
PostgreSQL 12.16 Documentation
官网
github
世界上最先进的开源关系数据库
1、新手入门
1.1 安装
当然,在使用PostgreSQL之前,你需要安装它。PostgreSQL可能已经安装在您的站点上,或者因为它包含在您的操作系统发行版中,或者因为系统管理员已经安装了它。如果是这种情况,您应该从操作系统文档或系统管理员那里获取有关如何访问PostgreSQL的信息。
如果你不确定PostgreSQL是否已经可用,或者你是否可以使用它进行实验,那么你可以自己安装它。这样做并不难,而且是一种很好的锻炼。PostgreSQL可以由任何非特权用户安装;不需要超级用户(root)访问。
如果您自己安装PostgreSQL,请参考第16章的安装说明,并在安装完成后返回本指南。一定要仔细阅读关于设置适当的环境变量的部分。
如果您的站点管理员没有以默认方式设置,那么您可能需要做更多的工作。例如,如果数据库服务器机器是远程机器,则需要将
PGHOST
环境变量设置为数据库服务器机器的名称。
可能还必须设置环境变量
PGHOST
。底线是:如果您尝试启动一个应用程序,而它抱怨无法连接到数据库,那么您应该咨询站点管理员,或者(如果是您的话)咨询文档,以确保正确设置了环境。如果你不理解前一段,那么请阅读下一节。
1.2 架构基础知识
在我们继续之前,您应该了解基本的PostgreSQL系统架构。理解PostgreSQL各部分是如何相互作用的,将使本章更加清晰。
在数据库术语中,PostgreSQL使用客户机/服务器模型。一个PostgreSQL会话(session )由以下进程(程序)组成:
- 服务器(server)进程管理数据库文件,接受来自客户机应用程序到数据库的连接,并代表客户机执行数据库操作。数据库服务器程序称为
postgres。 - 需要执行数据库操作的用户的客户机 (client) (前端)应用程序。客户端应用程序在本质上可以是多种多样的:客户端可以是一个面向文本的工具,一个图形化的应用程序,一个访问数据库以显示网页的web服务器,或者一个专门的数据库维护工具。一些客户端应用程序是随PostgreSQL发行版提供的;大多数是由用户开发的。
作为典型的客户机/服务器应用程序,客户机和服务器可以位于不同的主机上。在这种情况下,它们通过TCP/IP网络连接进行通信。您应该记住这一点,因为可以在客户机机器上访问的文件在数据库服务器机器上可能无法访问(或者只能使用不同的文件名访问)。
PostgreSQL服务器可以处理来自客户端的多个并发连接。
为此,它为每个连接启动(“forks”)一个新进程
。从那时起,客户机和新的服务器进程进行通信,而不受原始
postgres
进程的干预。因此,主服务器进程总是在运行,等待客户端连接,而客户端和关联的服务器进程来来往往。(当然,所有这些对用户来说都是不可见的。我们在这里提到它只是为了完整。)
1.3 创建数据库
查看是否可以访问数据库服务器的第一个测试是尝试创建一个数据库。一个运行中的PostgreSQL服务器可以管理多个数据库。通常,为每个项目或每个用户使用一个单独的数据库。
可能您的站点管理员已经创建了一个数据库供您使用。在这种情况下,您可以省略这一步,直接跳到下一节。
要创建一个新的数据库,在本例中名为
mydb
,使用以下命令:
$ createdb mydb
如果没有产生响应,则此步骤成功,您可以跳过本节的其余部分。
如果您看到类似如下的消息:
createdb: command not found
那么PostgreSQL没有正确安装。要么是根本没有安装它,要么是没有将shell的搜索路径设置为包含它。试着用绝对路径来调用命令:
$ /usr/local/pgsql/bin/createdb mydb
您站点上的路径可能不同。请联系您的站点管理员或检查安装说明以纠正这种情况。
另一种回应可能是:
createdb: could not connect to database postgres: could not connect to server: No such file or directory
Is the server running locally and accepting
connections on Unix domain socket "/tmp/.s.PGSQL.5432"?
这意味着服务器没有启动,或者它没有在
createdb
期望的位置启动。同样,请检查安装说明或咨询管理员。
另一种回应可能是:
createdb: could not connect todatabase postgres:FATAL: role "joe" does not exist
其中提到了您自己的登录名。如果管理员没有为您创建PostgreSQL用户帐户,则会发生这种情况。(PostgreSQL用户帐户不同于操作系统用户帐户。)如果您是管理员,请参见第21章创建帐户。您需要成为安装PostgreSQL的操作系统用户(通常是
postgres
)才能创建第一个用户帐户。也可能是你被分配的PostgreSQL用户名与你的操作系统用户名不同;在这种情况下,您需要使用
-U
开关或设置
PGUSER
环境变量来指定您的PostgreSQL用户名。
如果您有一个用户帐户,但它没有创建数据库所需的特权,您将看到以下内容:
createdb: database creation failed:ERROR: permission denied tocreate database
并非每个用户都有创建新数据库的授权。如果PostgreSQL拒绝为你创建数据库,那么站点管理员需要授予你创建数据库的权限。如果发生这种情况,请咨询您的站点管理员。如果您自己安装了PostgreSQL,那么为了本教程的目的,您应该以启动服务器时的用户帐户登录。[1](解释一下为什么这样做:PostgreSQL用户名与操作系统用户帐户是分开的。当你连接到数据库时,你可以选择连接的PostgreSQL用户名;如果不这样做,它将默认使用与当前操作系统帐户相同的名称。碰巧的是,总是有一个PostgreSQL用户帐户与启动服务器的操作系统用户具有相同的名称,并且该用户总是具有创建数据库的权限。你也可以在任何地方指定
-U
选项来选择要连接的PostgreSQL用户名,而不是以该用户登录。)
您还可以使用其他名称创建数据库。PostgreSQL允许您在给定站点上创建任意数量的数据库。数据库名称的第一个字符必须是字母,长度限制为63字节。一个方便的选择是创建一个与当前用户名同名的数据库。许多工具都假定数据库名称为默认值,因此它可以节省一些输入。要创建该数据库,只需输入:
$ createdb
如果不想再使用数据库,可以将其删除。例如,如果您是数据库mydb的所有者(创建者),您可以使用以下命令销毁它:
$ dropdb mydb
(对于该命令,数据库名称不默认为用户帐户名称。您总是需要指定它。)此操作将物理地删除与数据库关联的所有文件,并且无法撤消,因此只有在进行大量预先考虑的情况下才能执行此操作。
关于createdb和dropdb的更多信息可以分别在createdb和dropdb中找到。
1.4 访问数据库
一旦你创建了一个数据库,你可以通过以下方式访问它:
- 运行PostgreSQL交互式终端程序,称为
psql,它允许您交互式地输入,编辑和执行SQL命令。 - 使用现有的图形前端工具(如
pgAdmin)或具有ODBC或JDBC支持的办公套件来创建和操作数据库。本教程不涉及这些可能性。 - 使用几种可用的语言绑定来编写自定义应用程序。这些可能性将在第四部分进一步讨论。
您可能希望启动
psql
来尝试本教程中的示例。它可以通过输入以下命令来激活
mydb
数据库:
$ psql mydb
如果您不提供数据库名称,那么它将默认为您的用户帐户名称。在前一节中,您已经使用
createdb
发现了这个方案。
在
psql
中,您将看到以下消息:
psql (12.15)
Type "help"for help.
mydb=>
最后一行也可以是:
mydb=#

这意味着您是数据库超级用户,如果您自己安装了PostgreSQL实例,则很可能是这种情况。作为超级用户意味着您不受访问控制的约束。对于本教程而言,这并不重要。
如果在启动
psql
时遇到问题,请回到上一节。
createdb
和
psql
的诊断是相似的,如果前者可以,后者也应该可以。
psql
打印出的最后一行是提示符,它表明
psql
正在监听您,并且您可以在
psql
维护的工作空间中键入SQL查询。试试这些命令: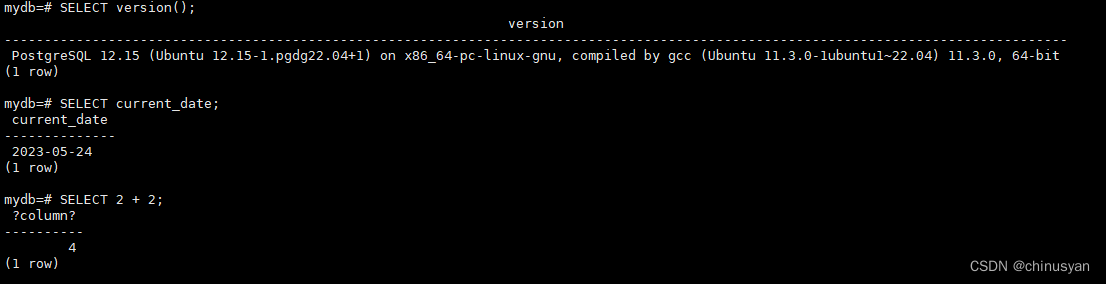
psql程序有许多不是SQL命令的内部命令。它们以反斜杠字符“
\
”开头。例如,你可以通过输入以下命令获得各种PostgreSQL SQL命令的语法帮助:
mydb=>\h
要退出
psql
,输入:
mydb=>\q
psql
将退出并返回到命令shell。(更多内部命令,键在PSQL提示符下入
\?
)在psql中记录了
psql
的全部功能。在本教程中,我们不会显式地使用这些特性,但是您可以在有帮助的时候自己使用它们。
2、SQL语言
2.1 介绍
本章概述如何使用SQL执行简单的操作。本教程只是为了给您一个介绍,并不是关于SQL的完整教程。有很多关于SQL的书,包括[melt93]和[date97]。您应该知道,一些PostgreSQL语言特性是对标准的扩展。
在下面的示例中,我们假设您已经创建了一个名为
mydb
的数据库,如前一章所述,并且已经能够启动psql。
本手册中的示例也可以在PostgreSQL的源代码分发目录
src/tutorial/
中找到。(PostgreSQL的二进制发行版可能不提供这些文件。)要使用这些文件,首先要切换到该目录并运行make:
$ cd.../src/tutorial
$ make
这将创建脚本并编译包含用户定义函数和类型的C文件。然后,要开始教程,请执行以下操作:
$ psql -s mydb
...
mydb=>\i /home/ubuntu/postgresql-12.15/src/tutorial/basics.sql
\i
命令从指定的文件中读取命令。
psql
的
-s
选项将您置于单步模式,在将每个语句发送到服务器之前暂停。本节中使用的命令在
basics.sql
文件中。
2.2 概念
**PostgreSQL是一个关系数据库管理系统(RDBMS)**。这意味着它是一个用于管理以关系(
relations
)存储的数据的系统。**
关系
本质上是表(
table
)的数学术语。如今,在表中存储数据的概念非常普遍,似乎是显而易见的,但是还有许多其他组织数据库的方法**。类unix操作系统上的文件和目录构成了分层数据库的一个例子。更现代的发展是面向对象的数据库。
每个表都是一个命名的行(
rows
)集合。给定表的每一行都有一组相同的命名列,每一列(
columns
)都有一个特定的数据类型。尽管列在每行中都有固定的顺序,但重要的是要记住,SQL并不以任何方式保证表中行的顺序(尽管可以显式地对它们进行排序以便显示)。
表被分组到数据库中,由单个PostgreSQL服务器实例管理的数据库集合构成数据库集群。
2.3 创建新表
您可以通过指定表名,以及所有列名和它们的类型来创建一个新表:
CREATETABLE weather (
city varchar(80),
temp_lo int,-- low temperature
temp_hi int,-- high temperature
prcp real,-- precipitationdatedate);
您可以使用换行符将其输入到
psql
中。
psql
将识别到直到分号才结束命令。
空白(即空格、制表符和换行符)可以在SQL命令中自由使用。这意味着您可以键入与上述命令对齐方式不同的命令,甚至可以在一行中键入所有命令。**两个破折号(“
--
”)表示注释。它们后面的内容将被忽略,直到行尾。
SQL对关键字和标识符不区分大小写
,除非标识符被双引号(double-quoted)括起来以保持大小写(上面没有这样做)**。
varchar(80)
指定了一种数据类型,可以存储长度不超过80个字符的任意字符串。
int
是普通的整数类型。
real
是用于存储单精度浮点数的类型。
date
应该不言自明。(是的,
date
类型的列也被命名为
date
。这可能是方便的,也可能是令人困惑的——你选择。)
**PostgreSQL支持标准的SQL类型
int
、
smallint
、
real
、
double precision
、
char(N)
、
varchar(N)
、
date
、
time
、
timestamp
和
interval
,以及其他类型的通用实用程序和丰富的几何类型集。PostgreSQL可以使用任意数量的用户定义数据类型进行定制。因此,类型名在语法中不是关键字,除非需要在SQL标准中支持特殊情况。**
第二个例子将存储城市及其相关的地理位置:
CREATETABLE cities (
name varchar(80),
location point);
point
类型是postgresql特定数据类型的一个例子。
最后,应该提到的是,如果你不再需要一个表,或者想要以不同的方式重新创建它,你可以使用以下命令删除它:
DROPTABLE tablename;
2.4 用行填充表
INSERT
语句用于向表中填充行:
INSERTINTO weather VALUES('San Francisco',46,50,0.25,'1994-11-27');
请注意,所有数据类型都使用相当明显的输入格式。**非简单数值的常量通常必须用单引号(
'
)括起来**,如示例中所示。
date
类型接受的内容实际上非常灵活,但在本教程中,我们将坚持使用这里所示的明确格式。
point
类型需要一个坐标对作为输入,如下所示:
INSERTINTO cities VALUES('San Francisco','(-194.0, 53.0)');
到目前为止使用的语法要求您记住列的顺序。另一种语法允许您显式列出列:
INSERTINTO weather (city, temp_lo, temp_hi, prcp,date)VALUES('San Francisco',43,57,0.0,'1994-11-29');
如果您愿意,您可以以不同的顺序列出这些列,甚至可以省略一些列,例如,如果降水未知:
INSERT INTO weather (date, city, temp_hi, temp_lo)
VALUES ('1994-11-29', 'Hayward', 54, 37);
许多开发人员认为显式列出列比隐式地依赖顺序更好。
请输入上面显示的所有命令,以便在接下来的部分中使用一些数据。
您还可以使用
COPY
从纯文本文件加载大量数据。这通常更快,因为
COPY
命令针对此应用程序进行了优化,但灵活性低于
INSERT
。一个例子是:
COPY weather FROM '/home/user/weather.txt';
源文件的文件名必须在运行后端进程的机器上可用,而不是在客户机上可用,因为后端进程直接读取文件。您可以在COPY中了解更多关于
COPY
命令的信息。
2.5 查询表
要从表中检索数据,表是必须的。使用SQL
SELECT
语句来执行此操作。**该语句被分为选择列表(列出要返回的列的部分)、表列表(列出要从中检索数据的表的部分)和可选限定(指定任何限制的部分)**。例如,要检索表weather的所有行,输入:
SELECT*FROM weather;
这里
*
是“所有列”的简写。[2]所以,同样的结果也适用于:
(虽然
SELECT *
对于即兴查询很有用,但它在生产代码中被普遍认为是不好的样式,因为向表中添加一列会改变结果。)
SELECT city, temp_lo, temp_hi, prcp,dateFROM weather;
city | temp_lo | temp_hi | prcp |date
---------------+---------+---------+------+------------
San Francisco |46|50|0.25|1994-11-27
San Francisco |43|57|0|1994-11-29
Hayward |37|54||1994-11-29
(3 rows)
您可以在选择列表中编写表达式,而不仅仅是简单的列引用。例如,你可以这样做:
SELECT city,(temp_hi+temp_lo)/2AS temp_avg,dateFROM weather;
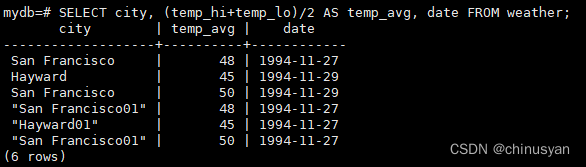
**请注意如何使用
AS
子句来重新标记输出列**。(
AS
从句是可选的。)
**可以通过添加
WHERE
子句来“限定(
qualified
)”查询,该子句指定需要哪些行。
WHERE
子句包含一个布尔(真值)表达式,并且只返回布尔表达式为真的行。通常的布尔运算符(
AND
、
OR
和
NOT
)在限定中是允许的**。例如,下面检索旧金山在雨天的天气:
SELECT*FROM weather
WHERE city ='San Francisco'AND prcp >0.0;

你可以请求一个查询的结果按排序顺序返回:
SELECT*FROM weather
ORDERBY city;
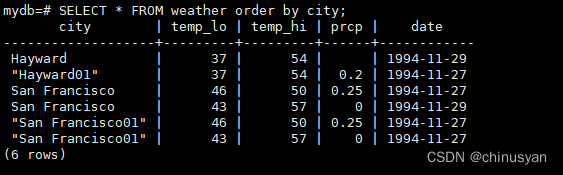
在本例中,没有完全指定排序顺序,因此您可能以任意一种顺序得到旧金山的行。但如果你这样做,你总是会得到如上所示的结果:
SELECT*FROM weather
ORDERBY city, temp_lo;
你可以请求从查询结果中删除重复的行:
SELECTDISTINCT city
FROM weather;
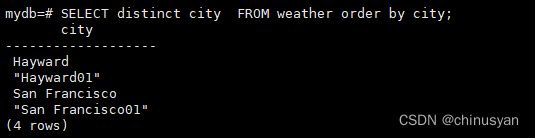
这里,结果行顺序可能会有所不同。你可以通过同时使用
DISTINCT
和
ORDER BY
来确保结果的一致性:[3](在一些数据库系统中,包括旧版本的PostgreSQL, DISTINCT的实现会自动对行排序,因此ORDER BY是不必要的。但是这不是SQL标准所要求的,并且当前的PostgreSQL不能保证DISTINCT会导致行排序。)
SELECTDISTINCT city
FROM weather
ORDERBY city;
2.6 表间连接
到目前为止,我们的查询一次只访问了一个表。查询可以一次访问多个表,或者以同时处理表的多行的方式访问同一个表。一次访问相同或不同表的多行查询称为连接查询(join query)。例如,假设您希望列出所有天气记录以及相关城市的位置。为此,我们需要比较
weather
表中每行的
city
列与
cities
表中所有行的
name
列,并选择这些值匹配的行对。
这只是一个概念模型。连接通常以比实际比较每个可能的行对更有效的方式执行,但这对用户是不可见的。
这将通过以下查询完成:
SELECT*FROM weather, cities
WHERE city = name;

观察结果集的两件事:
- 海沃德市目前还没有结果。这是因为在
cities表中没有与Hayward匹配的条目,因此连接忽略了weather表中不匹配的行。我们将很快看到如何解决这个问题。 - 有两列包含城市名称。这是正确的,因为来自
weather和cities表的列是连接在一起的。但在实践中,这是不可取的,因此您可能希望显式列出输出列,而不是使用*:
SELECT city, temp_lo, temp_hi, prcp,date, location
FROM weather, cities
WHERE city = name;
练习:当省略WHERE子句时,尝试确定该查询的语义。
由于列都有不同的名称,解析器会自动发现它们属于哪个表。如果两个表中有重复的列名,您需要限定(qualify )列名以显示您指的是哪个,如下所示:
SELECT weather.city, weather.temp_lo, weather.temp_hi,
weather.prcp, weather.date, cities.location
FROM weather, cities
WHERE cities.name = weather.city;
人们普遍认为,在连接查询中限定所有列名是一种很好的样式,这样,如果稍后将重复的列名添加到其中一个表中,查询就不会失败。
到目前为止,我们看到的联接查询也可以用这种形式编写:
SELECT*FROM weather INNERJOIN cities ON(weather.city = cities.name);
这种语法并不像上面的语法那样常用,但是我们在这里展示它是为了帮助您理解以下主题。
现在我们要想办法把海沃德(Hayward )的记录拿回来。我们希望查询做的是扫描
weather
表,并为每一行查找匹配的
cities
行。如果没有找到匹配的行,我们希望用一些“空值”替换城市表的列。这种查询称为外部连接(
outer join
)。(到目前为止,我们看到的连接都是内连接。)命令看起来像这样:
SELECT*FROM weather LEFTOUTERJOIN cities ON(weather.city = cities.name);

这个查询被称为左外连接(
left outer join
),因为连接操作符左侧提到的表的每一行至少会在输出中出现一次,而右侧的表只会输出与左表的某些行匹配的行。当输出没有与右表匹配的左表行时,将用空(null)值替换右表列。
练习:也有右外连接(right outer joins )和全外连接( full outer joins)。试着找出它们的作用。
**我们也可以将一个表与它本身对立起来。这被称为自连接(
self join
)**。例如,假设我们希望找到在其他天气记录温度范围的所有天气记录。因此,我们需要将每个
weather
行的temp_lo和temp_hi列与所有其他
weather
行的temp_lo和temp_hi列进行比较。我们可以用下面的查询来做到这一点:
SELECT W1.city, W1.temp_lo AS low, W1.temp_hi AS high,
W2.city, W2.temp_lo AS low, W2.temp_hi AS high
FROM weather W1, weather W2
WHERE W1.temp_lo < W2.temp_lo
AND W1.temp_hi > W2.temp_hi;
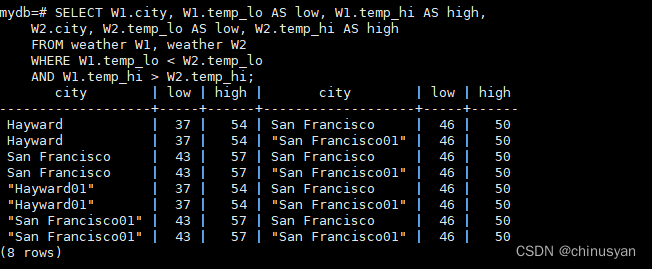
这里我们将天气表重新标记为
W1
和
W2
,以便能够区分连接的左侧和右侧。你也可以在其他查询中使用这些类型的别名来节省一些输入,例如:
SELECT*FROM weather w, cities c
WHERE w.city = c.name;
你会经常遇到这种缩写形式。
2.7 聚合函数
像大多数其他关系数据库产品一样,PostgreSQL支持聚合函数(
aggregate functions
)。聚合函数从多个输入行计算单个结果。例如,存在用于计算一组行的count、sum、avg(平均值)、max(最大值)和min(最小值)的聚合。
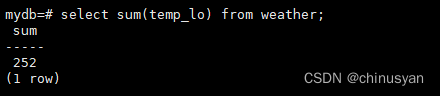
SELECTmax(temp_lo)FROM weather;
如果我们想知道最大的低温发生在哪个城市(或几个城市),我们可以试试:
SELECT city FROM weather WHERE temp_lo =max(temp_lo);# WRONG
但这将不起作用,因为聚合
max
不能在
WHERE
子句中使用。(这个限制的存在是因为
WHERE
子句决定哪些行将包含在聚合计算中;所以很明显,它必须在计算聚合函数之前进行评估。)然而,通常情况下,可以通过使用子查询(subquery)来再写查询以实现期望的结果:
SELECT city FROM weather
WHERE temp_lo =(SELECTmax(temp_lo)FROM weather);
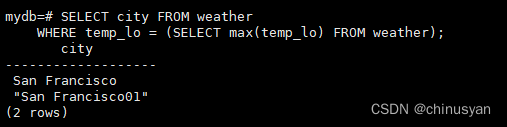
这是可以的,因为子查询是一个独立的计算,它与外部查询中发生的事情分开计算自己的聚合。
在与
GROUP BY
子句结合使用时,聚合也非常有用。例如,我们可以得到每个城市观测到的数量和最高低温:
SELECT city,count(*),max(temp_lo)FROM weather
GROUPBY city;
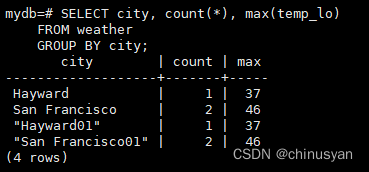
每个城市有一个输出行。每个聚合结果都是在匹配该城市的表行上计算的。我们可以使用
HAVING
过滤这些分组行:
SELECT city,count(*),max(temp_lo)FROM weather
GROUPBY city
HAVINGmax(temp_lo)<40;
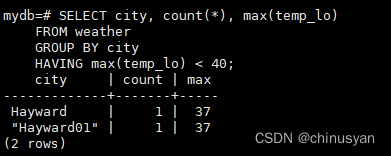
这只会为所有
temp_lo
值低于40的城市提供相同的结果。最后,如果我们只关心名字以“
S
”开头的城市,我们可能会这样做:
SELECT city,count(*),max(temp_lo)FROM weather
WHERE city LIKE'S%'-- (1)GROUPBY city;
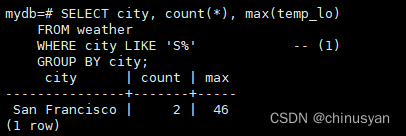
LIKE操作符进行模式匹配,将在第9.7节中解释。
**理解聚合和SQL的
WHERE
和
HAVING
子句之间的交互是很重要的。
WHERE
和
HAVING
之间的根本区别在于:
WHERE
在分组和聚合计算之前选择输入行(因此,它控制哪些行进入聚合计算),而
HAVING
在分组和聚合计算之后选择被分组后行(group rows)。因此,
WHERE子
句不能包含聚合函数;尝试使用聚合来确定哪些行将作为聚合的输入是没有意义的。另一方面,
HAVING
子句总是包含聚合函数**。(严格地说,你可以写一个不使用聚合的
HAVING
子句,但它很少有用。**在
WHERE
阶段可以更有效地使用相同的条件。**)
在前面的示例中,我们可以在
WHERE
中应用城市名称限制,因为它不需要聚合。这比在
HAVING
中添加限制更有效,因为我们避免了对所有没有通过
WHERE
检查的行进行分组和聚合计算。
**选择进入聚合计算的行的另一种方法是使用
FILTER
,这是一个per-aggregate 选项:**
SELECT city,count(*) FILTER (WHERE temp_lo <45),max(temp_lo)FROM weather
GROUPBY city;

**
FILTER
与
WHERE
非常相似,不同之处在于它只从它所附加的特定聚合函数的输入中删除行。这里,count**聚合只计算
temp_lo
低于45的行;但是max 聚合仍然应用于所有行,因此它仍然发现读数为46。
2.8 更新
可以使用
UPDATE
命令更新现有行。假设你发现11月28日之后的温度读数都差了2度。您可以对数据进行如下更正:
UPDATE weather
SET temp_hi = temp_hi -2, temp_lo = temp_lo -2WHEREdate>'1994-11-28';
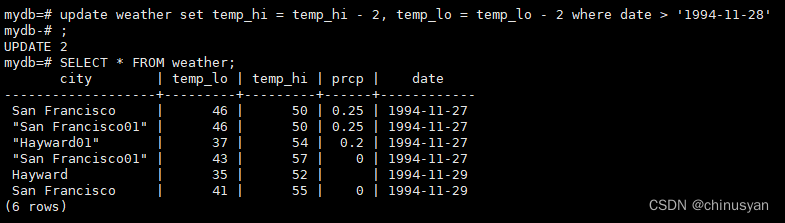
2.9 删除
可以使用
DELETE
命令从表中删除行。假如你对海沃德(Hayward)的天气不再感兴趣。然后,您可以执行以下操作从表中删除这些行:
DELETEFROM weather WHERE city ='Hayward';
海沃德的所有天气记录都被删除了。
SELECT*FROM weather;

人们应该警惕这种形式的语句:
DELETEFROM tablename;
**如果没有限定条件,
DELETE
将从给定表中删除所有行,使其为空。在此之前,系统不会请求确认!**
3、高级特性
3.1 介绍
在前一章中,我们已经介绍了在PostgreSQL中使用SQL存储和访问数据的基础知识。现在我们将讨论SQL的一些更高级的特性,它们可以简化管理并防止数据丢失或损坏。最后,我们将看看一些PostgreSQL扩展。
本章有时会引用第2章中的例子来修改或改进它们,所以读过第2章会很有用。本章中的一些例子也可以在前面教程目录中的
advanced.sql
找到。该文件还包含一些要加载的示例数据,这里不再重复。(关于如何使用该文件,请参阅2.1节。)
3.2 视图(Views)
请参考2.6节中的查询。假设您的应用程序对天气记录和城市位置的组合列表特别感兴趣,但是您不希望每次需要时都键入查询。**您可以在查询上创建一个
视图
( view),该视图为查询提供一个名称,您可以像引用普通表一样引用该查询**:
CREATEVIEW myview ASSELECT name, temp_lo, temp_hi, prcp,date, location
FROM weather, cities
WHERE city = name;SELECT*FROM myview;
自由使用视图是良好SQL数据库设计的一个关键方面。视图允许您将表结构的细节封装在一致的接口后面,这些细节可能会随着应用程序的发展而改变。
视图几乎可以在任何可以使用真实表的地方使用。在其他视图上构建视图并不罕见。
3.3 外键 (Foreign Keys)
回想一下第2章中的
weather
和
cities
表。考虑以下问题:您希望确保没有人可以在
weather
表中插入在
cities
表中没有匹配条目的行。这被称为维护数据的引用完整性(
referential integrity
)。在简单的数据库系统中,这将首先通过查看
cities
表来检查是否存在匹配的记录,然后插入或拒绝新的
weather
记录来实现(如果有的话)。这种方法有很多问题,而且非常不方便,所以PostgreSQL可以为你做到这一点。
表的新声明看起来像这样:
CREATETABLE cities (
name varchar(80)primarykey,
location point);CREATETABLE weather (
city varchar(80)references cities(name),
temp_lo int,
temp_hi int,
prcp real,datedate);
现在尝试插入一个无效的记录:
INSERTINTO weather VALUES('Berkeley',45,53,0.0,'1994-11-28');
ERROR: insert or update on table "weather" violates foreign key constraint "weather_city_fkey"
DETAIL: Key (city)=(Berkeley) is not present in table "cities".
外键的行为可以根据您的应用程序进行微调。在本教程中,我们不会超越这个简单的例子,但请参考第5章了解更多信息。正确使用外键肯定会提高数据库应用程序的质量,因此强烈建议您学习外键。
3.4 事务
事务(
Transactions
)是所有数据库系统的基本概念。事务的要点是,它将多个步骤捆绑到一个全有或全无的操作中。这些步骤之间的中间状态对于其他并发事务是不可见的,如果发生了一些阻止事务完成的故障,那么这些步骤都不会影响数据库。
例如,考虑一个银行数据库,它包含各种客户帐户的余额,以及分支机构的总存款余额。假设我们想记录从Alice的账户支付100美元到Bob的账户。简化得令人难以置信,它的SQL命令可能看起来像这样:
UPDATE accounts SET balance = balance -100.00WHERE name ='Alice';UPDATE branches SET balance = balance -100.00WHERE name =(SELECT branch_name FROM accounts WHERE name ='Alice');UPDATE accounts SET balance = balance +100.00WHERE name ='Bob';UPDATE branches SET balance = balance +100.00WHERE name =(SELECT branch_name FROM accounts WHERE name ='Bob');
这些命令的细节在这里并不重要;重要的一点是,要完成这个相当简单的操作,需要几个单独的更新。我们银行的官员希望得到保证,要么所有这些更新都发生,要么都不发生。如果系统故障导致Bob收到没有从Alice借记的100美元,那肯定不行。如果Alice被借记而Bob没有被贷记,那么她也不会长期保持一个快乐的客户。我们需要保证,如果在操作过程中出现问题,到目前为止执行的所有步骤都不会生效。将更新分组到事务中为我们提供了这种保证。一个事务被称为原子性的(atomic):从其他事务的角度来看,它要么完全发生,要么根本不发生。
我们还希望保证,一旦事务完成并被数据库系统确认,它确实已被永久记录,即使此后不久发生崩溃也不会丢失。例如,如果我们正在记录Bob的现金提取,我们不希望他的账户上的借方在他走出银行大门后突然消失。事务数据库保证在事务报告完成之前,事务所做的所有更新都记录在永久存储中(即磁盘上)。
**事务性数据库的另一个重要属性与原子更新的概念密切相关:
当多个事务并发运行时,每个事务都不应该能够看到其他事务所做的不完整更改
。例如,如果一个交易忙于计算所有的分支余额,那么它就不能包括Alice分支的借方,而不包括Bob分支的贷方,反之亦然。因此,事务必须要么全有,要么全无,这不仅取决于它们对数据库的永久影响,还取决于它们发生时的可见性**。到目前为止,开放事务所做的更新对其他事务是不可见的,直到事务完成,然后所有更新同时可见。
在
PostgreSQL
中,事务是通过在事务的SQL命令周围加上
BEGIN
和
COMMIT
命令来建立的。所以我们的银行交易实际上是这样的:
BEGIN;UPDATE accounts SET balance = balance -100.00WHERE name ='Alice';-- etc etc
COMMIT;
如果在事务进行到一半时,我们决定不提交(也许我们只是注意到Alice的余额变为负数),我们可以发出
ROLLBACK
命令而不是
COMMIT
,到目前为止我们所有的更新都将被取消。
**
PostgreSQL
实际上将每个SQL语句视为在事务中执行**。如果不发出BEGIN命令,那么每个单独的语句都有一个隐式的
BEGIN
和
COMMIT
(如果成功的话)。由
BEGIN
和
COMMIT
包围的一组语句有时称为事务块(
transaction block
)。
有些客户端库会自动发出
BEGIN和
COMMIT命令,因此您可能无需询问即可获得事务块的效果。检查您正在使用的接口的文档。
通过使用保存点(
savepoints
),可以以更细粒度的方式控制事务中的语句。
保存点允许您选择性地放弃事务的部分,同时提交其余部分
。**在使用
SAVEPOINT
定义保存点之后,如果需要,可以使用
ROLLBACK TO
回滚到保存点。在定义保存点和回滚到它之间的所有事务的数据库更改将被丢弃,但保留早于保存点的更改。**
回滚到保存点后,它将继续被定义,因此您可以多次回滚到它。相反,如果您确定不需要再次回滚到特定的保存点,则可以释放它,这样系统就可以释放一些资源。请记住,释放或回滚到保存点都将自动释放在该保存点之后定义的所有保存点。
所有这些都发生在事务块中,因此对其他数据库会话都不可见。当您提交事务块时,所提交的操作将作为一个单元对其他会话可见,而回滚操作则永远不可见。
记住银行数据库,假设我们从Alice的账户中借了100美元,并贷记了Bob的账户,后来才发现我们应该贷记了Wally的账户。我们可以使用如下保存点:
BEGIN;UPDATE accounts SET balance = balance -100.00WHERE name ='Alice';SAVEPOINT my_savepoint;UPDATE accounts SET balance = balance +100.00WHERE name ='Bob';-- oops ... forget that and use Wally's account
ROLLBACKTO my_savepoint;UPDATE accounts SET balance = balance +100.00WHERE name ='Wally';COMMIT;
当然,这个例子过于简化了,但是通过使用保存点,在事务块中有很多可能的控制。此外,**
ROLLBACK TO
是恢复对由于错误而被系统置于中止状态的事务块的控制的唯一方法**,除非将其完全回滚并重新开始。
3.5 窗口函数
**窗口函数(
window function
)跨一组与当前行有某种关联的表的行执行计算。这与可以使用聚合函数完成的计算类型相当。但是,窗口函数不会像非窗口聚合调用那样将行分组为单个输出行。相反,这些行保留各自的标识**。
在后台,窗口函数能够访问的不仅仅是查询结果的当前行
。
下面是一个例子,展示了如何比较每个员工的工资和他或她所在部门的平均工资:
SELECT depname, empno, salary,avg(salary)OVER(PARTITIONBY depname)FROM empsalary;
depname | empno | salary | avg
-----------+-------+--------+-----------------------
develop |11|5200|5020.0000000000000000
develop |7|4200|5020.0000000000000000
develop |9|4500|5020.0000000000000000
develop |8|6000|5020.0000000000000000
develop |10|5200|5020.0000000000000000
personnel |5|3500|3700.0000000000000000
personnel |2|3900|3700.0000000000000000
sales |3|4800|4866.6666666666666667
sales |1|5000|4866.6666666666666667
sales |4|4800|4866.6666666666666667(10 rows)
前三个输出列直接来自表
empsalary
,表中的每一行对应一个输出行。第四列表示与当前行具有相同
depname
值的所有表行的平均值。(这实际上是与非窗口
avg
聚合相同的函数,但
OVER
子句导致它被视为窗口函数并跨窗口框架计算。)
**窗口函数调用总是包含一个
OVER
子句,紧跟在窗口函数的名称和参数之后。这就是它在语法上区别于普通函数或非窗口聚合的地方。
OVER
子句准确地决定如何分割查询的行,以便由窗口函数进行处理。
OVER
中的
PARTITION BY
子句将行划分为组或分区,这些组或分区共享
PARTITION BY
表达式的相同值。对于每一行,窗口函数是在与当前行属于同一分区的行之间计算的。**
您还可以使用
OVER
中的
ORDER BY
来控制窗口函数处理行的顺序。(窗口
ORDER BY
甚至不必匹配输出行的顺序。)下面是一个例子:
SELECT depname, empno, salary,
rank()OVER(PARTITIONBY depname ORDERBY salary DESC)FROM empsalary;
depname | empno | salary | rank
-----------+-------+--------+------
develop |8|6000|1
develop |10|5200|2
develop |11|5200|2
develop |9|4500|4
develop |7|4200|5
personnel |2|3900|1
personnel |5|3500|2
sales |1|5000|1
sales |4|4800|2
sales |3|4800|2(10rows)
如图所示,**
rank
函数使用
ORDER BY
子句定义的顺序,为当前行的分区中的每个不同的
ORDER BY
值生成一个数字排名**。
rank
不需要显式参数,因为它的行为完全由
OVER
子句决定。
**窗口函数考虑的行是由查询的
FROM
子句过滤的
WHERE
、
GROUP BY
和
HAVING
子句(如果有的话)生成的“虚拟表”。例如,由于不满足WHERE条件而删除的行不会被任何窗口函数看到。查询可以包含多个窗口函数,这些窗口函数使用不同的
OVER
子句以不同的方式分割数据,但它们都作用于这个虚拟表定义的同一行集合。**
**我们已经看到,如果行排序不重要,可以省略
ORDER BY
。也可以省略
PARTITION BY
,在这种情况下,只有一个包含所有行的分区。**
与窗口函数相关的另一个重要概念是:对于每一行,在其分区内都有一组行,称为其窗框**(
window frame
)**。
一些窗函数只作用于窗框的行,而不是整个分区
。默认情况下,如果提供了
ORDER BY
,则框架由从分区开始到当前行的所有行组成,加上根据
ORDER BY
子句与当前行相等的任何后续行。如果省略
ORDER BY
,则默认窗框包含分区中的所有行。(还有其他方式定义窗口框架的选项,但本教程不介绍它们。详细信息请参见4.2.8节。)下面是一个使用sum的例子:
SELECT salary,sum(salary)OVER()FROM empsalary;
salary | sum
--------+-------5200|471005000|471003500|471004800|471003900|471004200|471004500|471004800|471006000|471005200|47100(10rows)
上面,由于
OVER
子句中没有
ORDER BY
,因此窗口框架与分区相同,由于没有
PARTITION BY
,分区就是整个表;换句话说,每个和都占用整个表,因此我们对每个输出行都得到相同的结果。但是如果我们添加一个
ORDER BY
子句,我们会得到非常不同的结果:
SELECT salary,sum(salary)OVER(ORDERBY salary)FROM empsalary;
salary | sum
--------+-------3500|35003900|74004200|116004500|161004800|257004800|257005000|307005200|411005200|411006000|47100(10rows)
这里的总和是从第一个(最低)工资到当前工资,包括当前工资的任何重复(注意重复工资的结果)。
**窗口函数只允许在查询的
SELECT
列表和
ORDER BY
子句中使用。它们在其他地方是被禁止的,比如
GROUP BY
、
HAVING
和
WHERE
子句。
这是因为它们在逻辑上是在处理那些子句之后执行的。此外,窗口函数在非窗口聚合函数之后执行
。这意味着在窗口函数的参数中包含聚合函数调用是有效的,反之则不然。**
如果需要在执行窗口计算后对行进行筛选或分组,则可以使用子查询。例如:
SELECT depname, empno, salary, enroll_date
FROM(SELECT depname, empno, salary, enroll_date,
rank()OVER(PARTITIONBY depname ORDERBY salary DESC, empno)AS pos
FROM empsalary
)AS ss
WHERE pos <3;
上面的查询只显示内部查询中排名小于3的行。
当查询涉及多个窗口函数时,可以使用单独的
OVER
子句写出每个窗口函数,但是如果多个函数需要相同的窗口行为,那么这是重复的并且容易出错。相反,每个窗口行为都可以在
WINDOW
子句中命名,然后在
OVER
中引用。例如:
SELECTsum(salary)OVER w,avg(salary)OVER w
FROM empsalary
WINDOW w AS(PARTITIONBY depname ORDERBY salary DESC);
关于窗口函数的更多细节可以在4.2.8节,9.21节,7.2.5节和SELECT参考页中找到。
3.6 继承
继承(
Inheritance
)是一个来自面向对象数据库的概念。它为数据库设计开辟了有趣的新可能性。
让我们创建两个表:一个
cities
城市和一个
capitals
首都。当然,首都也是城市,所以在列出所有城市时,您希望以某种方式隐式地显示首都。如果你真的很聪明,你可能会发明一些这样的计划:
CREATETABLE capitals (
name text,
population real,
elevation int,-- (in ft)
state char(2));CREATETABLE non_capitals (
name text,
population real,
elevation int-- (in ft));CREATEVIEW cities ASSELECT name, population, elevation FROM capitals
UNIONSELECT name, population, elevation FROM non_capitals;
就查询而言,这是可以工作的,但是当您需要更新几行时,它就变得很难看了。
一个更好的解决方案是:
CREATETABLE cities (
name text,
population real,
elevation int-- (in ft));CREATETABLE capitals (
state char(2)UNIQUENOTNULL) INHERITS (cities);
在本例中,
capitals
从其父
cities
继承所有列(
name, population, and elevation
)。
name
列的类型是
text
,这是一种用于可变长度字符串的本地PostgreSQL类型。
capitals
表有一个额外的列
state
,显示其州的缩写。在PostgreSQL中,一个表可以从零或多个其他表继承。
例如,下面的查询查找海拔超过500英尺的所有城市(包括州首府)的名称:
SELECT name, elevation
FROM cities
WHERE elevation >500;
它返回:
name | elevation
-----------+-----------
Las Vegas |2174
Mariposa |1953
Madison |845(3 rows)
另一方面,下面的查询查找所有非州首府且海拔超过500英尺的城市:
SELECT name, elevation
FROM ONLY cities
WHERE elevation >500;
name | elevation
-----------+-----------
Las Vegas |2174
Mariposa |1953(2 rows)
这里,
cities
前面的
ONLY
表示查询应该只在
cities
表上运行,而不是在继承层次结构中低于
cities
的表上运行。我们已经讨论过的许多命令——
SELECT
、
UPDATE
和
DELETE
——都支持这种
ONLY
表示法。
尽管继承通常很有用,但它没有与唯一约束或外键集成,这限制了它的有用性。参见5.10节了解更多细节。
3.7 总结
PostgreSQL有许多在本教程介绍中没有涉及的特性,它是面向SQL的新用户的。这些特性将在本书的其余部分进行更详细的讨论。
如果您觉得需要更多的介绍性材料,请访问PostgreSQL网站获取更多资源的链接。
版权归原作者 chinusyan 所有, 如有侵权,请联系我们删除。