
1、Hive简介
什么是Hive?
Hive是建立在Hadoop文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的工具。Hive定义简单的类SQL查询语言(即HQL),可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,允许熟悉MapReduce的开发者开发mapper和reducer来处理复杂的分析工作,与MapReduce相比较,Hive更具有优势。
Hive采用了SQL的查询语言Hive SQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处,MySQL与Hive对比如下所示。
Hive是底层封装了Hadoop的数据仓库处理工具,运行在Hadoop基础上,其系统架构组成主要包含4部分,分别是用户接口、跨语言服务、底层驱动引擎及元数据存储系统。
Hive建立在Hadoop系统之上,因此Hive底层工作依赖于Hadoop服务
Hive中所有的数据都存储在HDFS中,它包含数据库(Database)、表(Table)、分区表(Partition)和桶表(Bucket)四种数据模型。
2、Hive安装
Hive的安装模式分为三种,分别是嵌入模式、本地模式和远程模式。
嵌入模式:使用内嵌Derby数据库存储元数据,这是Hive的默认安装方式,配置简单,但是一次只能连接一个客户端,适合用来测试,不适合生产环境。
本地模式:采用外部数据库存储元数据,该模式不需要单独开启Metastore服务,因为本地模式使用的是和Hive在同一个进程中的Metastore服务。
远程模式:与本地模式一样,远程模式也是采用外部数据库存储元数据。不同的是,远程模式需要单独开启Metastore服务,然后每个客户端都在配置文件中配置连接该Metastore服务。远程模式中,Metastore服务和Hive运行在不同的进程中。
3、基于MySQL的Hive本地模式安装
1、安装MySQL数据库
1.1更新apt-get 命令行:sudo apt-get update
Ps:如果apt-get 安装失败,可添加中科院的镜像源:
①编辑sudo vim /etc/apt/sources.list
②在文件头添加内容:
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-security main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-updates main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-proposed main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu/ xenial-backports main restricted universe multiverse
1.2安装MySQL 命令行:sudo apt-get install mysql-server
1.2.1 设置root用户密码: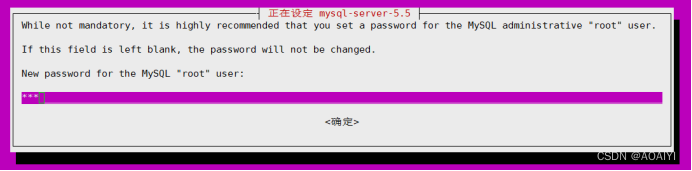
1.2.2 点击“确定”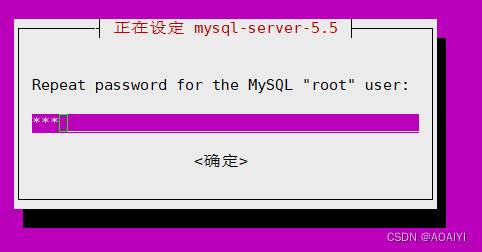
1.2.3 点击“是”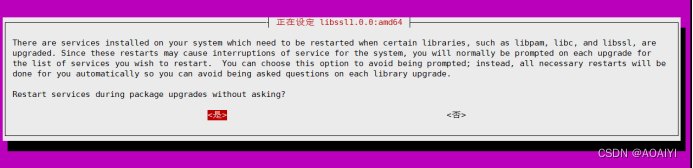
1.3登录MySQL
1.3.1 登录MySQL
①启动MySQL服务:sudo service mysql start
②登录MySQL:mysql -uroot -p123 (这里root用户密码设为123)
1.4允许远程登录MySQL
1.4.1 在MySQL命令行工具输入:
grant all on . to ‘root’@’%’ identified by ‘123456’ with grant option;
1.4.2 授权生效:
flush privileges;
1.4.3 退出MySQL:exit;
1.4.4 编辑MySQL配置文件:sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
Ps:删除或者注释掉这一行:blind-address =127.0.0.1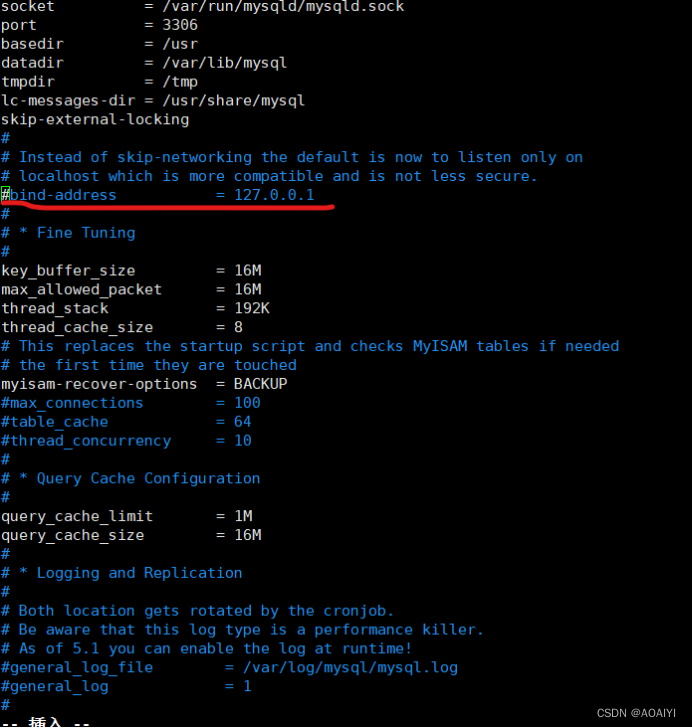
1.4.5 重启MySQL服务:sudo service mysql restart
2、安装Hive
2.1 上传并解压hive安装包
2.1.1 上传安装包到虚拟机中(注意自己的上传路径)
2.1.2 解压安装包:sudo tar -zvxf apache-hive-1.2.1-bin.tar.gz -C /usr/local/
2.1.3 重命名解压后的hive目录:sudo mv apache-hive-1.2.1-bin/ hive
2.1.4 更改hive目录拥有者为Hadoop用户:sudo chown -R hadoop:hadoop hive/
2.2 配置hive
2.2.1 打开 cd /usr/local/hive/conf/ ,将hive-default.xml.template拷贝一份,并重命名为hive-site.xml:cp hive-default.xml.template hive-site.xml
2.2.2 编辑vim hive-site.xml
Ps:将《configuration》和《/configuration》之间的内容全部删除,然后添加如下内容:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop101:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>


2.3 上传Java连接MySQL的驱动依赖包到/usr/local/hive/lib/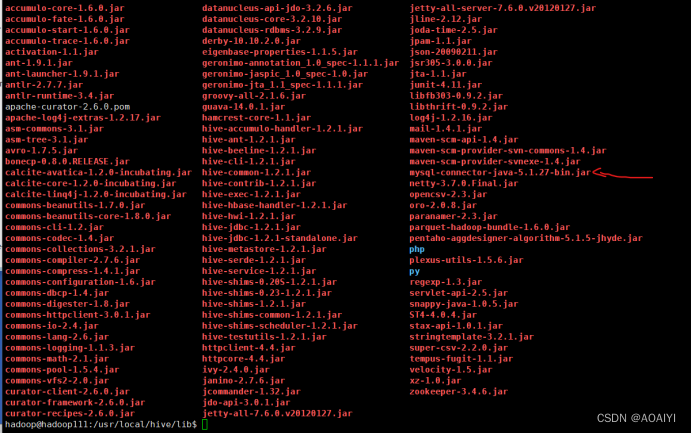
3、启动hive
3.1 将HIVE_HOME添加到环境变量
3.1.1 编辑vim ~/.bashrc
3.1.2 添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=${HIVE_HOME}/bin:$PATH
3.1.3 source生效:source ~/.bashrc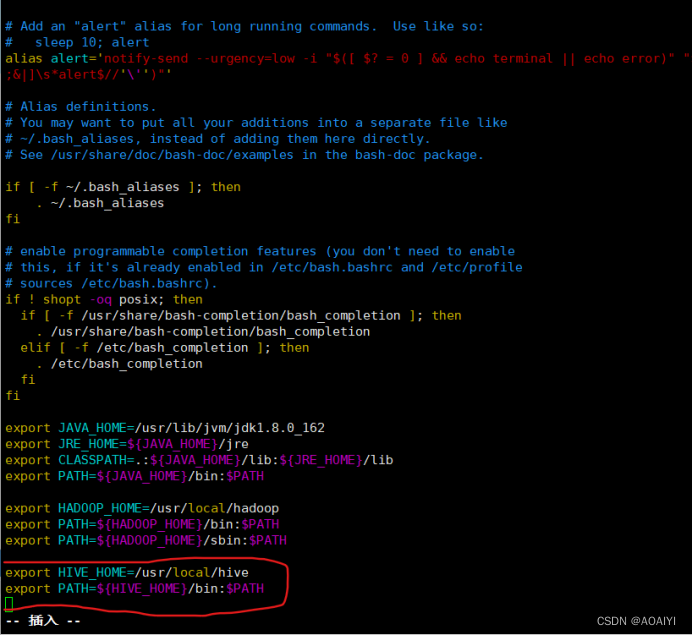
3.2 格式化MySQL
3.2.1格式化MySQL:schematool -dbType mysql -initSchema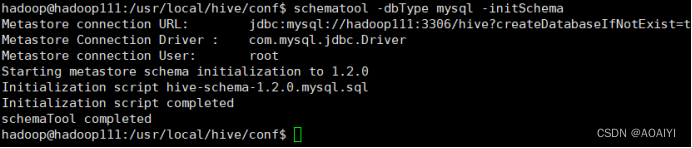
3.2.2 登录MySQL:mysql -uroot -p123 ,查看hive数据库:show databases;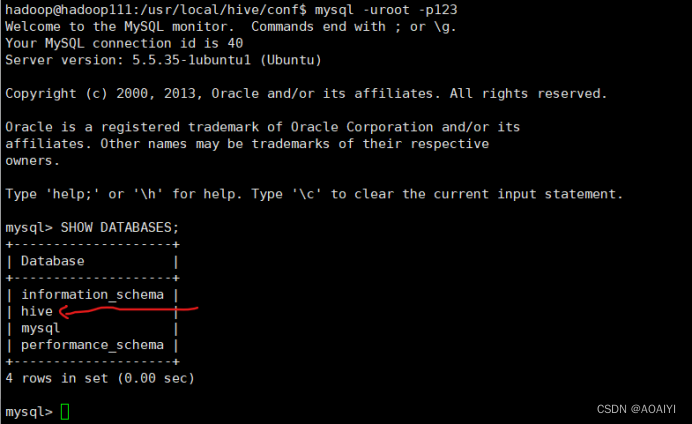
3.3 启动hive
先将HDFS和YARN 启动,再通过hive命令启动:hive
4、HIve初体验
4.1创建一个数据库test
create database test;
4.2 登录Hadoop网页(50070端口)查看命名空间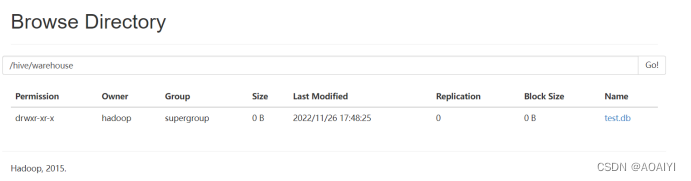
4.3 切换到数据库test
use test;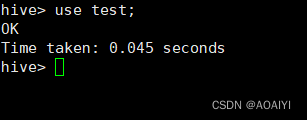
4.4 创建一张表
CREATE TABLE stu(
id string,
name string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’;
4.5 向表stu插入数据
INSERT INTO TABLE stu VALUES(101,‘zhangsan’);
INSERT INTO TABLE stu VALUES(102,‘lisi’);
INSERT INTO TABLE stu VALUES(103,‘wangwu’);
4.6 查询表
SELECT * FROM stu;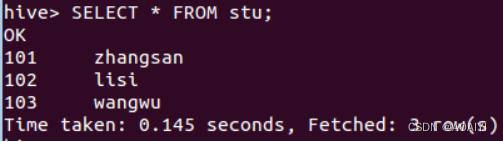
4、结尾
启动hive前,先启动dfs和yarn。如果需要Java连接MySQL的驱动依赖包和Hive安装包的,可找本博主小AO
版权归原作者 i阿极 所有, 如有侵权,请联系我们删除。