
前提条件
准备三台CenOS7机器,主机名称,例如:node2,node3,node4
三台机器安装好jdk8,通常情况下,flink需要结合hadoop处理大数据问题,建议先安装hadoop,可参考 hadoop安装
Flink集群规划
node2node3node4
JobManager
TaskManager
TaskManagerTaskManager
下载安装包
在node2机器操作
[hadoop@node2 ~]$ cd installfile/
[hadoop@node2 installfile]$ wget https://archive.apache.org/dist/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz --no-check-certificate
解压安装包
[hadoop@node2 installfile]$ tar -zxvf flink-1.17.1-bin-scala_2.12.tgz -C ~/soft
进入到解压后的目录,查看解压后的文件
[hadoop@node2 installfile]$ cd ~/soft/
[hadoop@node2 soft]$ ls
配置环境变量
[hadoop@node2 soft]$ sudo nano /etc/profile.d/my_env.sh
添加如下内容
#FLINK_HOME
export FLINK_HOME=/home/hadoop/soft/flink-1.17.1
export PATH=$PATH:$FLINK_HOME/bin
让环境变量生效
[hadoop@node2 soft]$ source /etc/profile
验证版本号
[hadoop@node2 soft]$ flink -v
Version: 1.17.1, Commit ID: 2750d5c
看到如上
Version: 1.17.1
版本号字样,说明环境变量配置成功。
配置flink
进入flink配置目录,查看配置文件
[hadoop@node2 ~]$ cd $FLINK_HOME/conf
[hadoop@node2 conf]$ ls
flink-conf.yaml log4j-console.properties log4j-session.properties logback-session.xml masters zoo.cfg
log4j-cli.properties log4j.properties logback-console.xml logback.xml workers
配置flink-conf.yaml
[hadoop@node2 conf]$ vim flink-conf.yaml
找到相关配置项并修改,如下
jobmanager.rpc.address: node2
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node2
rest.address: node2
rest.bind-address: 0.0.0.0
配置workers
[hadoop@node2 conf]$ vim workers
把原有内容删除,添加内容如下:
node2
node3
node4
配置masters
[hadoop@node2 conf]$ vim masters
修改后内容如下:
node2:8081
分发flink安装目录
确保node3、node4机器已开启的情况下,执行如下分发命令。
[hadoop@node2 conf]$ xsync ~/soft/flink-1.17.1
修改node3和node4的配置
node3
进入node3机器flink的配置目录
[hadoop@node3 ~]$ cd ~/soft/flink-1.17.1/conf/
配置
flinke-conf.yaml
文件
[hadoop@node3 conf]$ vim flink-conf.yaml
将
taskmanager.host
的值修改为
node3
taskmanager.host: node3
node4
进入node4机器flink的配置目录
[hadoop@node4 ~]$ cd ~/soft/flink-1.17.1/conf/
配置
flinke-conf.yaml
文件
[hadoop@node4 conf]$ vim flink-conf.yaml
将
taskmanager.host
的值修改为
node4
taskmanager.host: node4
配置node3、node4的环境变量
分别到node3、node4机器配置环境变量
sudo nano /etc/profile.d/my_env.sh
添加如下配置
#FLINK_HOME
export FLINK_HOME=/home/hadoop/soft/flink-1.17.1
export PATH=$PATH:$FLINK_HOME/bin
让环境变量生效
source /etc/profile
验证版本号
flink -v
看到
Version: 1.17.1
版本号字样,说明环境变量配置成功。
启动flink集群
在node2机器,执行如下命令启动集群
[hadoop@node2 conf]$ start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host node2.
Starting taskexecutor daemon on host node2.
Starting taskexecutor daemon on host node3.
Starting taskexecutor daemon on host node4.
查看进程
分别在node2、node3、node4机器上执行jps查看进程
[hadoop@node2 conf]$ jps
2311 StandaloneSessionClusterEntrypoint
2793 Jps
2667 TaskManagerRunner
[hadoop@node3 conf]$ jps
1972 TaskManagerRunner
2041 Jps
[hadoop@node4 conf]$ jps
2038 Jps
1965 TaskManagerRunner
node2有
StandaloneSessionClusterEntrypoint
、
TaskManagerRunner
进程
node3有
TaskManagerRunner
进程
node4有
TaskManagerRunner
进程
看到如上进程,说明flink集群配置成功。
Web UI
浏览器访问
node2的ip:8081

或者使用主机名称代替ip访问
node2:8081

注意:如果用windows的浏览器访问,需要先在windows的hosts文件添加ip和主机名node2的映射。
关闭flink集群
[hadoop@node2 ~]$ stop-cluster.sh
Stopping taskexecutor daemon (pid: 2667) on host node2.
Stopping taskexecutor daemon (pid: 1972) on host node3.
Stopping taskexecutor daemon (pid: 1965) on host node4.
Stopping standalonesession daemon (pid: 2311) on host node2.
查看进程
[hadoop@node2 ~]$ jps
4215 Jps
[hadoop@node3 ~]$ jps
2387 Jps
[hadoop@node4 ~]$ jps
2383 Jps
单独启动/关闭flink进程
单独启动flink进程
$ jobmanager.sh start
$ taskmanager.sh start
node2
[hadoop@node2 ~]$ jobmanager.sh start
Starting standalonesession daemon on host node2.
[hadoop@node2 ~]$ jps
4507 StandaloneSessionClusterEntrypoint
4572 Jps
[hadoop@node2 ~]$ taskmanager.sh start
Starting taskexecutor daemon on host node2.
[hadoop@node2 ~]$ jps
4867 TaskManagerRunner
4507 StandaloneSessionClusterEntrypoint
4940 Jps
node3
[hadoop@node3 ~]$ taskmanager.sh start
Starting taskexecutor daemon on host node3.
[hadoop@node3 ~]$ jps
2695 TaskManagerRunner
2764 Jps
node4
[hadoop@node4 ~]$ taskmanager.sh start
Starting taskexecutor daemon on host node4.
[hadoop@node4 ~]$ jps
2691 TaskManagerRunner
2755 Jps
单独关闭flink进程
$ jobmanager.sh stop
$ taskmanager.sh stop
node4
[hadoop@node4 ~]$ taskmanager.sh stop
Stopping taskexecutor daemon (pid: 2691) on host node4.
[hadoop@node4 ~]$ jps
3068 Jps
node3
[hadoop@node3 ~]$ taskmanager.sh stop
Stopping taskexecutor daemon (pid: 2695) on host node3.
[hadoop@node3 ~]$ jps
3073 Jps
node2
[hadoop@node2 ~]$ taskmanager.sh stop
Stopping taskexecutor daemon (pid: 4867) on host node2.
[hadoop@node2 ~]$ jobmanager.sh stop
Stopping standalonesession daemon (pid: 4507) on host node2.
[hadoop@node2 ~]$ jps
5545 Jps
提交应用测试
启动flink集群
[hadoop@node2 ~]$ start-cluster.sh
运行flink提供的wordcount案例程序
[hadoop@node2 ~]$ cd $FLINK_HOME/
[hadoop@node2 flink-1.17.1]$ flink run examples/streaming/WordCount.jar
Executing example with default input data.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
Job has been submitted with JobID 845db6f62321830f287e71b525e87dbe
Program execution finished
Job with JobID 845db6f62321830f287e71b525e87dbe has finished.
Job Runtime: 1290 ms
查看结果
查看输出的wordcount结果的末尾10行数据
[hadoop@node2 flink-1.17.1]$ tail log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
Web UI查看作业
查看作业


查看作业结果
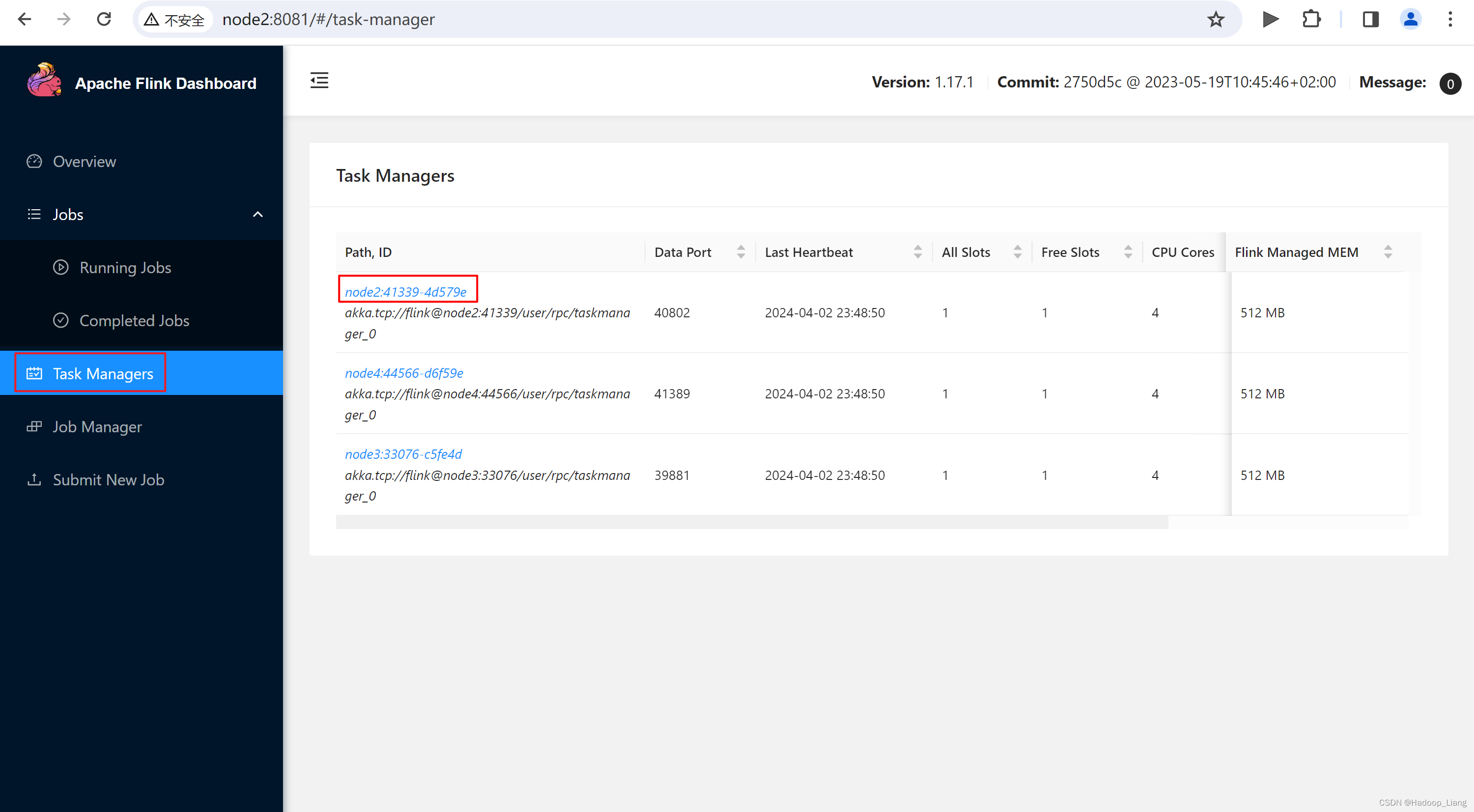

在Task Managers 的node2上可以查看到作业的结果
分别查看Task Managers 的node3、node4的输出结果

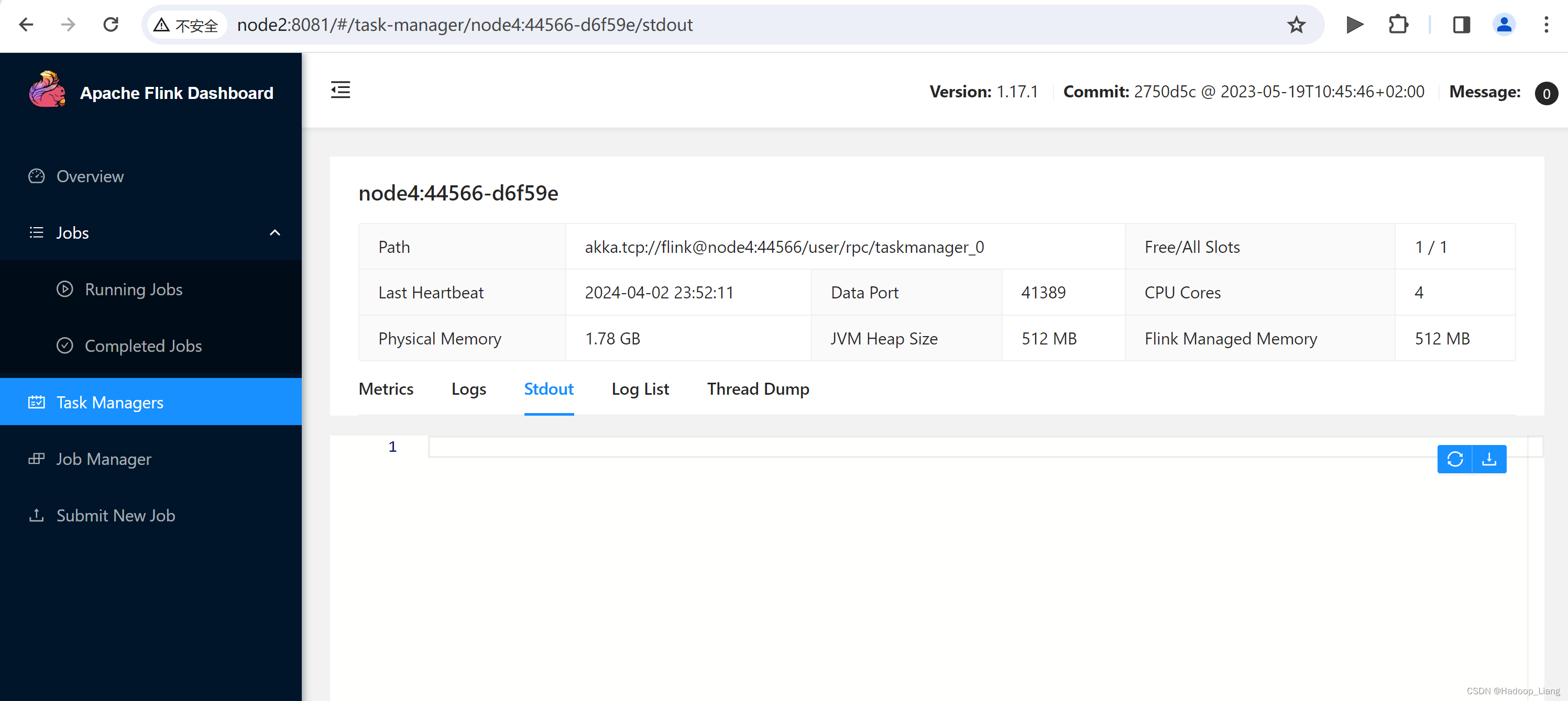
可以看到,三台Task Manager机器中,只有node2机器有结果,说明,本次wordcount计算只用到了node2机器进行计算。用于计算的机器并不固定,只要集群里有机器能看到计算结果都是正常的。
总结:至此,flink进程正常,可以提交应用到fink集群运行,同时能查看到相应计算结果,说明集群功能正常。
完成!enjoy it!
版权归原作者 Hadoop_Liang 所有, 如有侵权,请联系我们删除。