
分库分表Sharding

前言
笔者学年尚浅,目前接触的项目数据量不是很多,单表数据库最多的表数据量为562w,是一个学校的课程信息表,但是需要关联的表还是挺多的,如学籍表,如用户表等,按目前业务的发展来看,数据的增长量还是较快的。
目前的查询效率未到千万级别,再加上有缓存的配置,所以查询也不算慢。但是以防之后数据量过多导致查询效率低下,笔者学了一点
分库分表
的知识,与读者分享一下。
提醒:分库分表会给系统带来巨大的复杂性,不是万不得已建议不要提前使用。作为系统架构师可以让系统灵活性和可扩展性强,但是不要过度设计和超前设计。
什么是分库分表?
分库分表分为四种:水平分表、水平分库、垂直分表、垂直分库。
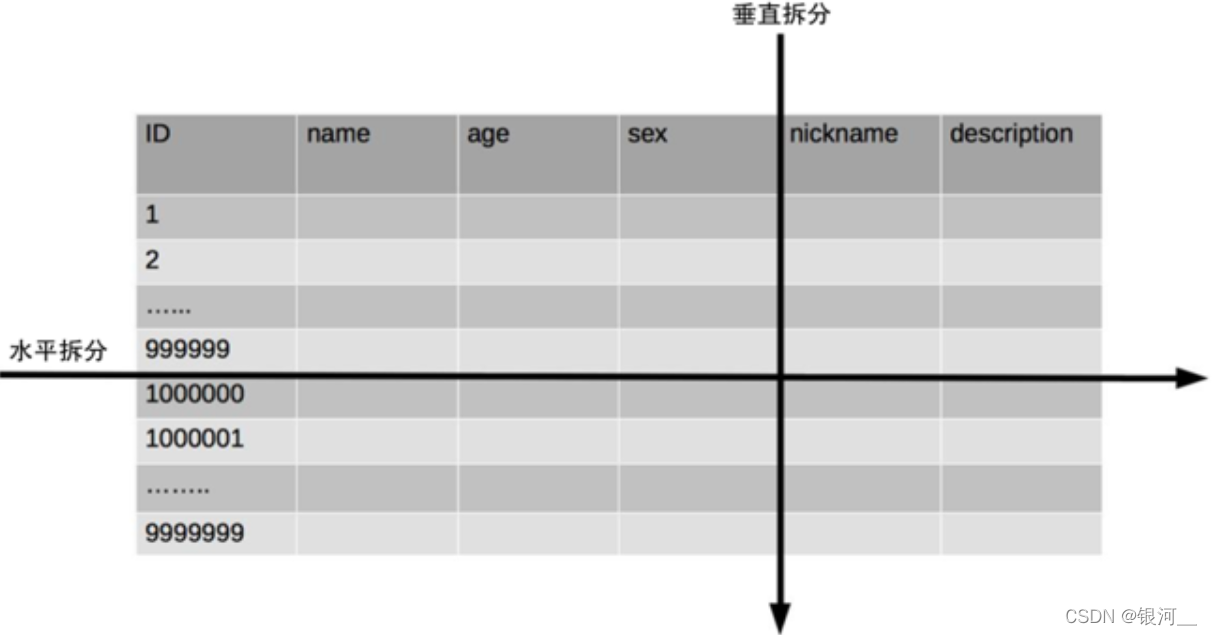
图中很好的表达了水平和垂直的含义,水平是拆分数据量,垂直是拆分字段(或表),很好理解。
使用场景
垂直分表:比如商品名称图片与商品描述,一般我们是存在一个表中,但商品描述相比名称图片又不是很重要,所以我们可以把描述字段分为另一个表,两个表以商品id相连。这样我们在查询时,名称图片查询时会少了描述字段,减少单表查询的磁盘I/O。
垂直分库:比如用户库与订单库,可以分在不同的数据库,增大单个数据库业务的吞吐量。操作用户系统就用户数据库,操作订单系统就订单数据库。
水平分表:单表数据量超过一定数量,查询操作会变的很慢。业内流传超过500w就考虑拆分,但其实只要不到1000w,也不会有很大变化。
水平分库:单数据库数据量太多,请求太多,将数据分散在不同数据库,减少对单个数据库的查询时间,提高数据库的承载量。
总结:
将业务数据进行解耦–垂直拆分
解决容量和性能压力–水平拆分
当然具体业务要具体分析,
SQL调优
、
缓存设置
、
读写分离
等提高的效果显著,并且成本很低,使用是优先考虑这些,不要为了分库分表而分库分表。
分库分表的复杂性
(1)跨库关联查询
在未拆分之前,我们只用简单的join就可以关联,但经过分库分表后两种表可能不在同一个数据库,那要怎么进行关联查询呢?
- 字段冗余:把要关联的字段放入主表中,避免join操作。
- 数据抽象:把各关联字段抽取出来,生成新的表。
- 公共表:将基础表在每个数据库都生成一份。
- 应用层组装:将基础数据查出来,通过应用程序计算组装。。
(2)分布式事务
单数据库用本地事务就可以搞定,使用多数据库就只能通过分布式事务解决了。
常用解决方案有:基于可靠消息(MQ)的解决方案、两阶段提交等。
(3)排序、分页、函数计算问题
在使用SQL时Order By、Limit等关键字需要特殊处理,一般来说采用分片的思想。
先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终得到结果(分库分表中间件一般会自己处理)
(4)分布式ID
如果是一个表,那可以id自增作为主键,但是分库分表之后就不行了,会出现id重复。常用的分布式ID解决方案有:UUID、雪花算法(SnowFlake)、美团Leaf等。
技术选型
笔者选择的中间件为
Sharding-JDBC
基于Sharding-JDBC的MySQL读写分离用起来真是很方便,而且ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目了
轻量级的Java框架,直接引入jar包即可。这意味着在项目中不需要做额外的安装软件,或者开启一部署某一个服务器框架。这对于学生机是很友好的,并且也是不收费的,适合自己的才是最好的。。。。。
但是缺点也是存在的,相比MyCat等有部署服务的框架,比如不便于观测和检测。
并且相比云数据库,基于中间件的分布式数据库,相对于单纯的中间件来说, 创建/管理方便、关键指标可视化/自动化告警、复杂运维。
demo
笔者分库分表还未真正应用,目前也只采用了水平分表的学习而已,但其实都差不多。简单展示一下。
操作方法与平时用的SpringBoot、MyBatisPlus那一套一样,只用配置文件
application.propertie(yml)
加一些配置即可,官网的配置很详细,需要配置自行去查考。
原表数据量562w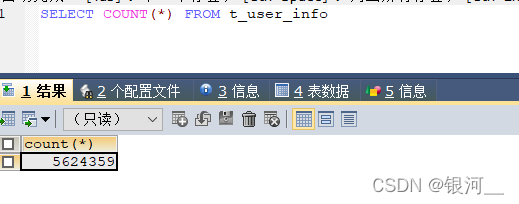
根据用户id取模2之后分为两个表,每个表280w
其他完全不影响我的增删改查。
版权归原作者 银河__ 所有, 如有侵权,请联系我们删除。