
一.引言
前面讲到了 Flink - 大规模状态 ValueState IO 实践与优化,工业场景下 Flink 经常使用 ValueState + RocksDBStateBackend 的组合,由于 RocksDBStateBackend IO 侧的压力,对于状态访问 QPS 过高的任务,需将状态后端转换至 HashMapStateBackend,但是受限于 JVM Heap 的容量,大规模状态 ValueState 任务还需继续进行优化。
二.ValueState + HashMapStateBackend
1.IO 瓶颈
为了解决 RocksDbStateBackend 序列化造成的机器 IO 压力过大导致程序出现背压的情况,我们采用 HashMapStateBackend 存储大规模状态,修改后任务峰值 QPS 阶段不再受 IO 影响。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new HashMapStateBackend)
// 切换为 FsStateBackend
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage(path));
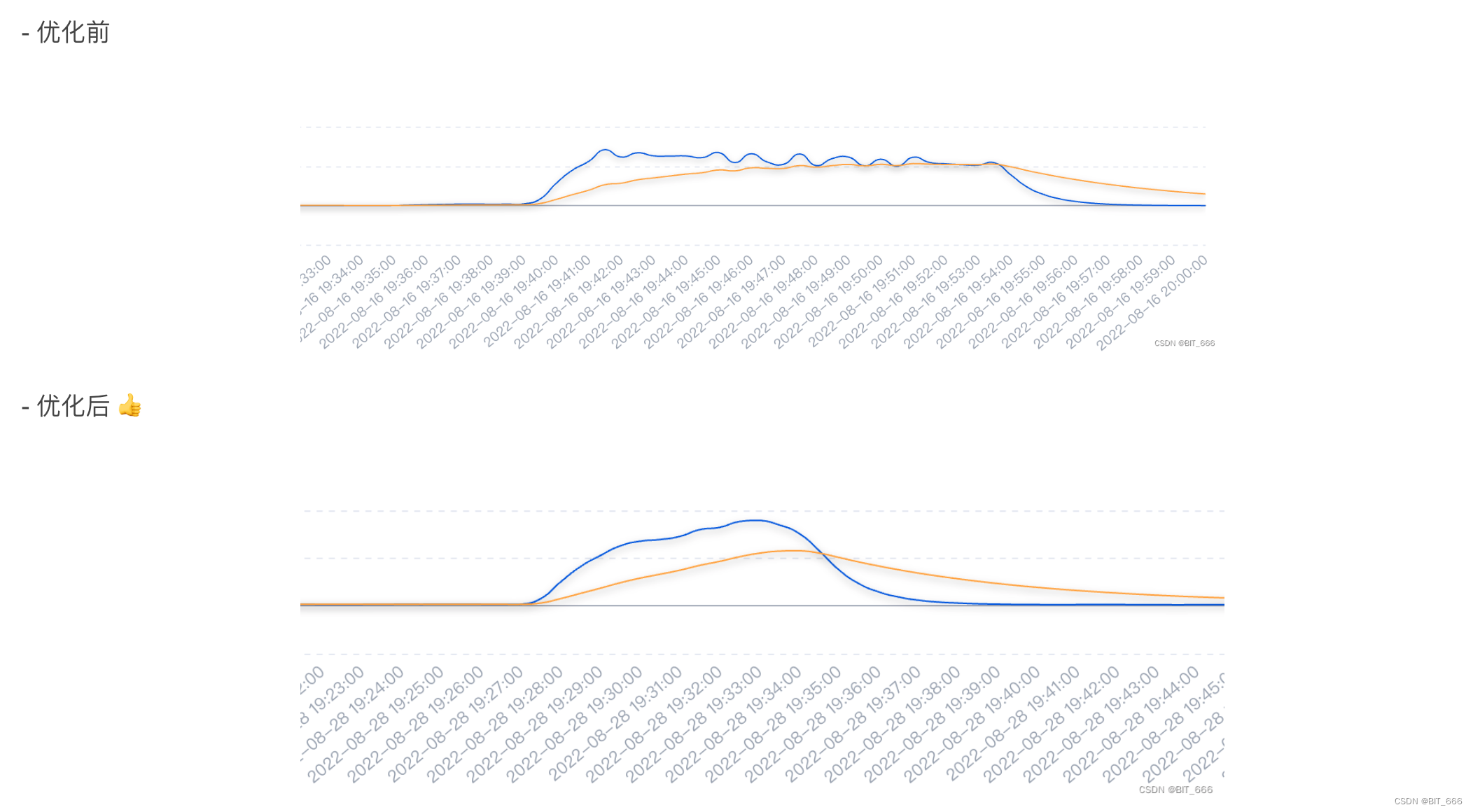
上图为优化前后 Kafka Sink 的流量图,可以看到优化后任务不再受限于 IO 瓶颈,kafka 的写出速率由平行线转换为驼峰线。
2.JVM 瓶颈
任务修改后正常运行了几天,但是新的问题又来了 runing beyond physical memory limits:

由于峰值 QPS 持续增高,虽然 IO 不再影响任务运行,但是由于 JVM 的内存瓶颈,导致峰值数据流量过高时内存溢出从而导致 TaskManager Failed,继而导致任务失败。

下面针对 JVM 进行定位与优化。
三.JVM 内存瓶颈定位
1.Total TM 内存分析
Flink 程序会对每条数据对应的 id 存储一个 ValueState 在对应 ProcessFunction 所处的 Stage,所以随着时间的推移,新增的 id 越来越多,导致内存处于持续增长的状态,所以导致最终内存溢出。
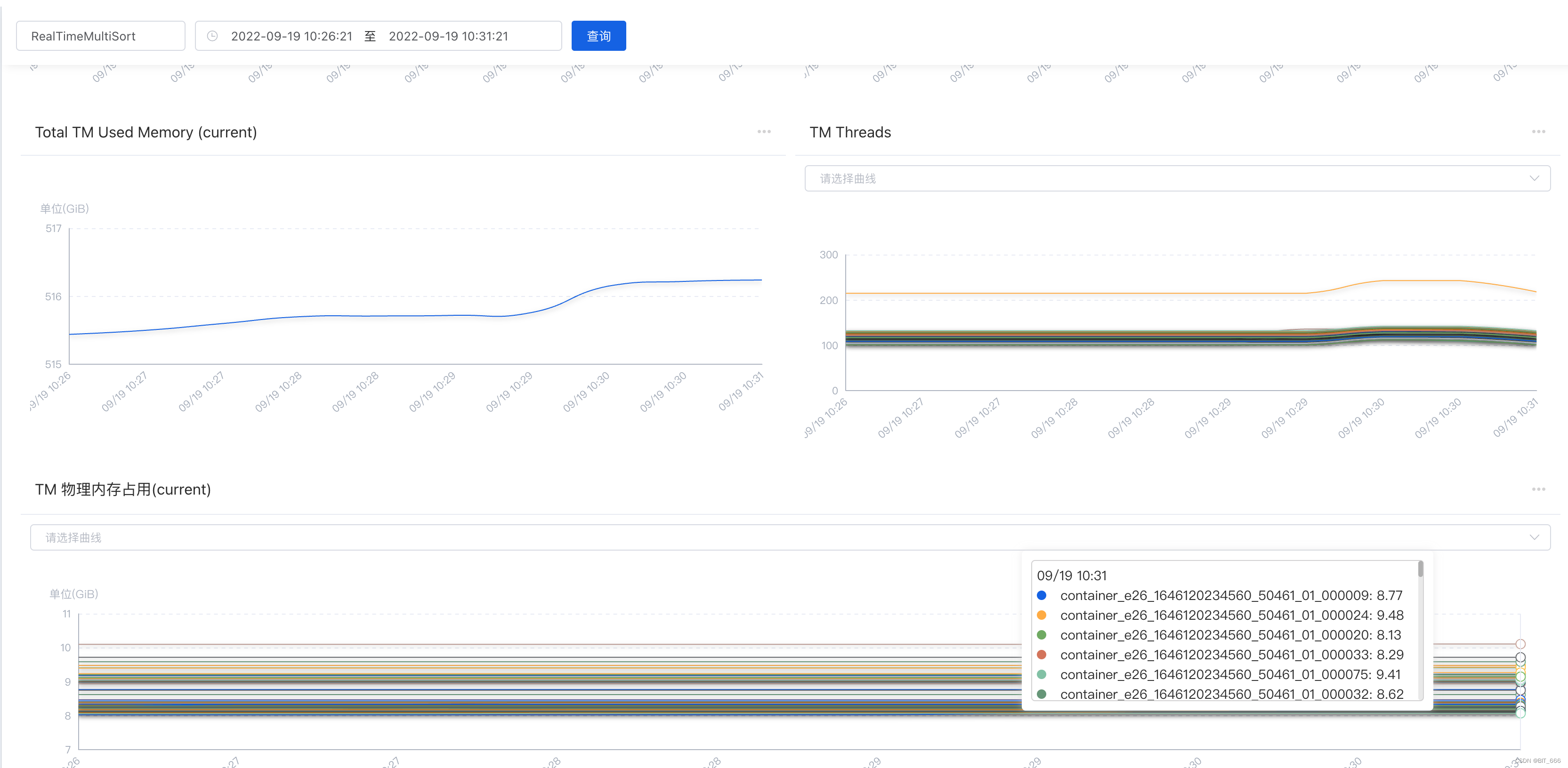
从图中 Total TM Used Memory(current) 可以看出随着时间推移,全部 TaskManager 占用的内存呈缓慢增长的状态,而每个 TaskManager 对应的单台 Container 所占用内存也已经飙升至 8-9 GB,距离总的内存限制 11 GB 非常接近,所以当短时再来一批大数据缓存 + GC不及时,对应 Container 就会报错内存溢出从而被 Kill。
Tips:
通过这一步分析,我们了解到内存不断增加是因为初始化的 ValueState 越来越多导致。
2.Single TM 内存分析
下图为 TM 申请 10GB 时的内存 Metric 图,可以看到运行期间 TaskHeap 6.03GB / 7.32GB,占比达到了 82.4%,处在危险边缘,一旦短时大批量数据请求或者发生 FullGC 等情况,极易导致内存移除;除此之外,可以看到 1GB 的 JVM Overhead 并未使用且 Network 的容量也只使用了 97.8MB / 896 MB,所以内存的分配也很不合理。
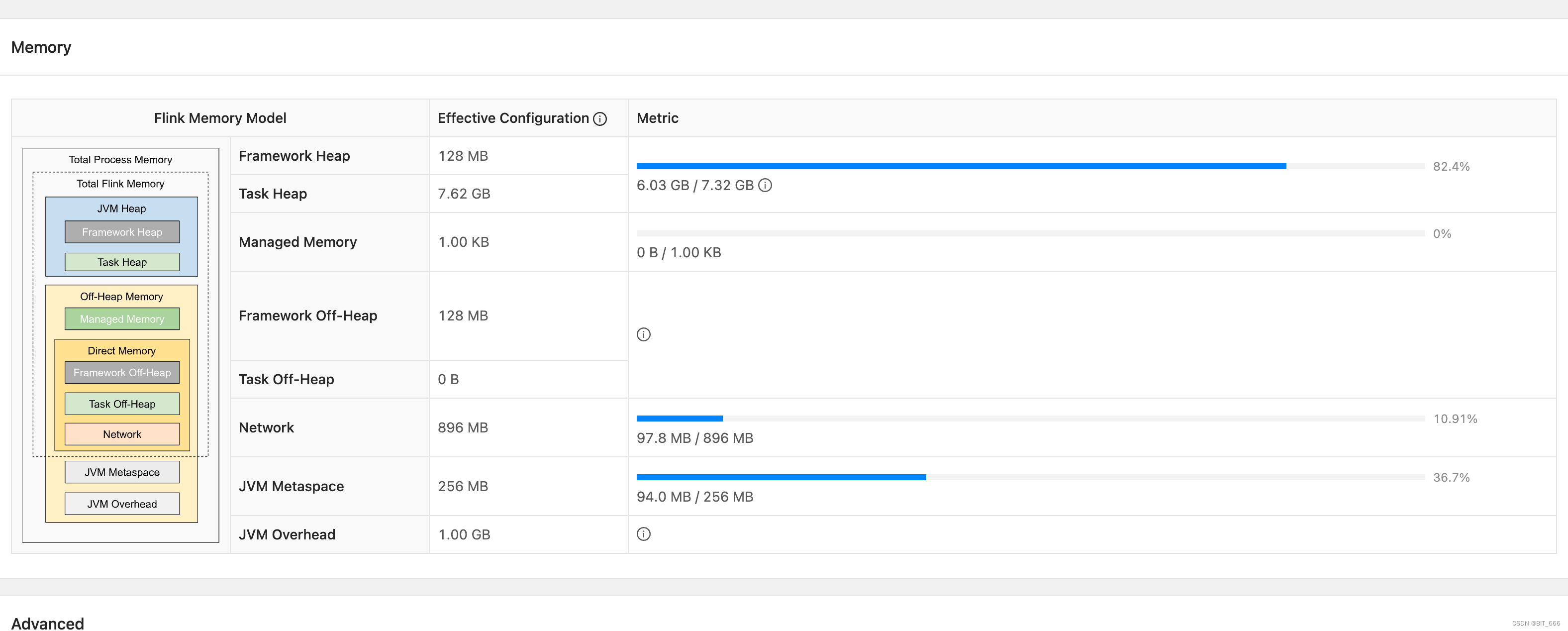
Tips:
通过这一步分析,我们了解到程序内存紧张,其中还有一部分原因是内存分配不合理,导致大量内存被浪费或闲置。
四.ValueState 大状态内存优化
HashMapStateBackend 下 ValueState 内存存储量过大,经过上述问题分析与排查,我们在不增加内存的基础上,总结如下几个优化方向:
A.ValueState 存储容量缩减:对 ValueState 内变量进行优化,例如 Long -> Double,String -> Long 的基础变量变化与压缩方法。
B.ValueState 存储数量缩减:对 ValueState 数量进行控制,结合业务场景,对无关紧要的数据放弃 ValueState 存储,对次要的数据 ValueState 进行及时的清除。
C.TaskManager 内存分配优化:对 TM 内存格局进行重分配,分配不合理和空闲内存为 Task Heap 所用。
D.TaskManager 存在数据倾斜:数据倾斜会造成某个 Container 下数据量过大,从而导致单台 Container 异常。
1.ValueState 容量缩减
对于一些 Id 类我们习惯使用 String 或者 Long 存储,如果 id 的长度可以控制在 Int 范围内,使用 Int 代替 String 或者 Long,将进一步优化内存占用,其次对于精度要求不高的变量,可以由 Double 优化为 Float,继而进一步优化内存空间。
class TestClassLarge() {
val id: String = "12345"
val score: Double = 0.98D
}
class TestClassTiny() {
val id: Int = 12345
val score: Float = 0.98F
}
println(SizeEstimator.estimate(new TestClassLarge))
println(SizeEstimator.estimate(new TestClassTiny))
同样存储 id=12345 与 score=0.98,前者使用 80 bytes,后者使用 24 bytes,二者相差3倍之多,当这样的 ValueState 数量是百万甚至千万量级时,节省的 Total TM 内存容量就是:

按 1000w 量级,一个变量类型的修改,就可以节省 0.5 GB 的内存,如果 Class 内还有更多的 HashMap,List,Array 等大变量,节省的内存空间将更加可观。
2.ValueState 数量缩减
减少数量肯定可以减少内存占用,但是这一步优化需要结合业务场景,区分数据的重要性或者优先级,如果所有数据都一样重要,则这一步无法进行优化,因为所有数据都要存储到 StateBackend 下,前面我们也提到了 Total TM 的内存缓慢但持续增长中:
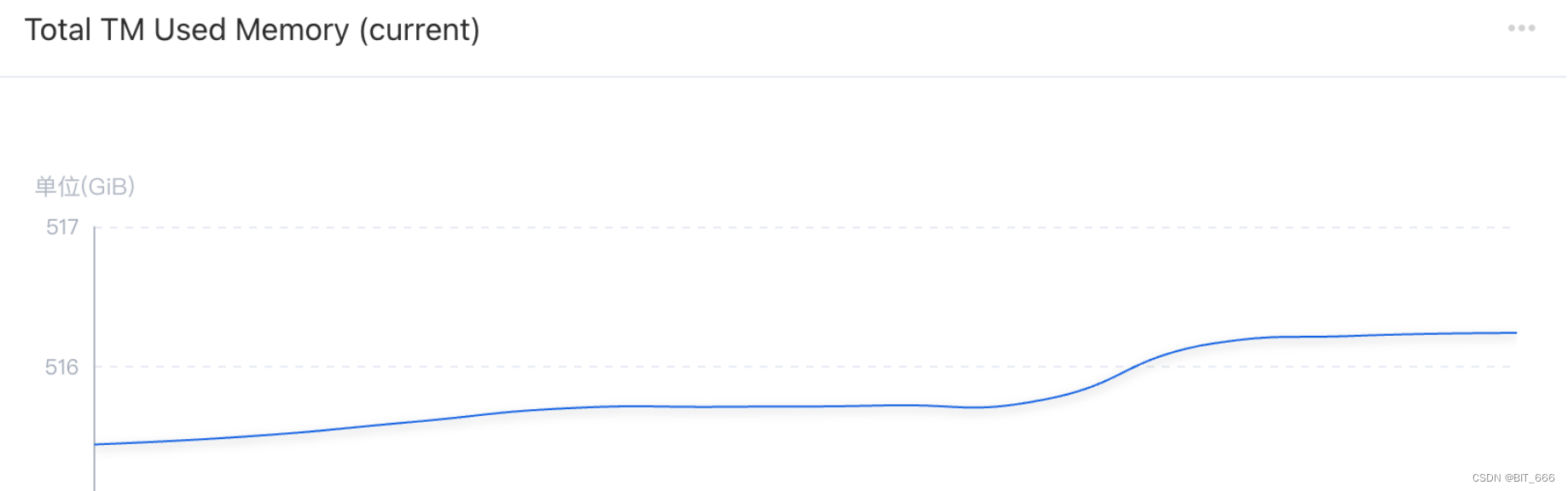
所以此时我们应该适当减少 ValueState 的数量,最简单的方法就是 state.clear():
Integer dataLevel = 0; // 标识数据重要性
if (dataLevel.equals(0)) {
state.clear();
} else {
state.update(valueState);
}
我们可以基于业务背景与 data 中的数据,给数据一个 dataLevel 标及其重要程度,对于低优先级的数据,我们将其 ValueState 及时清除,这样内存的增长速度也可以得到有效控制。
3.TM 内存分配优化
修改前:
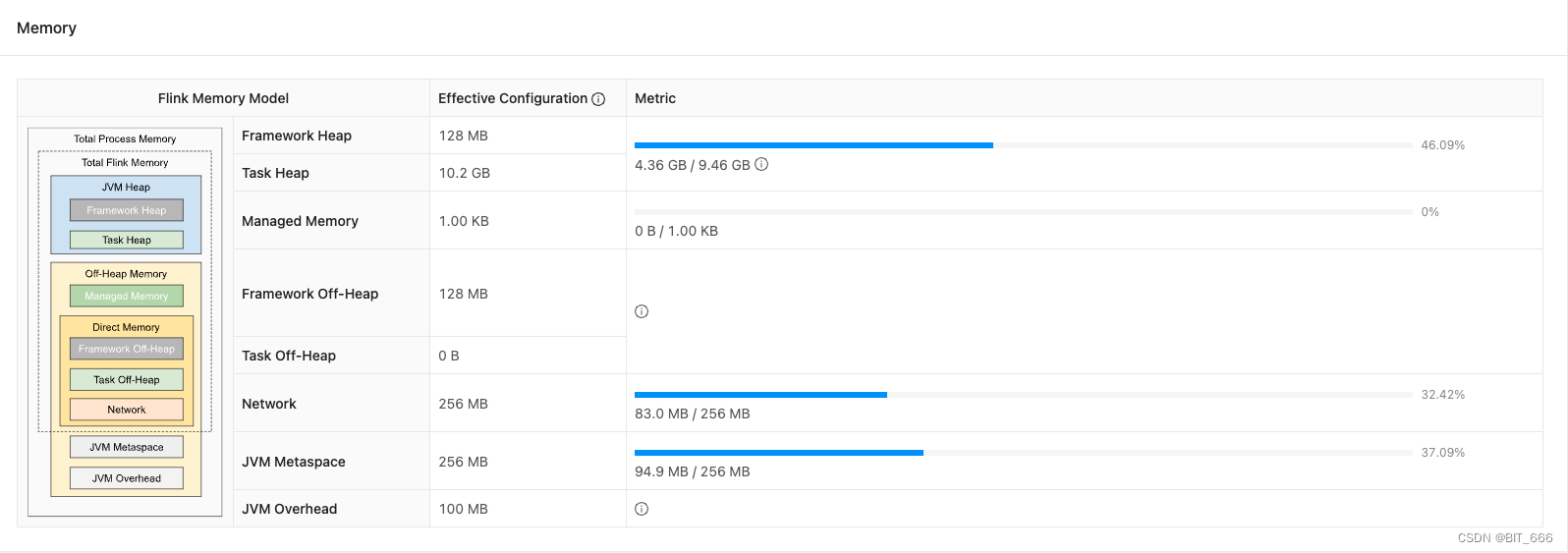
Network 占用 10.91%,剩余约 800 mb 内存,JVM Overhead 剩余 1GB 内存,合计 1.8GB:
修改后:
Network 保留 256mb,JVM Overhead 保留 100mb,其余全部让给 TaskHeap,单个 TM 立增 1.5 GB Heap,由于还单独多申请了 1GB 内存,所以这里实际 Heap 增加了 2.14 GB。
-yD taskmanager.memory.jvm-overhead.min=100mb \
-yD taskmanager.memory.jvm-overhead.max=100mb \
-yD taskmanager.memory.network.min=256mb \
-yD taskmanager.memory.network.max=256mb \
4.数据倾斜
上面三个优化是数据均匀情况下对 Task Heap 的内存优化方案,如果是数据倾斜导致的单台 Container 数据量异常的话,则首先需要解决数据倾斜的问题。数据倾斜一般由于 keyBy 数据不匀,存在热点 key 导致某个 window 或 state 数据量过多导致,这里我们可以查看 Flink Monitor UI 查看对应 stage 的 subtask 数据量接收是否存在较大差异:
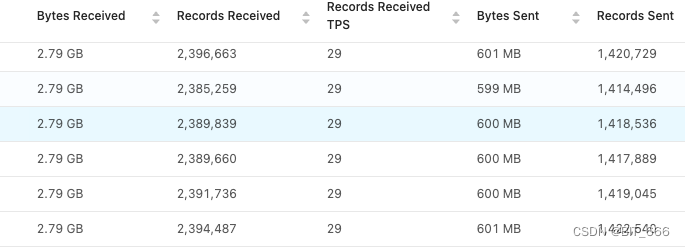
通过观察整体数据分配还是均匀的,所以不存在数据倾斜的问题,如果某个 task 数据量异常,则需要分析是否存在热点 key 导致数据倾斜,如果存在可以通过 key + random 的方式进行打散的方式调整数据均匀程度。
五.总结
通过优化 ValueState 容量,控制 ValueState 数量,优化 TM 内存分配以及增加内存资源,任务 TM 的内存容量与运行期间的内存占用量得到大大改善,在 -ytm 11264 即 11G 的情况下。
19号优化前:

20号优化后:
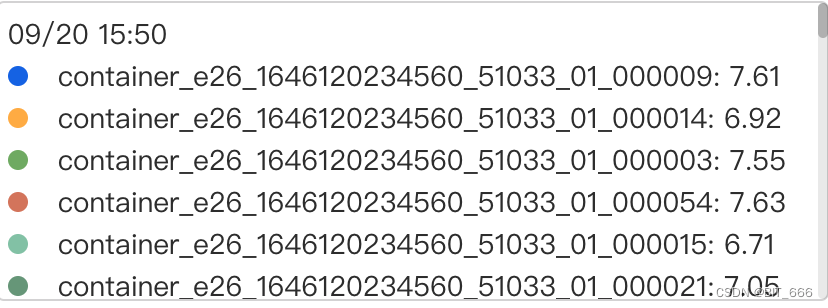
平均每个 TM 上内存占用均节省 1-2 GB,整体任务内存压力也大大降低,非常的奈斯。👍
版权归原作者 BIT_666 所有, 如有侵权,请联系我们删除。