
本次在CentOS7.6上搭建Kafka集群
Apache Kafka 是一个高吞吐量的分布式消息系统,被广泛应用于大规模数据处理和实时数据管道中。本文将介绍在CentOS操作系统上搭建Kafka集群的过程,以便于构建可靠的消息处理平台。
文件分享(KafkaUI、kafka3.3.2、jdk1.8)
链接:https://pan.baidu.com/s/1dn_mQKc1FnlQvuSgGjBc1w?pwd=t2v9 提取码:t2v9

也可以从官网自己下
Kafka官网
步骤概览
本次使用三台机器 hostname别名分别为res01(10.41.7.41)、res02(10.41.7.42)、res03(10.41.7.43)
在这个教程中,我们将覆盖以下主要步骤:
- 准备环境:安装和配置Java、Zookeeper和Kafka所需的依赖。
- 配置Zookeeper集群:确保Kafka有可靠的分布式协调服务。(本次使用Kafka自带的zookeeper)
- 配置Kafka集群:在每个节点上安装和配置Kafka,设置Kafka集群以实现高性能和高可用性。
步骤详解
步骤1:环境准备 (先对第一台服务器操作 其他的使用scp传输之后进行小修改就好)
安装Java
确保Java安装正确,并设置JAVA_HOME环境变量。
如果对于jdk安装有问题的可以看一下这篇Linux安装MySQL、JDK(含环境变量配置)、Tomcat

步骤2:安装Kafka
下载和解压Kafka
[root@res01 module]# clear
[root@res01 module]# ll
总用量 104124
drwxr-xr-x. 4 root root 40 11月 10 10:07 data
-rw-r--r--. 1 root root 106619987 11月 10 10:33 kafka_2.13-3.3.2.tgz
[root@res01 module]# tar -zxvf kafka_2.13-3.3.2.tgz
解压之后通过mv改名

步骤3:配置zookeeper
进入文件夹kafka3.3.2中找到config
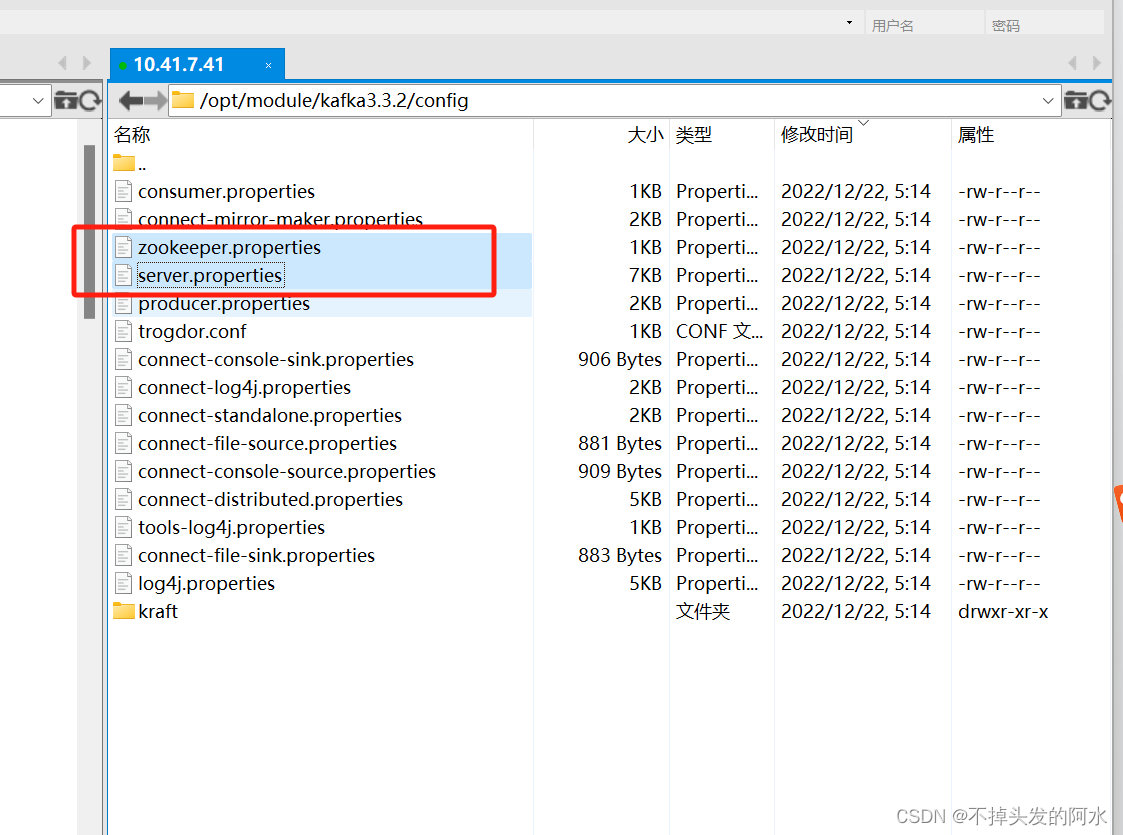
接下来主要修改zookeeper.properties和server.properties这两个文件
zookeeper.properties如下
# 需要去新建/opt/module/data/zookeeper下面这两个文件夹
dataDir=/opt/module/data/zookeeper/data
dataLogDir=/opt/module/data/zookeeper/logs
clientPort=12181
maxClientCnxns=0
admin.enableServer=false
tickTime=2000
initLimit=10
syncLimit=5
# server.X=hostname:peerPort:leaderPort
# peerPort 是服务器之间通信的端口。
# leaderPort 是用于选举 leader 的端口。
server.1=res01:12182:12183
server.2=res02:12182:12183
server.3=res03:12182:12183
#res01、res02、res03是我本地设置过的主机名 如果没设置使用ip地址即可
在每个节点上zookeeper的配置文件中dataDir目录下创建一个名为
myid
的文件,并分别填入相应节点的ID号:
1
、
2
、
3
。

步骤4:配置Kafka
编辑Kafka配置文件
config/server.properties
,设置
broker.id
和
zookeeper.connect
:
# 设置 broker.id 这个是 Kafka 集群区分每个节点的唯一标志符。 对应那个myid即可
broker.id=1
# 将监听端口设置为19091
listeners=PLAINTEXT://res01:19091
# 将广告给客户端的地址也设置为19091
advertised.listeners=PLAINTEXT://res01:19091
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 设置 Kafka 的数据存储路径 这个目录下不能有其他非 Kafka 目录,不然会导致 Kafka 集群无法启动。
log.dirs=/opt/module/data/kafka-log
# 默认的 Partition 的个数。
num.partitions=3
# 设置默认的复制因子为3
default.replication.factor=3
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# Kafka 的数据保留的时间,默认是 7 天 168h。 这里使用24小时
log.retention.hours=24
log.retention.check.interval.ms=300000
# Kafka 连接的 ZooKeeper 的地址和连接 Kafka 的超时时间。
zookeeper.connect=res01:12181,res02:12181,res03:12181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
# 设置是否可以删除 Topic,默认 Kafka 的 Topic 是不允许删除的 这里打开了
delete.topic.enable=true
# 这是用于启用或禁用日志清理的选项,默认值为 true,以确保 Kafka 持续进行日志清理。需要根据实际需求进行设置。
log.cleaner.enable=true
# 这个参数控制日志清理线程的数量。对于你的硬件配置,你可以考虑设置为 4 或 8 来充分利用服务器的性能。
log.cleaner.threads=4
# 这个参数用于控制日志清理线程的 IO 缓冲区大小。对于你的硬件配置,可以设置为 8192 或 16384。
log.cleaner.io.buffer.size=8192
# 这个参数是用来设置主题日志保留的最大字节数。对于控制磁盘空间的使用非常重要。例如,如果你希望限制每个主题的数据量不超过 100GB,可以设置为 107374182400
log.retention.bytes=107374182400
# 这个参数用于控制每个日志段文件的最大大小。对于你的硬件配置,你可以设置为 1073741824(即 1GB)。
log.segment.bytes=1073741824
# 这个参数用于设置 Zookeeper 会话的超时时间。对于较大的集群和连接较慢的网络,你可以考虑将其设置为 10000,即 10 秒。
zookeeper.session.timeout.ms=10000
重点是这个:
# 设置默认的复制因子为3
default.replication.factor=3
在Kafka集群的每个节点上,修改
broker.id
为对应的节点ID。
配置kafka环境变量
#java环境
export JAVA_HOME=/usr/local/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
#kafka环境
export KAFKA_HOME=/opt/module/kafka3.3.2
export PATH=$PATH:$KAFKA_HOME/bin
步骤5:复制虚拟机
(已有其他服务器的直接连网线scp就好 环境变量 配置小改一下就好 还有hosts、ip等等别忘了配置,我这里直接复制虚拟机了 )
配置ip、hostname以及hosts后尝试ping

res02修改kafka的config文件即可(zookeeper配置文件都一样 用res01配置的就好)

res03的kafka配置文件同理

以及各台机器的myid(对应上brokerId即可)

步骤6:配置Kafka集群
确保防火墙或安全组允许Kafka端口通过,通常是9092端口。(我这是修改过的为19091,我直接关防火墙了 方便。)
systemctl stop firewalld.service
#关闭运行的防火墙
systemctl disable firewalld.service
#永久关闭防火墙
本次使用的是绝对路径 各位可以到kafka目录下执行命令 去掉前面的绝对路径就好
zookeeper命令
在每个机器上,先启动zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-stop.sh
#停止命令
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh /opt/module/kafka3.3.2/config/zookeeper.properties
#启动命令
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh -daemon /opt/module/kafka3.3.2/config/zookeeper.properties
#后台启动命令 常用~
统一启动后jps查看进程

Kafka命令
在每个Kafka节点上,启动Kafka服务器:
/opt/module/kafka3.3.2/bin/kafka-server-start.sh /opt/module/kafka3.3.2/config/server.properties
#kafka启动命令
/opt/module/kafka3.3.2/bin/kafka-server-start.sh -daemon /opt/module/kafka3.3.2/config/server.properties
#kafka后台启动命令 常用~
/opt/module/kafka3.3.2/bin/kafka-server-stop.sh
#停止命令
统一启动后jps查看进程
创建主题
使用
kafka-topics.sh
命令创建一个主题:这里设置的复制因子为3
bin/kafka-topics.sh --create --topic 你的topic--bootstrap-server res01:19091--replication-factor 3 --partitions 3
验证Kafka集群
使用生产者和消费者验证Kafka集群的功能:
# 启动生产者
bin/kafka-console-producer.sh --topic myTopic --bootstrap-server res01:19091
# 启动消费者
bin/kafka-console-consumer.sh --topic myTopic --bootstrap-server res01:19091--from-beginning
停止 Zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-stop.sh
启动 Zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh /opt/module/kafka3.3.2/config/zookeeper.properties
后台启动 Zookeeper:
/opt/module/kafka3.3.2/bin/zookeeper-server-start.sh -daemon /opt/module/kafka3.3.2/config/zookeeper.properties
清空 Kafka 日志:
rm -rf //opt/module/data/kafka-logs/*
启动 Kafka 服务:
/opt/module/kafka3.3.2/bin/kafka-server-start.sh /opt/module/kafka3.3.2/config/server.properties
后台启动 Kafka 服务:
/opt/module/kafka3.3.2/bin/kafka-server-start.sh -daemon /opt/module/kafka3.3.2/config/server.properties
停止 Kafka 服务:
/opt/module/kafka3.3.2/bin/kafka-server-stop.sh
创建 Topic:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --create --topic [TOPIC_NAME] --bootstrap-server [SERVER_IP]:[PORT] --partitions [PARTITIONS_SIZE] --replication-factor [REPLICATION_FACTOR]
删除 Topic:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --delete --topic [TOPIC_NAME] --bootstrap-server [SERVER_IP]:[PORT]
查看 Topic 信息:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --describe --topic [TOPIC_NAME] --bootstrap-server [SERVER_IP]:[PORT]
列出所有的 Topic:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --list --bootstrap-server [SERVER_IP]:[PORT]
控制台生产消息:
/opt/module/kafka3.3.2/bin/kafka-console-producer.sh --bootstrap-server [SERVER_IP]:[PORT] --topic [TOPIC_NAME]
控制台消费信息:
/opt/module/kafka3.3.2/bin/kafka-console-consumer.sh --bootstrap-server [SERVER_IP]:[PORT] --topic [TOPIC_NAME] --from-beginning
查看副本:
/opt/module/kafka3.3.2/bin/kafka-topics.sh --describe --bootstrap-server [SERVER_IP]:[PORT] | grep consumer_offsets
请记住替换 [TOPIC_NAME]、[SERVER_IP]:[PORT]、[PARTITIONS_SIZE]、[REPLICATION_FACTOR] 等位中的值为实际的值。
自己的做的总结如上:

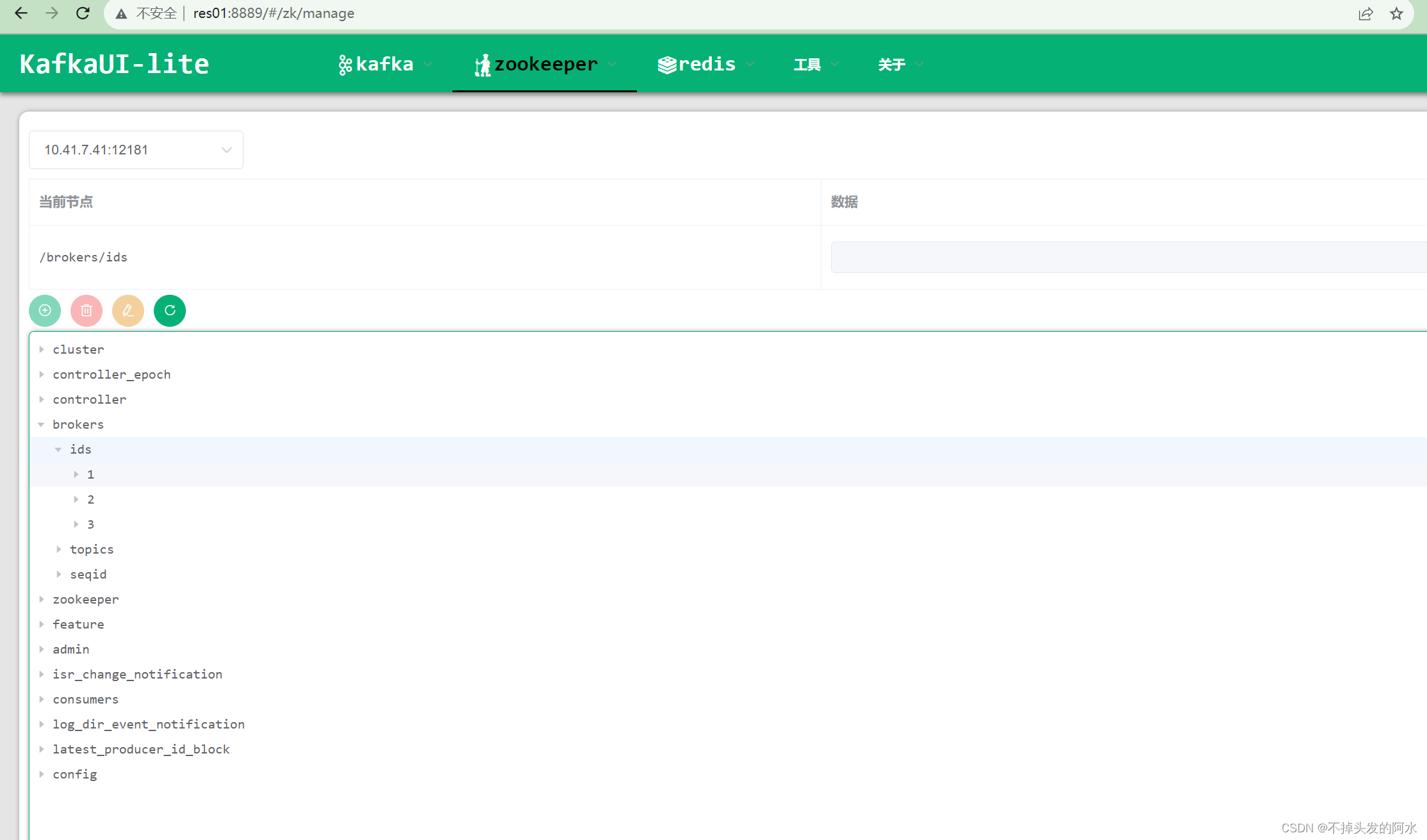
运行Java代码生成topic 可以看到分区都是3符合集群要求

运行kafkaui查看详细情况(百度网盘链接里有,自己输入命令太累了 直接用别人封装好现成的看就好~)
结论
通过这个步骤,我们成功地搭建了一个基本的Kafka集群。在实际生产环境中,您可能需要进一步调整和优化配置,以满足特定需求和性能要求。
希望这个教程可以帮助您成功搭建Kafka集群,为您的数据处理和消息传递架构提供强大的基础设施。
最后温馨提示:如果你远程服务器起了别名,而自己电脑的hosts别名对应其他的服务器 也会发生报错 记得别名对应好ip即可
本文转载自: https://blog.csdn.net/lps12345666/article/details/134326739
版权归原作者 不掉头发的阿水 所有, 如有侵权,请联系我们删除。
版权归原作者 不掉头发的阿水 所有, 如有侵权,请联系我们删除。