
** 1. Hadoop **集群部署规划
全分布模式下部署 Hadoop 集群时,最低需要两台机器,一个主节点和一个从节点。本书拟将 Hadoop 集群运行在 Linux 上,将使用三台安装有 Linux 操作系统的机器,主机名分别为 hadoop_base、hadoop_copy1、hadoop_copy2 ,其中 hadoop_base作为主节点,hadoop_copy1和hadoop_copy2 作为从节点。具体Hadoop 集群部署规划表如表 1-2 所示。

- 准备机器。
编者使用 VMware Workstation Pro 共安装了 3 台 CentOS 虚 拟 机 , 分 别为 hadoop_base、hadoop_copy1、hadoop_copy2,其中 hadoop_base 的内存为 4096MB, CPU 为 2 个 2 核,hadoop_copy1、hadoop_copy2 的内存也为 2048MB,CPU 为 1 个 2 核。
准备软件环境:
3.1 配置静态 IP
机器不同,CentOS 版本不同,网卡配置文件不尽相同。编者使用的 CentOS 7.6.1810 对应的网卡配置文件为/etc/sysconfig/network-scripts/ifcfg-ens33,读者可自行查 看个人 CentOS 的网卡配置文件。
(1)切换到 root 用户,使用命令“vim /etc/sysconfig/network-scripts/ifcfg-ens33”修 改 网卡配置文件,为该机器设置静态 IP 地址。网卡 ifcfg-ens33 配置文件较之原始内容, 变动的内容如下所示。
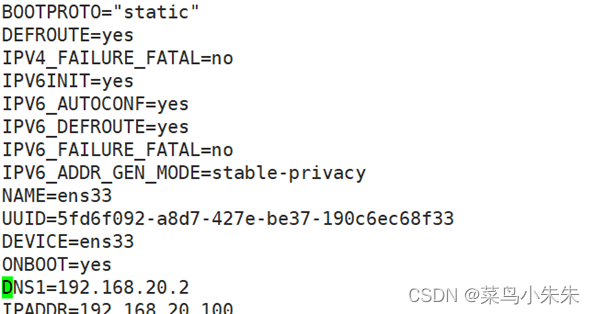
(2)使用“reboot”命令重启机器或者“systemctl restart network.service”命令重启网 络方可使得配置生效。如图所示,使用命令“ip address”或者简写“ip addr”查看到当 前机器的 IP 地址已设置为静态 IP“192.168.20.100”

同理,将虚拟机 hadoop_copy1、hadoop_copy2的IP 地址依次设置为静态 IP “192.168.20.101”、“192.168.20.102”。
** 3.2 **修改主机名;
切换到 root 用户,通过修改配置文件/etc/hostname,可以修改 Linux 主机名,按照部署规划,主节点的主机名为“hadoop100”,将配置文件/etc/hostname 中原始内容替换为:

使用“reboot”命令重启机器方可使得配置生效,使用命令“hostname”验证当前主机名是否已修改为“hadoop100”。
同理,将虚拟机 hadoop_copy1、hadoop_copy2 的主机名依次设置为“hadoop101”、“hadoop102”。
** 3.3**编辑域名映射;
为协助用户便捷访问该机器而无需记住 IP 地址串,需要编辑域名映射文件/etc/hosts,
在原始内容最后追加 3 行,内容如下所示。

使用“reboot”命令重启机器方可使得配置生效。
同理,编辑虚拟机 Hadoop101和Hadoop102 的域名映射文件,内容同虚拟机 hadoop2.9.2-master。
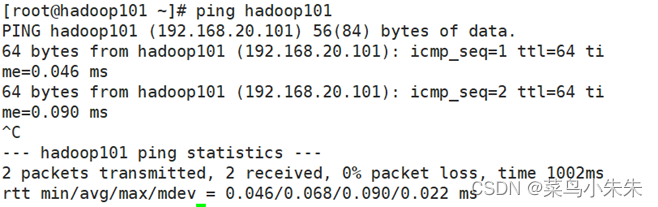
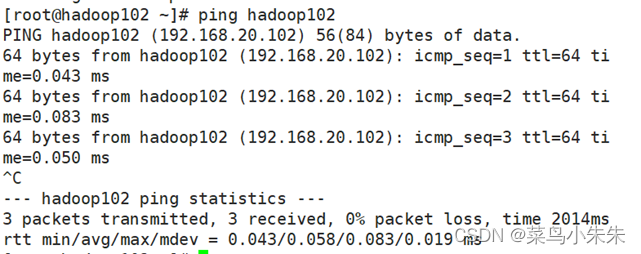
至此,3 台 CentOS 虚拟机的静态 IP、主机名、域名映射均已修改完毕,用 ping 命令来检测各节点间是否通讯正常,可按“Ctrl+C”组合键终止数据包的发送,成功效果如图所示。

3.4**安装和配置 Java**;
(1)卸载 Oracle OpenJDK。
首先,通过命令“java -version”查看是否已安装 Java。由于 CentOS 7 自带了 Oracle
OpenJDK,而更建议使用 Oracle JDK,因此将 Oracle OpenJDK 卸载。
其次,使用“rpm -qa|grep jdk”命令查询 jdk 软件,如图所示。

最后,切换到 root 用户下,分别使用命令“yum -y remove java-1.8.0”和“yum -y remove java-1.7.0”卸载 openjdk 1.8 和 openjdk 1.7。
同理,卸载节点 slave1 和 slave2 上的 Oracle OpenJDK。
(2)下载 Oracle JDK。
需要根据机器所安装的操作系统和位数选择相应 JDK 安装包下载,可以使用命令
“getconf LONG_BIT”来查询 Linux 操作系统是 32 还是 64 位;也可以使用命令“file /bin/ls”来显示 Linux 版本号。由于编者安装的是 CentOS 64 位,因此下载的 JDK 安装包文件名为2018 年 10 月 16 日发布的 jdk-8u191-linux-x64.tar.gz,并存放在目录/home/xuluhui/Downloads下。
同理,在节点 slave1 和 slave2 上也下载相同版本的 Oracle JDK,并存放在目录/home/zhu/下载 /下。
3)安装 Oracle JDK。
使用 tar 命令解压进行安装,例如安装到目录/usr/java 下,依次使用如下命令完成
[root@hadoop100 java]# cd /usr
[root@hadoop100 java]# mkdir java
[root@hadoop100 java]# cd java
[root@hadoop101 java]# tar -zxvf /home/zhu/下载/jdk-8u191-linux-x64.tar.gz
同理,在节点 hadoop101和hadoop1012上也安装 Oracle JDK。
4)配置 Java 环境。
通过修改/etc/profile 文件完成环境变量 JAVA_HOME、PATH 和 CLASSPATH 的设置,
在配置文件/etc/profile 的最后添加如下内容:

使用命令“source /etc/profile”重新加载配置文件或者重启机器,使配置生效,Java 环境变量配置成功后的系统变量“PATH”值如图所示。

5)验证 Java。
再次使用命令“java -version”,查看 Java 是否安装配置成功及其版本,如图所示。

3.5**安装和配置 SSH **免密登录。
(1)安装 SSH。
使用命令“rpm -qa|grep ssh”查询 SSH 是否已经安装,如图所示。

从上图可以看出,CentOS 7 已安装好 SSH 软件包,若没有安装好,用命令“yum”
安装,命令如下所示。
[root@hadoop100 java]# yum -y install openssh
[root@hadoop100 java]# yum -y install openssh-server
[root@hadoop100 java]# yum -y install openssh-clients
2)修改 sshd 配置文件。
使用命令“vim /etc/ssh/sshd_config”修改 sshd 配置文件,原始第 43 行内容为:
#PubkeyAuthentication yes
修改后为:
RSAAuthentication yes
PubkeyAuthentication yes
同理,在节点 slave1 和 slave2 上也修改 sshd 配置文件。
3)重启 sshd 服务。
使用如下命令重启 sshd 服务,同理,在节点 slave1 和 slave2 上也需要重启 sshd 服务。
systemctl restart sshd.service
(4)生成公钥和私钥。
首先,切换到普通用户 xuluhui 下,利用“cd ~”命令切换回到用户 zhu的家目录下,
使用命令“ssh-keygen”在家目录中生成公钥和私钥,如图所示。图中,文件 id_rsa是私钥,文件 id_rsa.pub 是公钥。

其次,使用以下命令把公钥 id_rsa.pub 的内容追加到 authorized_keys 授权密钥文件中。

最后,使用以下命令修改密钥文件的相应权限。

5)共享公钥。
经过共享公钥后,就不再需要输入密码。因为只有 1 主 2 从节点,所以直接复制公钥比
较方便,将 hadoop100 的公钥直接复制给 hadoop101,hadoop102 就可以解决主节点连接从节点时需要密码的问题,过程如图所示。
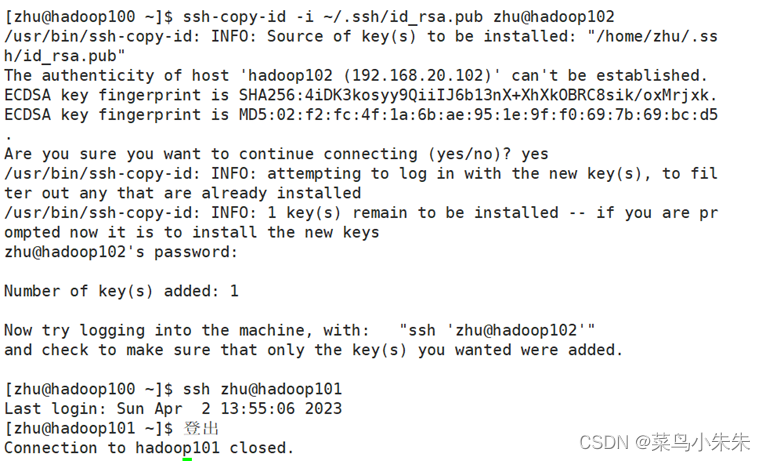
从上图可以看出,已能从 hadoop100 机器通过“ssh”命令免密登录到 hadoop101机器上。同理,将hadoop100的公钥首先通过命令“ssh-copy-id -i ~/.ssh/id_rsa.pub zhu@hadoop101”复制给hadoop102,然后测试是否可以通过“ssh”命令免密登录 hadoop102。
为了使主节点 hadoop100能通过“ssh”命令免密登录自身,使用“ssh hadoop100”命令尝试登录自身,第 1 次连接时需要人工干预输入“yes”,然后会自动将 hadoop100 的 key 加入/home/zhu/.ssh/know_hosts 文件中,此时即可登录到自身。第 2 次执行命令“ssh hadoop100”时就可以免密登录到自身。
至此,可以从 hadoop100节点通过“ssh”命令免密登录到自身、hadoop101和 hadoop102了,这对Hadoop 已经足够,但是若想达到所有节点之间都能免密登录的话,还需要在 hadoop101, hadoop102上各执行 3 次,也就是说两两共享密钥,这样累计共执行 9 次。
4. 获取和安装 Hadoop
以下步骤需要在 hadoop100、hadoop101和 hadoop102三个节点上均要完成。
** 4.1. 获取 Hadoop**
Hadoop 官方下载地址为 http://hadoop.apache.org/releases.html,本书选用的 Hadoop 版本是 2018 年 11 月 19 日发布的稳定版 Hadoop 2.9.2,其安装包文件 hadoop-2.9.2.tar.gz 例如存放在/home/zhu/下载 中。
** 4.2.安装 Hadoop**
(1)切换到 root 用户,将 hadoop-2.9.2.tar.gz 解压到目录/usr/local 下,具体命令如下所
示
[zhu@hadoop100 ~]$ su root
[root@hadoop100~]# cd /usr/local
[root@hadoop100 local]# tar -zxvf /home/xuluhui/Downloads/hadoop-2.9.2.tar.gz
(2)将 Hadoop 安装目录的权限赋给zhu用户,输入以下命令。

**5. 配置全分布模式 Hadoop **集群
需要说明的是,为了方便,下文中步骤 1-9 均在主节点 hadoop100 上进行,从节点 hadoop101、hadoop102上的配置文件可以通过“scp”命令同步复制。
** 5.1. 在系统配置文件目录/etc/profile.d 下新建 hadoop.sh**
切换到 root 用户,使用“vim /etc/profile.d/hadoop.sh”命令在/etc/profile.d 文件夹下新建文件 hadoop.sh,添加如下内容。
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使用命令“source /etc/profile.d/hadoop.sh”重新加载配置文件或者重启机器,使之生效当前系统变量“PATH”值如图所示。

此步骤可省略,之所以将 Hadoop 安装目录下 bin 和 sbin 加入到系统环境变量 PATH 中,是因为当输入启动和管理 Hadoop 集群命令时,无需再切换到 Hadoop 安装目录下的 bin 目录或者 sbin 目录,否则会出现错误信息“bash: ****: command not found...”。
由于上文已将 Hadoop 安装目录的权限赋给 zhu 用户,所以接下来的 2-9 步骤均在普通用户 zhu 下完成。配置的文件都在/usr/local/hadoop-2.9.2/etc/hadoop中。
** 5.2. 配置 hadoop-env.sh**
环境变量配置文件 hadoop-env.sh 主要配置 Java 的安装路径 JAVA_HOME、Hadoop 日志存储路径 HADOOP_LOG_DIR 及添加 SSH 的配置选项 HADOOP_SSH_OPTS 等。本书中关于 hadoop-env.sh 配置文件的修改具体如下。
(1)第 25 行“export JAVA_HOME=${JAVA_HOME}”修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_191
(2)第 26 行空行处加入:
export HADOOP_SSH_OPTS='-o StrictHostKeyChecking=no'
这里要说明的是,SSH 的选项“StrictHostKeyChecking”用于控制当目标主机尚未进行过认证时,是否显示信息“Are you sure you want to continue connecting (yes/no)?”。所以当登录其它机器时,只需要设置参数“HADOOP_SSH_OPTS”的值为“-o StrictHostKeyChecking=no”就可以直接登录,不会有上面的提示信息,不需要人工干预输入“yes”,而且还会将目标主机 key 加到~/.ssh/known_hosts 文件里。
(3)第 113 行“export HADOOP_PID_DIR=${HADOOP_PID_DIR}”指定 HDFS 守护进程号的保存位置,默认为“/tmp”,由于该文件夹用以存放临时文件,系统定时会自动清理,因此本书将“HADOOP_PID_DIR”设置为 Hadoop 安装目录下的目录 pids,如下所示,其中目录 pids 会随着 HDFS 守护进程的启动而由系统自动创建,无需用户手工创建。
export HADOOP_PID_DIR=${HADOOP_HOME}/pid
5.3. 配置 mapred-env.sh
环境变量配置文件 mapred-env.sh 主要配置 Java 安装路径 JAVA_HOME、MapReduce 日志存储路径 HADOOP_MAPRED_LOG_DIR 等,之所以再次设置 JAVA_HOME,是为了保证所有进程使用的是同一个版本的 JDK。本书中关于 mapred-env.sh 配置文件的修改具体如下。
(1)第 16 行注释“# export JAVA_HOME=/home/y/libexec/jdk1.6.0/”修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_191
(2)第 28 行指定 MapReduce 守护进程号的保存位置,默认为“/tmp”,同以上“HADOOP_PID_DIR”,此处注释“#export HADOOP_MAPRED_PID_DIR=”修改为 Hadoop安装目录下的目录 pids,如下所示,其中目录 pids 会随着 MapReduce 守护进程的启动而由系统自动创建,无需用户手工创建。
export HADOOP_MAPRED_PID_DIR=${HADOOP_HOME}/pids
** 5.4 配置 yarn-env.sh**
YARN 是 Hadoop 的资源管理器,环境变量配置文件 yarn-env.sh 主要配置 Java 安装路
径 JAVA_HOME 及 YARN 日志存放路径 YARN_LOG_DIR 等。本书中关于 yarn-env.sh 配置文件的修改具体如下。
(1)第 23 行注释“# export JAVA_HOME=/home/y/libexec/jdk1.6.0/”修改为:
export JAVA_HOME=/usr/java/jdk1.8.0_191
(2)yarn-env.sh 文件中并未提供 YARN_PID_DIR 配置项,用于指定 YARN 守护进程
号的保存位置,在该文件最后添加一行,内容如下所示,其中目录 pids 会随着 YARN 守护进程的启动而由系统自动创建,无需用户手工创建。
export YARN_PID_DIR=${HADOOP_HOME}/pids
5.5 配置 core-site.xml
core-site.xml 是 hadoop core 配置文件,如 HDFS 和 MapReduce 常用的 I/O 设置等,其中包括很多配置项,但实际上,大多数配置项都有默认项,也就是说,很多配置项即使不配置,也无关紧要,只是在特定场合下,有些默认值无法工作,这时再找出来配置特定值。关于 core-site.xml 配置文件的修改如下所示。

5.6 配置 hdfs-site.xml
hdfs-site.xml 配置文件主要配置 HDFS 分项数据,如字空间元数据、数据块、辅助节点的检查点的存放路径等,不修改配置项的采用默认值即可,本书中关于 hdfs-site.xml 配置文件未做任何修改。
由于上一步对 core-site.xml 的修改中将 Hadoop 的临时目录设置为“/usr/local/hadoop-2.9.2/hdfsdata”,故本书中将元数据存放在主节点的“/usr/local/hadoop-2.9.2/hdfsdata/dfs/name”,数据块存放在从节点的“/usr/local/hadoop-2.9.2/hdfsdata/dfs/data”,辅助节点的检查点存放在主节点的“/usr/local/hadoop-2.9.2/hdfsdata/dfs/namesecondary”,这些目录都会随着 HDFS 的格式化、HDFS 守护进程的启动而由系统自动创建,无需用户手工创建。
** 5.7 配置 mapred-site.xml**
mapred-site.xml 配置文件是有关 MapReduce 计算框架的配置信息,Hadoop 配置文件中没有 mapred-site.xml,但有 mapred-site.xml.template,读者使用命令例如“cp mapred-site.xml.template mapred-site.xml”将其复制并重命名为“mapred-site.xml”即可,然后用 vi编辑相应的配置信息,本书中对于 mapred-site.xml 的添加内容如下所示。

5.8 配置 yarn-site.xml
yarn-site.xml 是有关资源管理器的 YARN 配置信息,本书中对于 yarn-site.xml 的添加内容如下所示。

由于之前步骤已将 core-site.xml 中 Hadoop 的临时目录设置为“/usr/local/hadoop-2.9.2/hdfsdata”,故本书中未修改配置项“yarn.nodemanager.local-dirs”,中间结果的存放位置为“/usr/local/hadoop-2.9.2/hdfsdata/nm-local-dir”,这个目录会随着 YARN 守护进程的启动而在由系统自动在所有从节点上创建,无需用户手工创建。另外,“yarn.nodemanager.aux-services”需配置成“mapreduce_shuffle”,才可运行 MapReduce 程序
** 5.9配置 slaves**
配置文件 slaves 用于指定从节点主机名列表,在这个文件中,需要添加所有的从节点主机名,每一个主机名占一行,本书中 slaves 文件的内容如下所示。
hadoop101
hadoop102
需要注意的是,在 slaves 文件里,有一个默认值“localhost”,一定要删除,若不删除,虽然后面添加了所有的从节点主机名,Hadoop 还是无法逃脱“伪分布模式”的命运。
** 5.10 **同步配置文件
以上配置文件要求 Hadoop 集群中每个节点都“机手一份”,快捷的方法是在主节点hadoop100 上配置好,然后利用“scp”命令将配置好的文件同步到从节点 hadoop101、hadoop102上。scp 是 secure copy 的缩写,该命令用于在 Linux 下进行远程文件的拷贝,该命令用于在Linux 系统进行远程文件的拷贝,可以在 Linux 服务器之间复制文件和目录。
(1)同步 hadoop.sh
切换到 root 用户下,将 hadoop100 节点上的文件 hadoop.sh 同步到其他 2 台从节点上,命令如下所示。
[root@hadoop100 ~]# scp /etc/profile.d/hadoop.sh root@hadoop101:/etc/profile.d/
[root@hadoop100 ~]# scp /etc/profile.d/hadoop.sh root@hadoop102:/etc/profile.d/
(2)同步 Hadoop 配置文件
切换到普通用户 xuluhui 下,将 hadoop100 上/usr/local/hadoop-2.9.2/etc/hadoop 下的配置文件同步到其他 2 个从节点上。
首先,通过如下命令将主节点 hadoop100 上的 Hadoop 配置文件同步到从节点 hadoop101 上,具体执行效果如图所示。
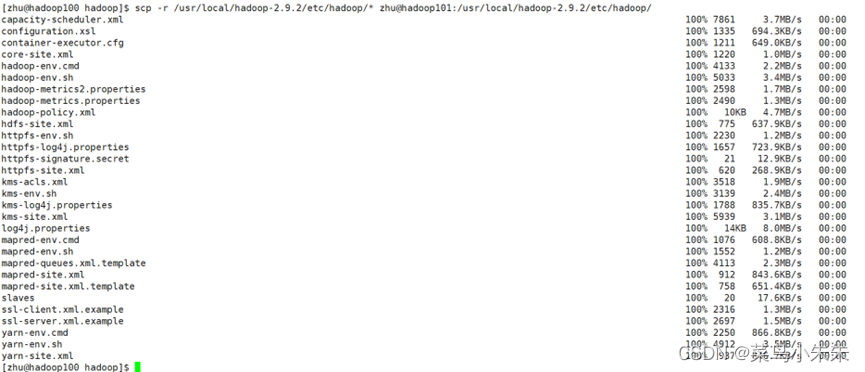
其次,通过相同方法将主节点 hadoop100 上的 Hadoop 配置文件同步到从节点 hadoop102 上,具体命令如下所示,此处略去执行效果的图片。
[zhu@hadoop100 hadoop]$ scp -r /usr/local/hadoop-2.9.2/etc/hadoop/* zhu@hadoop102:/usr/local/hadoop-2.9.2/etc/hadoop/
至此,1 主节点 2 从节点的 Hadoop 全分布模式集群全部配置结束,重启三台机器,使
得上述配置生效。
**6. **关闭防火墙
为了方便 Hadoop 集群间相互通信,建议关闭防火墙,若防火墙没有关闭,可能会导致Hadoop 虽然可以启动,但是数据节点 DataNode 无法连接名称节点 NameNode,如图 所示,Hadoop 集群启动正常,但数据容量为 0B,数据节点数量也是 0
CentOS 7 下关闭防火墙的方式有两种:命令“systemctl stop firewalld.service”用于临时关闭防火墙,重启机器后又会恢复到默认状态;命令“systemctl disable firewalld.service”用于永久关闭防火墙。编者采用在 master 节点上以 root 身份使用第 2 个命令,具体效果如图所示。
重启机器,使用命令“systemctl status firewalld.service”查看防火墙状态,如图所示,防火墙状态为“inactive (dead)”。
同理,关闭所有从节点 slave1、slave2 的防火墙。
**7. **格式化文件系统
在主节点 hadoop100 上以普通用户 zhu 身份输入以下命令,进行 HDFS 文件系统的格式 化。注意,此命令必须在主节点 zhu上执行,切勿在从节点上执行。
[zhu@hadoop100 logs]$ hdfs namenode -format
8. 启动和验证 Hadoop
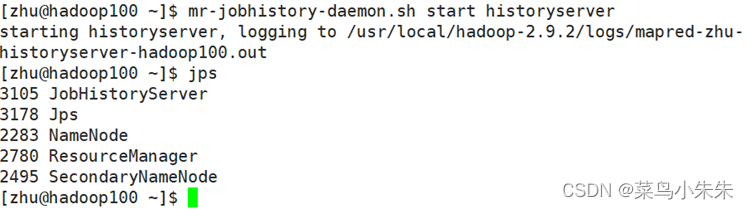
启动全分布模式 Hadoop 集群的守护进程,只需在主节点 hadoop100 上依次执行以下 3 条命令即可。
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
“start-dfs.sh”命令会在节点上启动 NameNode、DataNode 和 SecondaryNameNode 服务。“start-yarn.sh”命令会在节点上启动 ResourceManager 和 NodeManager 服务。“mr-jobhistorydaemon.sh start historyserver”命令会在节点上启动 JobHistoryServer 服务。请注意,即使对应的守护进程没有启动成功,Hadoop 也不会在控制台显示错误消息,读者可以利用“jps”命令一步一步查询,逐步核实对应的进程是否启动成功。


Hadoop 也提供了基于 Web 的管理工具,因此,Web 也可以用来验证全分布模式 Hadoop集群是否部署成功且正确启动。其中 HDFS Web UI 的默认地址为 http://namenodeIP:50070,运行界面如图1所示;YARN Web UI 的默认地址为 http://resourcemanagerIP:8088,运行界面如图2所示;MapReduce Web UI 的默认地址为 http://jobhistoryserverIP:19888,运行界面如图3所示。

图 1 HDFS Web UI 效果图

图 2 YARN Web UI 效果图
 图 3 图3 MapReduce Web UI 效果图
图 3 图3 MapReduce Web UI 效果图
9. 关闭 Hadoop
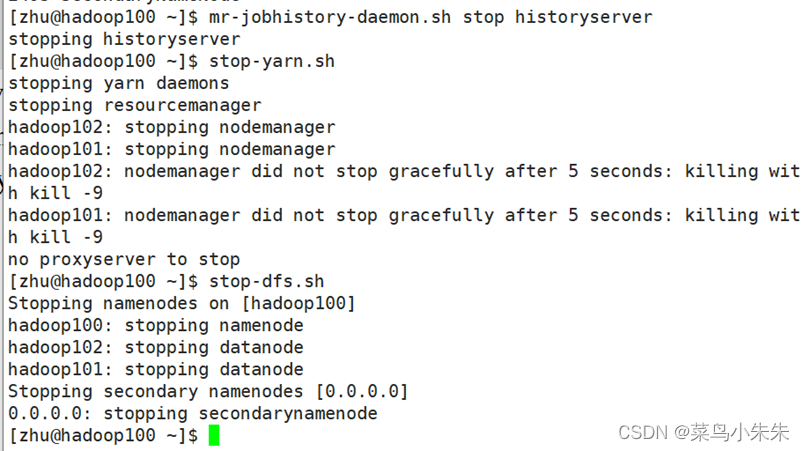
关闭全分布模式 Hadoop 集群的命令与启动命令次序相反,只需在主节点 master 上依次执行以下 3 条命令即可关闭 Hadoop。
mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh
版权归原作者 菜鸟小朱朱 所有, 如有侵权,请联系我们删除。