
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、实验目的
- 掌握机器学习建模分析
- 掌握回归分析、分类分析、聚类分析、降维等
- 了解各分类器之间的差异
二、实验环境
- ** ** 操作系统:Windows
- 应用软件:anaconda jupyter
三、实验内容与结果
1、SVM(support vector Machine)是什么?
支持向量机是基于数学优化方法的分类学习算法
• 通过使用最大分类间隔(Margin)来确定最优的最优的划分超平面,以获得良好的泛化能力
• 通过核函数的方法将低维数据映射到高维空间,并使得在高维空间的数据是线性可分的,从而能够处理低维空间中线性不可分的情况
具体理解可参考以下链接:[白话解析] 深入浅出支持向量机(SVM)之核函数 - 腾讯云开发者社区-腾讯云
2、SVM能干什么?
• SVM最基本的应用:分类
• 求解一个最优的分类面,将数据集分割为两个的子集
• 数据集在低维空间中无法使用超平面划分
• 映射到高维空间,寻找超平面分割
3、SVM如何实现?
SVM采用核函数(Kernel Function)将低维数据映射到高维空间
• 多种核函数,适应不同特性的数据集,影响SVM分类性能的关键因素
• 常用的核函数:线性核、多项式核、高斯核和sigmoid核等

4、独热编码:独热编码(One-Hot Encoding) - 知乎
可以大概这么理解:平等地位的就独热编码,有大小顺序的就标签编码;
其实严格来说性别也应该独热编码,因为他们是平等的。
5、 随机森林算法的基本原理
核心思想是“三个臭皮匠,顶个诸葛亮”
• 通过随机的方式建立一个森林
• 每棵树都是由从训练集中抽取的部分样本,且基于部分随机选择的特征子集训练构建
• 预测未知数据时,多个决策树投票决定最终结果:如果是数值形的输出,则采取多个决策树结果的平均或者加权作为最终输出;如果是分类任务,则采取投票机制或者是加权作为最终输出。
四、模型构建
例题
1.使用scikit-learn建立SVM模型为葡萄酒数据集构造分类器(分类结果为’good’或‘not’ ) [“不可使用quantity”列]
2.评估分类器在此数据集上的分类性能* 需要划分训练集和测试集
1、读入数据

原始数据共有3899条。
代码如下:
import pandas as pd
filename='data\wine.csv'
data=pd.read_csv(filename,index_col='idx')
data.loc[data['good_or_not']=='good','good_or_not']=1
data.loc[data['good_or_not']=='not','good_or_not']=0
data.drop('quality',axis=1,inplace=True)
print(data[0:5])
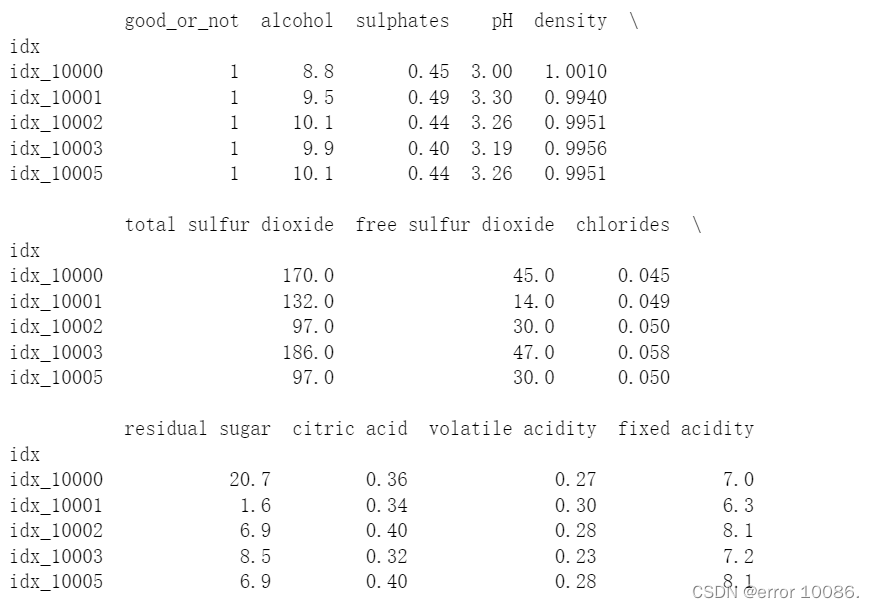
2、数据初始化
代码如下(示例):
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.preprocessing import MinMaxScaler
x = data.drop('good_or_not', axis=1).values.astype(float)
y = data['good_or_not'].values.astype(float)
print(type(x),type(y))
3、训练模型,评价分类器性能
from sklearn import svm
clf = svm.SVC(kernel='rbf', gamma=0.6, C=100)
clf.fit(x,y)
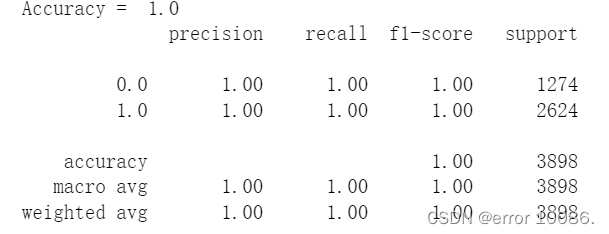
print('Accuracy = ', clf.score(x, y))
y_pred = clf.predict(x)
from sklearn import metrics
print(metrics.classification_report( y, y_pred) )
4、将数据集拆分为训练集和测试集,在测试集上查看分类效果
from sklearn import svm
from sklearn import model_selection
x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, test_size=0.2,random_state=1)
clf = svm.SVC(kernel='rbf',gamma=0.7, C=1)
clf.fit(x_train, y_train)
b = clf.score(x_train, y_train)
print("训练集准确率:",b)
a = clf.score(x_test, y_test)
print("测试集准确率:",a)
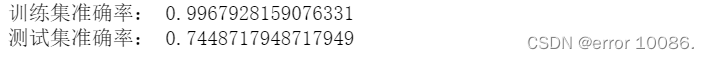
5、数据处理
from sklearn import preprocessing
from sklearn import model_selection
% 对不同方差的数据标准化
x_scale = preprocessing.scale(x)
%将标准化后的数据集拆分为训练集和测试集,在测试集上查看分类效果
from sklearn import svm
x_train, x_test, y_train, y_test = model_selection.train_test_split(x_scale, y, test_size=0.2,random_state=1)
clf = svm.SVC(kernel='rbf',gamma=0.7, C=30)
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
a = clf.score(x_test, y_test)
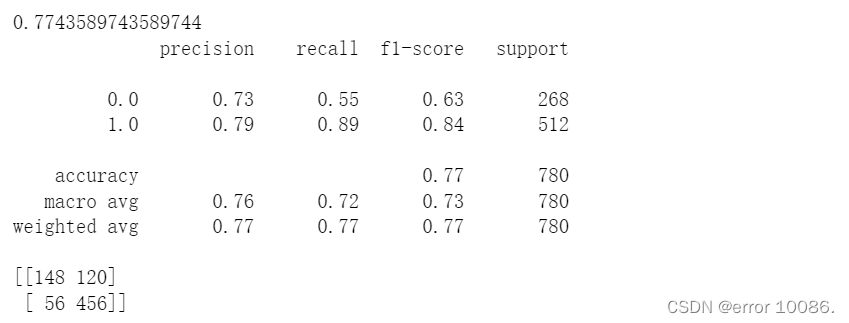
print(a)
print(metrics.classification_report(y_test, y_pred))
print(metrics.confusion_matrix(y_test, y_pred))
3.使用scikit-learn建立随机森林回归模型预测葡萄酒质量(1-10之间)[“不可使用good_or_not”列]
step 1. 从文件中读入数据,进行预处理,将所有特征转换为数值型
import numpy as np
import pandas as pd
filename='data\wine.csv'
data=pd.read_csv(filename,index_col='idx')
data.drop('good_or_not',axis=1,inplace=True)
x = data.drop('quality', axis=1).values.astype(float)
y = data['quality'].values.astype(float)
step 2. 从DataFrame对象中取出特征矩阵X和分类标签y,无需进行归一化处理
%划分测试集和训练集
from sklearn import model_selection
x_train, x_test, y_train, y_test = model_selection.train_test_split(x,y, test_size=0.3, random_state=1)
step 3. 使用随机森林算法训练集成分类器
参数n_ estimators和max_depth的设置直接影响模型的性能
且不同的数据集取值差别较大,通常通过搜索的方式找出合适的值
from sklearn.ensemble import RandomForestClassifier
%固定决策树个数,搜索最大深度max_depth在给定范围内的最优取值
%从1到10中探索最优深度
d_score = []
for i in range(1,10):
RF = RandomForestClassifier(n_estimators=15, criterion='entropy', max_depth=i)
RF.fit(x_train, y_train)
d_score.append(RF.score(x_test, y_test))
depth = d_score.index(max(d_score)) #列表求最大值的索引
print(depth,d_score[depth])

% 按最优深度,搜索最优决策树个树n_estimators
% 从1到21中探索最优决策树的数目
e_score = []
for i in range(1,21):
RF = RandomForestClassifier(n_estimators=i, criterion='entropy', max_depth=depth)
RF.fit(x_train, y_train)
e_score.append(RF.score(x_test, y_test))
est = e_score.index(max(e_score))
print(est,e_score[est])

%双层搜索
scores = [] % 记录深度
pos = [] %记录决策树数目
for i in range(1, 10): %深度
temp = []
for j in range(1, 40): % 决策树数目
RF = RandomForestClassifier(n_estimators=j, criterion='entropy', max_depth=i)
RF.fit(x_train, y_train)
temp.append(RF.score(x_test, y_test))
scores.append(max(temp))% 存储这21个中表现最好的模型的scores
pos.append(temp.index(max(temp))) % 存储表现最好的模型的决策树数目
max_scores = max(scores) % 找出每种深度下的所有模型的最好模型
si = scores.index(max(scores)) % 该最好模型对应的决策树的数目
depth = pos[si]
print(max_scores, depth)

总结
以上就是今天要讲的内容,本文仅仅简单介绍了使用SVM模型对葡萄酒的数据进行回归分析的使用,SVM的算法添加了限制条件,来保证尽可能减少不可分割的点的影响,使分割达到相对最优。
版权归原作者 error 10086. 所有, 如有侵权,请联系我们删除。