
1.数据集简介、训练集与测试集划分
2.模型相关知识
3.model.py——定义ResNet50网络模型
4.train.py——加载数据集并训练,训练集计算损失值loss,测试集计算accuracy,保存训练好的网络参数
5.predict.py——利用训练好的网络参数后,用自己找的图像进行分类测试
一、数据集简介
1.自建数据文件夹
首先确定这次分类种类,采用爬虫、官网数据集和自己拍照的照片获取5类,新建个文件夹data,里面包含5个文件夹,文件夹名字取种类英文,每个文件夹照片数量最好一样多,五百多张以上。如我选了雏菊,蒲公英,玫瑰,向日葵,郁金香5类,如下图,每种类型有600~900张图像。如下图
花数据集下载链接https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
2.划分训练集与测试集
这是划分数据集代码,同一目录下运,复制改文件夹路径。
import os
from shutil import copy
import random
defmkfile(file):ifnot os.path.exists(file):
os.makedirs(file)# 获取 photos 文件夹下除 .txt 文件以外所有文件夹名(即3种分类的类名)
file_path ='data/flower_photos'
flower_class =[cla for cla in os.listdir(file_path)if".txt"notin cla]# 创建 训练集train 文件夹,并由3种类名在其目录下创建3个子目录
mkfile('flower_data/train')for cla in flower_class:
mkfile('flower_data/train/'+ cla)# 创建 验证集val 文件夹,并由3种类名在其目录下创建3个子目录
mkfile('flower_data/val')for cla in flower_class:
mkfile('flower_data/val/'+ cla)# 划分比例,训练集 : 验证集 = 9 : 1
split_rate =0.1# 遍历3种花的全部图像并按比例分成训练集和验证集for cla in flower_class:
cla_path = file_path +'/'+ cla +'/'# 某一类别动作的子目录
images = os.listdir(cla_path)# iamges 列表存储了该目录下所有图像的名称
num =len(images)
eval_index = random.sample(images, k=int(num * split_rate))# 从images列表中随机抽取 k 个图像名称for index, image inenumerate(images):# eval_index 中保存验证集val的图像名称if image in eval_index:
image_path = cla_path + image
new_path ='flower_data/val/'+ cla
copy(image_path, new_path)# 将选中的图像复制到新路径# 其余的图像保存在训练集train中else:
image_path = cla_path + image
new_path ='flower_data/train/'+ cla
copy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index +1, num), end="")# processing barprint()print("processing done!")
二、模型相关知识
之前有文章介绍模型,如果不清楚可以点下链接转过去学习。
深度学习卷积神经网络CNN之ResNet模型网络详解说明(超详细理论篇)
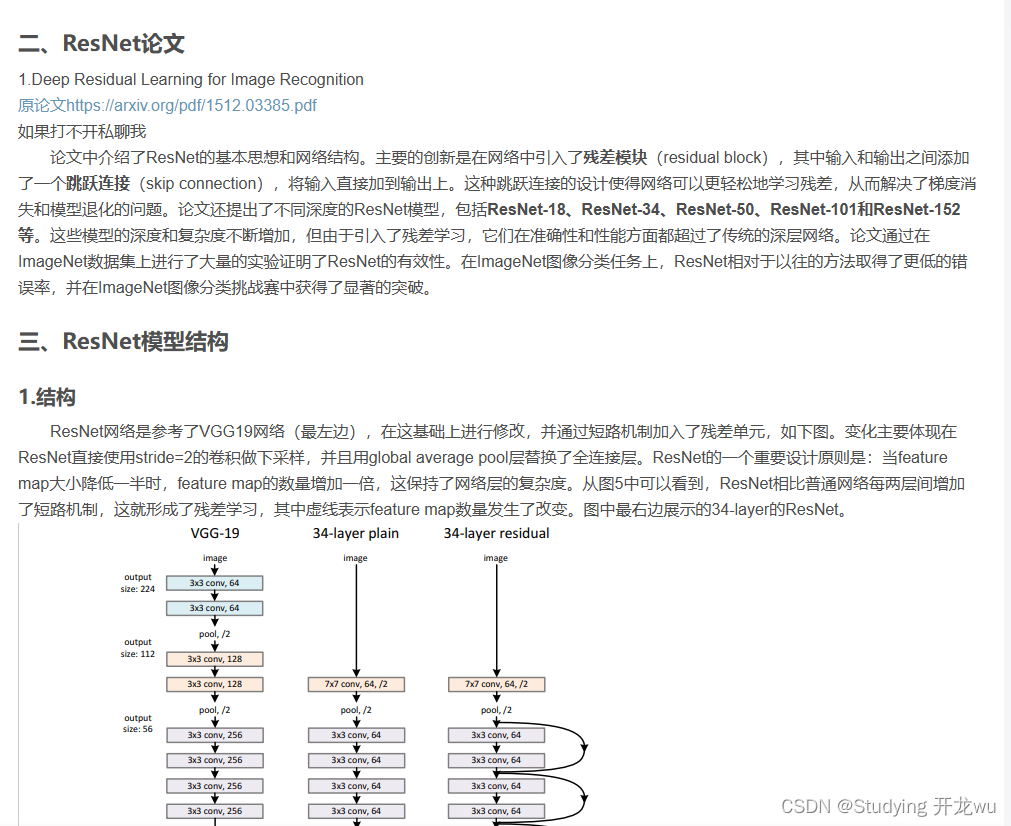
三、model.py——定义ResNet50网络模型
import torch.nn as nn
import torch
classBasicBlock(nn.Module):
expansion =1def__init__(self, in_channel, out_channel, stride=1, downsample=None,**kwargs):super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
defforward(self, x):
identity = x
if self.downsample isnotNone:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)return out
classBottleneck(nn.Module):"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion =4def__init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):super(Bottleneck, self).__init__()
width =int(out_channel *(width_per_group /64.))* groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False)# squeeze channels
self.bn1 = nn.BatchNorm2d(width)# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False)# unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
defforward(self, x):
identity = x
if self.downsample isnotNone:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)return out
classResNet(nn.Module):def__init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel =64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block,64, blocks_num[0])
self.layer2 = self._make_layer(block,128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block,256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block,512, blocks_num[3], stride=2)if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1,1))# output size = (1, 1)
self.fc = nn.Linear(512* block.expansion, num_classes)for m in self.modules():ifisinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')def_make_layer(self, block, channel, block_num, stride=1):
downsample =Noneif stride !=1or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers =[]
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ inrange(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))return nn.Sequential(*layers)defforward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x,1)
x = self.fc(x)return x
defresnet34(num_classes=1000, include_top=True):# https://download.pytorch.org/models/resnet34-333f7ec4.pthreturn ResNet(BasicBlock,[3,4,6,3], num_classes=num_classes, include_top=include_top)defresnet50(num_classes=1000, include_top=True):# https://download.pytorch.org/models/resnet50-19c8e357.pthreturn ResNet(Bottleneck,[3,4,6,3], num_classes=num_classes, include_top=include_top)defresnet101(num_classes=1000, include_top=True):# https://download.pytorch.org/models/resnet101-5d3b4d8f.pthreturn ResNet(Bottleneck,[3,4,23,3], num_classes=num_classes, include_top=include_top)defresnext50_32x4d(num_classes=1000, include_top=True):# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups =32
width_per_group =4return ResNet(Bottleneck,[3,4,6,3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)defresnext101_32x8d(num_classes=1000, include_top=True):# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups =32
width_per_group =8return ResNet(Bottleneck,[3,4,23,3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
四、model.py——定义ResNet34网络模型
batch_size = 16
epochs = 5
import os
import sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model import resnet50
defmain():
device = torch.device("cuda:0"if torch.cuda.is_available()else"cpu")print("using {} device.".format(device))
data_transform ={"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])]),"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])}
data_root = os.path.abspath(os.path.join(os.getcwd(),"../.."))# get data root path
image_path = os.path.join(data_root,"zjdata","flower_data")# flower data set pathassert os.path.exists(image_path),"{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path,"train"),
transform=data_transform["train"])
train_num =len(train_dataset)# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict =dict((val, key)for key, val in flower_list.items())# write dict into json file
json_str = json.dumps(cla_dict, indent=4)withopen('class_indices.json','w')as json_file:
json_file.write(json_str)
batch_size =16
nw =min([os.cpu_count(), batch_size if batch_size >1else0,8])# number of workersprint('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path,"val"),
transform=data_transform["val"])
val_num =len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = resnet50(num_classes=5, include_top=True)
net.to(device)# define loss function
loss_function = nn.CrossEntropyLoss()# construct an optimizer
params =[p for p in net.parameters()if p.requires_grad]
optimizer = optim.Adam(params, lr=0.1)
epochs =5
best_acc =0.0
save_path ='./resNet50.pth'
train_steps =len(train_loader)for epoch inrange(epochs):# train
net.train()
running_loss =0.0
train_bar = tqdm(train_loader,file=sys.stdout)for step, data inenumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()# print statistics
running_loss += loss.item()
train_bar.desc ="train epoch[{}/{}] loss:{:.3f}".format(epoch +1,
epochs,
loss)# validate
net.eval()
acc =0.0# accumulate accurate number / epochwith torch.no_grad():
val_bar = tqdm(validate_loader,file=sys.stdout)for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc ="valid epoch[{}/{}]".format(epoch +1,
epochs)
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f'%(epoch +1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)print('Finished Training')if __name__ =='__main__':
main()
训练中截图
五、predict.py——利用训练好的网络参数后,用自己找的图像进行分类测试
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import resnet34
defmain():
device = torch.device("cuda:0"if torch.cuda.is_available()else"cpu")
data_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])# load image
img_path ="./1.jpg"assert os.path.exists(img_path),"file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)# [N, C, H, W]
img = data_transform(img)# expand batch dimension
img = torch.unsqueeze(img, dim=0)# read class_indict
json_path ='./class_indices.json'assert os.path.exists(json_path),"file: '{}' dose not exist.".format(json_path)withopen(json_path,"r")as f:
class_indict = json.load(f)# create model
model = resnet34(num_classes=5).to(device)# load model weights
weights_path ="./resNet50.pth"assert os.path.exists(weights_path),"file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path, map_location=device))# prediction
model.eval()with torch.no_grad():# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res ="class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)for i inrange(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()if __name__ =='__main__':
main()
本文转载自: https://blog.csdn.net/qq_55433305/article/details/131176242
版权归原作者 Studying 开龙wu 所有, 如有侵权,请联系我们删除。
版权归原作者 Studying 开龙wu 所有, 如有侵权,请联系我们删除。