
1.准备数据
su - spark
wget http://statweb.stanford.edu/~tibs/ElemStatLearn/datasets/spam.data
hadoop fs -mkdir /user/spark
hadoop fs -put spam.data /user/spark/
hadoop fs -put README.md /user/spark/
2.进入spark命令行
spark-shell
3.运行简单spark程序
3.1加载文件
val inFile = sc.textFile("/user/spark/spam.data")

3.2显示一行
inFile.first()

该命令表明:spark加载文件是按行加载,每行为一个字符串,这样一个RDD[String]字符串数组就可以将整个文件存到内存中。
3.3 map函数的应用
val nums = inFile.map(x=>x.split(' ').map(_.toDouble))

nums.first()

这里的命令行:将每行的字符串转换为相应的一个double数组,这样全部的数据将可以用一个二维的数组 RDD[Array[Double]]来表示了
3.4 collect函数的应用
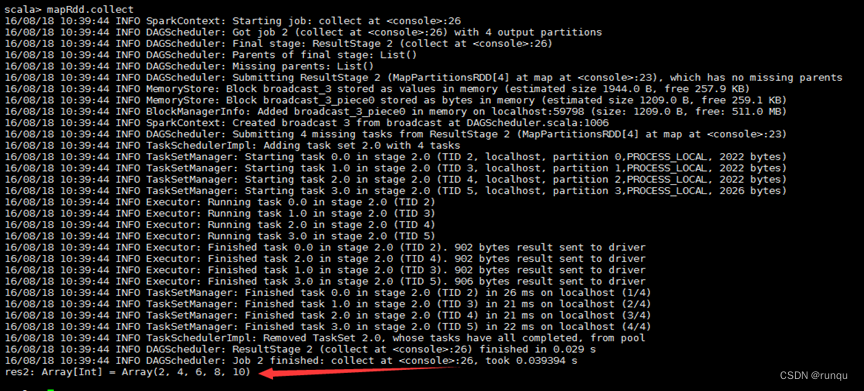
val rdd = sc.parallelize(List(1,2,3,4,5))

val mapRdd = rdd.map(2*_)

mapRdd.collect
3.5 filter函数的应用
val filterRdd = sc.parallelize(List(1,2,3,4,5)).map(*2).filter(>5)

filterRdd.collect

3.6 flatMap函数的应用
val rdd = sc.textFile("/user/spark/README.md")

rdd.count

rdd.cache

rdd.count

val wordCount = rdd.flatMap(.split(' ')).map(x=>(x,1)).reduceByKey(+_)

wordCount.collect

wordCount.saveAsTextFile("/user/spark/wordCountResult")
查看,在shell命令行中
hadoop fs -ls /user/spark/wordCountResult

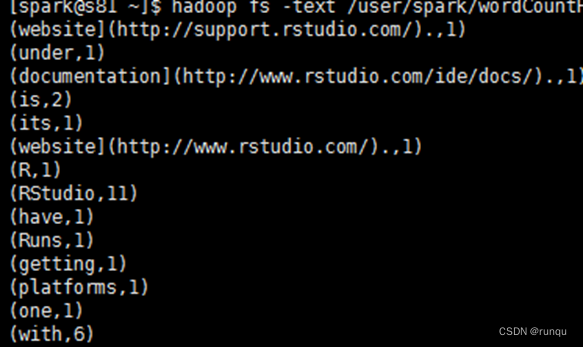
hadoop fs -text /user/spark/wordCountResult/part-*
部分截图
3.7 union函数应用
spark命令行
val rdd = sc.parallelize(List(('a',1),('a',2)))
val rdd2 = sc.parallelize(List(('b',1),('b',2)))
rdd union rdd2

res10.collect

3.8 join函数的应用
val rdd1 = sc.parallelize(List(('a',1),('a',2),('b',3),('b',4)))
val rdd2 = sc.parallelize(List(('a',5),('a',6),('b',7),('b',8)))
rdd1 join rdd2

res0.collect

3.9 lookup函数的应用
val rdd1 = sc.parallelize(List(('a',1),('a',2),('b',3),('b',4)))
rdd1.lookup('a')

3.10 groupByKey函数的应用
val wc = sc.textFile("/user/spark/README.md").flatMap(.split(' ')).map((,1)).groupByKey
wc.collect

3.11 sortByKey函数的应用
val rdd = sc.textFile("/user/spark/README.md")
val wordcount = rdd.flatMap(.split(' ')).map((,1)).reduceByKey(+)
val wcsort = wordcount.map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1))
wcsort.saveAsTextFile("/user/spark/sort_desc")
val wcsort2 = wordcount.map(x => (x._2,x._1)).sortByKey(true).map(x => (x._2,x._1))
wcsort2.saveAsTextFile("/user/spark/sort")
shell命令行查看
hadoop fs -ls /user/spark/sort

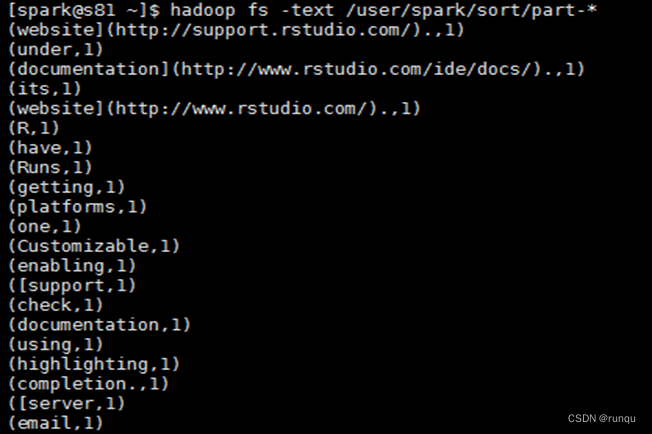
hadoop fs -text /user/spark/sort/part-*
部分截图
hadoop fs -ls /user/spark/sort_desc

hadoop fs -text /user/spark/sort_desc/part-*
部分截图

欢迎添加交流:


版权归原作者 runqu 所有, 如有侵权,请联系我们删除。