
zookeeper选举详解
一,zookeeper选举原理
1,源码下载
在这个https://github.com/apache/zookeeper里面把源码下载即可,这里推荐版本为3.5.8
源码下载完成之后,在这个zookeeper-server的模块下面,在version包下面新建一个info的接口
其内容如下,如果会有编译报错就加入这个接口,没有的话也可以不加。
publicinterfaceInfo{int MAJOR =1;int MINOR =0;int MICRO =0;String QUALIFIER =null;int REVISION =-1;String REVISION_HASH ="1";String BUILD_DATE ="2022‐09‐03";}
2,zookeeper集群选举流程
2.1,zookeeper集群启动以及配置加载
1,由于这个zookeeper的启动是通过一个./zkServer.sh的脚本实现整个服务的启动的,因此可以发现脚本里面主要是通过这个QuorumPeerMain 类来作为一个集群的主启动类,接下来就是主要分析一下这个类。
ZOOMAIN="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY org.apache.zookeeper.server.quorum.QuorumPeerMain"
2,在这个类里面,有一个main的入口方法
@InterfaceAudience.Publicpublicclass{publicstaticvoidmain(String[] args){QuorumPeerMain main =newQuorumPeerMain();try{
main.initializeAndRun(args);}catch(Execption e){...}}}
3,接下来就是一个重点,主要查看这个initializeAndRun的这个方法,这个方法主要会解析一下配置文件,清理一些文件
protectedvoidinitializeAndRun(String[] args)throwsConfigException,IOException,AdminServerException{QuorumPeerConfig config =newQuorumPeerConfig();//解析配置文件,主要是解析这个zoo.cfg的配置文件if(args.length ==1){
config.parse(args[0]);}//定时清理一些文件目录DatadirCleanupManager purgeMgr =newDatadirCleanupManager(config
.getDataDir(), config.getDataLogDir(), config
.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();//如果是分布式集群环境,那么走这个逻辑if(args.length ==1&& config.isDistributed()){runFromConfig(config);}//如果是单机状态,那么走这个逻辑else{ZooKeeperServerMain.main(args);}}
4,那么可以查看这个分布式环境下的方法所走的流程,主要是查看这个runFromConfig方法,主要是会创建一个nio实例或者创建一个netty的一个工厂,将一些解析的文件存储到一个QuorumPeer的对象里面
publicvoidrunFromConfig(QuorumPeerConfig config)throwsIOException,AdminServerException{try{ServerCnxnFactory cnxnFactory =null;ServerCnxnFactory secureCnxnFactory =null;if(config.getClientPortAddress()!=null){//创建nio或者netty工厂
cnxnFactory =ServerCnxnFactory.createFactory();//监听客户端的端口
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns(),false);}
quorumPeer =getQuorumPeer();//将解析出来的配置文件的值存到这个quorumPeer对象里面
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setConfigFileName(config.getConfigFilename());
quorumPeer.setZKDatabase(newZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setQuorumVerifier(config.getQuorumVerifier(),false);//属性填充之后就进行一个初始化
quorumPeer.initialize();//开启这个zookeeper的集群
quorumPeer.start();
quorumPeer.join();}}
5,接下来主要查看这个start启动方法,会将已有的数据从磁盘加载到内存里面
@Overridepublicsynchronizedvoidstart(){if(!getView().containsKey(myid)){thrownewRuntimeException("My id "+ myid +" not in the peer list");}//加载zookeeper里面已有的数据文件//比如一些快照文件,需要从磁盘加载到内存里面loadDataBase();//启动刚刚初始化的这个CNX的工厂startServerCnxnFactory();try{
adminServer.start();}catch(AdminServerException e){
LOG.warn("Problem starting AdminServer", e);System.out.println(e);}//和选举有关的算法startLeaderElection();//选举的具体实现super.start();}
6,结点的几个状态,当集群没有选举出来这个leader的时候,这个结点处于一个LOOKING状态;当主结点选举出来之后,这个主结点是LEADING状态,这个从结点是FOLLOWING状态;
publicenumServerState{
LOOKING, FOLLOWING, LEADING, OBSERVING;}
2.2,leader选举工作准备开始
7,接下来就是一个重点和这个选举主结点有关的方法startLeaderElection
synchronizedpublicvoidstartLeaderElection(){try{//观望状态if(getPeerState()==ServerState.LOOKING){//初始化一个投票对象,先给自己投一票
currentVote =newVote(myid,getLastLoggedZxid(),getCurrentEpoch());}}catch(IOException e){RuntimeException re =newRuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());throw re;}if(electionType ==0){try{
udpSocket =newDatagramSocket(getQuorumAddress().getPort());
responder =newResponderThread();
responder.start();}catch(SocketException e){thrownewRuntimeException(e);}}//快速选举的一个算法this.electionAlg =createElectionAlgorithm(electionType);}
8,这个选举的算法如下,这个默认传进来的参数为3。因此这个默认选用的就是这个FastLeaderElection的这个算法。主要是会初始化一个选举数据的一个管理器,然后会通过一个bio的方式对这个选举进行一个监听的操作,最后会有一个选举的具体的一个算法
protectedElectioncreateElectionAlgorithm(int electionAlgorithm){Election le=null;switch(electionAlgorithm){case0:
le =newLeaderElection(this);break;case1:
le =newAuthFastLeaderElection(this);break;case2:
le =newAuthFastLeaderElection(this,true);break;case3://初始化一个QuorumCnxManager类QuorumCnxManager qcm =createCnxnManager();QuorumCnxManager oldQcm = qcmRef.getAndSet(qcm);if(oldQcm !=null){
oldQcm.halt();}//创建一个线程QuorumCnxManager.Listener listener = qcm.listener;if(listener !=null){//开启线程,底层会去绑定一个端口,通过这个bio的方式进行一个选票的逻辑
listener.start();//选举的逻辑FastLeaderElection fle =newFastLeaderElection(this, qcm);
fle.start();
le = fle;}else{
LOG.error("Null listener when initializing cnx manager");}break;default:assertfalse;}return le;}
9,这个算法的逻辑方法FastLeaderElection的如下,主要就是在里面创建了几个链表类型的阻塞队列。阻塞队列就是为了后面加这个消息存放在这几个阻塞队列里面。
publicFastLeaderElection(QuorumPeer self,QuorumCnxManager manager){this.stop =false;this.manager = manager;starter(self, manager);}privatevoidstarter(QuorumPeer self,QuorumCnxManager manager){this.self = self;
proposedLeader =-1;
proposedZxid =-1;
sendqueue =newLinkedBlockingQueue<ToSend>();
recvqueue =newLinkedBlockingQueue<Notification>();this.messenger =newMessenger(manager);}
10,接下来会有一个fle.start();的这个方法,里面的主要方法实现如下
voidstart(){this.wsThread.start();this.wrThread.start();}Messenger(QuorumCnxManager manager){//发起选票的线程this.ws =newWorkerSender(manager);this.wsThread =newThread(this.ws,"WorkerSender[myid="+ self.getId()+"]");this.wsThread.setDaemon(true);//接收选票的线程this.wr =newWorkerReceiver(manager);this.wrThread =newThread(this.wr,"WorkerReceiver[myid="+ self.getId()+"]");this.wrThread.setDaemon(true);}
11,接下来回到第五步里面的这个 super.start() 的这个方法,其run方法的主要的核心如下,就是一个具体的投票的一个业务逻辑。主要会判断当前机器的一个状态,是looking状态还是已经选举成功的状态
try{while(running){switch(getPeerState()){//默认是looking观望状态,还在找leadercase LOOKING:
LOG.info("LOOKING");if(Boolean.getBoolean("readonlymode.enabled")){
LOG.info("Attempting to start ReadOnlyZooKeeperServer");finalReadOnlyZooKeeperServer roZk =newReadOnlyZooKeeperServer(logFactory,this,this.zkDb);Thread roZkMgr =newThread(){publicvoidrun(){try{sleep(Math.max(2000, tickTime));if(ServerState.LOOKING.equals(getPeerState())){
roZk.startup();}}catch(InterruptedException e){}catch(Exception e){}}};try{
roZkMgr.start();reconfigFlagClear();if(shuttingDownLE){
shuttingDownLE =false;startLeaderElection();}setCurrentVote(makeLEStrategy().lookForLeader());}catch(Exception e){
LOG.warn("Unexpected exception", e);setPeerState(ServerState.LOOKING);}finally{
roZkMgr.interrupt();
roZk.shutdown();}}else{try{reconfigFlagClear();if(shuttingDownLE){
shuttingDownLE =false;startLeaderElection();}//设置一个当前的投票,就是给自己投一票setCurrentVote(makeLEStrategy().lookForLeader());}catch(Exception e){
LOG.warn("Unexpected exception", e);setPeerState(ServerState.LOOKING);}}break;case OBSERVING:try{
LOG.info("OBSERVING");setObserver(makeObserver(logFactory));
observer.observeLeader();}catch(Exception e){
LOG.warn("Unexpected exception",e );}finally{
observer.shutdown();setObserver(null);updateServerState();}break;case FOLLOWING:try{
LOG.info("FOLLOWING");setFollower(makeFollower(logFactory));
follower.followLeader();}catch(Exception e){
LOG.warn("Unexpected exception",e);}finally{
follower.shutdown();setFollower(null);updateServerState();}break;case LEADING:
LOG.info("LEADING");try{setLeader(makeLeader(logFactory));
leader.lead();setLeader(null);}catch(Exception e){
LOG.warn("Unexpected exception",e);}finally{if(leader !=null){
leader.shutdown("Forcing shutdown");setLeader(null);}updateServerState();}break;}
start_fle =Time.currentElapsedTime();}}
12,这个设置投票的方法如下,主要是在这个lookForLeader里面,从这一步开始,就是选票的正式开始
publicVotelookForLeader()throwsInterruptedException{try{//创建两个集合HashMap<Long,Vote> recvset =newHashMap<Long,Vote>();HashMap<Long,Vote> outofelection =newHashMap<Long,Vote>();int notTimeout = finalizeWait;//构建一个同步块synchronized(this){
logicalclock.incrementAndGet();//更新选票信息updateProposal(getInitId(),getInitLastLoggedZxid(),getPeerEpoch());}//发送选票通知sendNotifications();while((self.getPeerState()==ServerState.LOOKING)&&(!stop)){//从队列中获取消息,接收这个选票的信息Notification n = recvqueue.poll(notTimeout,TimeUnit.MILLISECONDS);//初始为空if(n ==null){if(manager.haveDelivered()){sendNotifications();}else{//和其他端口建立这个bio的Socket连接//每个结点在开启的时候都会开启一个socket连接
manager.connectAll();}int tmpTimeOut = notTimeout*2;
notTimeout =(tmpTimeOut < maxNotificationInterval?
tmpTimeOut : maxNotificationInterval);}//如果收到了选票,判断这个选票是否合理elseif(validVoter(n.sid)&&validVoter(n.leader)){}}}}
初始这个选票的个数为空,然后会发送一个选票通知,具体实现如下
privatevoidsendNotifications(){//获取全部可以发送消息的机器for(long sid : self.getCurrentAndNextConfigVoters()){QuorumVerifier qv = self.getQuorumVerifier();//构造一条消息,向目标机器发送ToSend notmsg =newToSend(ToSend.mType.notification,
proposedLeader,
proposedZxid,
logicalclock.get(),QuorumPeer.ServerState.LOOKING,
sid,
proposedEpoch, qv.toString().getBytes());if(LOG.isDebugEnabled()){}//将消息加入到这个内存队列里面
sendqueue.offer(notmsg);}}
13,在这个客户端之间建立这个socket连接时,主要会通过下面这个方式实现。就是一般大的机器的sid会去连接小的sid,避免重复的双向连接。只要有一方连接,就可以实现双方的通信
privatevoidhandleConnection(Socket sock,DataInputStream din){try{
protocolVersion = din.readLong();if(protocolVersion >=0){// this is a server id and not a protocol version
sid = protocolVersion;}else{try{//获取远端服务器连接信息InitialMessage init =InitialMessage.parse(protocolVersion, din);//获取远端服务器的sid
sid = init.sid;
electionAddr = init.electionAddr;}catch(InitialMessage.InitialMessageException ex){
LOG.error("Initial message parsing error!", ex);closeSocket(sock);return;}}}//如果请求的机器的sid小,那么会直接关闭这个连接if(sid < self.getId()){closeSocket(sock);}else{//发送数据线程SendWorker sw =newSendWorker(sock, sid);//接收数据线程RecvWorker rw =newRecvWorker(sock, din, sid, sw);//来一个连接,就会将这个连接存放在一个map里面去
senderWorkerMap.put(sid, sw);//最后将这个选票的线程存放队列
queueSendMap.putIfAbsent(sid,newArrayBlockingQueue<ByteBuffer>(SEND_CAPACITY));
sw.start();
rw.start();}}
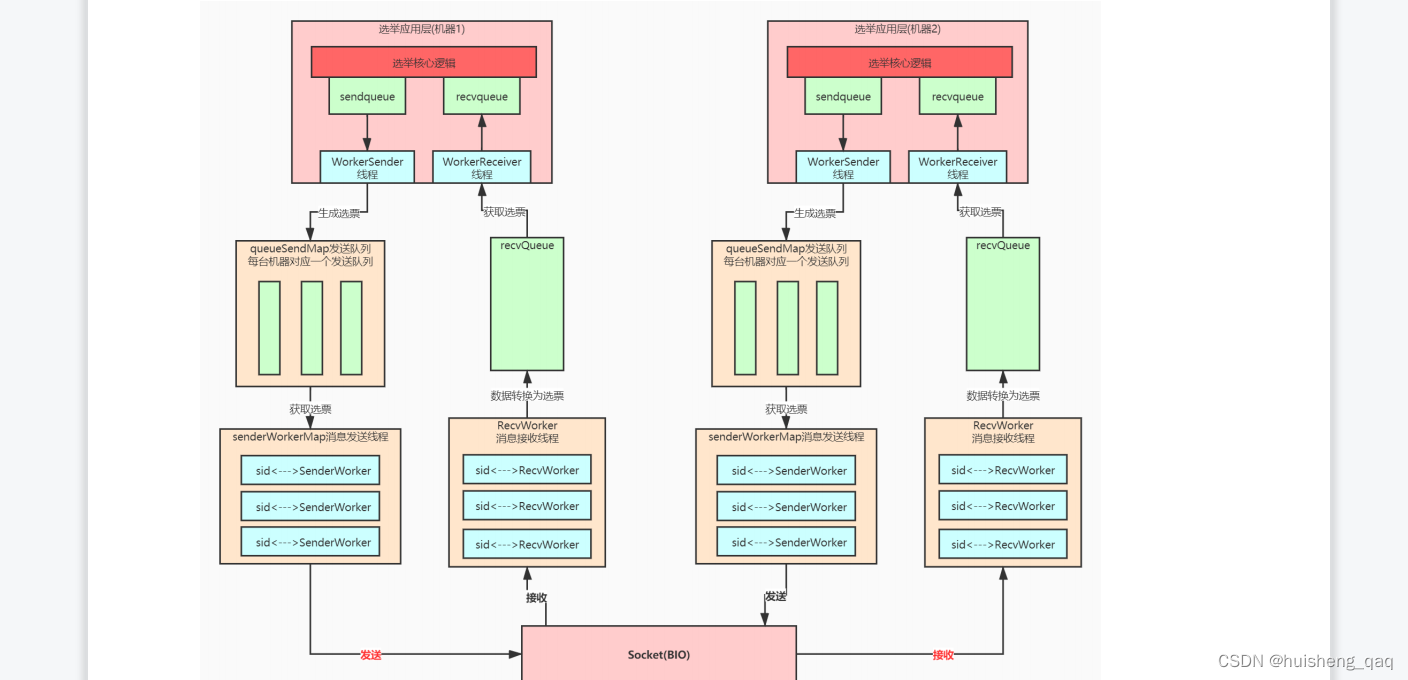
2.3,leader投票开始(重点)
14,那么在这个SendWorker线程和这个RecvWorker这两个线程,就是一个用来给其他结点投票的线程,一个用来接收别的结点给当前结点投票的线程
接下来先看这个SendWorker的底层实现,由于下面sw.start()以及开启这个这个线程,那么就是主要他看的这个run方法就知道他底层的具体实现,就是一个发送选票的线程
@Overridepublicvoidrun(){//获取刚刚加入到map里面的阻塞队列//就是说这个远端服务器有一个对应的队列,会通过socket管道连接将数据发送给别人ArrayBlockingQueue<ByteBuffer> bq = queueSendMap.get(sid);if(bq ==null||isSendQueueEmpty(bq)){ByteBuffer b = lastMessageSent.get(sid);if(b !=null){send(b);}}}
接下来查看这个RecvWorker的这个底层实现,就是一个接收选票的线程,会将接收到的数据存放在一个队列里面
@Overridepublicvoidrun(){
threadCnt.incrementAndGet();try{//输出流,读取一下别的机器发的数据
din.readFully(msgArray,0, length);ByteBuffer message =ByteBuffer.wrap(msgArray);//将这个信息存放到这个阻塞队列里面addToRecvQueue(newMessage(message.duplicate(), sid));}}
15,在向其他的这个服务端发送这个投票信息后,会对这个投票进行一个处理
classWorkerSenderextendsZooKeeperThread{@Overridepublicvoidrun(){try{//获取刚刚加入到队列里面的投票ToSend m = sendqueue.poll(3000,TimeUnit.MILLISECONDS);if(m ==null)continue;//处理这个投票process(m);}}}
然后在这个处理投票process的方法里面,主要是有一个toSend方法
voidprocess(ToSend m){ByteBuffer requestBuffer =buildMsg(m.state.ordinal(),
m.leader,
m.zxid,
m.electionEpoch,
m.peerEpoch,
m.configData);
manager.toSend(m.sid, requestBuffer);}
然后这个toSend方法里面有这个具体的处理这个投票的请求,如果是自己投自己的票,那么会将消息加入到一个队列里面,如果是投别的票,就会加入到其他的队列里面。
publicvoidtoSend(Long sid,ByteBuffer b){//如果机器的id是当前的myidif(this.mySid == sid){
b.position(0);//加入到一个队列里面addToRecvQueue(newMessage(b.duplicate(), sid));}else{ArrayBlockingQueue<ByteBuffer> bq =newArrayBlockingQueue<ByteBuffer>(
SEND_CAPACITY);ArrayBlockingQueue<ByteBuffer> oldq = queueSendMap.putIfAbsent(sid, bq);if(oldq !=null){addToSendQueue(oldq, b);}else{addToSendQueue(bq, b);}connectOne(sid);}}
同时如上图,由于底层使用的是bio,所以会有阻塞问题,因此在客户端发送选票信息里面增加了很多的这个队列
16,机器除了向自己或者向别的机器投票之外,也会去接收其他机器给当前机器的选票。接下来加入这个11的else if的这个方法里面
//如果收到了选票,会验证这个选票是否有效elseif(validVoter(n.sid)&&validVoter(n.leader)){switch(n.state){case LOOKING:if(n.electionEpoch > logicalclock.get()){
logicalclock.set(n.electionEpoch);
recvset.clear();if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,getInitId(),getInitLastLoggedZxid(),getPeerEpoch())){updateProposal(n.leader, n.zxid, n.peerEpoch);}else{updateProposal(getInitId(),getInitLastLoggedZxid(),getPeerEpoch());}sendNotifications();}elseif(n.electionEpoch < logicalclock.get()){if(LOG.isDebugEnabled()){}break;}//重点pk逻辑,通过这个totalOrderPredicate方法实现elseif(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
proposedLeader, proposedZxid, proposedEpoch)){//第一轮没有得出谁输输谁赢//如果对面的这个机器胜了,那么就会更新这个当前机器的选票updateProposal(n.leader, n.zxid, n.peerEpoch);sendNotifications();}//将所有接收到的选票存在这个hashMap里面
recvset.put(n.sid,newVote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));//获取到所有的这个票数之后呢,就会去校验一下这个底层的逻辑,通过这个termPredicate方法if(termPredicate(recvset,newVote(proposedLeader, proposedZxid,
logicalclock.get(), proposedEpoch))){}if(n ==null){//如果pk成功,那么设置成LEADING,失败则设置成FOLLOWING
self.setPeerState((proposedLeader == self.getId())?ServerState.LEADING:learningState());//返回这个要选举成leader的主结点Vote endVote =newVote(proposedLeader,
proposedZxid, logicalclock.get(),
proposedEpoch);leaveInstance(endVote);return endVote;}}
2.4,结点之间的pk(重点)
17,接下来就是这个pk的逻辑,通过这个totalOrderPredicate方法实现,其选举周期就是下面的这个return的这个方法。就是说会先比较投票周期,哪个结点的投票周期大,那么哪个结点pk赢,如果周期一样,那么会比较这个zxid的这个事务id,谁的事务id大,谁胜利,如果一样,那么就比较这个serverId,就是对应机器的myid,谁的myid大,那么谁pk胜利。
//newId : 接收到的选票protectedbooleantotalOrderPredicate(long newId,long newZxid,long newEpoch,long curId,long curZxid,long curEpoch){if(self.getQuorumVerifier().getWeight(newId)==0){returnfalse;}/*
* We return true if one of the following three cases hold:
* 1- New epoch is higher
* 2- New epoch is the same as current epoch, but new zxid is higher
* 3- New epoch is the same as current epoch, new zxid is the same
* as current zxid, but server id is higher.
*///先判断这个选举周期是否比当前机器的选举周期大return((newEpoch > curEpoch)||//如果周期一样就会比较这个事务id谁大((newEpoch == curEpoch)&&((newZxid > curZxid)||//如果事务id一样,那么会比较这个myId谁大((newZxid == curZxid)&&(newId > curId)))));}
18,接下来查看这个16里面的这个termPredicate方法,就是做一个校验,就是说验证一下这个被投的票数有没有过半,如果过半,那就成为一个leader结点。
protectedbooleantermPredicate(Map<Long,Vote> votes,Vote vote){//最后会通过一个遍历的方式将这个票存在一个set的一个集合里面return voteSet.hasAllQuorums();}publicbooleanhasAllQuorums(){for(QuorumVerifierAcksetPair qvAckset : qvAcksetPairs){//判断这个票数有没有过半if(!qvAckset.getQuorumVerifier().containsQuorum(qvAckset.getAckset()))returnfalse;}returntrue;}publicbooleancontainsQuorum(Set<Long> ackSet){return(ackSet.size()> half);}
19,前面两个结点就可以确定一个follow和一个leader,如果有第三台机器加入,那么第三台机器处于一个looking状态,已经有了这个leader和follow的话就不会再参与选举了,这个第三台机器直接从这个looking状态变为这个follow状态。就是在这第三台机器向这个follow和leader发送这个票数之后,follow和leader都会返回这个leader的这个sid,那么这个第三台机器里面存储的这个myid也会变成leader主结点的sid。
2.5,leader挂了重新选举
20,这样的话选举的流程就结束了,接下来讲一下如果这个leader挂了,follow如何选举新的leader。在选举完成之后,leader会走leader的选票流程,follow会走follow的业务流程。首先先看leader的业务流程
case LEADING:try{setLeader(makeLeader(logFactory));//选举完成之后,会做一个leader的一个业务逻辑
leader.lead();setLeader(null);}
其leader主要做的事情如下
voidlead()throwsIOException,InterruptedException{try{//将文件数据加入到内存里面
zk.loadData();//又会开启一个线程
cnxAcceptor =newLearnerCnxAcceptor();
cnxAcceptor.start();}}
这个线程的run方法如下,就是会初始化一个socket连接,便于和这个follow从结点进行一个通信
@Overridepublicvoidrun(){try{
s = ss.accept();}}
21,主结点建立了一个socket连接通道之后,再来看看这个follow这个从结点的业务流程。
case FOLLOWING:try{setFollower(makeFollower(logFactory));
follower.followLeader();}catch(Exception e){}finally{
follower.shutdown();setFollower(null);updateServerState();}break;
在这个followLeader这个方法里面,也会创建一个通信的通道,用于连接这个主结点
voidfollowLeader()throwsInterruptedException{try{QuorumServer leaderServer =findLeader();try{//连接主结点connectToLeader(leaderServer.addr, leaderServer.hostname);//将zxid发送给主结点syncWithLeader(newEpochZxid);}}}
这样的话这个leader和这个follow就建立起这个通道用于通信连接了,主要用于做一些数据同步,心跳的发送等。
22,leader和这个follow主要是通过这个长连接的方式进行通信的,就是过一段时间就会发送一段这个心跳包,如果一段时间内leader没有再发心跳,那么这个follow感知这个leader挂了,follow又会重新进行一个leader选举的操作。
//leader会给每个follow发送ping命令for(LearnerHandler f :getLearners()){
f.ping();}
如果从结点那边没有收到这个ping命令,那么这个从结点就会抛出一个io流的一个异常,并且会更新这个从结点的follow的状态,将follow变为这个Looking状态,又可以进行一个重新的选举
try{
sock.close();}privatesynchronizedvoidupdateServerState(){setPeerState(ServerState.LOOKING);}
二,总结
1,leader选举总结
zookeeper的每个结点,都会有一个发送投票的线程和一个接收投票的线程,每个结点都是通过这种bio,就是阻塞Io的方式获取这个投票。
然后每个结点都会有一个对应的状态,比如说LOOKING观望状态,LEADING,FOLLOWING状态。在一开始,每个结点都处于这个LOOKING状态。
每个结点的都会有一个myid和事务id,这两个会通过一个map保存,如(myid,zxid),只要有两个结点或者以上,那么就会进行一个主从结点的一个选举,就是会通过这个投票线程投票和接收投票的线程接收到其他线程给自己的投票。选举开始就是每个线程都会先投自己一票,然后再给别的机器进行一个投票,然后机器里面就会存一个自己的myid,事务id和别的机器的sid,事务id,那么两个(myid,zxid)就会进行一个pk,谁赢谁留下来。
pk过程就是会先比较投票周期,哪个结点的投票周期大,那么哪个结点pk赢,如果周期一样,那么会比较这个zxid的这个事务id,谁的事务id大,谁胜利,如果一样,那么就比较这个serverId,就是对应机器的myid,谁的myid大,那么谁pk胜利。结点会将赢的(sid,zxid)保存,也就是两台机器都会保存同一个(sid,zxid)
只要这个(sid,zxid)超过一半,那么这台sid的机器就会成为这个leader,另一台机器就成为follow,那么这样选举就完成。
如果有第三台机器进来,那么这台机器处于LOOKING状态,如果有leader和follow,那么就不会重新选举,而是将这个leader的(sid,zxid)直接和这台机器的(myid,zxid)进行一个替换,那么这台机器也可以成为一个follow结点。
2,主结点挂了选举方式
zookeeper在选举完这个主结点之后,会新建一个socker进行一个通信,比如说一些主从复制,发布ping心跳命令等。如果说这个心跳出现异常,就是主结点挂了,那么这个从结点可以通过这个ping命令来感知到这个主结点挂了,并且会抛出异常,之后所有的这个从结点的状态会发生改变,从之前的following状态变为looking状态,此时没有这个lead和follow结点,那么这些LOOKING状态的结点又会进行一轮新的选举。
版权归原作者 huisheng_qaq 所有, 如有侵权,请联系我们删除。