
Hive SQL-DML-insert插入数据


1. 插入静态数据
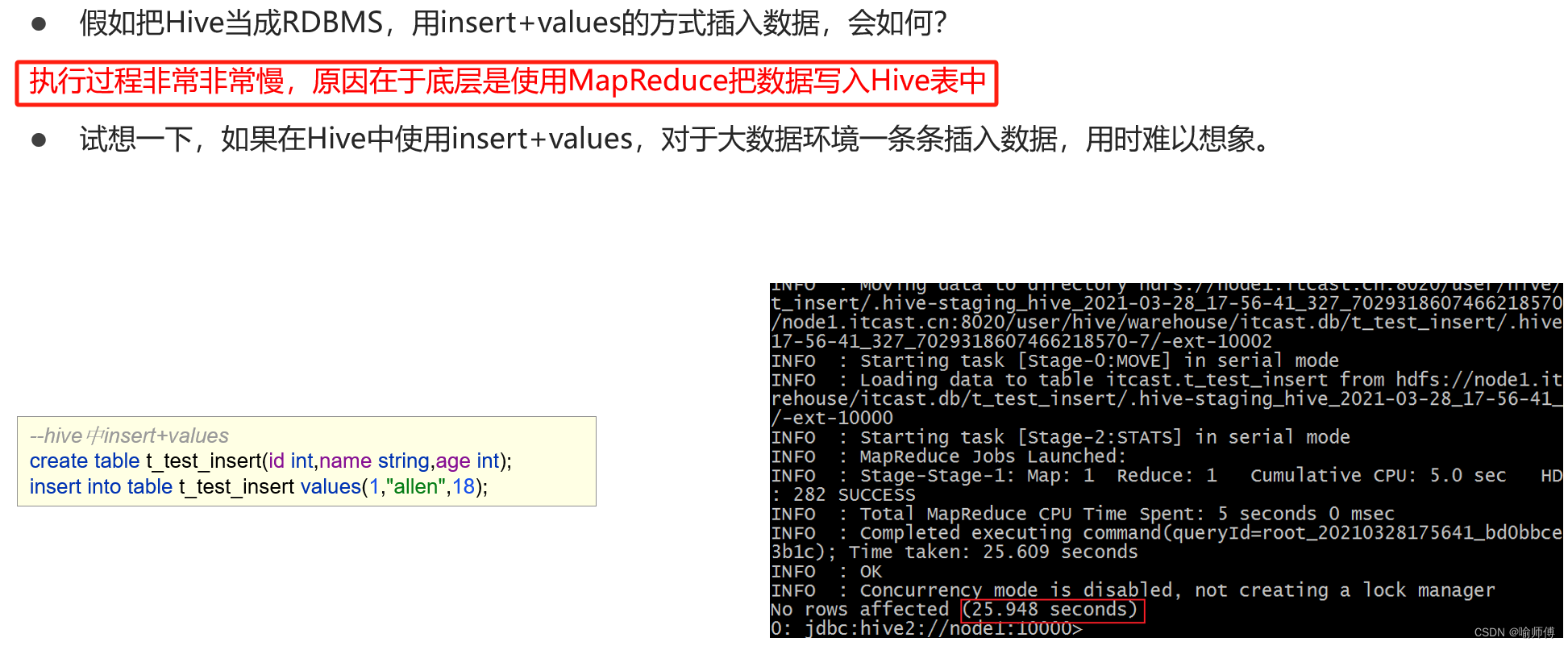
可以直接插入具体的值到Hive表中:
INSERTINTOTABLE tablename (column1, column2, column3)VALUES(value1, value2, value3),(value4, value5, value6),...;
2. 插入查询结果

将一条查询的结果直接插入到另一个表中。这是一种很常见的操作,用于数据转移和转换:
INSERTINTOTABLE tablename
SELECT column1, column2, column3
FROM othertable
WHERE condition;
3. 多重插入和静态分区插入

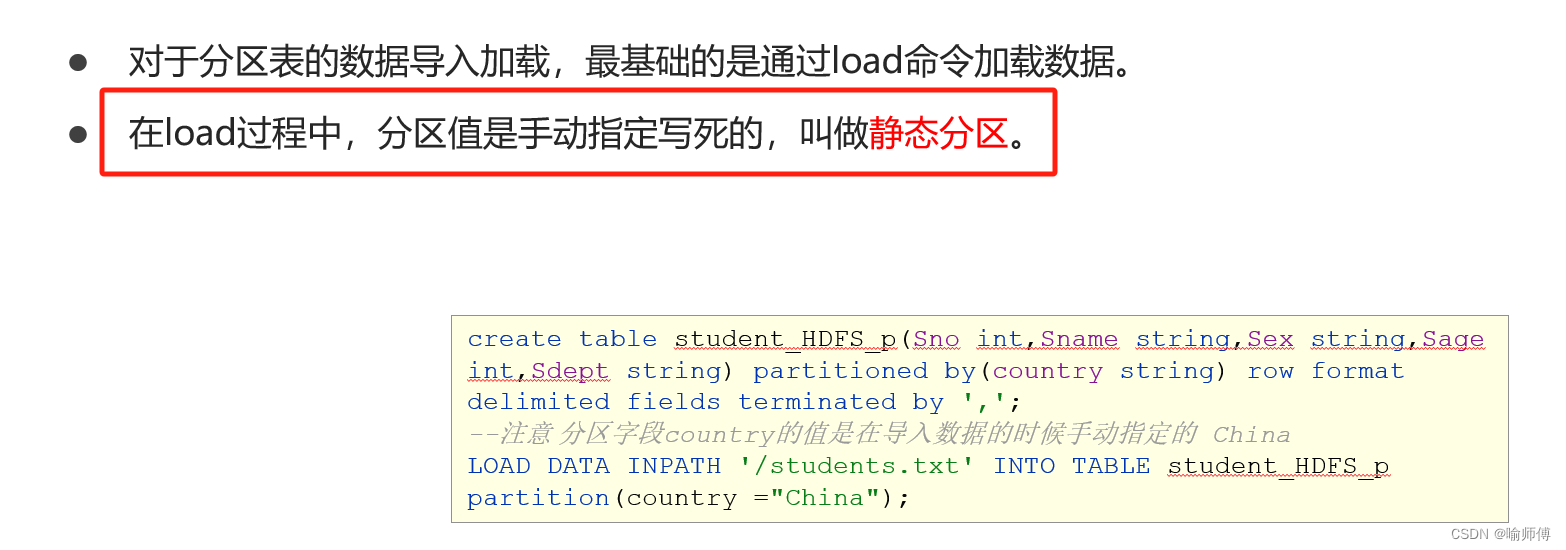
对于分区表,可以在插入时指定分区。这不仅可以提高查询效率,而且还能更好地管理数据:
-- 插入到指定分区INSERTINTOTABLE tablename PARTITION(partition_column='partition_value')SELECT column1, column2, column3
FROM othertable
WHERE condition;
-- 插入不同分区的数据FROM from_table
INSERTINTOTABLE tablename PARTITION(partition1)SELECT column1, column2 WHERE condition1
INSERTINTOTABLE tablename PARTITION(partition2)SELECT column1, column2 WHERE condition2;
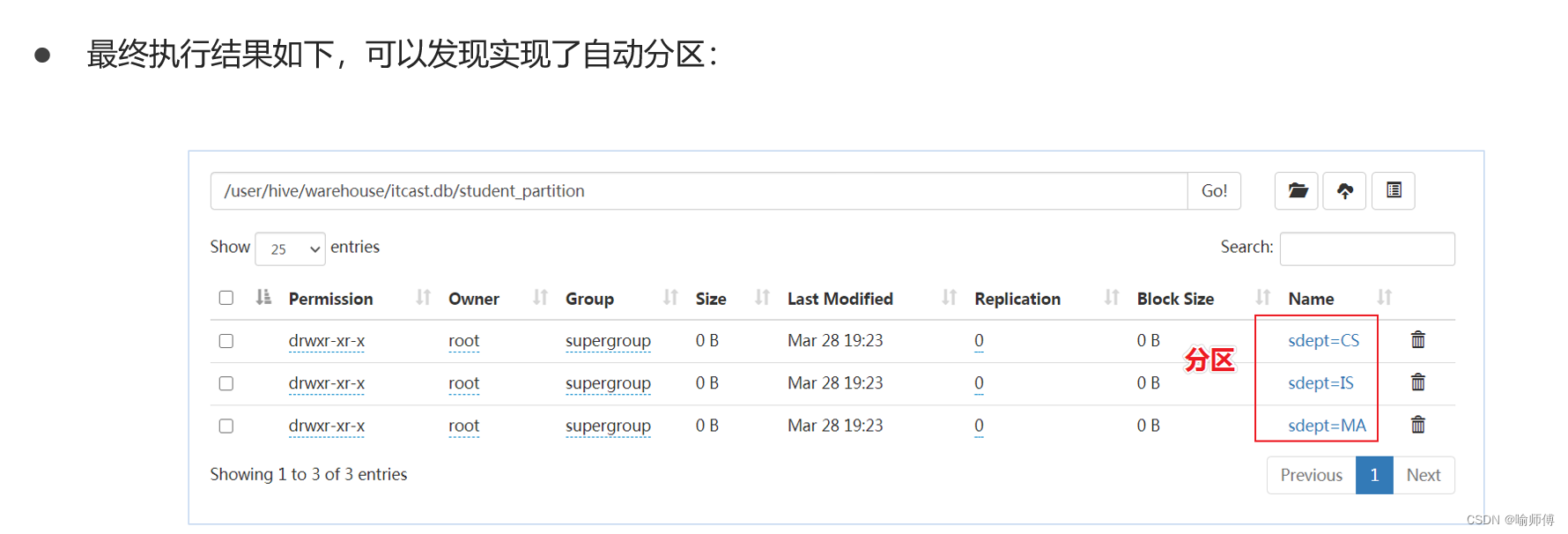
4. 动态分区插入



Hive还支持在执行
INSERT
操作时动态创建分区。这需要设置一些配置参数,如启用动态分区:
SET hive.exec.dynamic.partition=true;SET hive.exec.dynamic.partition.mode=nonstrict;INSERTINTOTABLE tablename PARTITION(partition_column)SELECT column1, column2, partition_column
FROM othertable;


5.导出数据
导出数据是从 Hive 中提取数据的过程,通常用于将数据转移到本地文件系统、HDFS 或其他数据存储中。
INSERT OVERWRITE
用于将查询结果或表数据写入到特定的输出位置。可以将数据导出到 HDFS 或本地文件系统。这个方法支持多种文件格式,如 Text、Parquet、ORC 等。
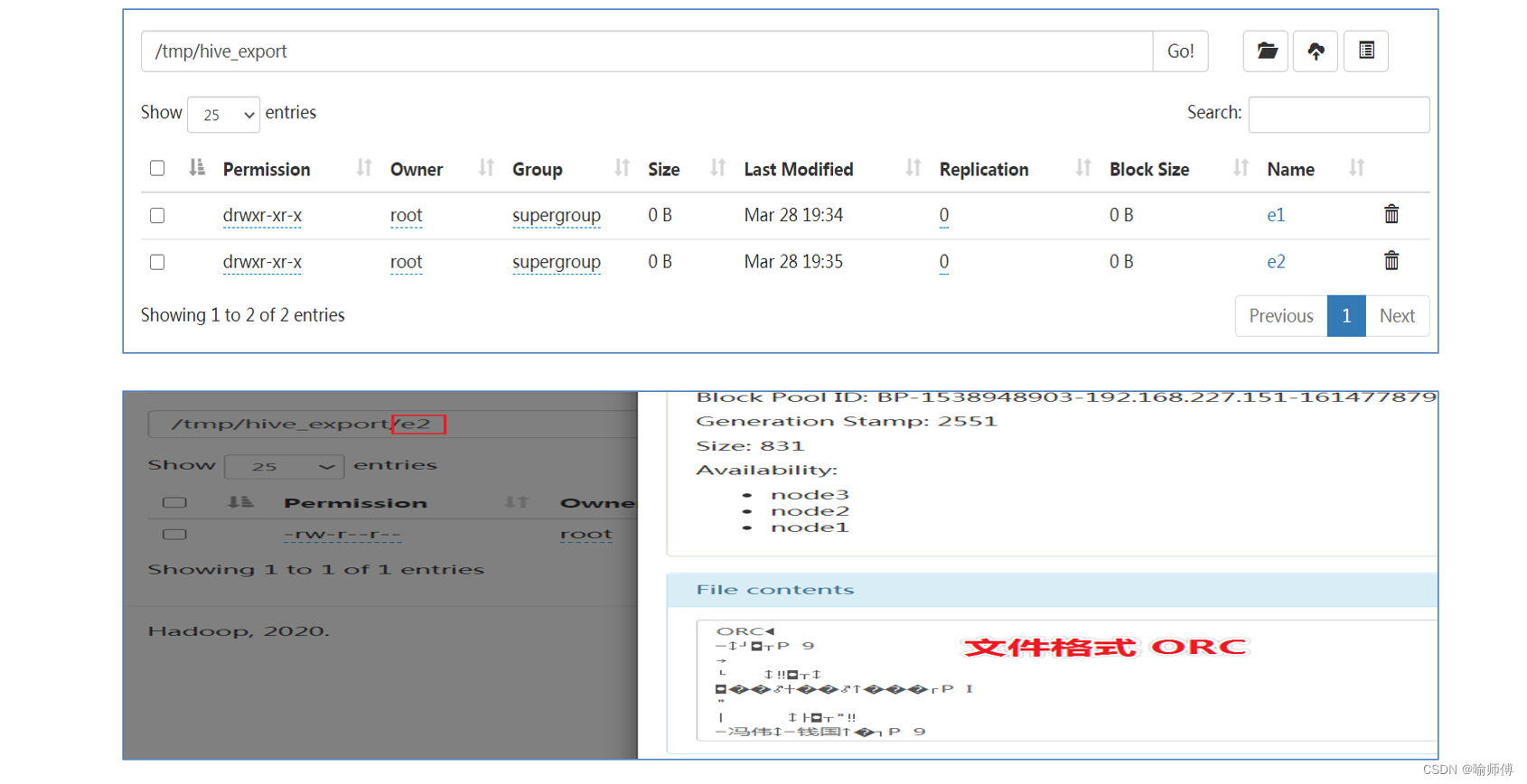
- 导出到 HDFS:
INSERT OVERWRITE DIRECTORY '/path/to/hdfs/directory'SELECT*FROM my_table; - 导出到本地文件系统:
INSERT OVERWRITE LOCAL DIRECTORY '/path/to/local/directory'SELECT*FROM my_table;
在这两个示例中,数据将被导出到指定的 HDFS 或本地路径。默认情况下,数据以文本格式输出,但可以通过
STORED AS
选项指定不同的文件格式。


示例:
6.注意事项
- Hive中的
INSERT操作本质上是对文件的写操作。特别是在HDFS中,这意味着每次INSERT都会生成新文件。这可能会影响性能,特别是在大量小批量插入时。 - 建议在执行大批量数据插入前调优Hive配置和考虑合适的文件格式和压缩机制。
- 在执行大数据量的插入时,需要注意Hive服务器和Hadoop集群的资源配置,以避免过载。
本文转载自: https://blog.csdn.net/weixin_48935611/article/details/138560351
版权归原作者 喻师傅 所有, 如有侵权,请联系我们删除。
版权归原作者 喻师傅 所有, 如有侵权,请联系我们删除。