groupby($"word").count()
-> 结果表输出:cat 1, dog 3
time2:
新增消息 "owl cat"
-> groupby($"word").count()
-> 结果表输出:cat 2, owl 1 (变化和新增输出,dog 3对比time1无变化不输出)
处理事件时间
{''id'':''8888888'', ''time'':''2024-03-04 19:36:30'',''data'':''****''}
事件时间是嵌入在数据本身中的时间,spark允许基于eventTime窗口聚合
时间窗口:
滚动窗口:窗口无重合,window($"timestamp", "5 minutes", "5 minutes")
滑动窗口:窗口有重合,window($"timestamp", "10 minutes", "5 minutes")
会话窗口:设有一个时间间隔(5分钟),结合下图看,12:09分后面5分钟,都没收到新数据,所以在12:14分窗口关闭

水位线解决延迟数据 (超级重点,面试爱问)
从 Spark 2.1 开始,支持水印或者叫水位线(watermark),一种窗口关闭延迟机制,用于解决部分乱序数据。
官网写的太长,我简化一下,你对着图看:
注:④抽象为一条数据(其事件时间为12:04的)
水位线 = 曾经消费过****最迟事件时间(max eventTime) - 允许延迟的时间(threshold)
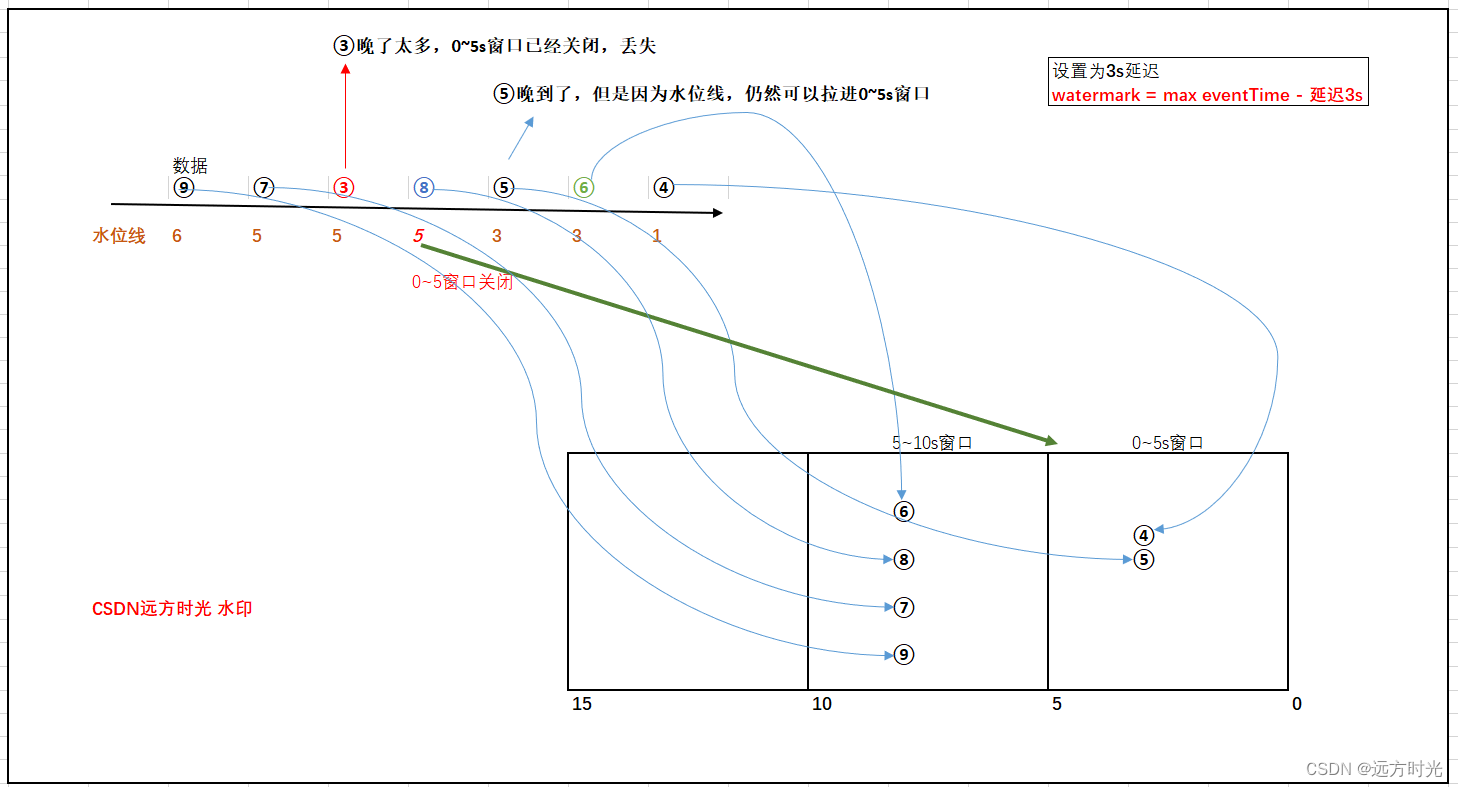
1)消费到④,拉倒0~5s窗口,watermark=4 - 3 = 1
2)消费到⑥,拉到5~10s窗口,watermark=6 - 3 = 3
3)消费到⑤,拉到5~10s窗口,⑤正常是会⑥之前被消费到,此时出现乱序,⑤它晚到了
如果没有设置水位线,消费到⑥的时候0~5s窗口就应该被关闭,⑤丢失
但是我们设置了3s水位线延迟机制,
此时水位线watermark = 6 - 3 = 3 (曾经消费过****最迟eventTime是⑥ - 3,而不是⑤ - 3),抽象理解为水位线只会上涨,不会下降
因为水位线机制,晚到的⑤仍然可以进入到0~5s窗口
只有当水位线>=5,这里5指的是开窗的(0,5]右区间,0~5s窗口才会关闭
4)消费到⑧,拉倒510s窗口,watermark=8 - 3 = 5,*那么***05s窗口此时正式关闭**
5)消费到③,0~5s窗口已经关闭,这条数据晚太多了,被丢失掉了,所以尽管设置水位线还是会有数据丢失。
水位线用来鉴别延迟数据的有效性:在水位线以内的数据都是有效数据参与窗口的计算,水位线以外的数据则为过期数据丢弃
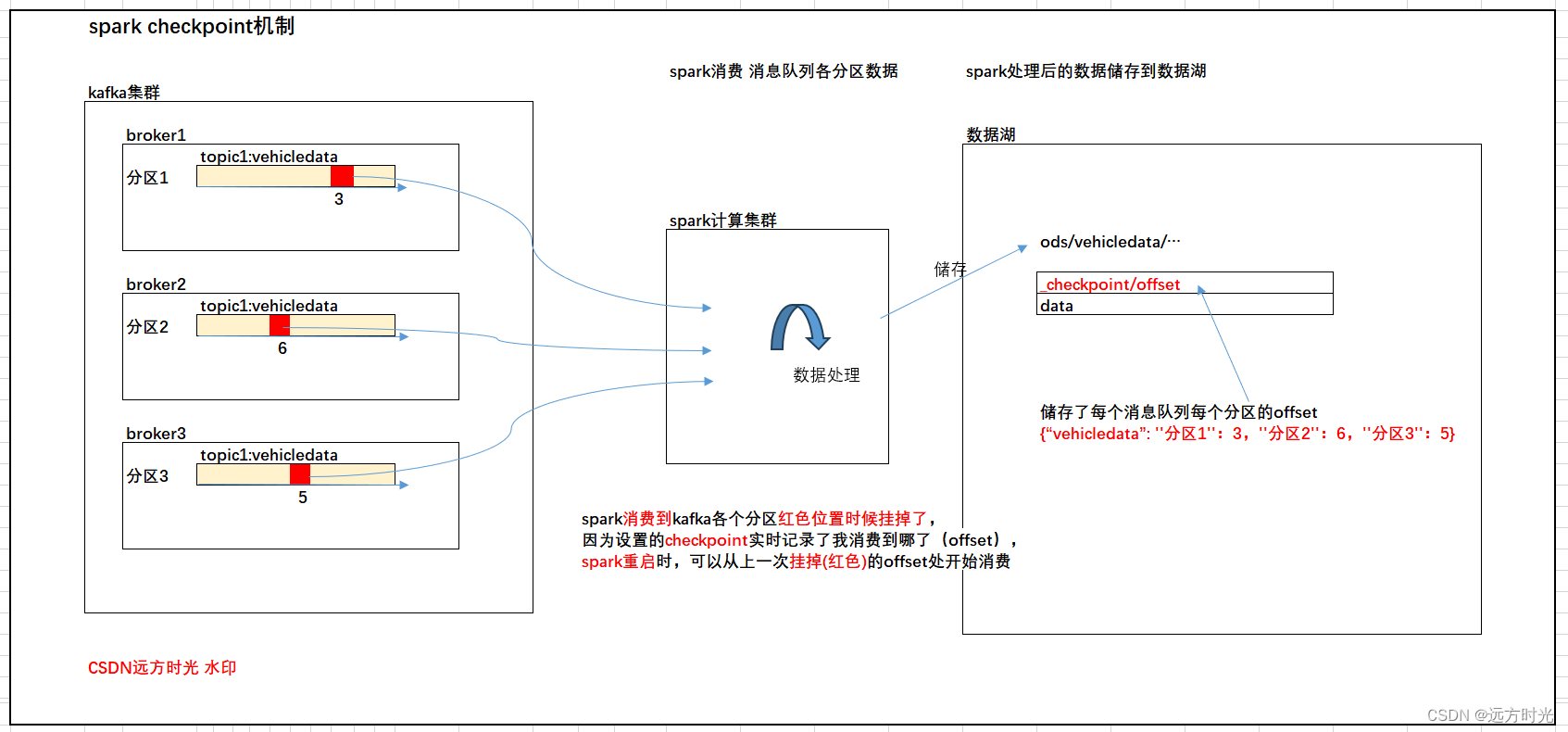
检查点机制保证端到端精确一次消费(checkpoint) <--重点
在 Spark Structured Streaming 中,通过使用 checkpoint 可以确保端到端的精确一次语义和容错。
val spark = SparkSession.builder.appName("YourAppName").getOrCreate()
// 设置检查点目录
spark.conf.set("spark.checkpoint.directory", "/path/to/checkpoint")
// 创建 Event Hubs 配置
val eventHubsConf = Map(
"eventhubs.connectionString" -> "your_eventhubs_connection_string",
"eventhubs.consumerGroup" -> "your_consumer_group",
"eventhubs.name" -> "your_eventhubs_name"
)
val streamingQuery = spark.readStream
.format("eventhubs")
.options(eventHubsConf)
.option("startingOffsets", "latest") // or "earliest" based on your requirements
.load()
// Perform transformations, aggregations, etc.
.writeStream
.outputMode("update")
.format("console")
.option("checkpointLocation", "/path/to/checkpoint") // <---checkpoint 记录消费的offset
.start()
streamingQuery.awaitTermination()
在 options 中,可以使用 startingOffsets 参数来指定从哪个 offset 开始读取数据。你可以将其设置为 "latest" 或 "earliest",具体取决于你的需求。
确保检查点目录是在可靠的文件系统上。这样,在应用程序重新启动时,Spark Streaming 将能够恢复到上次处理的状态,从上一次记录的 offset 开始读取数据,实现端到端的精确一次语义和容错。
真实checkpoint储到路径是什么样的

预写日志WAL(write ahead log)机制来保证精确一次消费(重点)
3.通过检查点和预写日志WAL确保端到端精确一次容错保证。(一条数据只被消费一次)
思考一个问题我只需要checkpoint记录我的offset就可以保证精确一次消费吗?

至多一次消费:
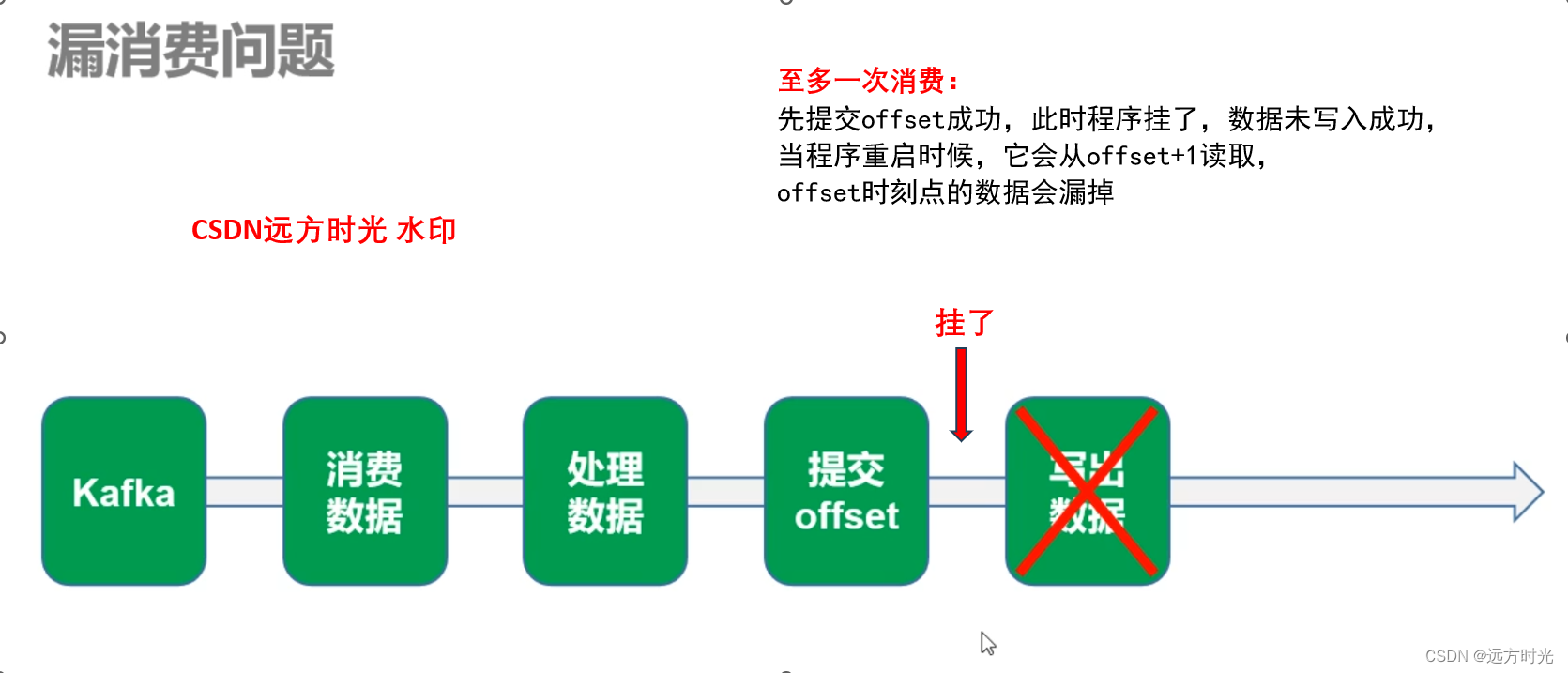
至少一次消费:

精确一次消费:
两种方式:
1.使用后提交offset保证至少一次(数据重复)+幂等性,也就是写入目的地支持去重,来去处重复数据
2.另外一种就是保证提交offset和输出数据同时成功,或者同时失败,也就是事务。预写日志机制(WAL)就是这么做的。
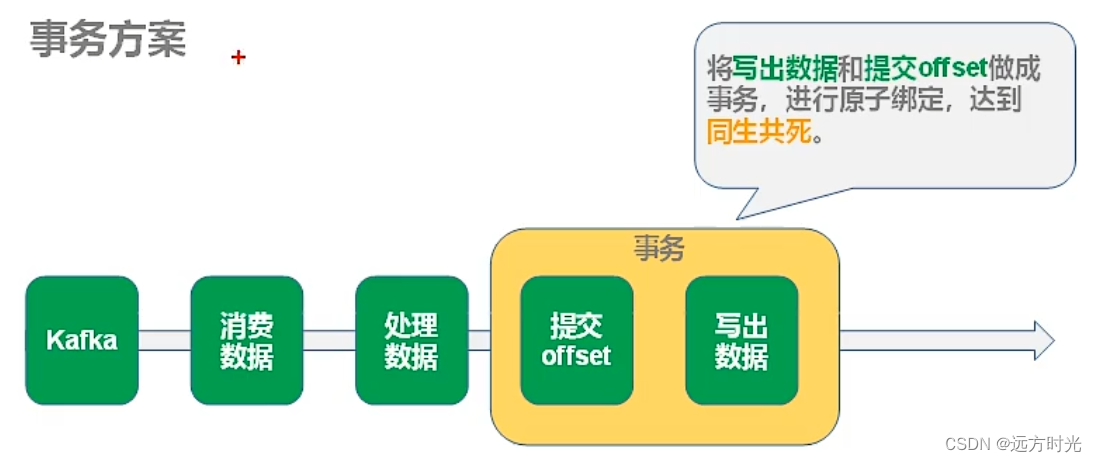
WAL(Write Ahead Log)预写日志,是数据库系统中常见的一种手段,用于保证数据操作的原子性和持久性。
「预写式日志」(Write-ahead logging,缩写 WAL)是关系数据库系统中用于提供原子性和持久性(ACID 属性中的两个)的一系列技术。在使用 WAL 的系统中,所有的修改在提交之前都要先写入 log 文件中。
log 文件中通常包括 redo 和 undo 信息(redo重做,undo撤销还原)。这样做的目的可以通过一个例子来说明。假设一个程序在执行某些操作的过程中机器掉电了。在重新启动时,程序可能需要知道当时执行的操作是成功了还是部分成功或者是失败了。如果使用了 WAL,程序就可以检查 log 文件,并对突然掉电时计划执行的操作内容跟实际上执行的操作内容进行比较。在这个比较的基础上,程序就可以决定是撤销已做的操作还是继续完成已做的操作,或者是保持原样。
我抽象理解:有一个地方记录了log,用于记录这一次的offset和写出数据是否都成功,如果两个中有一次没成功,成功的那一个回滚(撤销已做的操作),在程序重启的时候先检查一下WAL文件,看看我是否需要回滚,来保证原子性。
官网原文:
The engine uses checkpointingand write-ahead logs to record the offset range of the data being processed in each trigger. The streaming sinks are designed to be idempotent for handling reprocessing. Together, using replayable sources and idempotent sinks, Structured Streaming can ensure end-to-end exactly-once semantics under any failure.
Checkpiont+WAL记录offset,回滚
还有一个流接收器来让数据幂等性(没找的相关介绍和科普),我问了一下chatGPT:
预写式日志(WAL):
- WAL提供持久性和原子性,并确保即使在处理数据但在元数据检查点之前发生故障时,系统也可以通过回滚到已记录的信息进行恢复。
幂等性的接收端:
- Structured Streaming中的流接收端被设计为幂等(key去重)。
- 幂等的接收端确保如果系统由于故障而需要重新处理数据,不会导致重复或不正确的输出。
- 通过使接收端具有幂等性,系统可以安全地回滚数据而不会引入不一致性。
2024-3-7 0:18 写不动了,明天看看有什么继续写的
觉得不错的点赞收藏一下
版权归原作者 远方时光 所有, 如有侵权,请联系我们删除。