
Spark分布式集群搭建
这里的Spark分布式集群是以我上一篇文章发的Hadoop分布式集群为基础搭建的,都是在UbuntuKylin系统中搭建的。过几天发Centos上的分布式集群搭建。
一、集群规划
Spark集群以三台电脑搭建,Spark集群以Hadoop集群为基础搭建,虚拟机主机名分别为hadoop101、hadoop111和hadoop121。IP地址分别为192.168.43.101、192.168.43.111和192.168.43.121。
Spark分布式集群的安装环境,需要事先配置好Hadoop的分布式集群环境。这里采用3台虚拟机来搭建Spark集群,其中1台虚拟机,主机名为hadoop101,作为master节点和worker节点,另外两台虚拟机作为worker节点(即作为Worker节点),主机名分别为hadoop111和hadoop121。
Spark集群规划:
hadoop101:master worker;
hadoop111:worker;
hadoop121:worker;
二、安装Spark
2.1.解压Spark安装包
首先下载
spark-2.1.0-bin-without-hadoop.tgz
,保存到本地的
“~/Downloads”
目录下,然后在终端执行命令解压缩,并修改spark权限。
sudo tar -zxf ~/Downloads/spark-2.1.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local
sudo mv ./spark-2.1.0-bin-without-hadoop ./spark
sudo chown -R hadoop:hadoop ./spark
2.2.配置环境变量
在master节点主机的终端中执行如下命令:
vim ~/.bashrc
在.bashrc添加如下配置:
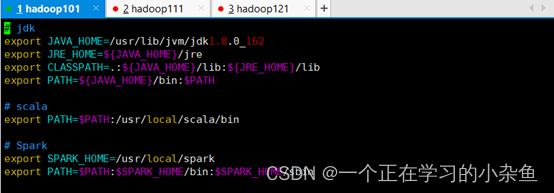
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
执行一下命令是配置立即生效:
source ~/.bashrc
三、配置Spark
在master节点主机上进行如下操作:
3.1.slave文件
配置
slaves
文件
将slaves.template 拷贝到slaves。
cd /usr/local/spark/
cp ./conf/slaves.template ./conf/slaves
slaves文件设置worker节点。编辑slaves内容,把默认内容localhost替换成如下内容:
hadoop101
hadoop111
hadoop121

3.2. spark-env.sh文件
配置spark-env.sh文件
将
spark-env.sh.template
拷贝到
spark-env.sh
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
编辑spark-env.sh,添加如下内容:
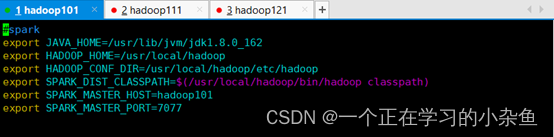
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/Hadoop classpath)
export SPARK_MASTER_HOST=hadoop101
export SPARK_MASTER_PORT=7077
3.3. spark-defaults.conf文件
修改spark-defaults.conf文件,添加如下内容:
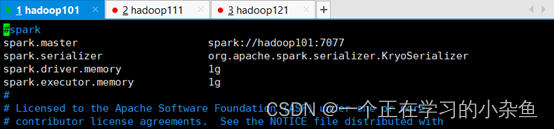
spark.master spark://hadoop101:7077
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 1g
spark.executor.memory 1g
3.4.分发
将spark目录分发到其他节点
scp -r ./usr/local/spark hadoop111:/usr/local/
scp -r ./usr/local/spark hadoop121:/usr/local/
四、启动Spark
4.1.启动spark
启动Spark集群前,要先启动
Hadoop集群
。在master节点主机上运行如下命令:
cd /usr/local/hadoop/
sbin/start-all.sh
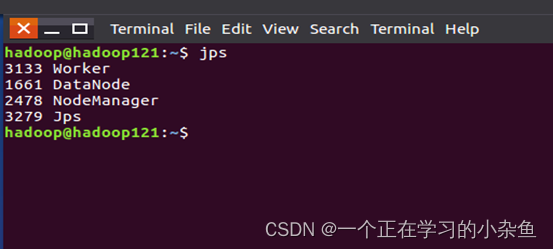
在master和worker节点通过命令jps可以看到进程启动。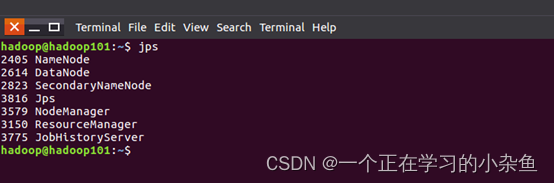
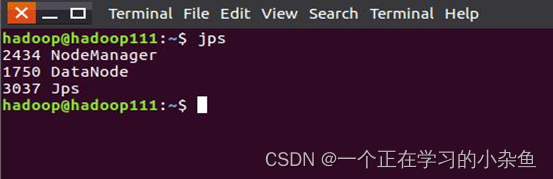
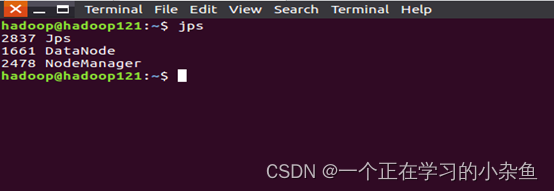
在
master
节点主机上运行如下命令启动spark集群:
cd /usr/local/spark/
sbin/start-all.sh
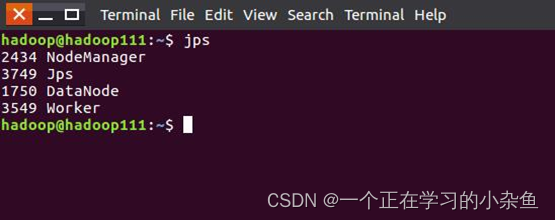
在
master
和
worker
节点通过命令jps可以看到进程启动。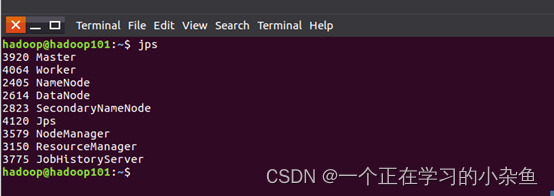
4.2.通过web端查看
启动hadoop分布式集群和spark分布式集群之后,我们可以通过web端来查看后台页面。
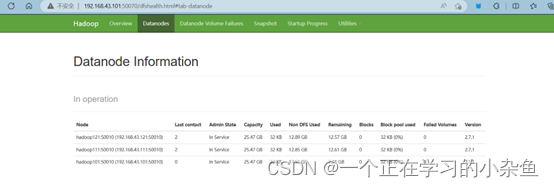
我们可以在浏览器上查看HDFS界面
HDFS:http://192.168.43.101:50070/
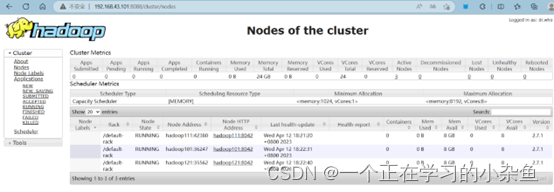
我们可以在浏览器上查看YARN界面
YARN:http://192.168.43.101:8088/
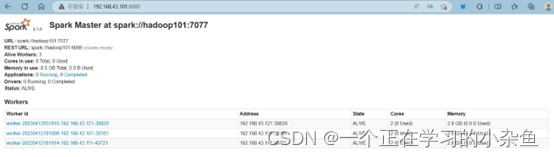
我们可以在浏览器上查看Spark界面
Spark:http://192.168.43.101:8080/
4.3.spark分布式集群验证
spark分布式集群启动成功之后,可以通过向服务器提交任务来检查是否spark是否存在问题。
在hadoop和spark启动的状态下,在终端运行一下命令:
./bin/spark-submit \
--master spark://hadoop101:7077 \
examples/src/main/python/ pi.py
向服务器提交运算pi值的任务。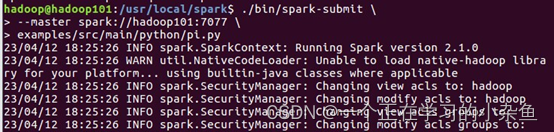
版权归原作者 一个正在学习的小杂鱼 所有, 如有侵权,请联系我们删除。