
linux的集群搭建
1.注意事项
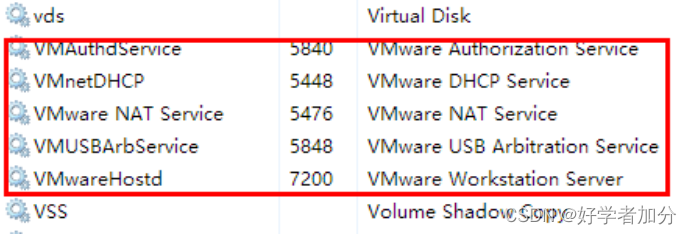
windows系统确认所有的关于VmWare的服务都已经启动
右键“我的电脑”->“管理”
确认好VmWare生成的网关地址
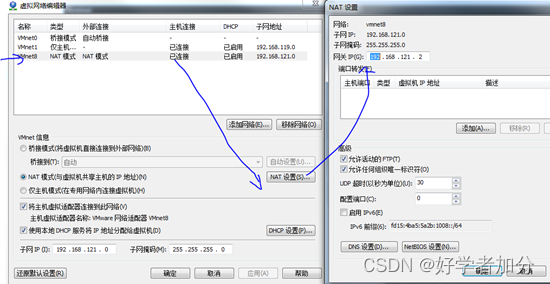
这里设置网关为192.168.121.2,子网ip:192.168.121.0,子网掩码:255.255.255.0
2.vmware创建centos虚拟机hadoop04
2.1 设置主机名为hadoop04
使用 vim编辑器打开 /etc/hostname 文件
#vim /etc/hostname
删除文件中原有内容,添加内容主机名:hadoop04,保存退出(wq!)
2.2设置静态网络
更改虚拟机静态ip,例如hadoop04
打开网卡配置文件修改内容
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" #配置静态 ip选项,默认为 dhcp模式改为static
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="58d5bd5f-0c03-4e8d-8614-ce18b09d18b4"
DEVICE="ens33"
ONBOOT="yes" #启动网卡 将no改为yes
IPADDR=192.168.121.4 #静态 ip
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.121.2 #网关,需要在虚拟机网络编辑中 NAT模式查看到
DNS1=8.8.8.8 #DNS
2.3设置主机名及IP映射
使用 vim 编辑器打开 /etc/hosts 文件
vim /etc/hosts
在文件尾部添加内容,格式:IP地址 主机名(中间用空格分隔),保存退出(wq!)
192.168.121.4 hadoop04
192.168.121.5 hadoop05
192.168.121.6 hadoop06
设置完成后,重启网路服务
reboot
2.4使用 ping 命令 ping 主机名
ping hadoop04
如果可以ping 通,表示设置成功
2.5虚拟机关闭防火墙
查看防火墙状态
#systemctl status firewalld.service
关闭防火墙#systemctl stop firewalld.service
停止并禁用开机启动# systemctl disable firewalld.service
2.6 关闭selinux
修改selinux的配置文件
vim /etc/selinux/config,保存退出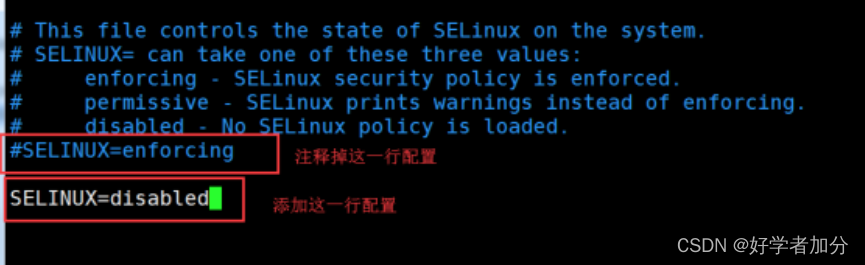
完成以上步骤后将hadooop04克隆出hadoop05和hadoop06,然后记得修改hadoop05、hadoop06的主机名和静态ip为192.168.121.5和192.168.121.6再重启网络
2.7ssh免密钥登陆
私钥:密钥留在本机
公钥:密钥发给本机
在hadoop04
生成密钥:ssh-keygen //一直回车键
发送私钥(本机):ssh-copy-id haadoop04
发送公钥(其他计算机):ssh-copy-id (其他计算机主机名)
测试免密钥登陆:
ssh localhost
ssh (其他计算机主机名)
辅助软件安装
hadoop04机器JDK安装
1.1 查看自带的openjdk并卸载
rpm -qa | grep java
1.2 创建安装目录
mkdir -p /opt/software #软件包存放目录
mkdir -p /opt/module #安装目录
1.3上传并 解压
#上传jdk/opt/software到路径下去,并解压
tar -zxvf jdk-8u161-linux-x64.tar.gz -C ../module/
1.4 配置环境变量
vim /etc/profile
//添加如下内容
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
//修改完成之后记得 source /etc/profile生效//java version 检查
然后使用该命令jdk和/etc/profile拷贝到每台机器上与hadoop04相同的路径上
scp - r jdk1.8.0_161 root@hadoop04:/opt/module
集群规划
hadoop04 hadoop05 hadoop06 HADFS NameNode SecondaryNameNode DataNode DataNode DataNode YARN ResourceManager NodeManager NodeManager NodeManager
因为namenode、resourcemanager、secondarynamenode占用资源大,所以我将它们安排在不同的节点 上
hadoop安装
第一步:下载安装包并解压
先将下载的hadoop-3.1.3.tar.gz安装包上传到主节点hadoop04的/opt/software目录下,然后将文件解压到/opt/module/目录,具体指令如下。
#cd /opt/software/
#tar -zxvf hadoop-3.1.3.tar.gz -C …/module/
第二步:配置hadoop系统环境变量
#vim /etc/profile
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存退出,令配置文件生效
#source /etc/profile
#hadoop version ##hadoop环境验证
hadoop配置
这里需要配置五个文件
1.hadoop-env.sh
配置自己的jdk路径然后在末尾添加以下
export JAVA_HOME=$JAVA_HOME
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.core-site.xml
<configuration><!--用于设置Hadoop的文件系统,由URI指定--><property><name>fs.defaultFS</name><!--用于指定namenode地址在hadoop01机器上--><value>hdfs://hadoop04:9000</value></property><!--配置hadoop临时目录,默认/tmp/hadoop-${user.name}--><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property></configuration>
3.hdfs-site.xml
<configuration><!-- 指定HDFS副本的数量--><property><name>dfs.replication</name><value>3</value></property><!-- secondary namenode所在主机的IP和端口 --><property><name>dfs.namenode.secondary.http-address</name><value>hadoop06:50090</value></property><!-- 指定namenode的访问地址和端口 --><property><name>dfs.namenode.http-address</name><value>hadoop04:50070</value></property><!-- 设置HDFS的文件权限,默认是false--><property><name>dfs.permissions</name><value>false</value></property><!-- 设置一个文件切片的大小:默认128M--><property><name>dfs.blocksize</name><value>134217728</value></property></configuration>
4.yarn-site.xml
<configuration><!-- 指定YARN集群的管理者(ResourceManager)的地址 --><property><name>yarn.resourcemanager.address</name><value>hadoop05</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><![CDATA[<property><!-- 定义NodeManager上要提供给正在运行的容器的全部可用资源大小,默认是8192MB --><name>yarn.nodemanager.resource.memory-mb</name><value>2048</value></property><property><!-- 资源管理器中分配给每个容器请求的最小内存限制,默认是1024MB --><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><!-- NodeManager可以分配的CPU核数--><name>yarn.nodemanager.resource.cpu-vcores</name><value>1</value></property><property><!-- 开启日志聚合功能 --><name>yarn.log-aggregation-enable</name><value>true</value></property><property><!-- 设置聚合日志在hdfs上的保存时间 --><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property>]]><property><!-- 开启日志聚合功能 --><name>yarn.log-aggregation-enable</name><value>true</value></property></configuration>
5.mapred-site.xml
<configuration><!-- 指定MapReduce运行时框架,这里指定在YARN上,默认是local --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 设置历史任务的主机和端口 --><property><name>mapreduce.jobhistory.address</name><value>hadoop04:10020</value></property><!-- 设置网页访问历史任务的主机和端口 --><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop04:19888</value></property></configuration>
5 workers
hadoop04
hadoop05
hadoop06
配置完以上文件后将使用以下命令将hadoop3.1.3拷贝到其他服务器上(hadoop05、hadoop06)
注意要拷贝到相同的路径上,然后再拷贝环境变量的配置文件
#scp /etc/profile hadoop05:/etc/profile
#scp /etc/profile hadoop06:/etc/profile
#scp -r /opt/module/ hadoop05:/opt
#scp -r /opt/module/ hadoop06:/opt
然后#source /etc/profile 让环境生效
hadoop格式化
格式化一般进行一次,不然格式化多次数据丢失,如果再次格式化时先关闭集群然后每台的路径/opt/module/hadoop-3.1.3下的data和logs删掉再格式化,,,在hdoop04上面进行格式化。
hdfs namenode -format
启动hadoop
start-dfs.sh //在hadoop04启动
start-yarn.sh //在hadoop05启动
不能用start-all.sh因为resourcemanager和namenode不在同一台机器上
使用该命令可能会爆以下错误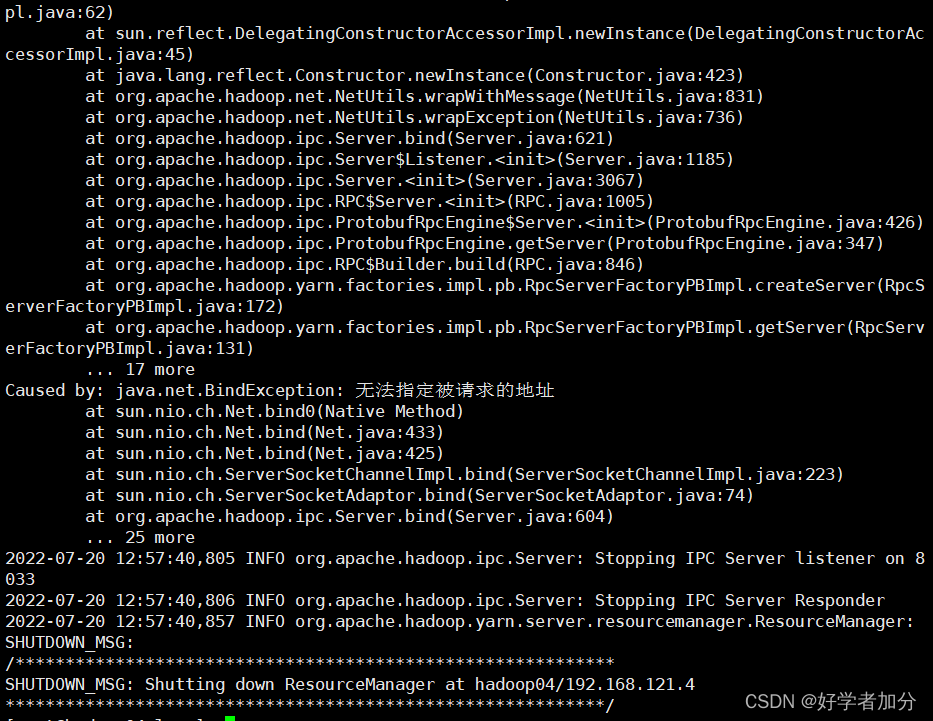
web ui查看hadoop集群
http://hadoop04:50070
http://hadoop05:8088
版权归原作者 好学者加分 所有, 如有侵权,请联系我们删除。