
1. 环境介绍
服务版本zookeeper3.8.0kafka3.3.1flink1.13.5mysql5.7.34jdk1.8scala2.12连接器作用flink-sql-connector-upsert-kafka_2.11-1.13.6.jar连接kafka,支持主键更新flink-connector-mysql-cdc-2.0.2.jar读mysqlflink-connector-jdbc_2.11-1.13.6.jar写mysqlmysql-connector-java-5.1.37.jar连接mysql
2. mysql中建表
CREATE TABLE src_mysql_order(
order_id BIGINT,
store_id BIGINT,
sales_amt double,
PRIMARY KEY (`order_id`)
);
CREATE TABLE src_mysql_order_detail(
order_id BIGINT,
store_id BIGINT,
goods_id BIGINT,
sales_amt double,
PRIMARY KEY (order_id,store_id,goods_id)
);
CREATE TABLE dim_store(
store_id BIGINT,
store_name varchar(100),
PRIMARY KEY (`store_id`)
);
CREATE TABLE dim_goods(
goods_id BIGINT,
goods_name varchar(100),
PRIMARY KEY (`goods_id`)
);
CREATE TABLE dwa_mysql_order_analysis (
store_id BIGINT,
store_name varchar(100),
sales_goods_distinct_nums bigint,
sales_amt double,
order_nums bigint,
PRIMARY KEY (store_id,store_name)
);
3. flinksql建表
3.1 进入flinksql客户端
sql-client.sh embedded
 3.2 配置输出格式
3.2 配置输出格式
SET sql-client.execution.result-mode=tableau;

3.3 flink建表
--mysql中的 订单主表
CREATE TABLE src_mysql_order(
order_id BIGINT,
store_id BIGINT,
sales_amt double,
PRIMARY KEY (`order_id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop002',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'test',
'table-name' = 'src_mysql_order',
'scan.incremental.snapshot.enabled' = 'false'
);
--mysql中的 订单明细表
CREATE TABLE src_mysql_order_detail(
order_id BIGINT,
store_id BIGINT,
goods_id BIGINT,
sales_amt double,
PRIMARY KEY (order_id,store_id,goods_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop002',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'test',
'table-name' = 'src_mysql_order_detail',
'scan.incremental.snapshot.enabled' = 'false'
);
--mysql中的 商店维表
CREATE TABLE dim_store(
store_id BIGINT,
store_name varchar(100),
PRIMARY KEY (`store_id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop002',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'test',
'table-name' = 'dim_store',
'scan.incremental.snapshot.enabled' = 'false'
);
--mysql中的 商品维表
CREATE TABLE dim_goods(
goods_id BIGINT,
goods_name varchar(100),
PRIMARY KEY (`goods_id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'hadoop002',
'port' = '3306',
'username' = 'root',
'password' = 'root',
'database-name' = 'test',
'table-name' = 'dim_goods',
'scan.incremental.snapshot.enabled' = 'false'
);
--kafka中的 ods层 订单表
CREATE TABLE ods_kafka_order (
order_id BIGINT,
store_id BIGINT,
sales_amt double,
PRIMARY KEY (`order_id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'ods_kafka_order',
'properties.bootstrap.servers' = 'hadoop001:9092',
'properties.group.id' = 'ods_group1',
'key.format' = 'json',
'value.format' = 'json'
);
----kafka中的 ods层 订单明细表
CREATE TABLE ods_kafka_order_detail (
order_id BIGINT,
store_id BIGINT,
goods_id BIGINT,
sales_amt double,
PRIMARY KEY (order_id,store_id,goods_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'ods_kafka_order_detail',
'properties.bootstrap.servers' = 'hadoop001:9092',
'properties.group.id' = 'ods_group1',
'key.format' = 'json',
'value.format' = 'json'
);
--kafka中的 dwd层 订单表
CREATE TABLE dwd_kafka_order (
order_id BIGINT,
store_id BIGINT,
sales_amt double,
PRIMARY KEY (`order_id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'dwd_kafka_order',
'properties.bootstrap.servers' = 'hadoop001:9092',
'properties.group.id' = 'dwd_group1',
'key.format' = 'json',
'value.format' = 'json'
);
--kafka中的 dwd层 订单明细表
CREATE TABLE dwd_kafka_order_detail (
order_id BIGINT,
store_id BIGINT,
goods_id BIGINT,
sales_amt double,
PRIMARY KEY (order_id,store_id,goods_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'dwd_kafka_order_detail',
'properties.bootstrap.servers' = 'hadoop001:9092',
'properties.group.id' = 'dwd_group1',
'key.format' = 'json',
'value.format' = 'json'
);
--mysql中的dwa 订单指标统计
CREATE TABLE dwa_mysql_order_analysis (
store_id BIGINT,
store_name varchar(100),
sales_goods_distinct_nums bigint,
sales_amt double,
order_nums bigint,
PRIMARY KEY (store_id,store_name) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop002:3306/test',
'table-name' = 'dwa_mysql_order_analysis',
'driver' = 'com.mysql.cj.jdbc.Driver',
'username' = 'root',
'password' = 'root',
'sink.buffer-flush.max-rows' = '10'
);
3.4 任务流配置
--任务流配置
insert into ods_kafka_order select * from src_mysql_order;
insert into ods_kafka_order_detail select * from src_mysql_order_detail;
insert into dwd_kafka_order select * from ods_kafka_order;
insert into dwd_kafka_order_detail select * from ods_kafka_order_detail;
insert into dwa_mysql_order_analysis
select
orde.store_id as store_id
,store.store_name as store_name
,count(distinct order_detail.goods_id) as sales_goods_distinct_nums
,sum(order_detail.sales_amt) as sales_amt
,count(distinct orde.order_id) as order_nums
from dwd_kafka_order as orde
join dwd_kafka_order_detail as order_detail
on orde.order_id = order_detail.order_id
join dim_store as store
on orde.store_id = store.store_id
group by
orde.store_id
,store.store_name
;
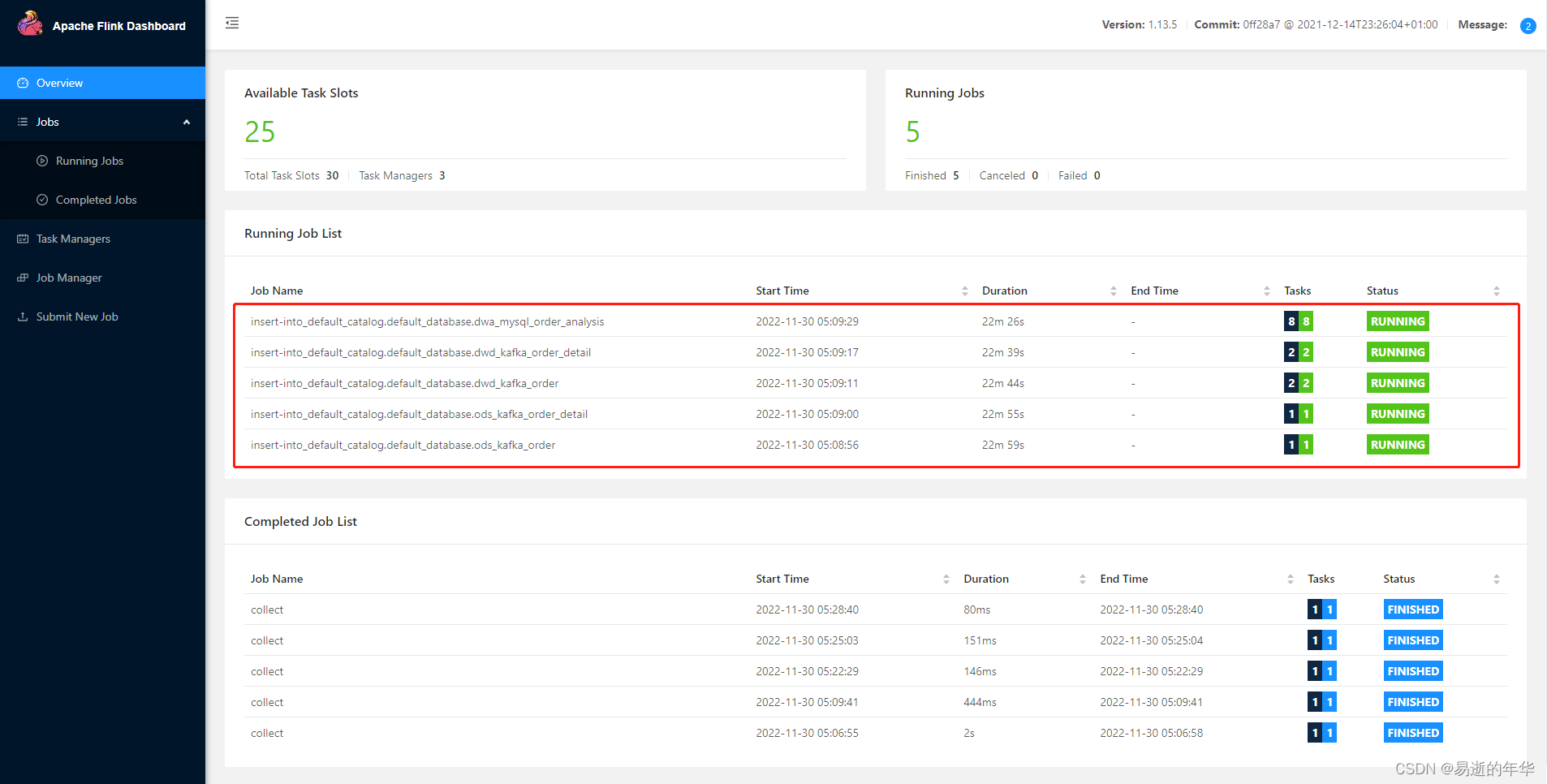
查看flink管理界面,可以看到有5个正在运行的任务,实时流就配置好了
4. 测试
4.1 插入测试数据
insert into src_mysql_order values
(20221210001,10000,50),
(20221210002,10000,20),
(20221210003,10001,10);
insert into src_mysql_order_detail values
(20221210001,10000,100000,30),
(20221210001,10000,100001,20),
(20221210002,10000,100001,20),
(20221210003,10001,100000,10);
insert into dim_store values
(10000, '宇唐总店'),
(10001, '宇唐一店'),
(10002, '宇唐二店'),
(10003, '宇唐三店');
insert into dim_goods values
(100000, '天狮达特浓缩枣浆'),
(100001, '蜜炼柚子茶');
4.2 查看结果表数据

4.3 新增测试数据
insert into src_mysql_order values
(20221210004,10002,50),
(20221210005,10003,30);
insert into src_mysql_order_detail values
(20221210004,10002,100000,30),
(20221210004,10002,100001,20),
(20221210005,10003,100000,10),
(20221210005,10003,100001,20);
4.4 再次查看结果表数据

本文转载自: https://blog.csdn.net/TangYuG/article/details/128268085
版权归原作者 易逝的年华 所有, 如有侵权,请联系我们删除。
版权归原作者 易逝的年华 所有, 如有侵权,请联系我们删除。