
神经网络是所有 AI 算法的核心,如今,深度神经网络用于从图像识别和对象检测到自然语言处理和生成的各种任务。在剖析了构成神经网络的基本构建块及其工作原理之后,本问将深入研究神经架构类型及其各自的用途、神经网络芯片和模型优化技术。
介绍
计算单元(也称为神经元)的大规模互连包括一个神经网络,它是所有人工智能 (AI) 算法的核心和灵魂。大约 80 年前的 1943 年,伊利诺伊大学芝加哥分校的神经生理学家 Warren McCullough 和数学家 Walter Pitts 首次提出了神经网络。经过一系列演变,深度神经网络 (DNN)——通常是具有两个以上隐藏层的网络——现在被用于**图像识别、图像分类、对象检测、语音识别、语言翻译、自然语言处理 (NLP)和自然语言生成 (NLG)**。
本文首先通过与生物神经网络进行类比来介绍神经网络的概念,随后引导读者了解神经网络的基本组成部分,这些组成部分被认为是构建块。随后讨论了常见的神经架构,定义了神经元的基本排列及其服务的特定目的。
然后,我们将讨论专门为高效处理 DNN 工作负载而设计的不同 AI 加速器,以及用于提高学习率以减少整体损失并提高准确性的神经网络优化器。最后,我们将介绍 DNN 在各行业中的各种应用,并探索将高性能计算 (HPC) 与 AI 结合使用的能力。
什么是神经网络?
我们的生物神经网络通过我们的五种感官接收来自外部环境的感觉。然后神经元将这些感觉传递给我们的其他神经细胞。人工神经网络 (ANN) 以同样的方式收集数据作为**输入,神经元整合所有信息**。就像生物神经网络的突触一样,ANN 中的互连在隐藏层中转换输入数据。ANN 中的输出的生成类似于生物神经网络中轴突的机制,该神经网络将输出通道化。
神经网络基础
本节将首先阐明神经网络的组成部分,然后是说明神经元的各种网络架构是如何排列的。随后对神经网络芯片和优化器将展示网络的无缝实施,以提高准确性和速度。
神经网络组件
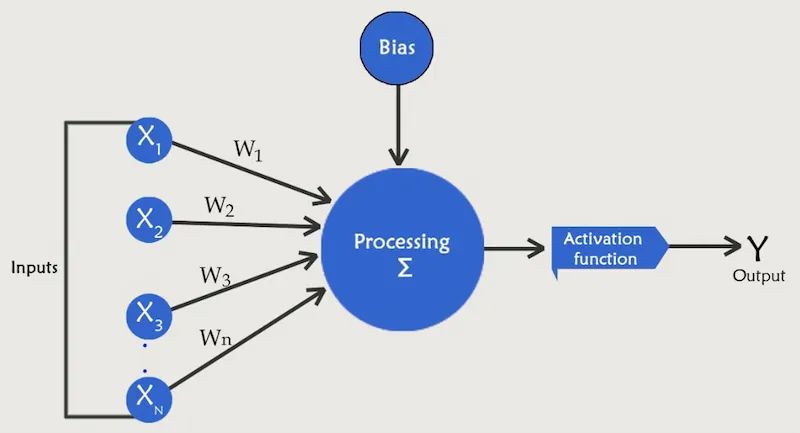
首先了解神经网络的具体细节至关重要,它由三层组成——输入、隐藏和输出——以及感知器、激活函数、权重和偏差。
输入、隐藏和输出层
单个输入层接受有助于预测期望结果的外部自变量。模型的所有自变量都是输入层的一部分。**一对多互连的隐藏层**是根据神经网络将要服务的目的进行配置的,例如通过视觉识别和 NLP 进行对象检测和分类。隐藏层是输入/预测变量的加权和的函数。当网络包含多个隐藏层时,每个隐藏单元都是前一个隐藏层单元的加权和的函数。输出层,作为隐藏层的函数,包含目标(因)变量。对于任何图像分类,输出层根据模型的预期目标将输入数据分离到多个节点中。
图1:输入、隐藏和输出
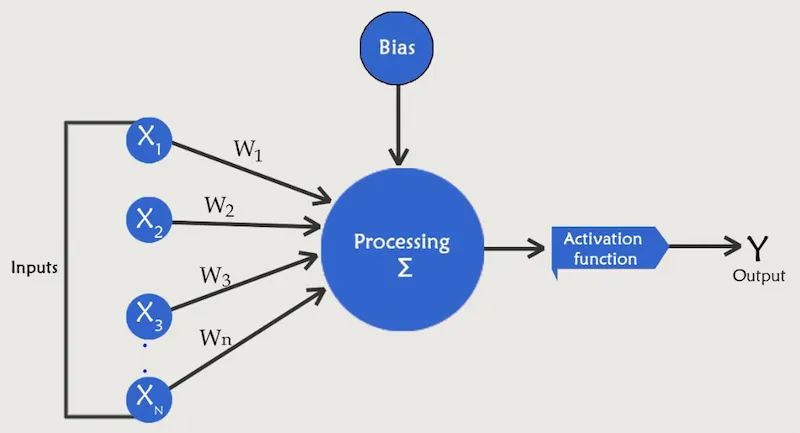
感知器
康奈尔大学的实验心理学家 Frank Rosenblatt 对神经元的学习能力很感兴趣,并创建了一个具有多个输入、一个处理器和一个单一输出的简单感知器。因此,感知器是包含单层的神经网络的构建块。
图2 感知机
激活函数
激活函数,也称为传递函数,控制神经元输出的幅度。在具有多个隐藏层的深度神经网络中,激活函数将一层中单元的加权和与后续层中单元的值联系起来。所有隐藏层都使用相同的激活函数。激活函数可以是线性的也可以是非线性的,下表总结了最常用的激活函数:
表1 激活函数

如果对使用哪种激活函数最适合您的用例有任何混淆,建议使用 ReLU,因为它有助于克服梯度消失问题并允许更好地训练模型。
权重和偏差
权重表示相应特征(输入变量)在预测输出中的重要性。他们还解释了该功能与目标输出之间的关系。下图说明输出是 x(输入)乘以连接权重 w0 和 b(偏差)乘以连接权重 w1 的总和。
图3 权重与偏差

偏差就像线性函数 y = mx+c 中的常数,其中 m = 权重,c = 偏差。没有偏差,模型只会通过原点,这样的场景与现实相去甚远。因此,偏差有助于转置线条并使模型更加灵活。
常见的神经架构
神经网络架构由神经元组成,这些神经元的排列方式创建了定义算法将如何学习的结构。这些排列具有输入层和输出层,中间有隐藏层,增加了模型的计算和处理能力。下面讨论关键架构。
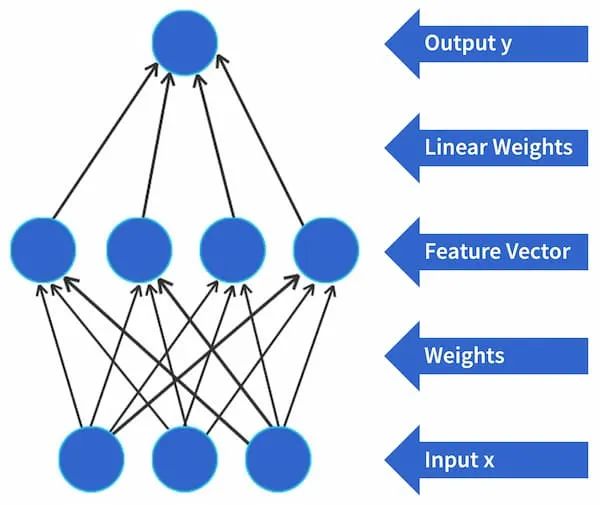
径向基函数
径向基函数 (RBF) 有一个称为“特征向量”的非线性隐藏层,其中隐藏层中的神经元数量应多于输入层中的神经元数量,以将数据投射到更高的维空间。因此,RBF 增加了特征向量的维数,使分类在高维空间中具有高度可分性。下图说明了如何通过单个隐藏层(即特征向量)将输入 (x) 转换为输出 (y),该隐藏层通过权重连接到 x 和 y。
图4 径向基函数
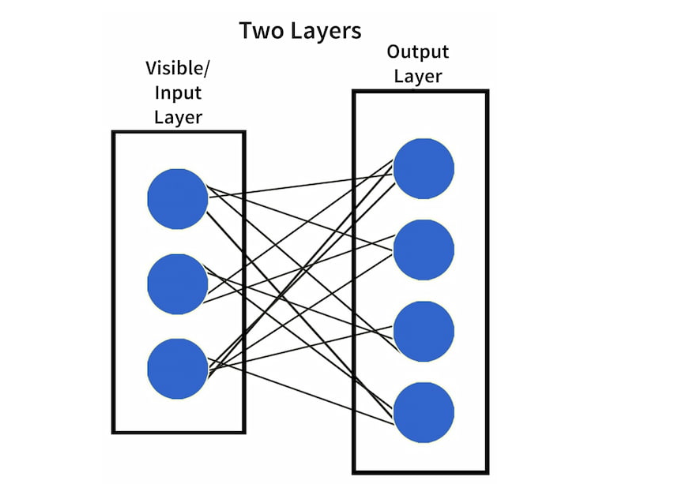
受限玻尔兹曼机
受限玻尔兹曼机 (RBM) 是无监督学习算法,具有两层神经网络,包括可见/输入层和隐藏层,没有任何层内连接——即层中没有两个节点连接,这会产生限制。RBM 用于电影推荐引擎、模式识别(例如,理解手写文本)和用于实时脉冲内识别的雷达目标识别。
图4 受限玻尔兹曼机
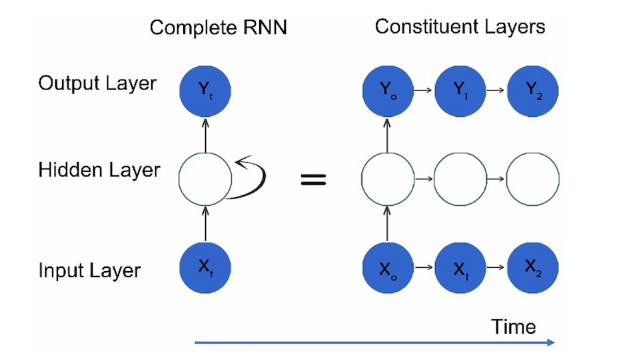
递归神经网络
循环神经网络 (RNN) 将输入视为时间序列,以生成具有至少一个连接周期的时间序列的输出。RNN 是通用逼近器:它们几乎可以逼近任何动态系统。RNN 用于时间序列分析,例如股票预测、销售预测、自然语言处理和翻译、聊天机器人、图像字幕和音乐合成。
图 6:循环神经网络
由遗忘门、输入门和输出门组成的长短期记忆 (LSTM) 有多种应用,包括时间序列预测和自然语言理解和生成。LSTM 主要用于捕获长期依赖关系。遗忘门决定是保留前一个时间戳的信息还是“忘记”它。门数量较少的不太复杂的变体形成门控循环单元(GRU)。
GRU 是 LSTM 的简化变体,其中遗忘门和输入门组合成一个更新门,单元状态和隐藏状态也组合在一起。因此,GRU 使用的内存更少,因此比 LSTM 更快。
卷积神经网络
卷积神经网络 (CNN) 在图像分类中广受欢迎。CNN 为图像中的对象分配权重和偏差以进行分类。包含像素值矩阵的图像通过卷积层、池化层和全连接 (FC) 层进行处理。池化层减小了卷积特征的空间大小。最后的输出层生成一个置信度分数,以确定图像属于定义类的可能性有多大。CNN 广泛用于 Facebook 和其他社交媒体平台来监控内容。
深度强化学习
deep RL 是深度强化学习的缩写,通过融合人工智能和强化学习的力量创造了完美的协同作用。通过强化学习是指奖励正确决策和惩罚错误决策的算法。深度强化学习的应用包括负载平衡、机器人技术、工业运营、交通控制和推荐系统。
生成对抗网络
生成对抗网络 (GAN) 使用两个神经网络、一个生成器和一个鉴别器。虽然生成器有助于生成图像、语音和视频内容,但鉴别器将它们分类为来自域或生成。这两个模型都针对零和游戏进行了训练,直到证明生成器模型产生了合理的结果。
神经网络芯片
神经网络芯片通过处理速度、存储和网络提供计算基础设施的能力,使芯片能够在大量数据上快速运行神经网络算法。网络芯片将任务分解为多个子任务,这些子任务可以同时运行到多个内核中,以提高处理速度。
人工智能加速器的类型
专门设计的 AI 加速器根据模型大小、支持的框架、可编程性、学习曲线、目标吞吐量、延迟和成本而有很大差异。此类硬件包括图形处理单元 (GPU)、视觉处理单元 (VPU)、现场可编程门阵列 (FPGA)、中央处理单元 (CPU) 和张量处理单元 (TPU)。虽然 GPU 等一些加速器更能够处理计算机图形和图像处理,但 FPGA 需要使用 VHDL 和 Verilog 等硬件描述语言 (HDL) 进行现场编程,而 Google 的 TPU 则更专门用于神经网络机器学习。让我们在下面分别查看它们以了解它们的功能。
GPU 最初是为图形处理而开发的,现在广泛用于深度学习 (DL)。它们的好处是通过以下五种架构进行并行处理:
单指令单数据 (SISD)
单指令多数据 (SIMD)
多指令单数据 (MISD)
多指令多数据 (MIMD)
单指令多线程 (SIMT)
GPU 的计算速度比 CPU 快,因为它将更多的晶体管用于数据处理,这有助于最大化具有中到大型模型和更大有效批量大小的大型数据集的内存带宽。
VPU 是优化的 DL 处理器,旨在在不影响性能的情况下实现具有超低功耗要求的计算机视觉任务。因此,VPU 通过利用预训练的 CNN 模型的力量针对深度学习推理进行了优化。
FPGA 有数千个内存单元,它们以低功耗运行并行架构。它由可重新编程的逻辑门组成,以创建自定义电路。FPGA 用于自动驾驶和自动口语识别和搜索。
具有 MIMD 架构的 CPU 在任务优化方面非常出色,更适合并行度有限的应用,例如稀疏 DNN、依赖于步骤的 RNN 以及有效批量较小的小型模型。
TPU 是 Google 定制开发的专用集成电路 (ASIC),用于加速 DL 工作负载。TPU 为大批量提供高吞吐量,适用于训练数周且以矩阵计算为主的模型。
用于深度学习推理的 AI 加速器
DL 推理需要 AI 加速器,以通过并行计算能力进行更快的计算。它们具有高带宽内存,可以在处理器之间分配比传统芯片多四到五倍的带宽。用于 DL 推理的几个领先的 AI 加速器是 AWS Inferentia,一种定制设计的 ASIC,以及开放视觉推理和神经网络优化 (OpenVINO),一种用于优化和部署 AI 推理的开源工具包。
它们都提高了执行计算机视觉、语音识别、NLP 和 NLG 等任务的深度学习性能。OpenVINO 使用在 TensorFlow、PyTorch、Caffe 和 Keras 等框架中训练的模型,并通过 CPU、GPU、VPU 和 iGPU 的加速来优化模型性能。
神经网络模型优化
深度学习模型优化用于各种场景,包括视频分析和计算机视觉。由于大多数这些计算密集型分析都是实时完成的,因此以下目标至关重要:
更快的性能
减少计算要求
优化空间使用
例如,OpenVINO 借助以下工具提供神经网络的无缝优化:
模型优化器——将模型从多个框架转换为中间表示(IR);然后可以使用 OpenVINO Runtime 完成这些操作。OpenVINO 运行时插件是软件组件,包含在 CPU、GPU 和 VPU 等硬件上进行推理的完整实现。
训练后优化工具包 (POT) – 通过 DefaultQuantization 和 AccuracyAwareQuantization 算法应用训练后自动模型量化,加快 IR 模型的推理速度。
神经网络压缩框架 (NNCF) – 与 PyTorch 和 TensorFlow 集成,通过剪枝来量化和压缩模型。常用的压缩算法有8位量化、滤波器剪枝、稀疏、混合精度量化和二值化。
结论
在当前时代,各个行业以及各个特定领域都广泛应用了人工智能。考虑到这一点,在本参考卡中,我们深入研究了 AI 算法的根源,并探索了神经网络的基础知识、DNN 的架构复杂性以及最佳性能的硬件要求。下表展示了深度神经网络在整个行业中的一些主要应用:
行业
示例
零售
自助结账
自动测量产品尺寸以优化货架图中的空间
自动补货
医疗保健
医学图像分类
癌症分布式学习环境(CANDLE)
政府预防犯罪用于物料搬运和交付的物流仓库机器人制造质量控制缺陷分类汽车自动驾驶金融服务
欺诈检测
反洗钱与风险分析
贷款处理
交易清算和结算
期权定价
随着人工智能算法复杂性的进步,超越人工智能芯片以减少建模时间/洞察时间并提高准确性变得越来越重要。由于高性能计算是一种共享资源,Kubernetes 等容器化解决方案为赋予用户更多控制权和大规模处理数据铺平了道路。伊利诺伊州的国家超级计算应用中心 (NCSA) 正在引领 AI 和 HPC 融合在从基因组图谱到自动运输等行业的应用。

版权归原作者 元宇宙MetaAI 所有, 如有侵权,请联系我们删除。