
数据科学和机器学习所需的数学知识中,约有30-40%来自线性代数。矩阵运算在线性代数中占有重要的地位。Numpy通常用于在Python中执行数值计算,并且对于矩阵操作做了特殊的优化。numpy通过向量化避免许多for循环来更有效地执行矩阵操作。
我将包括本文中讨论的每个矩阵操作的含义、背景描述和代码示例。本文末尾的“关键要点”一节将提供一些更具体矩阵操作的简要总结。所以,一定要阅读这部分内容。
我将按照以下顺序讨论每个矩阵操作。
- 内积
- 点积
- 转置
- 迹
- 秩
- 行列式
- 逆
- 伪逆
- 扁平化
- 特征值和特征向量
内积 Inner product
内积接收两个大小相等的向量,并返回一个数字(标量)。这是通过将每个向量中相应的元素相乘并将所有这些乘积相加来计算的。在numpy中,向量被定义为一维numpy数组。
为了得到内积,我们可以使用np.inner()。对于1维向量np.dot()和np.inner()是相同的两者都给出了相同的结果(np文档中有详细描述,大意是对于2-D数组,它等效于矩阵乘法,对于1-D数组,其等效于向量的内积)。这些函数的输入是两个向量它们的大小应该是一样的。
import numpy as np
# Vectors as 1D numpy arrays
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print("a= ", a)
print("b= ", b)
print("\ninner:", np.inner(a, b))
print("dot:", np.dot(a, b))

点积 Dot product
点积是为矩阵定义的。它是两个矩阵中相应元素的乘积的和。为了得到点积,第一个矩阵的列数应该等于第二个矩阵的行数。
有两种方法可以在numpy中创建矩阵。最常见的一种是使用numpy ndarray类。这里我们创建了二维numpy数组(ndarray对象)。另一种方法是使用numpy矩阵类。
ndarray和matrix对象的点积都可以使用np.dot()得到。
import numpy as np
# Matrices as ndarray objects
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6, 7], [8, 9, 10]])
print("a", type(a))
print(a)
print("\nb", type(b))
print(b)
# Matrices as matrix objects
c = np.matrix([[1, 2], [3, 4]])
d = np.matrix([[5, 6, 7], [8, 9, 10]])
print("\nc", type(c))
print(c)
print("\nd", type(d))
print(d)
print("\ndot product of two ndarray objects")
print(np.dot(a, b))
print("\ndot product of two matrix objects")
print(np.dot(c, d))

当使用操作符将两个ndarray对象相乘时,结果是逐元素相乘。另一方面,当使用操作符将两个矩阵对象相乘时,结果是点(矩阵)乘积,相当于前面的np.dot()。
import numpy as np
# Matrices as ndarray objects
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [8, 9]])
print("a", type(a))
print(a)
print("\nb", type(b))
print(b)
# Matrices as matrix objects
c = np.matrix([[1, 2], [3, 4]])
d = np.matrix([[5, 6], [8, 9]])
print("\nc", type(c))
print(c)
print("\nd", type(d))
print(d)
print("\n* operation on two ndarray objects (Elementwise)")
print(a * b)
print("\n* operation on two matrix objects (same as np.dot())")
print(c * d)

转置
矩阵的转置是通过行与列的交换得到的。我们可以使用np.transpose()函数或NumPy ndarray.transpose()方法或ndarray。T(一种不需要括号的特殊方法)来求转置。它们都给出相同的输出。
import numpy as np
a = np.array([[1, 2], [3, 4], [5, 6]])
print("a = ")
print(a)
print("\nWith np.transpose(a) function")
print(np.transpose(a))
print("\nWith ndarray.transpose() method")
print(a.transpose())
print("\nWith ndarray.T short form")
print(a.T)

转置也可以应用到向量上。但是,从技术上讲,一维numpy数组不能转置。
import numpy as npa = np.array([1, 2, 3])
print("a = ")
print(a)
print("\na.T = ")
print(a.T)

如果你真的想转置一个向量,它应该被定义为一个带有双方括号的二维numpy数组。
import numpy as npa = np.array([[1, 2, 3]])
print("a = ")
print(a)
print("\na.T = ")
print(a.T)

迹 Trace
迹是方阵中对角线元素的和。有两种方法来计算迹。我们可以简单地使用ndarray对象的trace()方法,或者先获取对角线元素,然后再获取和。
import numpy as npa = np.array([[2, 2, 1],
[1, 3, 1],
[1, 2, 2]])
print("a = ")
print(a)
print("\nTrace:", a.trace())
print("Trace:", sum(a.diagonal()))

秩 Rank
矩阵的秩是由它的列或行张成(生成)的向量空间的维数。换句话说,它可以被定义为线性无关的列向量或行向量的最大个数。
可以使用numpy linalg包中的matrix_rank()函数来查找矩阵的秩。
import numpy as npa = np.arange(1, 10)
a.shape = (3, 3)
print("a = ")
print(a)
rank = np.linalg.matrix_rank(a)
print("\nRank:", rank)

行列式(决定式)
方阵的行列式可以计算det()函数,该函数也来自numpy linalg包。如果行列式是0,这个矩阵是不可逆的。在代数术语中,它被称为奇异矩阵。
import numpy as npa = np.array([[2, 2, 1],
[1, 3, 1],
[1, 2, 2]])
print("a = ")
print(a)
det = np.linalg.det(a)
print("\nDeterminant:", np.round(det))

逆
方阵的逆可以通过numpy linalg包的inv()函数找到。如果方阵的行列式不为0,它的逆矩阵就为真。
import numpy as npa = np.array([[2, 2, 1],
[1, 3, 1],
[1, 2, 2]])
print("a = ")
print(a)
det = np.linalg.det(a)
print("\nDeterminant:", np.round(det))
inv = np.linalg.inv(a)
print("\nInverse of a = ")
print(inv)

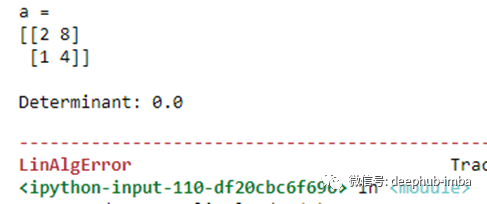
如果你试图计算一个奇异矩阵(行列式为0的方阵)的真逆,你会得到一个错误。
import numpy as npa = np.array([[2, 8],
[1, 4]])
print("a = ")
print(a)
det = np.linalg.det(a)
print("\nDeterminant:", np.round(det))
inv = np.linalg.inv(a)
print("\nInverse of a = ")
print(inv)
伪逆
即使对于奇异矩阵(行列式为0的方阵),也可以使用numpy linalg包的pinv()函数计算伪(非真实)逆。
import numpy as npa = np.array([[2, 8],
[1, 4]])
print("a = ")
print(a)
det = np.linalg.det(a)
print("\nDeterminant:", np.round(det))
pinv = np.linalg.pinv(a)
print("\nPseudo Inverse of a = ")
print(pinv)

如果方阵是非奇异的(行列式不为0),则真逆和伪逆没有区别。
扁平化
Flatten是一种将矩阵转换为一维numpy数组的简单方法。为此,我们可以使用ndarray对象的flatten()方法。
import numpy as npa = np.arange(1, 10)
a.shape = (3, 3)
print("a = ")
print(a)
print("\nAfter flattening")
print("------------------")
print(a.flatten())

特征值和特征向量
设A是一个nxn矩阵。如果有一个非零向量x满足下列方程,λ标量称为A的特征值。

向量x称为与λ相对应的A的特征向量。
在numpy中,可以使用eig()函数同时计算特征值和特征向量。
import numpy as npa = np.array([[2, 2, 1],
[1, 3, 1],
[1, 2, 2]])
print("a = ")
print(a)
w, v = np.linalg.eig(a)
print("\nEigenvalues:")
print(w)
print("\nEigenvectors:")
print(v)
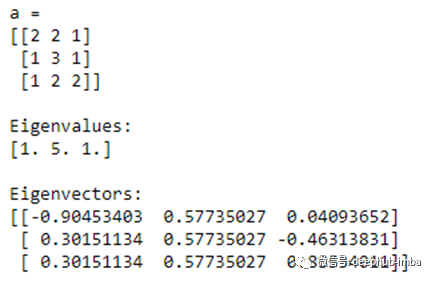
特征值的总和(1+5+1=7)等于同一个矩阵的迹(2+3+2=7)!特征值(1x5x1=5)的乘积等于同一个矩阵的行列式(5)!
特征值和特征向量在主成分分析(PCA)中非常有用。在主成分分析中,相关矩阵或协方差矩阵的特征向量代表主成分(最大方差方向),对应的特征值代表每个主成分解释的变化量。
关键要点总结
由于有了numpy库,只需一两行代码就可以轻松地执行矩阵操作。在本篇文章中我们介绍了numpy10个常用的矩阵运算。Numpy有一些通用函数,也有一些专门用于线性代数的特殊函数,例如,linalg包有一些专门用于线性代数的特殊函数。
在numpy中,矩阵和ndarray是两个不同的东西。熟悉它们的最好方法是亲自尝试这些代码。
在Scikit-learn机器学习库中,今天介绍的大多数矩阵操作在我们创建和拟合模型时是在后台进行工作的。例如,当我们使用Scikit-learn PCA()函数时,特征值和特征向量是在幕后计算的。Scikit-learn和许多其他的库,如pandas, seaborn, matplotlib都是建立在numpy之上的。因此,numpy是一个功能强大的Python库。
我们还可以将一些矩阵运算结合起来进行复杂的计算。例如,如果你想按这个顺序乘3个矩阵A, B和C,我们可以用np.dot(np.dot(A, B), C)。A, B, C的尺寸应相应匹配。
感谢你的阅读!
作者:Rukshan Pramoditha
原文地址:https://towardsdatascience.com/top-10-matrix-operations-in-numpy-with-examples-d761448cb7a8
deephub翻译组