
第1章 Kafka概述
1.1 定义
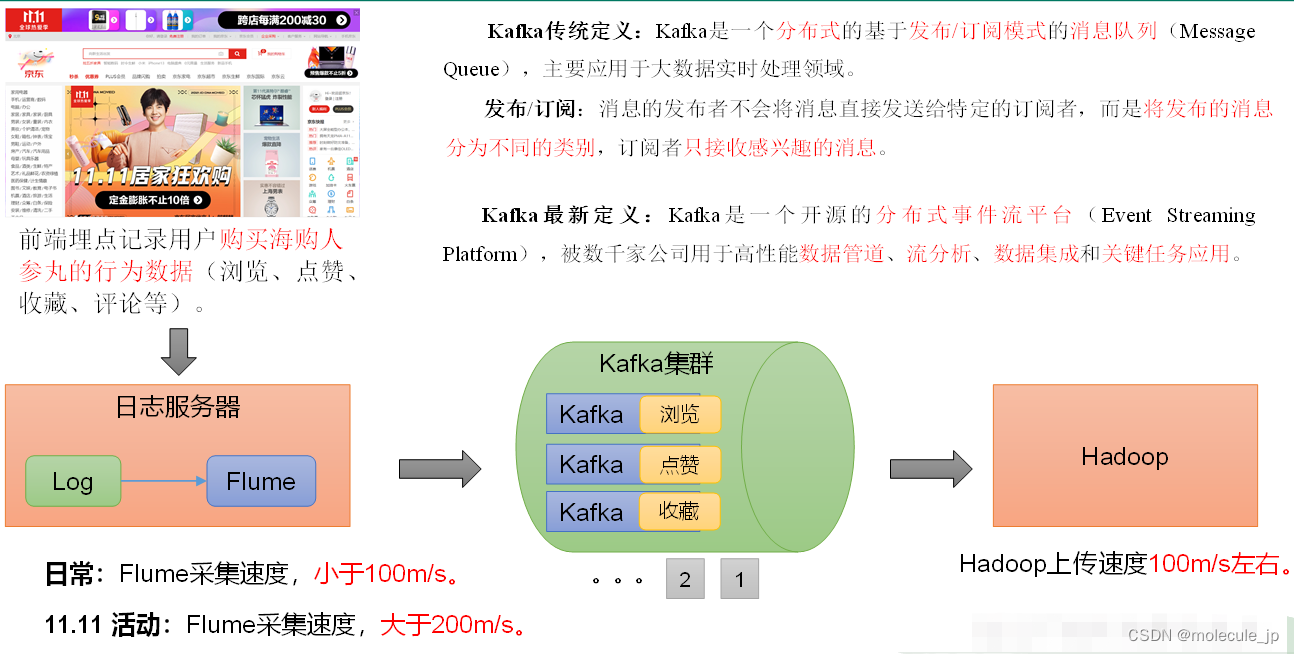
1.2 消息队列
目前企业中比较常见的消息队列产品主要有Kafka、ActiveMQ、RabbitMQ、RocketMQ等。Message Queue
② 在大数据场景主要采用Kafka作为消息队列
② 在JavaEE开发中主要采用ActiveMQ、RabbitMQ、RocketMQ
Kafka存储数据,且保证数据一致性,存取速度都很快!
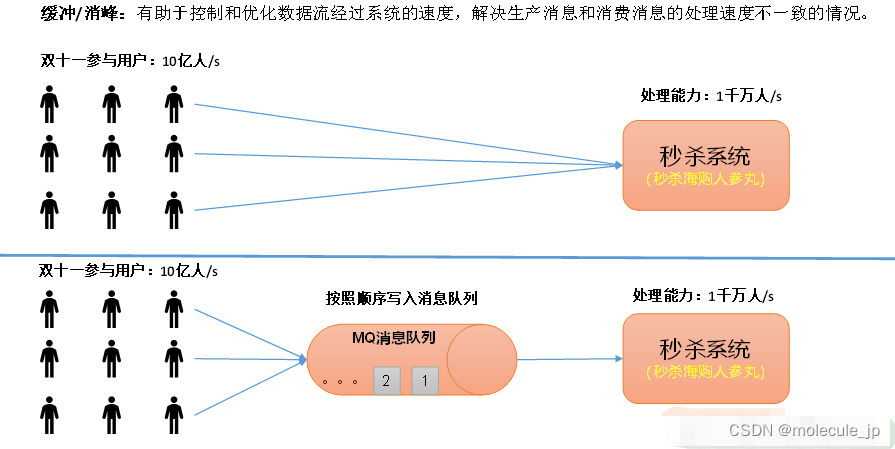
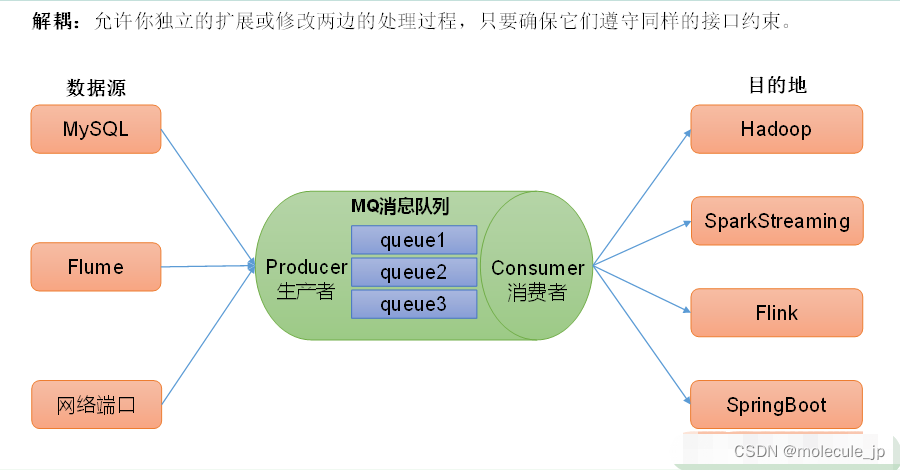
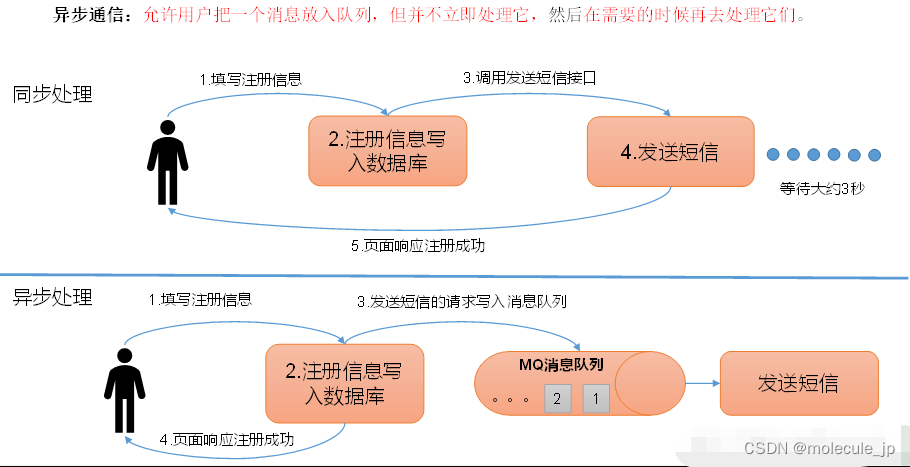
1.2.1 传统消息队列的应用场景
- 传统的消费队列的主要应用场景有:缓存/削峰、解耦、异步通信。
1.2.2 消息队列的两种模式
消息队列主要分为两种模式:点对点模式和发布/订阅模式。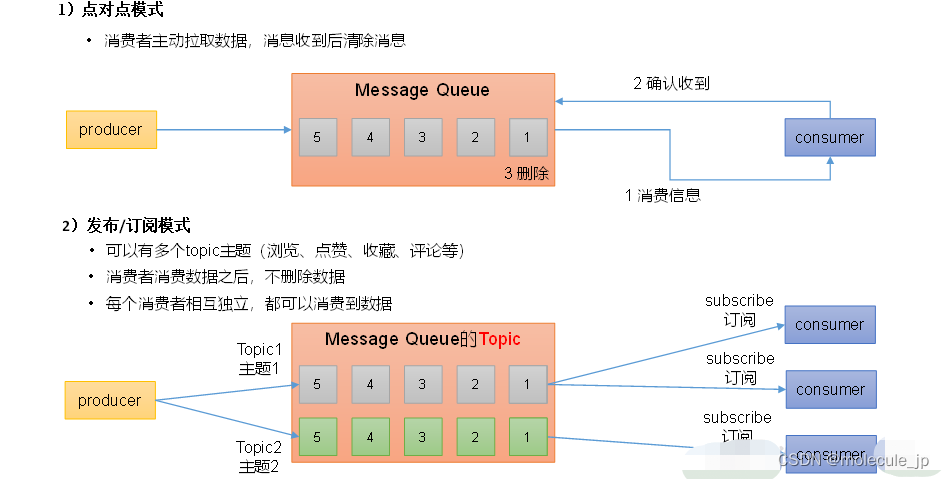
1.3 Kafka基础架构
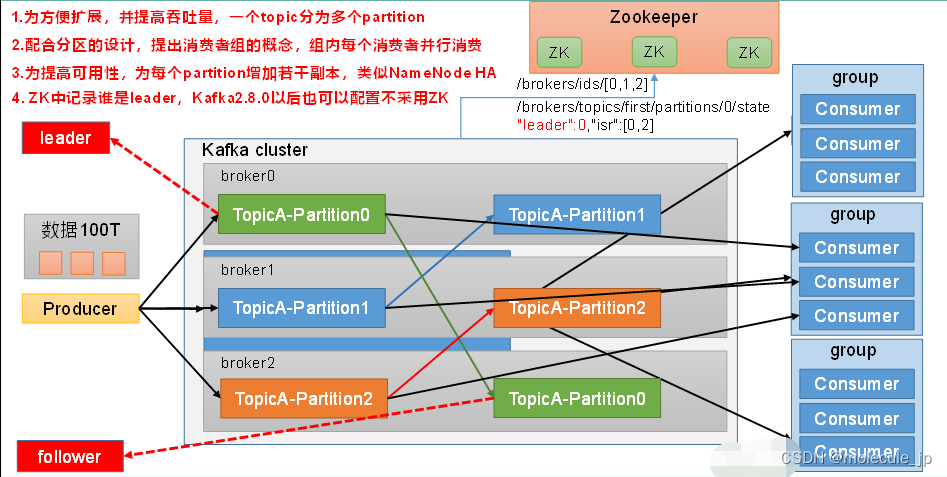
1)Producer :消息生产者,就是向kafka broker发消息的客户端;
2)Consumer :消息消费者,向kafka broker取消息的客户端;
3)Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个topic下的一个分区只能被一个消费者组内的一个消费者所消费;消费者组之间互不影响。消费者组是逻辑上的一个订阅者。
4)Broker :一台kafka服务器就是一个broker。一个broker可以容纳多个topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic;
6)Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
8)leader:每个分区副本中的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
9)follower:每个分区副本中的“从”,实时与leader副本保持同步,在leader发生故障时,成为新的leader。
第2章 Kafka快速入门
2.1 安装部署
2.1.1 集群规划

2.1.2 集群部署
- 官方下载地址:http://kafka.apache.org/downloads.html
- 上传安装包到102的/opt/software目录下 [aa@hadoop102 software]$ ll -rw-rw-r–. 1 atguigu atguigu 86486610 3月 10 12:33 kafka_2.12-3.0.0.tgz
- 解压安装包到/opt/module/目录下 [aa@hadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
- 进入到/opt/module目录下,修改解压包名为kafka [a@hadoop102 module]$ mv kafka_2.12-3.0.0 kafka
- 修改config目录下的配置文件server.properties内容如下 [aa@hadoop102 kafka]$ cd config/ [aa@hadoop102 config]$ vim server.properties
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=102
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
- 配置环境变量
[aa@hadoop102 kafka]$ sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[atguigu@hadoop102 kafka]$ source /etc/profile
- 分发环境变量文件并source
[aa@hadoop102 kafka]$ xsync /etc/profile.d/my_env.sh
==================== hadoop102 ====================
sending incremental file list
sent 47 bytes received 12 bytes 39.33 bytes/sec
total size is 371 speedup is 6.29==================== hadoop103 ====================
sending incremental file list
my_env.sh
rsync: mkstemp "/etc/profile.d/.my_env.sh.Sd7MUA" failed: Permission denied (13)
sent 465 bytes received 126 bytes 394.00 bytes/sec
total size is 371 speedup is 0.63
rsync error: some files/attrs were not transferred (see previous errors)(code 23) at main.c(1178)[sender=3.1.2]==================== hadoop104 ====================
sending incremental file list
my_env.sh
rsync: mkstemp "/etc/profile.d/.my_env.sh.vb8jRj" failed: Permission denied (13)
sent 465 bytes received 126 bytes 1,182.00 bytes/sec
total size is 371 speedup is 0.63
rsync error: some files/attrs were not transferred (see previous errors)(code 23) at main.c(1178)[sender=3.1.2],
# 这时你觉得适用sudo就可以了,但是真的是这样吗?
[aa@hadoop102 kafka]$ sudo xsync /etc/profile.d/my_env.sh
sudo: xsync:找不到命令
# 这时需要将xsync的命令文件,copy到/usr/bin/下,sudo(root)才能找到xsync命令
[aa@hadoop102 kafka]$ sudo cp /home/atguigu/bin/xsync /usr/bin/[aa@hadoop102 kafka]$ sudo xsync /etc/profile.d/my_env.sh
# 在每个节点上执行source命令,如何你没有xcall脚本,就手动在三台节点上执行source命令。
[aa@hadoop102 kafka]$ xcall source /etc/profile
- 分发安装包
[aa@hadoop102 module]$ xsync kafka/
- 修改配置文件中的brokerid 分别在hadoop103和hadoop104上修改配置文件server.properties中broker.id=103、broker.id=104
注:broker.id不得重复
[aa@hadoop103 kafka]$ vim config/server.properties
broker.id=103 [atguigu@hadoop104 kafka]$ vim config/server.properties
broker.id=104
- 启动集群 ① 先启动Zookeeper集群
[aa@hadoop102 kafka]$ zk.sh start
② 依次在hadoop102、hadoop103、hadoop104节点上启动kafka
[aa@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[aa@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[aa@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
版权归原作者 molecule_jp 所有, 如有侵权,请联系我们删除。