
1.首先在hive目录下启动hiveserver2服务
1)通过命令: bin/hive --service hiveserver2 启动(该方式会占用命令行,不推荐)
2)通过命令: nohup bin/hiveserver2 >/dev/null 2>&1 & 启动(不会占用命令行)
nohup: 该命令用于忽略终端关闭信号(SIGHUP),使得命令在后台运行时不会受到终端关闭的影响。bin/hiveserver2: 这是启动 HiveServer2 进程的命令或脚本的路径。>/dev/null:>符号用于重定向输出,并将标准输出重定向到/dev/null设备文件,这相当于将输出丢弃,不会在终端上显示。2>&1:2表示标准错误输出(stderr),&1表示将其重定向到标准输出(stdout)。因此,2>&1表示将标准错误输出与标准输出合并为同一个流,也会被重定向到/dev/null,即错误输出也被丢弃。&:&符号表示将命令放入后台运行。
2.两种使用方式
方式一:使用命令行客户端beeline进行远程访问
新开一个命令行窗口,输入命令: bin/beeline -u jdbc:hive2://hadoop102:10000 -n name
bin/beeline: 这是执行 Beeline 命令行工具的路径。-u jdbc:hive2://hadoop102:10000:-u是指定连接的 URL 参数,jdbc:hive2://hadoop102:10000是 HiveServer2 的连接 URL。其中,hadoop102是 HiveServer2 所在的主机名或 IP 地址,10000是 HiveServer2 的监听端口。-n name:-n是指定用户名参数,name 是要使用的用户名。
方式二:使用DataGrip可视化工具连接hive
1)打开左上角+号,添加新的连接
2)选择Data Source
- 选择连接hive

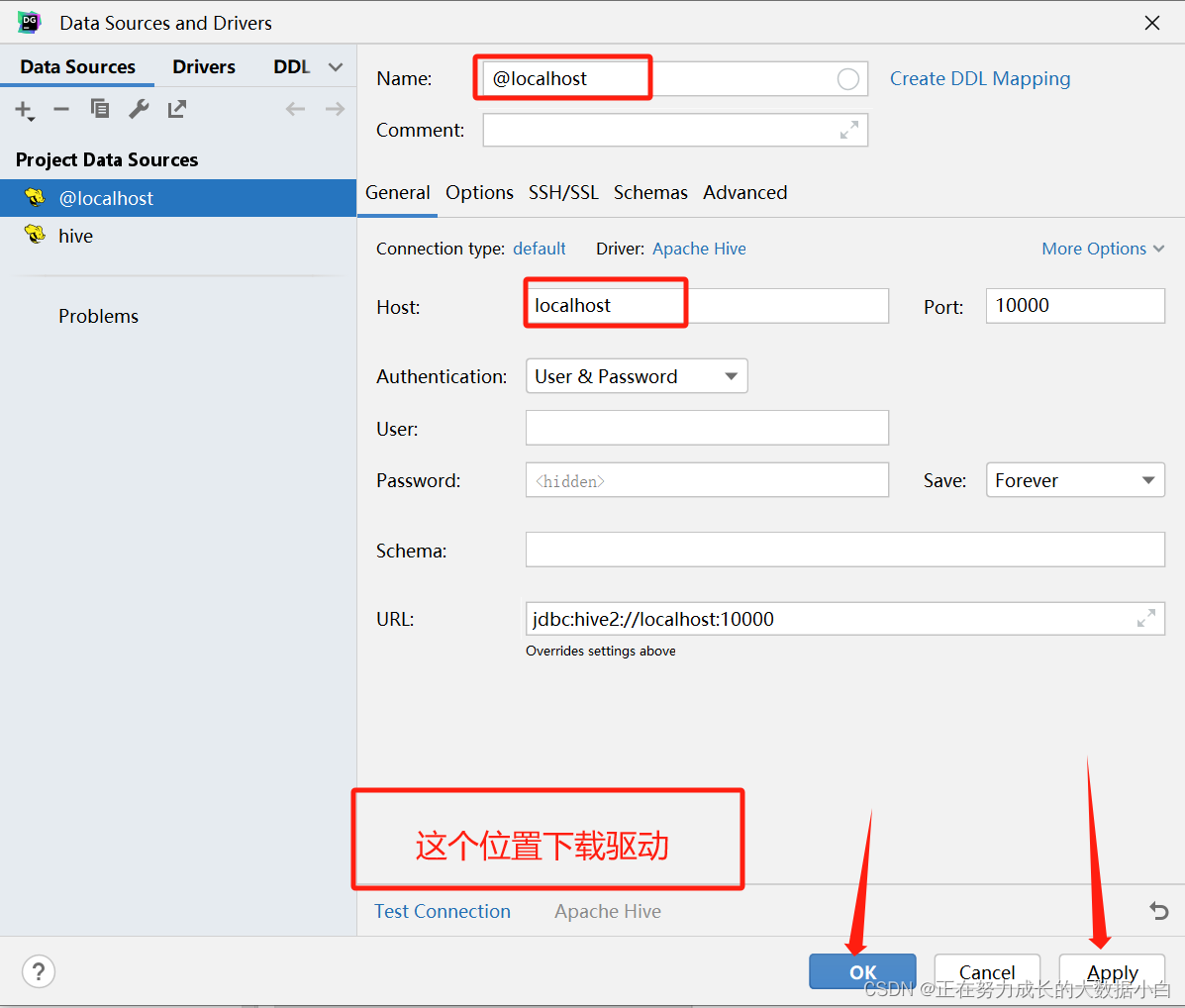
4)输入名称(自己取名),Host改成启动hiveserver2的主机名就OK, Port端口默认10000, 第一次连接需要下载驱动,完成上述步骤点击Apply应用,点击OK。 可视化连接就完成啦~
创作不易,如果觉得有用,点个赞呗,评论区可以留言,遇到的问题一起探讨~~
本文转载自: https://blog.csdn.net/m0_63960309/article/details/133547260
版权归原作者 婉然从物 所有, 如有侵权,请联系我们删除。
版权归原作者 婉然从物 所有, 如有侵权,请联系我们删除。