

今天,我们将使用深度学习来创建面部解锁算法。要完成我们的任务需要三个主要部分。
- 查找人脸的算法
- 一种将人脸嵌入向量空间的方法
- 比较已编码人脸的函数
人脸面孔查找和定位
首先,我们需要一种在图像中查找人脸的方法。我们可以使用一种称为MTCNN(多任务级联卷积网络)的端到端方法。
只是一点技术背景,所以称为Cascaded,因为它由多个阶段组成,每个阶段都有其神经网络。下图显示了该框架。
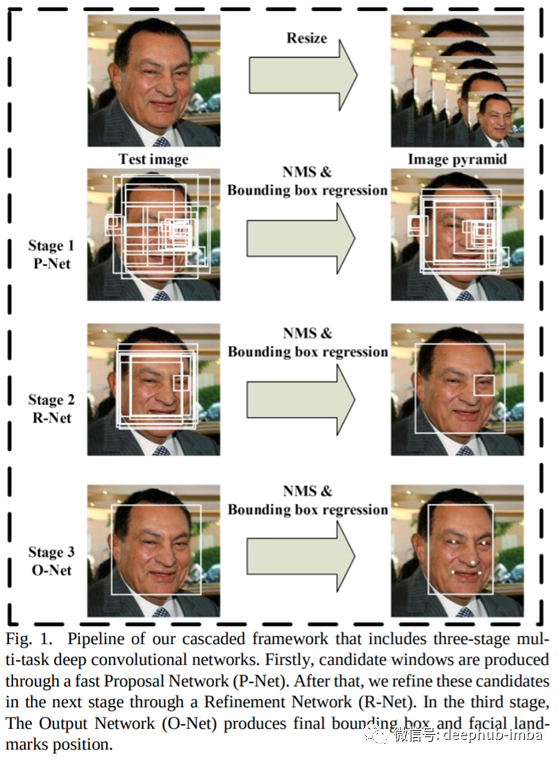
我们依靠facenet-pytorch中的MTCNN实现。
数据
我们需要图像!我整理了一些照片,莱昂纳多·迪卡普里奥和马特·戴蒙。
遵循PyTorch最佳做法,我使用ImageFolder加载数据集。我创建了MTCNN实例,并使用transform参数将其传递给数据集。
我的文件夹结构如下:
./faces
├── di_caprio
│ ├── ....jpg
├── matt_demon
│ ├── ....jpg
└── me
│ ├── ....jpg
MTCNN自动裁剪输入并调整其大小,我使用image_size = 160,因为模型将使用具有该尺寸的图像进行训练。我还要添加18像素的边距,以确保我们包括整个脸部。
import torch
import torchvision.transforms as T
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision.datasets import ImageFolder
from facenet_pytorch import MTCNN, InceptionResnetV1
from pathlib import Path
from typing import Union, Callable
data_root = Path('.')
# create the MTCNN network
transform = MTCNN(image_size=160, margin=18)
ds = ImageFolder(root=data_root / 'faces', transform=transform)
# our dataset is so small that the batch_size can equal to its lenght
dl = DataLoader(ds, batch_size=len(ds))
ds[1]
ds结构如下:
(tensor([[[ 0.9023, 0.9180, 0.9180, ..., 0.8398, 0.8242, 0.8242], [ 0.9023, 0.9414, 0.9492, ..., 0.8555, 0.8320, 0.8164], [ 0.9336, 0.9805, 0.9727, ..., 0.8555, 0.8320, 0.7930], ..., [-0.7070, -0.7383, -0.7305, ..., 0.4102, 0.3320, 0.3711], [-0.7539, -0.7383, -0.7305, ..., 0.3789, 0.3633, 0.4102], [-0.7383, -0.7070, -0.7227, ..., 0.3242, 0.3945, 0.4023]], [[ 0.9492, 0.9492, 0.9492, ..., 0.9336, 0.9258, 0.9258], [ 0.9336, 0.9492, 0.9492, ..., 0.9492, 0.9336, 0.9258], [ 0.9414, 0.9648, 0.9414, ..., 0.9570, 0.9414, 0.9258], ..., [-0.3633, -0.3867, -0.3867, ..., 0.6133, 0.5352, 0.5820], [-0.3945, -0.3867, -0.3945, ..., 0.5820, 0.5742, 0.6211], [-0.3711, -0.3633, -0.4023, ..., 0.5273, 0.6055, 0.6211]], [[ 0.8867, 0.8867, 0.8945, ..., 0.8555, 0.8477, 0.8477], [ 0.8789, 0.8867, 0.8789, ..., 0.8789, 0.8633, 0.8477], [ 0.8867, 0.9023, 0.8633, ..., 0.9023, 0.8789, 0.8555], ..., [-0.0352, -0.0586, -0.0977, ..., 0.7617, 0.7070, 0.7461], [-0.0586, -0.0586, -0.0977, ..., 0.7617, 0.7617, 0.8086], [-0.0352, -0.0352, -0.1211, ..., 0.7227, 0.8086, 0.8086]]]), 0)
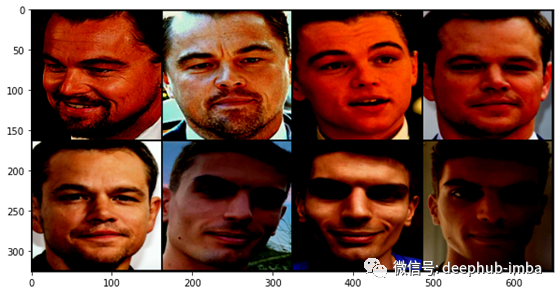
数据集返回张量。让我们可视化所有输入。它们已通过MTCNN图像进行了归一化,最后一行的最后三张图像是作者自己的自拍照:)
嵌入向量空间
我们的数据已准备就绪。为了比较人脸并找出两个人脸是否相似,我们需要在向量空间中对它们进行编码,如果两个人脸相似,则与它们相关联的两个向量也都相似(接近)。
我们可以使用在一个著名的人脸数据集(例如vgg_face2)上训练的模型,并使用分类头之前的最后一层的输出(潜在空间)作为编码器。
在这些数据集之一上训练的模型必须学习有关输入的重要特征。最后一层(在完全连接的层之前)对高级功能进行编码。因此,我们可以使用它将输入嵌入向量空间中,希望相似图像彼此靠近。
详细地,我们将使用在vggface2数据集上训练的初始Resnet。嵌入空间的尺寸为512。
resnet = InceptionResnetV1(pretrained='vggface2').eval()
with torch.no_grad():
for (imgs, labels) in dl:
embs = resnet(imgs)
break
embs.shape
torch.Size([8, 512])
完美,我们有8张图片,我们获得了8个矢量
相似度计算
为了比较向量,我们可以使用cosine_similarity来查看它们彼此之间的距离。余弦相似度将输出[-1,1]之间的值。在朴素的情况下,两个比较的向量相同,它们的相似度为1。因此,最接近1的相似度。
现在,我们可以在数据集中找到每对之间的所有距离。
import seaborn as sns
import numpy as np
similarity_matrix = torch.zeros(embs.shape[0], embs.shape[0])
for i in range(embs.shape[0]):
for j in range(embs.shape[0]):
similarity_matrix[i,j] = torch.cosine_similarity(embs[i].view(1, -1), embs[j].view(1, -1))
fig = plt.figure(figsize=(15, 15))
sns.heatmap(similarity_matrix.numpy(), annot = True,)
numicons = 8
for i in range(numicons):
axicon = fig.add_axes([0.12+0.082*i,0.01,0.05,0.05])
axicon.imshow(un_normalize(ds[i][0]).permute(1,2,0).numpy())
axicon.set_xticks([])
axicon.set_yticks([])
axicon = fig.add_axes([0, 0.15 + 0.092 * i,.05,0.05])
axicon.imshow(un_normalize(ds[len(ds) - 1 - i][0]).permute(1,2,0).numpy())
axicon.set_xticks([])
axicon.set_yticks([])
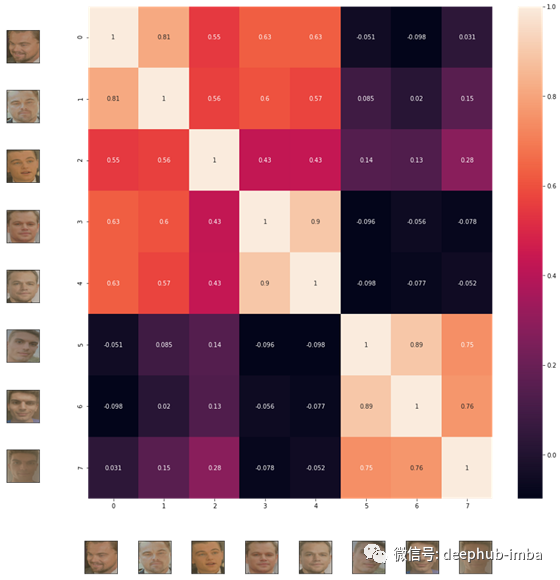
显然,我与Matt或Leo不太相似,但是它们有一些共同点!
我们可以更加深入,在嵌入向量中运行PCA并将图像投影到二维平面中
from matplotlib.offsetbox import OffsetImage, AnnotationBbox
def pca(x: torch.Tensor, k: int = 2) -> torch.Tensor:
"""
From http://agnesmustar.com/2017/11/01/principal-component-analysis-pca-implemented-pytorch/
"""
# preprocess the data
X_mean = torch.mean(x, 0)
x = x - X_mean.expand_as(x)
# svd
U, S, V = torch.svd(torch.t(x))
return torch.mm(x, U[:, :k])
points = pca(embs, k=2)
plt.rcParams["figure.figsize"] = (12,12)
fig, ax = plt.figure(), plt.subplot(111)
plt.scatter(points[:,0], points[:,1])
for i, p in enumerate(points):
x, y = p[0], p[1]
img = un_normalize(ds[i][0])
img_np = img.permute(1, 2, 0).numpy().squeeze()
ab = AnnotationBbox(OffsetImage(img_np, zoom=0.6), (x, y), frameon=False)
ax.add_artist(ab)
plt.plot()
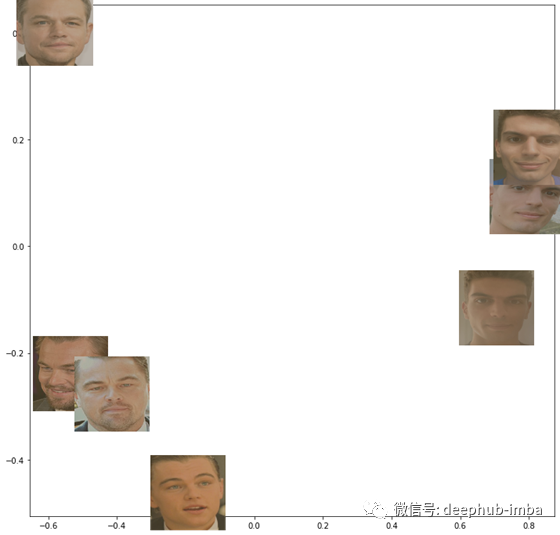
我们将512维压缩为2,所以我们丢失了很多数据。
好的,我们有一种方法来找到脸,看看它们是否彼此相似,现在我们可以创建我们的脸解锁算法。
我的想法是取n张允许的人的图像,在嵌入空间中找到中心,选择一个阈值,看d看中心和新图像之间的余弦相似度是小于还是大于它。
from dataclasses import dataclass, field
from typing import List, Callable
from PIL import Image
@dataclass
class FaceUnlock:
images: List[Image.Image] = field(default_factory = list)
th: float = 0.8
transform: Callable = MTCNN(image_size=160, margin=18)
embedder: torch.nn.Module = InceptionResnetV1(pretrained='vggface2').eval()
center: torch.Tensor = None
def __post_init__(self):
faces = torch.stack(list(map(self.transform, self.images)))
embds = self.embedder(faces)
self.center = embds.sum(0) / embds.shape[0]
def __call__(self, x: Image.Image) -> bool:
face = self.transform(x)
emb = self.embedder(face.unsqueeze(0))
similarity = torch.cosine_similarity(emb.view(1, -1), self.center.view(1, -1))
is_me = similarity > self.th
return is_me, similarity
# load pictures of myself
me = data_root / 'faces' / 'me'
images = list(map(Image.open, me.glob('*')))
# initialize face unlock with my images
face_unlock = FaceUnlock(images)
from ipywidgets import interact, interactive, fixed, interact_manual
def unlock_with_filepath(path):
img = Image.open(path)
is_me, similarity = face_unlock(img)
print(f"{'🔓' if is_me else '🔒'} similarity={similarity.item():.3f}")
fig = plt.figure()
plt.imshow(img)
plt.plot()
test_root = data_root / 'faces_test'
interact(unlock_with_filepath, path=list(test_root.glob('*')))
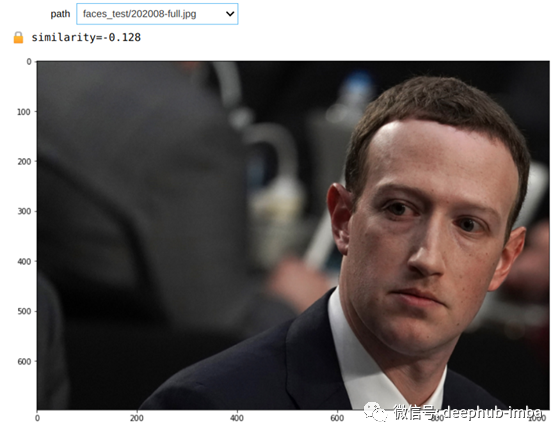
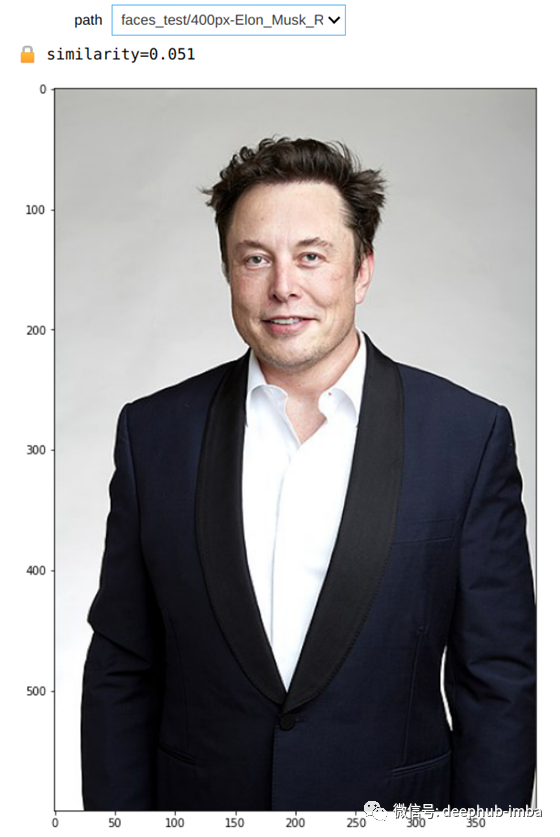
相似度得分比以前的图像高,所以我猜是真的!
让我们尝试自己的新自拍

总结
我们已经看到了一种仅使用2D数据(图像)创建人脸解锁算法的有吸引力的方法。它依靠神经网络对相似面孔彼此靠近的高维向量空间中的裁剪面孔进行编码。但是,我不知道该模型是如何训练的,并且可能很容易弄糊涂(即使在我的实验中该算法效果很好)。
如果在没有数据扩充的情况下训练模型怎么办?然后,可能只是翻转同一个人可能会破坏潜在的表示。
更加健壮的训练例程将是无监督的(类似于BYOL),它严重依赖于数据增强。
最后,你可以在这里找到所有的代码
https://github.com/FrancescoSaverioZuppichini/Face-Unlock
感谢您的阅读。
作者:Francesco Zuppichini
deephub翻译组