
前端关于网络安全看似高深莫测,其实来来回回就那么点东西,我总结一下就是 3 + 1 = 4,3个用字母描述的【分别是 XSS、CSRF、CORS】 + 一个中间人攻击。当然 CORS 同源策略是为了防止攻击的安全策略,其他的都是网络攻击。除了这 4 个前端相关的面试题,其他的都是一些不常用的小喽啰。
我将会在我的《面试题一网打尽》专栏中先逐一详细介绍,然后再来一篇文章总结,预计一共5篇文章,欢迎大家关注~
本篇文章是前端网络安全相关的第一篇文章,内容就是 XSS 攻击。
一、准备工作
跨站脚本攻击(cross-site scripting),为了和 css 区分所有才叫 XSS【也叫作代码注入攻击】,重点在【脚本】两个字,所以同样都是利用 script 标签,XSS 和后面说的 CSRF 还是有区别的。通过在网站注入恶意脚本,使脚本在用户的浏览器上运行,从而盗取用户的信息或者破环页面的结构。
1.1 拉取仓库
很多知识都需要结合实际的代码来学习,所以本篇文章的基础是需要一个服务端的项目,可以跟着我的这篇文章搭建自己的服务端项目。或者直接克隆我的仓库代码在这个提交上拉一个新分支,本篇文章所有的代码都是在这个提交基础上进行的。

1.2 新增 xss 文件夹
在项目的根目录增加一个 xss 文件夹,并且在 xss 下面新建 index.html 和 index.js
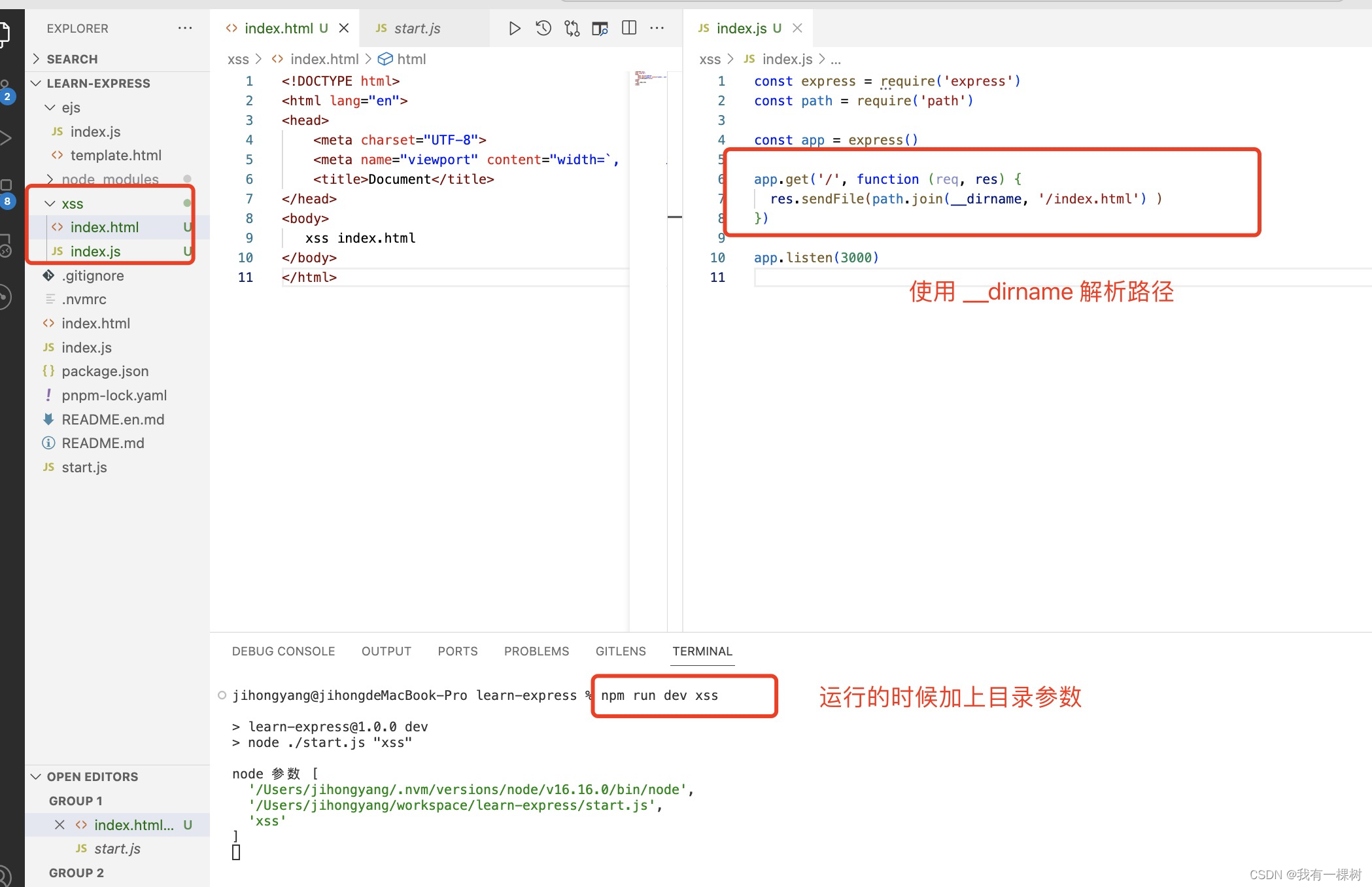
__dirname是 Node.js 中的一个特殊变量,表示当前执行脚本所在的目录的绝对路径。它是全局对象
global的属性之一,可在任何地方使用。具体可以看这个
至于运行的时候为什么加上目录参数,请看这篇文章 。
1.3 提交代码
二、攻击方式
顾名思义,xss 的攻击方式重点是脚本,就是利用 js 脚本干的一些坏事,主要的攻击方式如下:
- 利用脚本获取页面的数据,盗用 cookie、localStorage 等
- 破坏页面结构,操作 dom
- DOS 攻击,拒绝服务请求,恶意发送请求,占用服务器资源
反正 js 能干的事情都可以利用。
三、攻击类型
xss 的攻击类型分别是 存储型、反射型、DOM 型,下面开始做详细的讲解
3.1 存储型 XSS 攻击
恶意脚本由前端生成、发送并存在目标服务器上,属于服务器端漏洞,重点是:
- 这个脚本是前端某个用户写的,好好想想,肯定是这样的,服务端不会无缘无故的多出来数据;
- 服务器在接收到前端传的内容后,没有经过检查就存到数据库中
- 攻击发生在前端再一次访问存储的数据的时候
3.1.1 具体流程
- 一个用户修改一个公共【文件名】为一段脚本,如
<img src='invalid-image' onerror='alert("我是秦始皇,加v给我100万")'> - 服务器对【文件名】没有过滤(对不合法的文件名没有进行转义等处理),就保存在服务端数据库了
- 当其他用户访问这个公共【文件名】的时候就会触发攻击
- 脚本中可以获取网站的 cookie,把 cookie 数据传到黑客服务器【或者是利用脚本破坏页面结构等】
- 拿到用户 cookie 信息后,就可以利用 cookie 信息在其他机器上登录改用户的账号,并利用用户账号进行一些恶意操作
3.1.2 代码模拟
我模拟的是【破坏页面结构】的 XSS 攻击,我们再在 XSS 文件夹下新建两个文件
- data.txt 用来存数据来模拟数据库
- index2.html 用来展示第二个页面,用于访问数据库中的数据
现在我们总共有四个文件了。

系统功能描述:
- 一个公开可访问的书籍列表,一个管理员用户 1 可以在页面 1 (index.html) 修改书籍的名称;
- 一个普通用户 2, 可以在页面 2(index2.html)访问书籍列表(也就是书籍名)
(1)index.html 的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=`, initial-scale=1.0" />
<title>Document</title>
<style>
h1,h2 {
margin: 0;
}
.box {
display: inline-flex;
flex-direction: column;
}
.book-name {
margin: 10px 0;
width: 400px;
height:100px
}
.button {
width: 100px;
height: 38px;
}
</style>
</head>
<body>
<div class="box">
<h1>【首页,用户1】</h1>
<h1>设置一个公开的书籍的名称</h1>
<div>这个书籍是所用用户都可以访问的</div>
<div>修改书名:</div>
<textarea class="book-name" id="name" ></textarea>
<button class="button" onclick="saveName()">保存</button>
</div>
<script>
function saveName() {
const name = document.getElementById('name').value;
if (name) {
fetch('saveName', {
method: 'post',
headers: {
'content-type': 'application/json'
},
body: JSON.stringify({
name: name
}),
}).then(() => {
console.log('保存成功 姓名:', name)
})
}
}
</script>
</body>
</html>
(2)index2.html 的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=`, initial-scale=1.0" />
<title>Document</title>
<style>
h1,
h2 {
margin: 0;
}
.box {
display: inline-flex;
flex-direction: column;
}
.book-name {
margin: 10px 0;
width: 400px;
height: 100px;
}
.button {
width: 100px;
height: 38px;
}
</style>
</head>
<body>
<div class="box">
<h1>【另一个页面,用户2】</h1>
<h1>书籍列表页面</h1>
<div>访问公开的书籍</div>
<div>书名</div>
<div id="name"></div>
</div>
<script>
// 初始化的时候就获取数据
fetch('/getName')
.then((res) => {
return res.json();
})
.then((data) => {
const name = data.name;
const ele = document.getElementById('name');
// 设置书名
ele.innerHTML = name;
});
</script>
</body>
</html>
(3)index.js 的代码
const express = require('express');
const path = require('path');
const bodyParser = require('body-parser')
const fs = require('fs')
const app = express();
app.use(bodyParser.urlencoded({ extended: true }));
app.use(bodyParser.json());
// 首页 -> 用户1 保存数据
app.get('/', function (req, res) {
res.sendFile(path.join(__dirname, '/index.html'));
});
// 首页 -> 保存书名
app.post('/saveName', function (req, res) {
const { name } = req.body
fs.writeFileSync(path.resolve(__dirname, 'data.txt'), name)
res.send('保存成功');
});
// 新建另一个页面
app.get('/index2', function (req, res) {
res.sendFile(path.join(__dirname, '/index2.html'));
});
// 另一个页面 -> 用户2 获取数据
app.get('/getName', function (req, res) {
// 从 data.txt 中取出存储的书名
const name = fs.readFileSync(path.resolve(__dirname, 'data.txt')).toString()
console.log(name)
res.send(
JSON.stringify({
name: name,
})
);
});
app.listen(3000);
注意 xss/index.js 中关于使用 express 写服务端代码,有两个知识点
(1)post 请求需要使用 body-parser 解析 body 的 json 数据
(2)写入/读取 data.txt 是用node 的核心模块 fs,方法 fs.writeFileSync / s.readFileSync
(3)fs.readFileSync 的结果是 buffer 需要转成字符串 toString()
data.txt 里面不必输入任何内容,我们会通过代码进行写入。
(4)运行代码
npm run dev xss
访问 localhost:3000,输入一段恶意的代码作为书名,点击保存
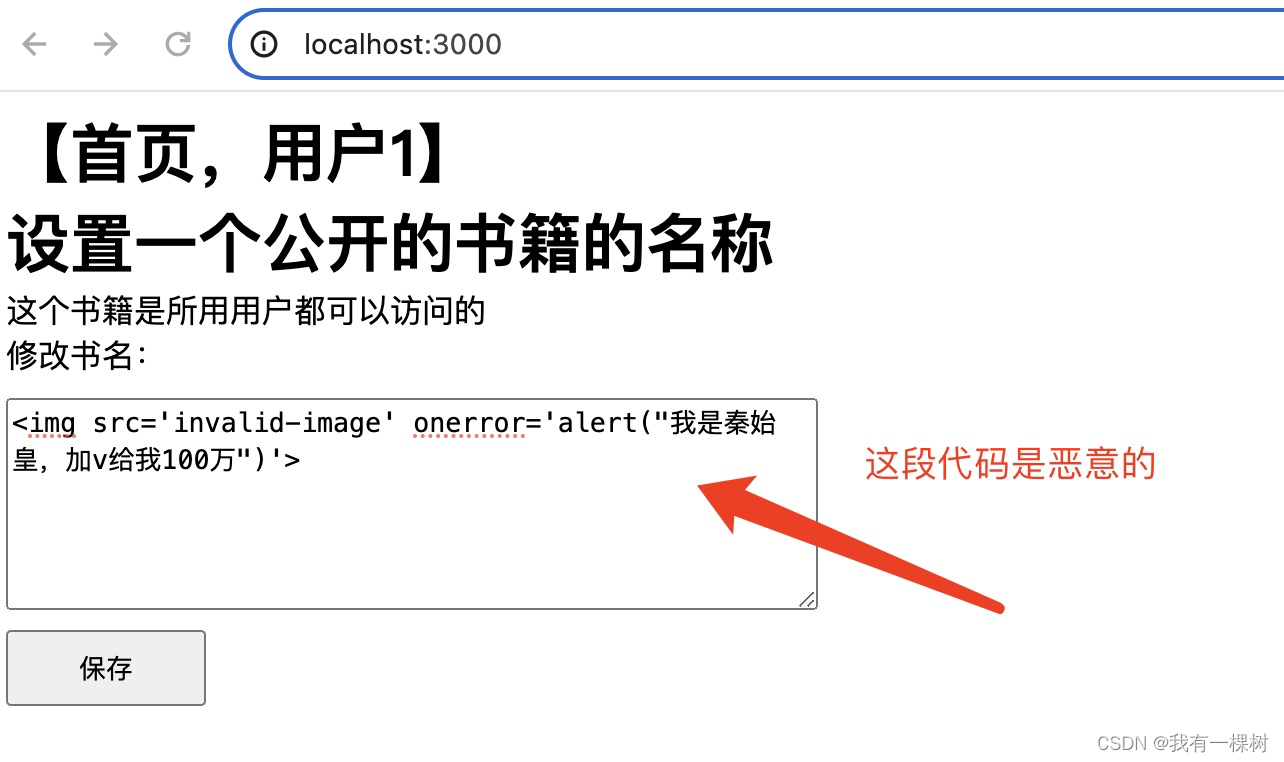
点击保存之后,输入的内容会保存在 data.txt 中

再打开 localhost:3000/index2.html,这样一个存储型的、对于 dom 结构的破环的 XSS 攻击就完成了。

这里面有一个知识点就是我们在 index.html 中保存的恶意脚本是
<img src='invalid-image' onerror='alert("我是秦始皇,加v给我100万")'>我们用了一个 img 标签,然后使用 onerror 事件里面写一些脚本,而没有这么写,为啥呢?
<script>alert(1)</script>这是因为我们在 index2.html 里面使用 innerHTML 将数据渲染在页面上,使用 innerHTML 直接渲染 script 字符串,脚本是不会被执行的。 而事件处理器,如 img 的 onerror 事件却可以触发。
(5)提交代码
3.2 反射型 XSS 攻击
恶意脚本在前端访问的 URL 中,要用户主动点击 URL,服务器解析 URL, 并返回恶意脚本,属于服务端漏洞,重点是:
- 恶意脚本不是前端用户手动写的,和存储型有区别
- 恶意脚本在 URL 上,需要用户手动点击才能触发攻击
- 服务器收到访问 URL 的请求时,解析 URL 得到恶意脚本,然后返回给客户端
- 服务器不会存储恶意脚本,只会返回(反射)它
3.2.1 具体流程
- 黑客诱导用户访问有恶意代码的 URL ,如 https://danger.com?xss=<script>alert('attack)</script>
- 服务器接收到访问 URL 的请求
- 服务器解析 URL ,得到 XSS 的值,但是并没有对 XSS 的值做校验是否合法,对于不合法的没有进行转义
- 服务器将解析后的结果,反射给浏览器,如返回 { xss : <script>alert('attack)</script> }
- 浏览器的恶意代码的 URL 页面有渲染 XSS 值的逻辑
- 此时浏览器弹出警告框
- 一个反射型 XSS 攻击就完成了
黑客经常会通过 qq群或者邮件等渠道诱导用户去点击这些恶意链接。
看到没?没事别惦记乱七八糟的连接,谨防电信诈骗!
3.2.2 代码模拟
(1)新建 xss/ index3.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div>反射型 xss 攻击</div>
<h1><a href="http://localhost:3000/reflect?xss=<script>alert('哈哈,你上当了')</script>"> 点击收款100万 </a></h1>
</body>
</html>
(2)修改 index.js
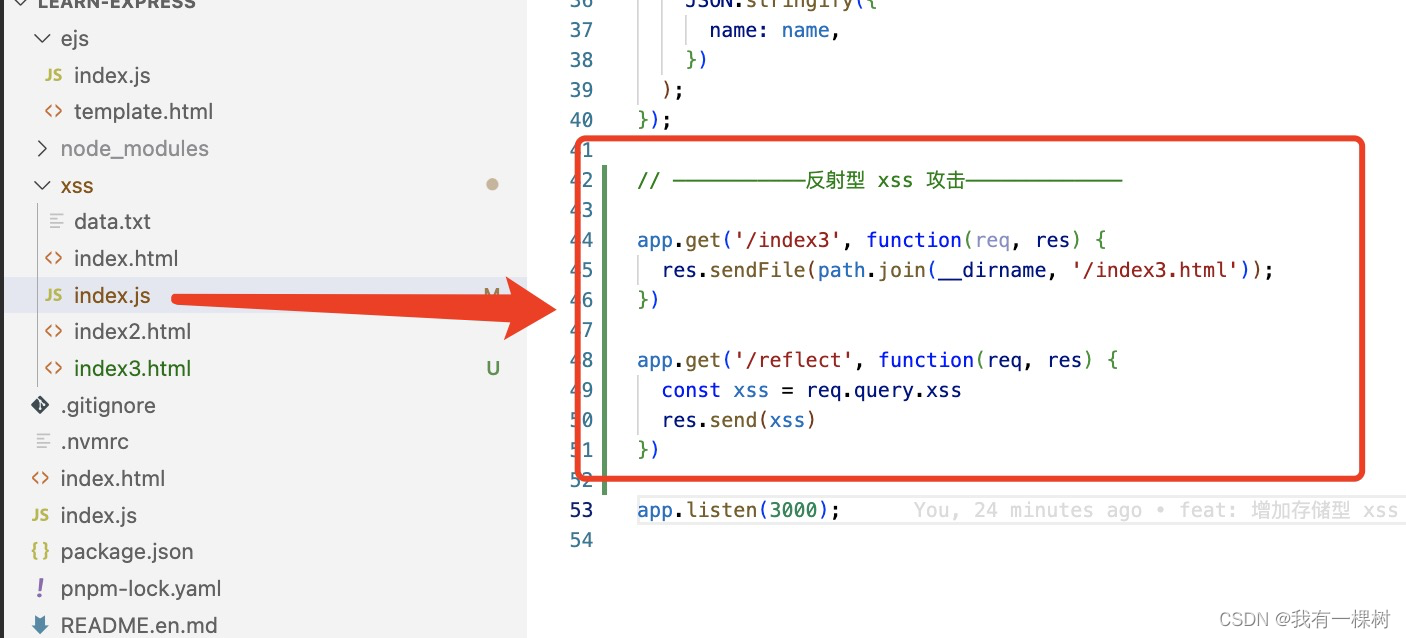
注意看这个服务端代码关于 reflect 方法的 get 请求,他就是简单的把参数上的获取并返回,浏览器就能运行这段代码。
(3)运行代码
npm run dev xss
访问 localhost:3000/index3

跳转之后发生了攻击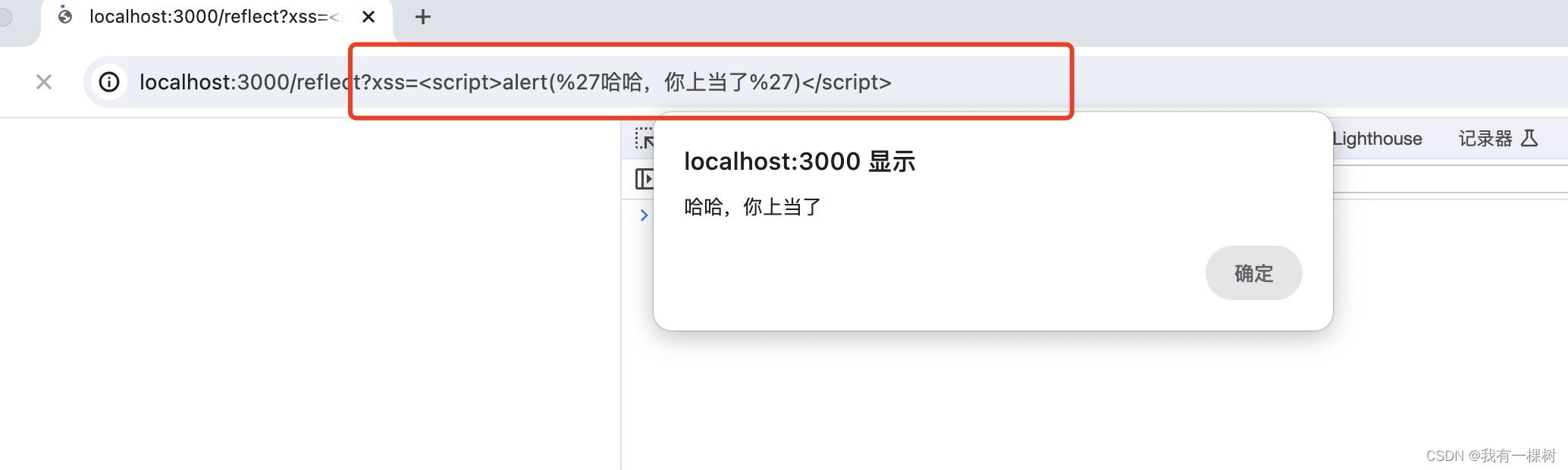
(4)提交代码
3.3 DOM 型 XSS 攻击
攻击者通过操纵 DOM 来触发攻击,是前端漏洞,不牵扯到服务器。重点是:
- 整个过程服务器不参与
- 脚本的具体来源还是利用网页中用户交互的部分, URL 参数、表单输入、cookie 等
- 多发生在使用 innerHTML 的场景
3.3.1 具体流程
- 从 URL 中取出恶意代码/或者从用户输入的表单/ cookie 中
- 把恶意代码使用 innerHTML 插入页面,改变 dom 结构
尤其是在使用 innerHTML 的时候会出现这种问题,可以使用插件如 xss-filters 避免这一类问题,这个插件的原理是将某些字符进行转义,将 < 转成 < 等
3.3.2 代码模拟
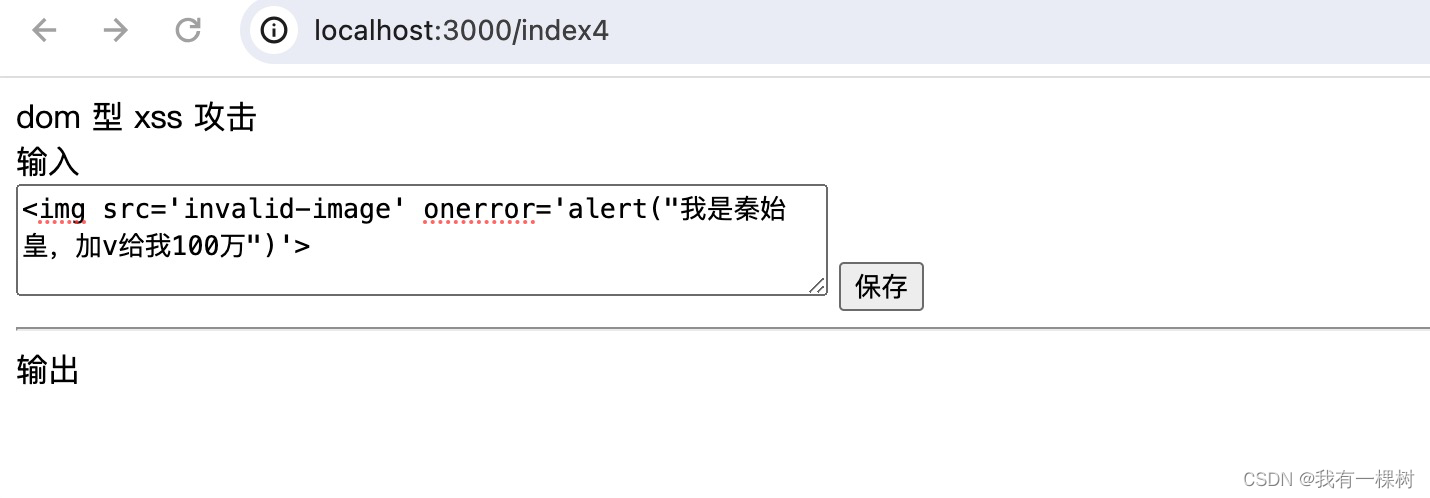
(1)新增 index4.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=<device-width>, initial-scale=1.0">
<title>Document</title>
<style>
textarea {
width: 400px;
height: 50px;
}
</style>
</head>
<body>
<h1>dom 型 xss 攻击</h1>
<div>输入</div>
<textarea id="input"></textarea>
<button onclick="save()">保存</button>
<hr>
<div>输出</div>
<div id="output"></div>
<script>
function save() {
const text = document.getElementById('input').value
if (text) {
const output = document.getElementById('output')
output.innerHTML = text
}
}
</script>
</body>
</html>
(2)修改 xss/index.js

(3)运行代码
npm run dev xss
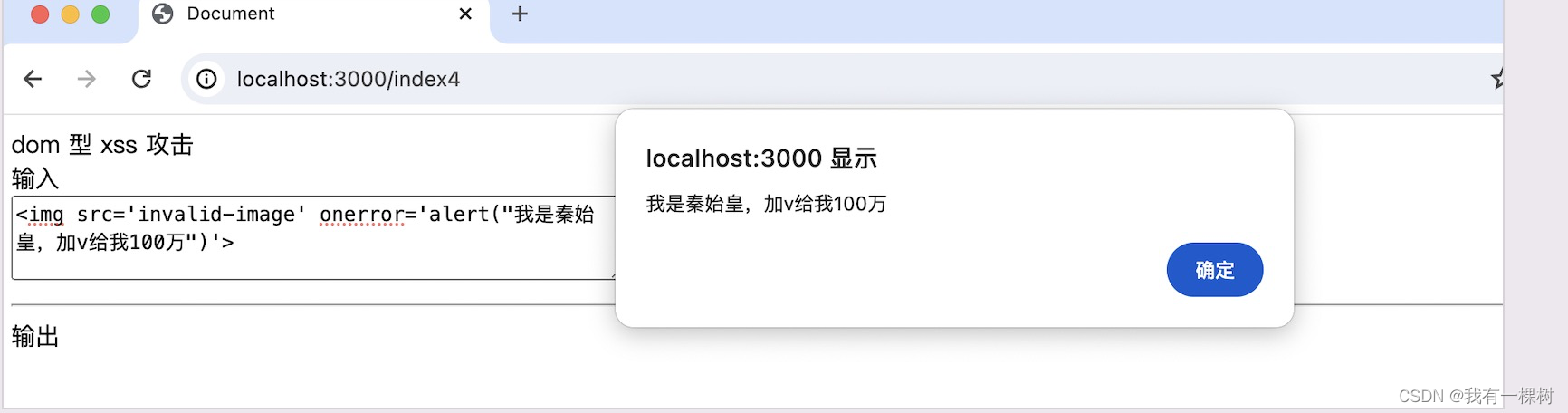
 点击保存按钮之后,就出现攻击了。
点击保存按钮之后,就出现攻击了。
注意,这全程没有服务端的参与,但是我们还是修改 index.js 。但是其实 index.js 里面的代码就是为了起一个服务运行 index4.html 而已, 应该很好理解吧。
(4)提交代码
好了至此三种类型的 XSS 攻击我们都用代码的形式实现。一点都不难吧,光说不练假把式,如果只看理论知识,肯定云里雾里,你跟着一起写一遍代码就理解了,不用背诵就记下来了。

3.4 XSS 攻击防御方法
- 不使用服务端渲染,前两种是服务端的安全漏洞,服务器不能信任前端输入的任何东西,服务端要对输入脚本进行过滤或者转码。<script> 标签被转换为 <script> ,注意,https 不能防止安全问题,只会增加攻击难度和成本;
- 对于 dom 型,对要插入的 html 做好充分的转义, npm 包:xss-filters;
- 使用内容安全策略,csp 建立白名单,告诉浏览器可以执行和加载哪些功能 Content-Security-Policy 服务端设置【设置 csp 有两种方式 http 头部、meta 标签】
- x-content-type-options\x-frame-options\x-xss-protentcion 等httip头部设置
- 敏感信息 cookie 设置 httpOnly
总结
xss 攻击的三种类型都用代码模拟了,我的仓库地址如下,欢迎查看
yangjihong2113/learn-express
内容较多,难免疏漏,如有问题,欢迎指正。
这是一系列的文章,关于网络安全的内容还有 CSRF、CORS 和中间人攻击的内容没有总结,持续更新中,欢迎关注。
版权归原作者 我有一棵树 所有, 如有侵权,请联系我们删除。