
一、概况
Hadoop是一个由Apache基金会所开发分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。
二、虚拟机创建
使用hadoop需要先在linux上创建主机master以及克隆出两台以上克隆机,主机master可自命名。
三、远程连接虚拟机
我用的是mobaxterm远程连接,SSH用虚拟机网关进行连接,用户名为root。
四、开启和关闭hadoop集群
1.主机映射
Workers:在/usr/local/hadoop-3.1.3/etc/hadoop/路径下,修改workers文件,改成以下部分(这里不添加master节点,因此后面启动时候master没有datanote,其他3个子节点会有datanote)
slave1
slave2
slave3
2.SSH免密登录
①要使master虚拟机能够向slave1虚拟机传输文件,确实需要确保slave1上的SSH服务允许root用户登录,则需要配置好slave1的/etc/ssh/sshd_config文件,找到以下行,更改为PermitRootLogin yes
②输入:scp -r root@master:/usr/local/hadoop-3.1.3/test/aa.txt root@slave1:/usr/local/hadoop-3.1.3/test/
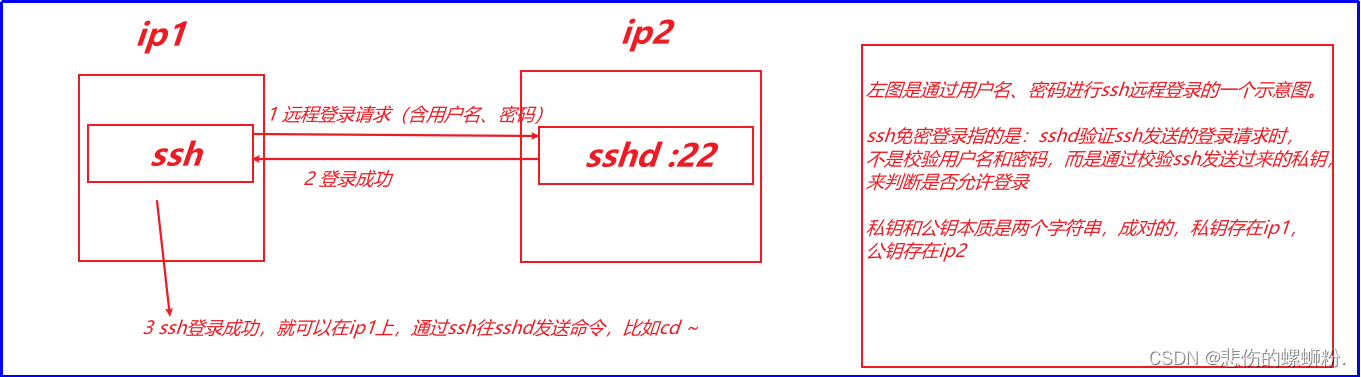
在进行上述过程中,每次发起scp命令,都需要输入2次密码,整个过程会比较繁琐。下面我们来介绍SSH免密登录:想要在机器1上,远程控制机器2,常用的方案就是在机器1安装ssh客户端,机器2安装ssh服务端,ssh客户端和ssh服务端之间的通信协议是ssh协议。在linux系统中ssh命令,就是一个ssh客户端程序;sshd服务,就是一个ssh服务端程序。在windows中,给大家提供的mobaxterm是一个图形化界面的ssh客户端。
ssh免密的登录说明见下图:
③免密过程
(1)在master主机里,先尝试ssh登录,命令:ssh slave1,现在需要输入密码登录。
(2)先从slave1退出,回到master主机里,使用exit或者logout命令
(3)在master主机里,使用ssh-keygen产生公钥与私钥对,命令:ssh-keygen -t rsa(执行命令后,对弹出提示连续按3次回车键)。
(4)进入home目录,用命令:ll -al查看隐藏文件,能看到隐藏文件.ssh。
(5)进入.ssh文件夹,再使用ll命令查看文件,其中,id_rsa是私钥,is_rsa.pub是公钥。
(6)在master主机,使用命令ssh-copy-id slave1将公钥复制到slave1中,期间需要输入slave1密码,然后使用ssh命令登录slave1。
(7)切换到slave1主机,进入/root/.ssh路径,用cat命令查看授权文件,当最后显示的是root/master时候,表示master主机已授权。
(8)同理,重复(6)(7)对slave2,slave3进行免密设置。
(9)最后,在master也给自己也发放公钥,命令:ssh-copy-id master(为后续启动集群做准备)。
3.启动集群
①在master里,修改/etc/ssh/sshd_config文件,把注释了在文件去掉#
PasswordAuthentication yes
PubkeyAuthentication yes
PermitRootLogin yes
②使用命令hdfs namenode -format开启集群,出现 Storage directory /data/hadoop/hdfs/name has been successfully formatted.表示格式化NameNode成功。
③使用命令sbin/start-dfs.sh,开启HDFS,sbin/start-dfs.sh出现如下权限问题时候,在master用ssh-copy-id master命令,然后重新执行命令sbin/start-dfs.sh。
④使用命令sbin/start-yarn.sh,开启yarn。
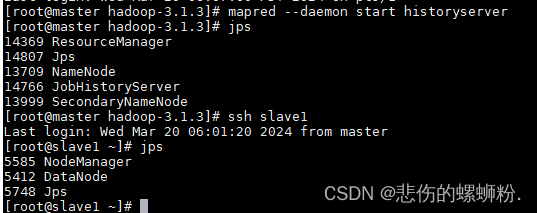
⑤使用命令mapred --daemon start historyserver开启日志。
⑥最后,在master、slave1、slave2、slave3使用jps查看,如下:
4.关闭集群
①使用命令sbin/stop-yarn.sh
②使用命令sbin/stop-dfs.sh
③使用命令mapred --daemon stop historyserver(注意,重新开机后要重新启动Hadoop集群)
五、监控Hadoop集群
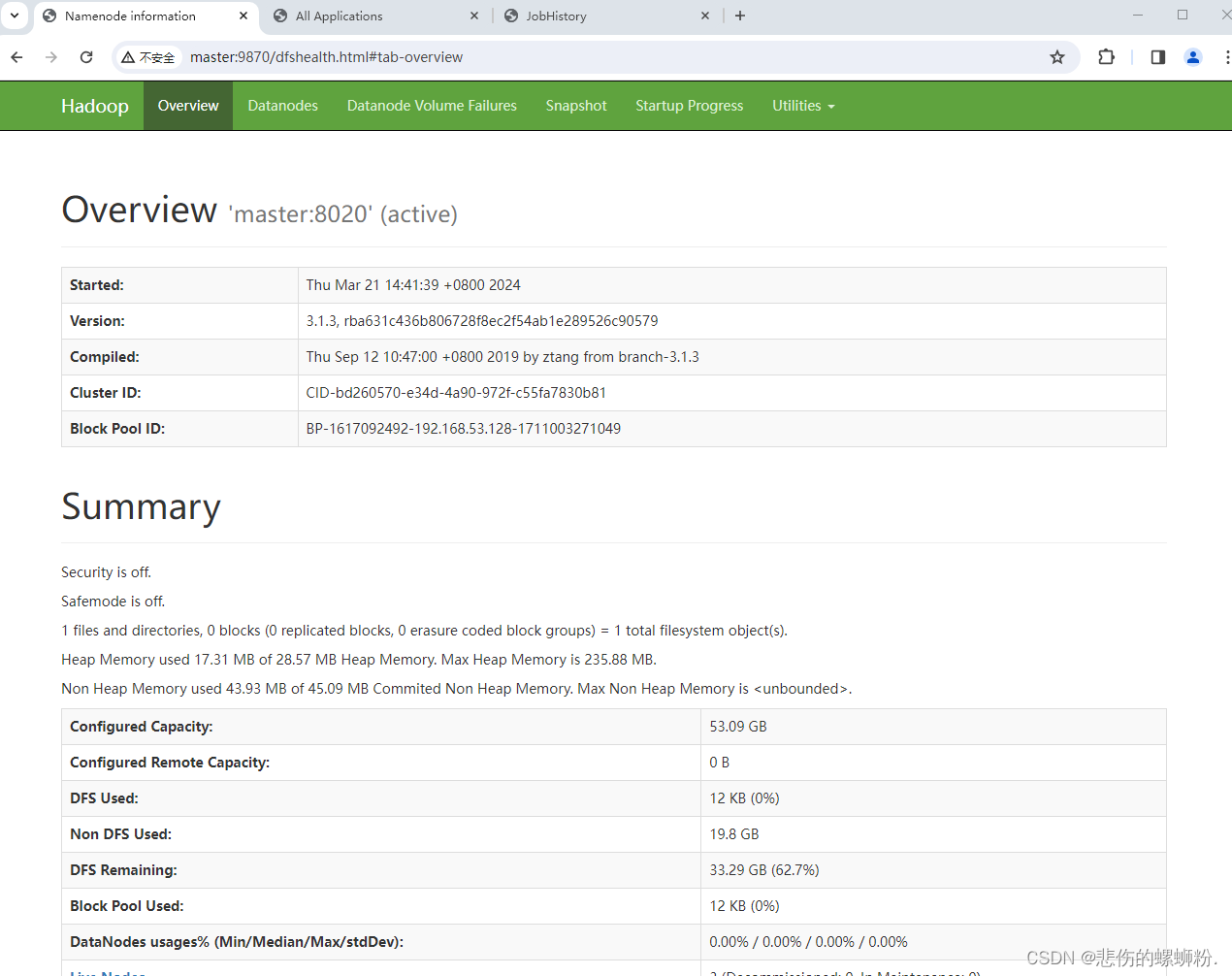
1.HDFS监控
在windows用**http://192.168.122.128:9870/**(自己虚拟机的网址)
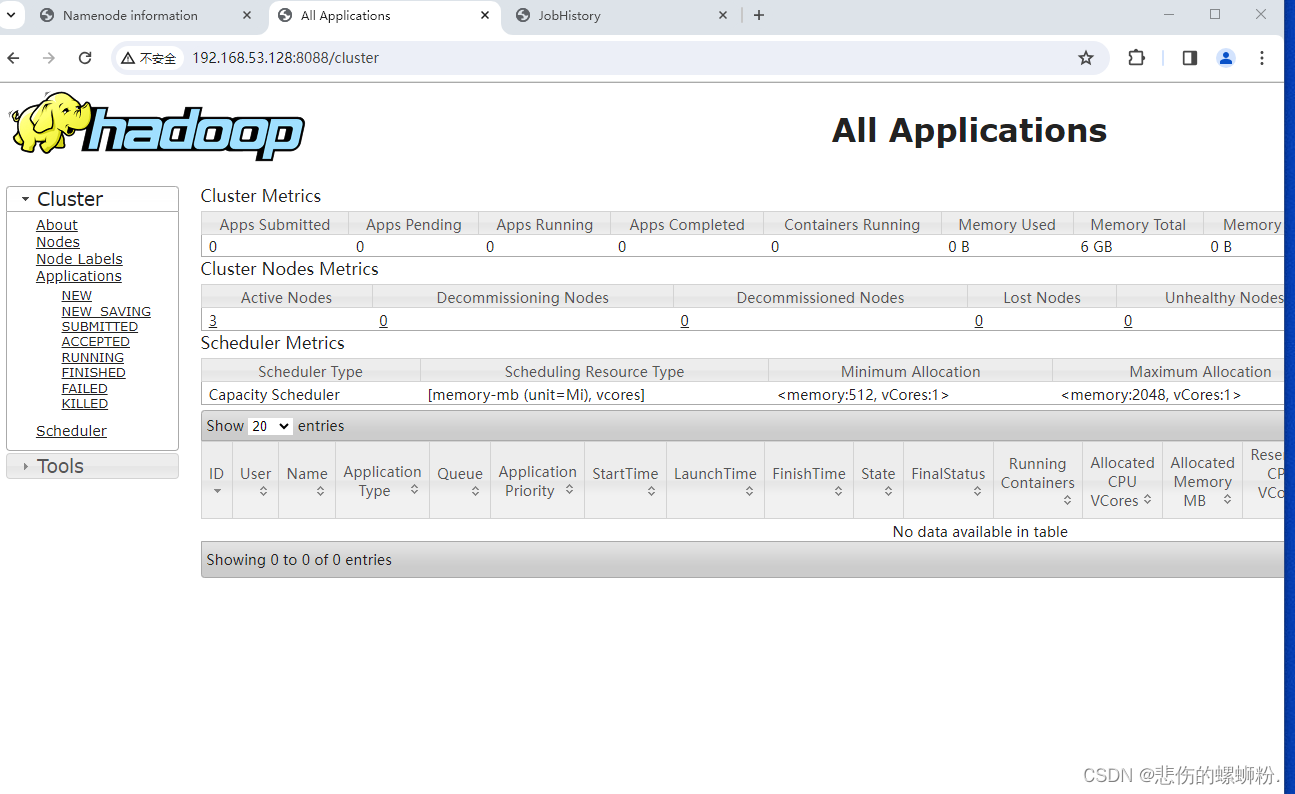
2.Yarn监控
在windows用**http://192.168.122.128:8088/**(自己虚拟机的网址)
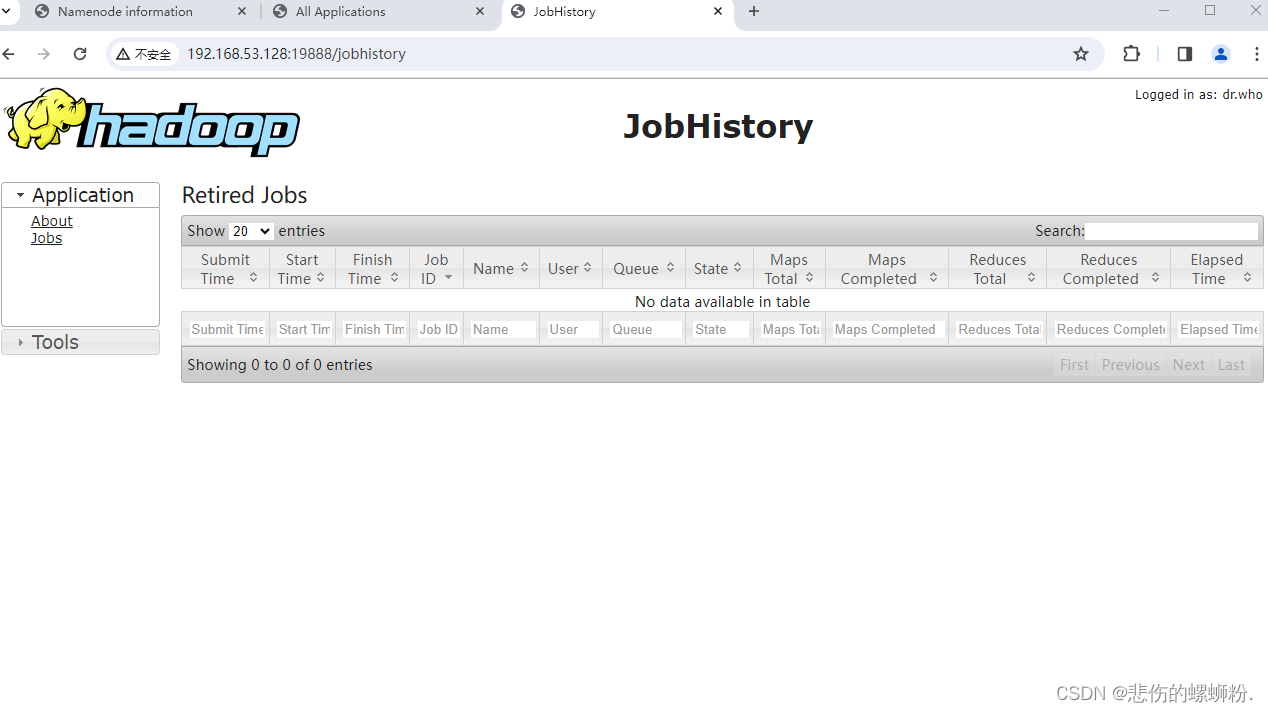
3.日志监控
在windows用**http://192.168.122.128:19888/**(自己虚拟机的网址)
六、在Mapreduce中实现
1.Mapreduce概述
Mapreduce是一种编程模型,用于处理大规模数据集的并行运算。MapReduce的核心思想来自于函数式编程语言,如Lisp,其中的map和reduce函数。在MapReduce模型中,用户通过定义一个map函数来处理键值对(key/value)数据集,生成一组新的键值对,然后Reduce函数负责将所有具有相同键的中间结果合并,最终得到处理后的数据。
MapReduce系统通常隐藏了分布式计算的复杂细节,如数据分布存储、数据通信和容错处理,从而简化了大规模数据集的并行计算过程。它允许用户在不知道底层分布式系统细节的情况下,编写并行处理程序。MapReduce框架能够自动划分数据和任务,在集群的节点上分配和执行任务,并收集结果。此外,MapReduce还提供了并行计算平台和软件框架,使得开发者能够更容易地开发和运行分布式应用程序。
2.windows需安装JDK8版本。
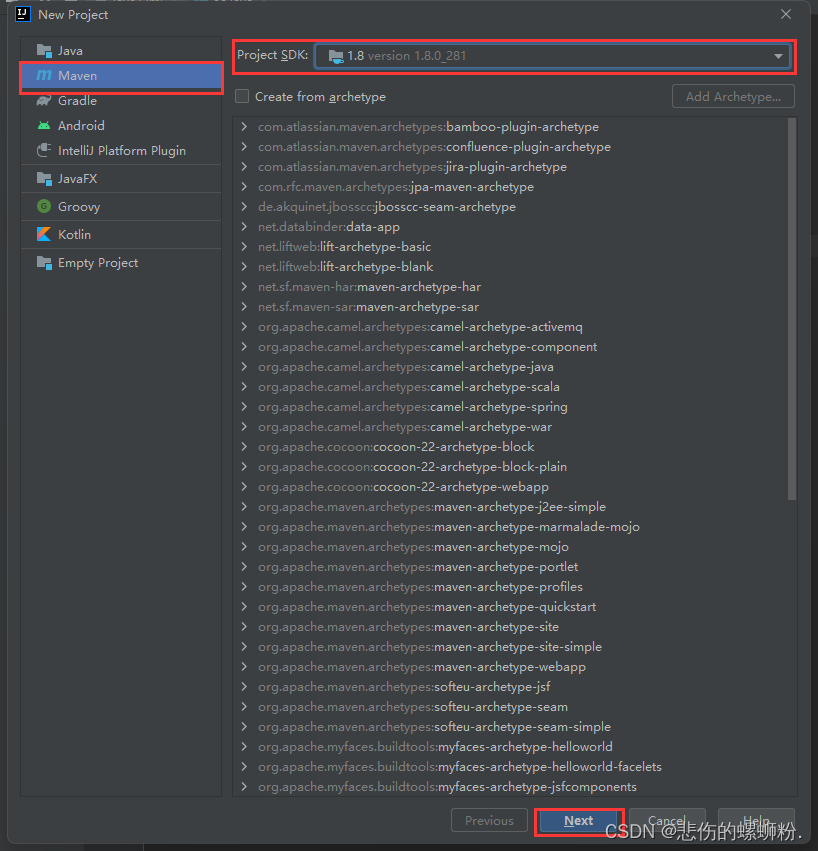
3.使用In2tellij IDEA 创建Mapreduce工程
4.在本地windows系统运行
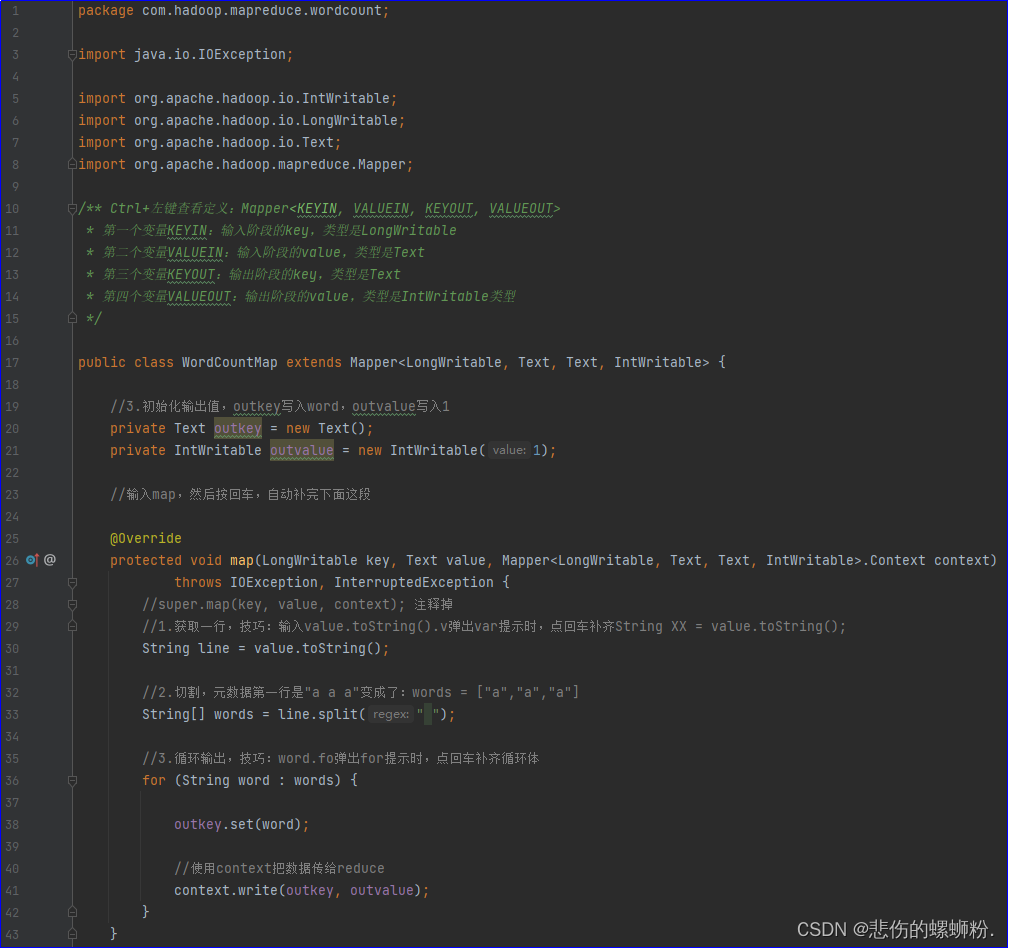
①map阶段编码
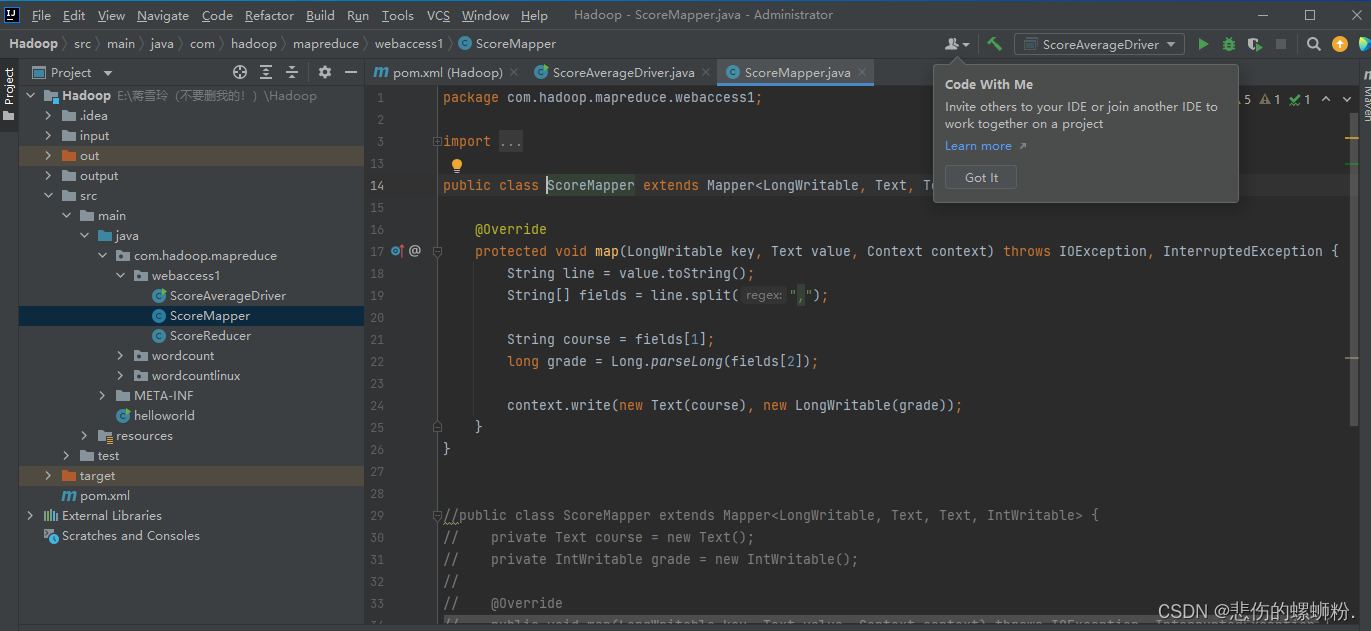
用户自定义的Mapper要继承自己的父类,Mapper的输入数据是key-value(KV)对的形式(KV的类型可自定义),Mapper中的业务逻辑写在map()方法中,Mapper的输出数据是KV对的形式(KV的类型可自定义),map()方法(MapTask进程)对每一个<K,V>调用一次。
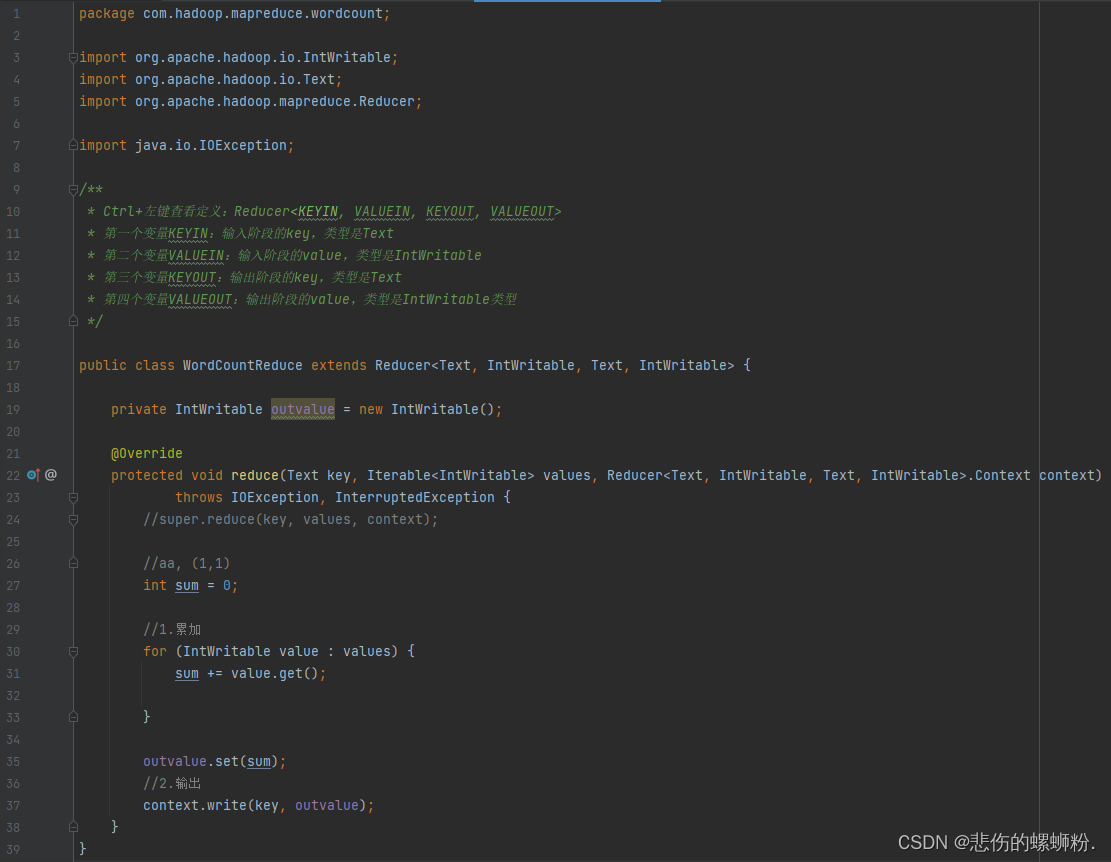
②reduce阶段编码
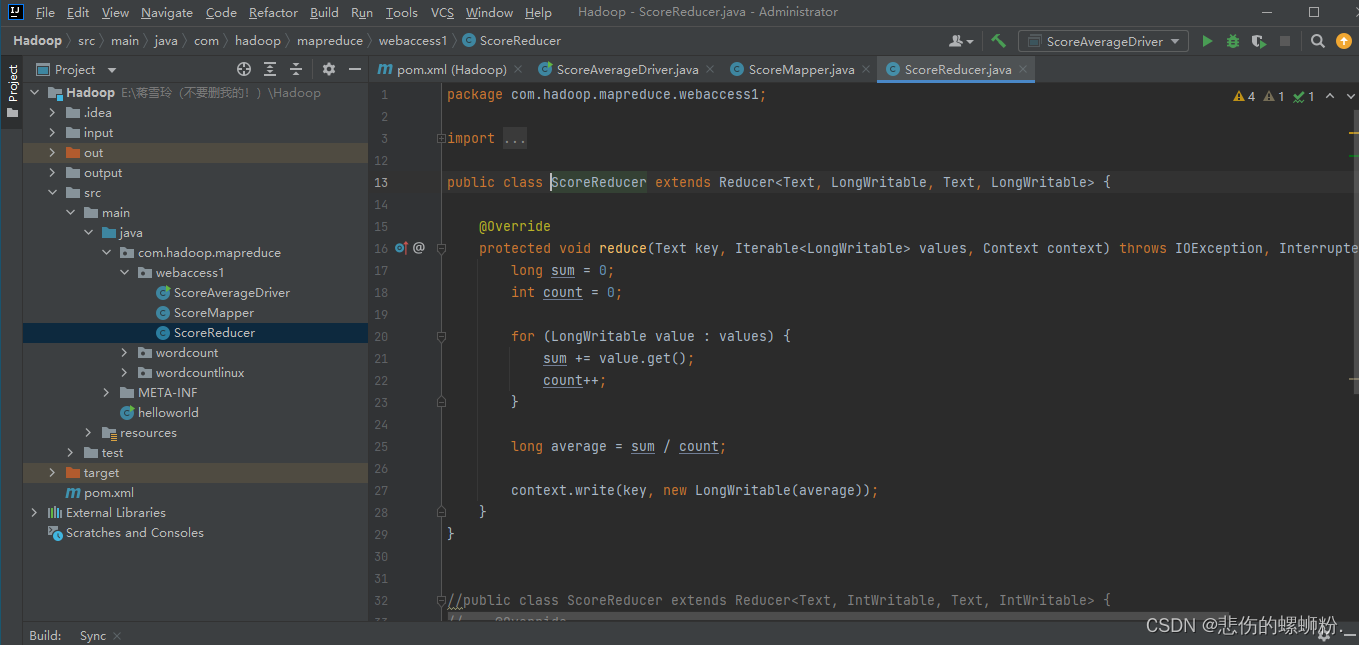
- 用户自定义的Reducer要继承自己的父类
- Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
- Reducer的业务逻辑写在reduce()方法中
- ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法
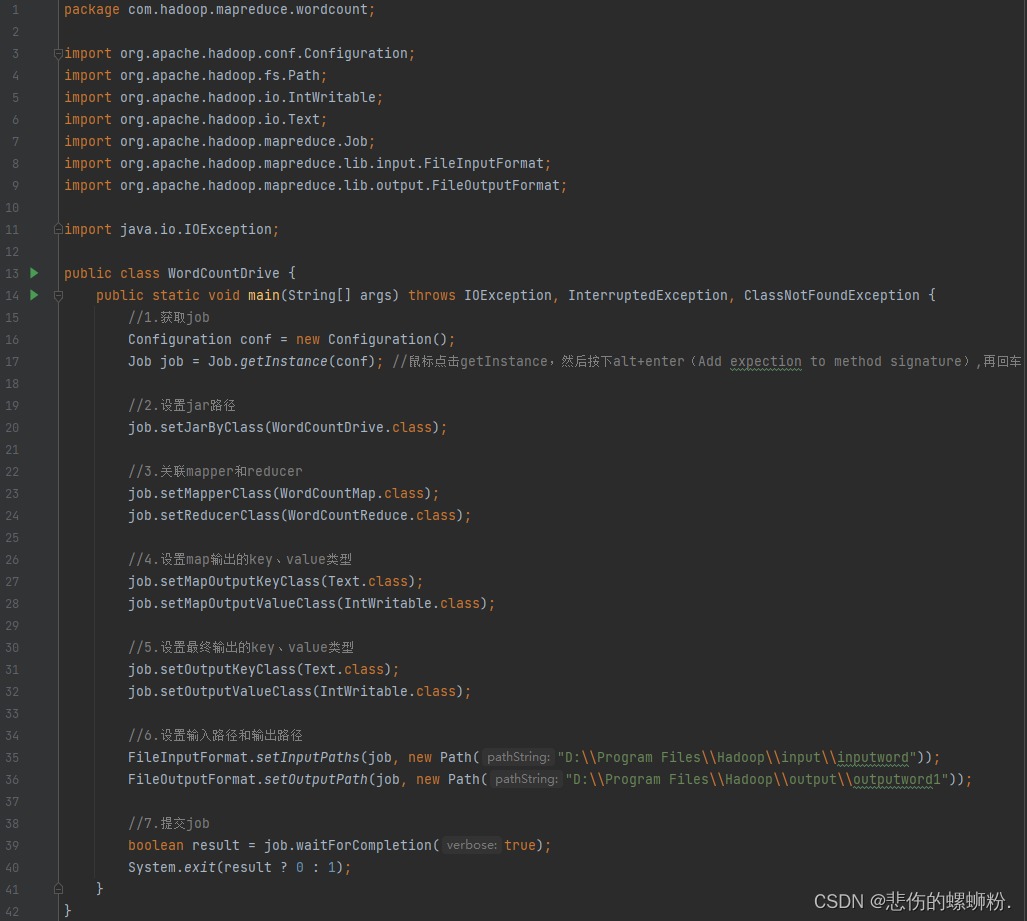
③diver阶段编码
- 配置作业:设置作业的各种参数,如输入和输出的路径、使用的Mapper和Reducer类等。
- 提交作业:将配置好的作业提交给ResourceManager。
④执行WordCountDriver
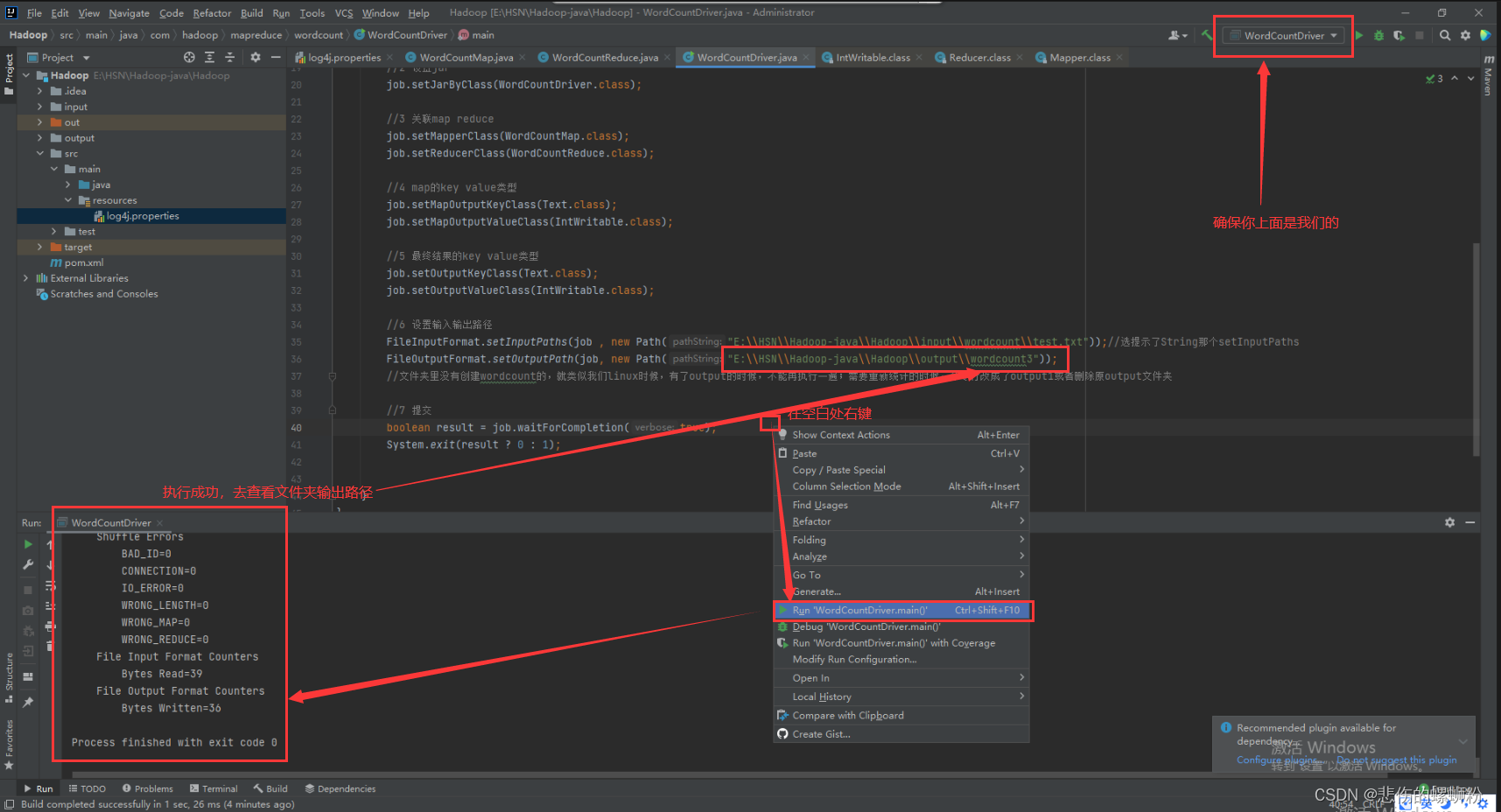
⑤查看结果
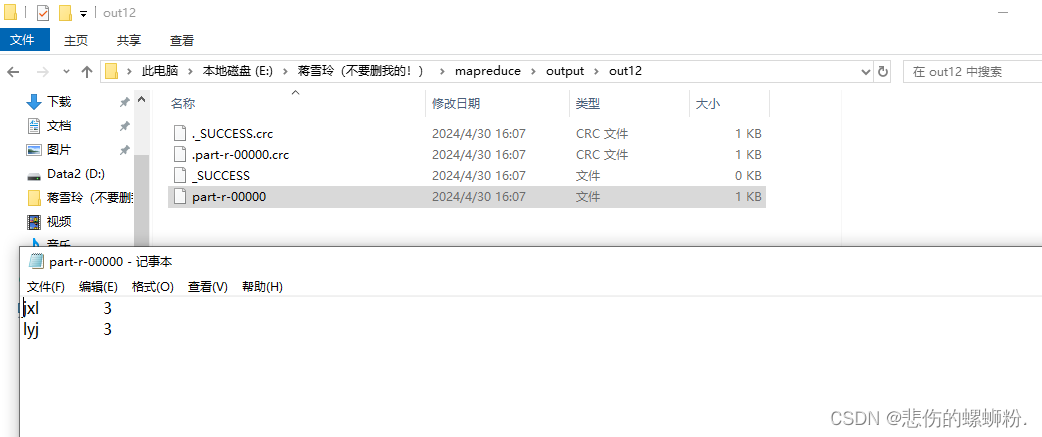
七、Mapreduce实战
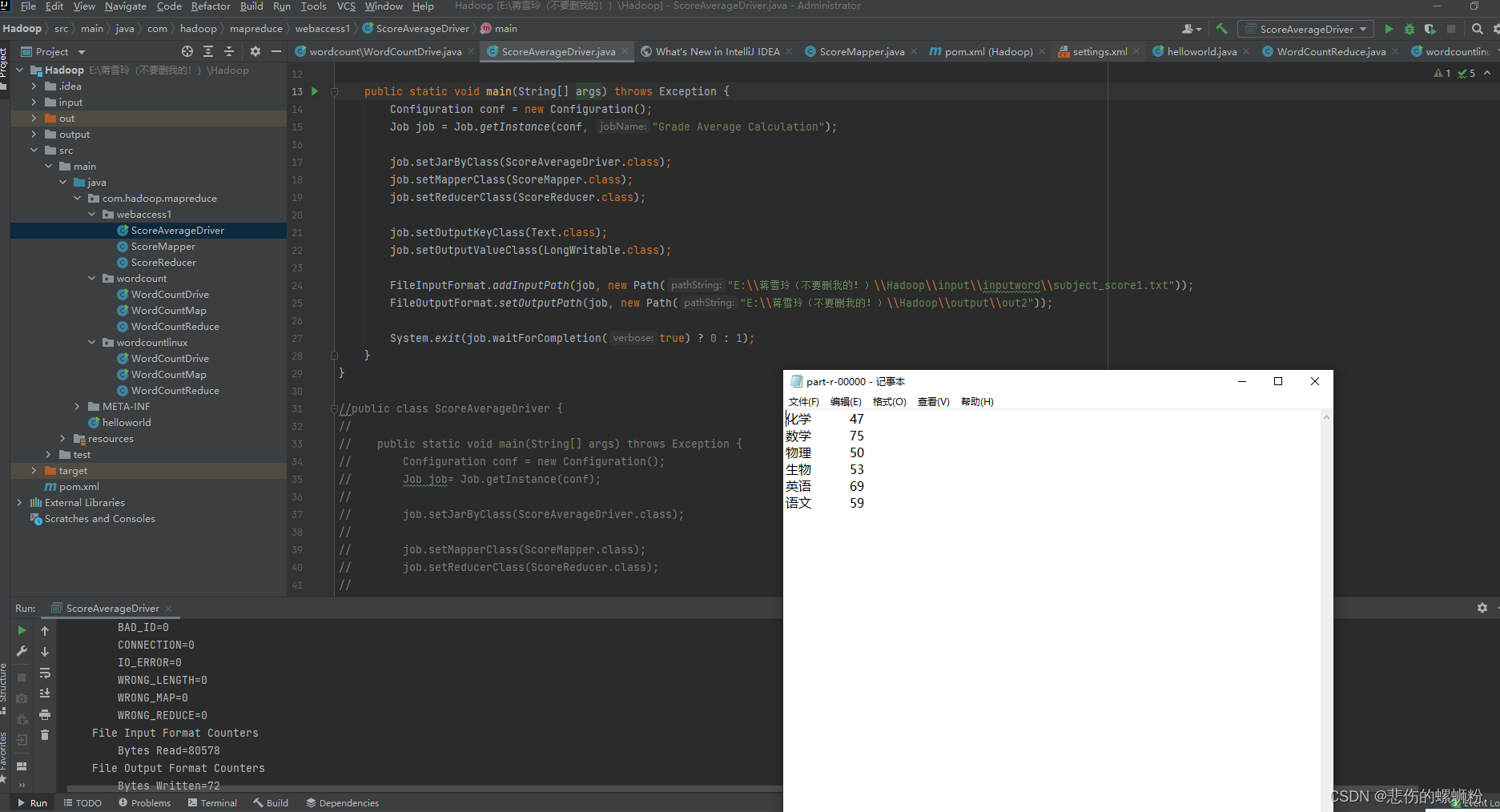
用Mapreduce计算班级各学科平均分。
1.map阶段
2.reduce阶段
3.driver阶段
4.结果
八、结论
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和Mapreduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
感谢各位读者的阅读,文章作者技术和水平有限,如果文中出现错误,希望大家能指正!
版权归原作者 悲伤的螺蛳粉. 所有, 如有侵权,请联系我们删除。