
一、JPA的概述
JPA的全称是Java Persisitence API,即JAVA持久化API,是sum公司退出的一套基于ORM的规范,内部是由一些列的接口和抽象类构成。JPA通过JDK5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中。
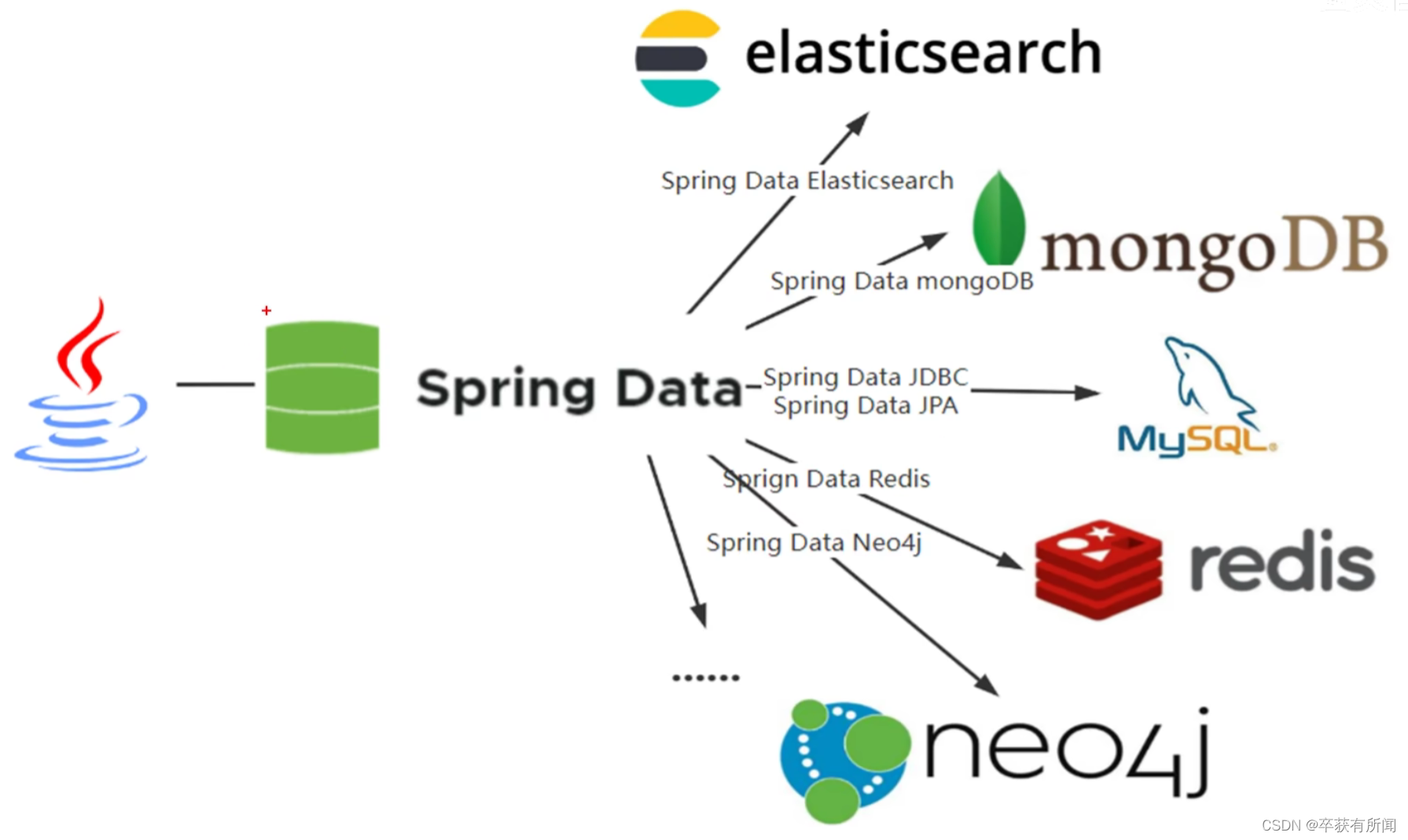
Spring Data的优势:可以操作多种数据库,关系型数据库,非关系型数据库都可以,他就是为数据访问DAO提供熟悉且一致的基于spring的编程模板
1、JPA的优势
1、标准化
JPA是JCP组织发布的javaEE标准之一,因此任何声称符合JPA标准的框架都遵循同样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能在不同的JPA框架下运行。
2、容器级特性的支持
JPA框架中支持大数据集、事务、并发等容器级事务,使得JPA超越了简单持久化框架的局限,在企业应用发挥更大的作用。
3、简单方便
JPA主要目标就是提供更加简单的编程模型:在JPA框架下创建实体和创建Java类一样简单,没有任何的约束和限制,只需要使用javax.persistence.Entity进行注解,JPA框架和接口也非常简单,没太多特别的规则和设计要求,开发者可以很容易掌握,JPA基于非侵入式原则设计,因此可以很容易和其他框架或容器集成
4、查询能力
JPA的查询语言是面向对象而非面向数据的,它3以3面向对象的自然语法构造查询语句,可以看成是Hibernate HQL的等价物,JPA定义了独特的JPQL,它是针对实体的一种查询语言,操作对象是实体,而不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING等通常只有SQL才能提供的高级查询特性,甚至还能支持子查询
5、高级特性
JPA支持面向对象的高级特性,如类之间的继承、多台和类之间的复杂关系,这样的支持能够让开发放着最大限制的使用面向对象的模型设计企业应用,而不需要自行处理这些特性在关系数据库的持久化。
2、JPA和Hibernate关系
JPA规范本质上就是一种ORM规范,注意不是ORM框架,因为API并未提供ORM实现,只是指定了一些规范,提供了一些编程API接口,但具实现则是服务厂商来实现
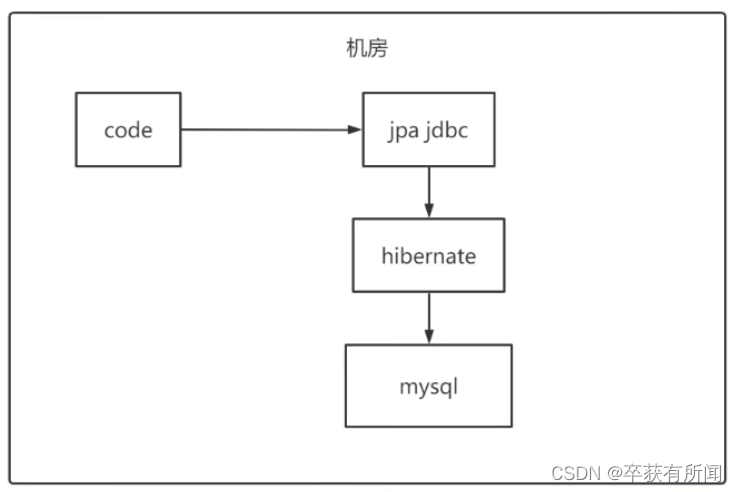
JPA和Hibernate的关系就像JDBC和JDBC驱动的关系,JPA是规范,Hibernate除了作为ORM框架之外,他也是一种JPA实现,JPA怎么取代Hibernate呢?Jdbc规范可以驱动底层数据吗?不行,如果使用jpa规范进行数据库操作,底层需要hibernate作为实现完成数据持久化工作。
二、快速入门
1、配置数据源
这里用的yml方式,里面的jpa就是数据库的名称,大家也可以写其他的,前提是这个数据库存在,用户名和密码写自己的就好。
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/jpa?serverTimezone=UTC
username: root
password: 123456
2、导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version>
</dependency>
3、创建实体类
通过注解方式让数据库知道我们的表长什么样
这里就可以知道表的名称是users(当然你可以任意取名),表的创建一般都有主键和自增操作,这里全部通过注解来完成。这里第一次创建表的时候表名会爆红,我们需要给他手动指定数据库,也就是数据源配置时的数据库
import lombok.Data;
import javax.persistence.*;
@Data
@Entity //这是实体类
@Table(name = "user") //对应哪张表
public class User {
@Id //这是主键
@Column(name = "id")//数据库中的id,对应属性中的id
@GeneratedValue(strategy = GenerationType.IDENTITY) //
int id;
@Column(name = "username")//数据库中的username,对应属性中的username
String username;
@Column(name = "password")//数据库中的password,对应属性中的password
String password;
}
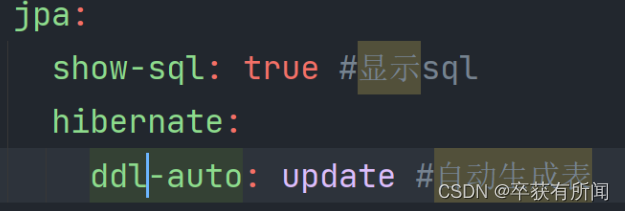
这里我们还需要设置自动表定义ddl-auto,可以自己生成表不用开发人员自己建表了
spring:
jpa:
show-sql: true #显示sql
hibernate:
ddl-auto: create #自动生成表
ddl-auto属性用于设置自动表定义,可以实现自动在数据库中为我们创建一个表,表的结构会根据我们定义的实体类决定,它有4种
- create 启动时删数据库中的表,然后创建,退出时不删除数据表
- create-drop 启动时删数据库中的表,然后创建,退出时删除数据表 如果表不存在报错
- update 如果启动时表格式不一致则更新表,原有数据保留
- validate 项目启动表结构进行校验 如果不一致则报错
4、启动测试类完成表创建
这时候可以看到控制台打印这两句话,就会发现表已经创建成功了(和我们自己去敲命令行十分类似,hibernate帮我们完成这些操作,是不是很方便) 删表是因为选择了create策略创建表,后面还会讲其他的策略。

5、访问我们的表
第一个泛型填实体类,第二个是id的类型
@Repository
public interface UserRepository extends JpaRepository<User,Integer> {
}
当我们想用的时候:
@SpringBootTest
class YdljpaApplicationTests {
@Autowired
UserRepository userRepository;
@Test
public void testQuery(){
userRepository.findById(1).ifPresent(System.out::println);
}
}
这里需要注意把create策略改成update,因为create策略会删表中数据
增操作
@Test
public void testAdd(){
User user=new User();
//user.setId(2);
user.setUsername("itnanls");
user.setPassword("ydl666");
User saveUser = userRepository.save(user); //新增 返回的实体中带着实体id
System.out.println(saveUser);
}
删操作
@Test
public void testDel(){
userRepository.deleteById(3);
}
分页操作
@Test
public void testPageable(){
userRepository.findAll(PageRequest.of(0,2)).forEach(System.out::println);
}
三、方法命名规则查询
顾名思义,方法命名规则查询就是根据方法的名字,就能创建查询。只需要按照Spring Data JPA提供的方法命名规则定义方法的名称,就可以完成查询工作。Spring Data JPA在程序执行的时候会根据方法名称进行解析,并自动生成查询语句进行查询.
按照Spring Data JPA 定义的规则,查询方法以findBy开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
@Repository
public interface UserRepository extends JpaRepository<User,Integer> {
//根据username查询
List<User> findAllByUsername(String str);
//根据用户名和密码查询
List<User> findByUsernameAndPassword(String username,String password);
//根据用户名模糊查询
List<User> findByUsernameLike(String username);
}
具体的关键字,使用方法和生产成SQL如下表所示
KeywordSampleJPQLAndfindByLastnameAndFirstname… where x.lastname = ?1 and x.firstname = ?2OrfindByLastnameOrFirstname… where x.lastname = ?1 or x.firstname = ?2Is,EqualsfindByFirstnameIs,findByFirstnameEquals… where x.firstname = ?1BetweenfindByStartDateBetween… where x.startDate between ?1 and ?2LessThanfindByAgeLessThan… where x.age < ?1LessThanEqualfindByAgeLessThanEqual… where x.age ⇐ ?1GreaterThanfindByAgeGreaterThan… where x.age > ?1GreaterThanEqualfindByAgeGreaterThanEqual… where x.age >= ?1AfterfindByStartDateAfter… where x.startDate > ?1BeforefindByStartDateBefore… where x.startDate < ?1IsNullfindByAgeIsNull… where x.age is nullIsNotNull,NotNullfindByAge(Is)NotNull… where x.age not nullLikefindByFirstnameLike… where x.firstname like ?1NotLikefindByFirstnameNotLike… where x.firstname not like ?1StartingWithfindByFirstnameStartingWith… where x.firstname like ?1 (parameter bound with appended %)EndingWithfindByFirstnameEndingWith… where x.firstname like ?1 (parameter bound with prepended %)ContainingfindByFirstnameContaining… where x.firstname like ?1 (parameter bound wrapped in %)OrderByfindByAgeOrderByLastnameDesc… where x.age = ?1 order by x.lastname descNotfindByLastnameNot… where x.lastname <> ?1InfindByAgeIn(Collection ages)… where x.age in ?1NotInfindByAgeNotIn(Collection age)… where x.age not in ?1TRUEfindByActiveTrue()… where x.active = trueFALSEfindByActiveFalse()… where x.active = falseIgnoreCasefindByFirstnameIgnoreCase… where UPPER(x.firstame) = UPPER(?1)
四、使用JPQL的方式查询
使用Spring Data JPA提供的查询方法已经可以解决大部分的应用场景,但是对于某些业务来说,我们还需要灵活的构造查询条件,这时就可以使用@Query注解,结合JPQL的语句方式完成查询。
@Query 注解的使用非常简单,只需在方法上面标注该注解,同时提供一个JPQL查询语句即可,注意:
- 大多数情况下将*替换为别名
- 表名改为类名
- 字段名改为属性名
- 搭配注解@Query进行使用
@Query("select 表别名 from 表名(实际为类名) 别名 where 别名.属性='itlils'")
public List<User> findUsers();
最简单的查询
注意是面向对象的查询,所以from的不是表,而且User对象
@Query("select u from User u")//从实体类,查询,而不是表
List<User> findAllUser();
筛选条件
@Query("select u from User u where u.username='itlils'")//从实体类,查询,而不是表。where不是列名,而是属性名
List<User> findAllUserByUsername();
投影结果
@Query("select u.id from User u")//从实体类,查询,而不是表
List<Integer> findAllUser2();
聚合查询
@Query("select count(u) from User u")//从实体类,查询,而不是表
List<Integer> findAllUser4();
传参
//修改数据 一定加上@Modifying 注解
@Transactional
@Modifying
@Query("update User set username=?1 where id=?2")
int updateUsernameById2(String username,Integer id);
使用原生sql
使用原生的sql需要在sql语句后面加上 nativeQuery = true
//修改数据 一定加上@Modifying 注解
@Transactional
@Modifying
@Query(value = "update user u set u.username=?1 where u.id=?2",nativeQuery = true)
int updateUsernameById3(String username,Integer id);
五、一对一关系
我们用账号表和账号详细表来举例
@Data
@Entity //表示这个类是一个实体类
@Table(name = "account") //对应的数据库中表名称
public class Account {
@GeneratedValue(strategy = GenerationType.IDENTITY) //生成策略,这里配置为自增
@Column(name = "id") //对应表中id这一列
@Id //此属性为主键
int id;
@Column(name = "username") //对应表中username这一列
String username;
@Column(name = "password") //对应表中password这一列
String password;
//一对一
@JoinColumn(name = "detail_id")
@OneToOne//声明为一对一关系
AccountDetail detail;//对象类型,也可以理解这里写哪个实体类,外键就指向哪个实体类的主键
}
@Data
@Entity
@Table(name = "account_details")
public class AccountDetail {
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)//还是设置一个自增主键
@Id
int id;
@Column(name = "address")
String address;
@Column(name = "email")
String email;
@Column(name = "phone")
String phone;
@Column(name = "real_name")
String realName;
}
这里从日志中可以看出hibernate帮我们完成外键的创建
但这还不能完成同时对两张表进行操作 设置懒加载完成想查什么就查什么功能,设置关联级别完成同时操作两张表
@JoinColumn(name = "detail_id")
@OneToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL) //设置关联操作为ALL
AccountDetail detail;
这里的关联级别也是有多个,一般设置为all就行
- ALL:所有操作都进行关联操作
- PERSIST:插入操作时才进行关联操作
- REMOVE:删除操作时才进行关联操作
- MERGE:修改操作时才进行关联操作
现在我们就可以同时添加数据和删除了
@Autowired
AccountRepository accountRepository;
@Test
public void testFind11() {
Account account=new Account();
account.setUsername("itlils");
account.setPassword("ydl666");
AccountDetail accountDetail=new AccountDetail();
accountDetail.setPhone("13000000000");
accountDetail.setRealName("itlils");
accountDetail.setAddress("cn");
accountDetail.setEmail("[email protected]");
account.setDetail(accountDetail);
Account save = accountRepository.save(account);
System.out.println("插入之后account id为:"+save.getId()+"|||accountDetail id"+save.getDetail().getId());
}
六、一对多的关系
我们用作者和文章来举例,一对多的情况,肯定是在多的地方有个字段来标识是那个作者
Author 和 Article 是一对多关系(双向)。那么在JPA中,如何表示一对多的双向关联呢?
JPA用@OneToMany和@ManyToOne来标识一对多的双向关联。一端(Author)使用@OneToMany,多端(Article)使用@ManyToOne。
在JPA规范中,一对多的双向关系由多端(Article)来维护。就是说多端(Article)为关系维护端,负责关系的增删改查。一端(Author)则为关系被维护端,不能维护关系。
一端(Author)使用@OneToMany注释的mappedBy="author"属性表明Author是关系被维护端。
多端(Article)使用@ManyToOne和@JoinColumn来注释属性 author,@ManyToOne表明Article是多端,@JoinColumn设置在article表中的关联字段(外键)。
@Data
@Entity //表示这个类是一个实体类
@Table(name = "author") //对应的数据库中表名称
public class Author {
@Column(name = "id")
@Id // 主键
@GeneratedValue(strategy = GenerationType.IDENTITY) // 自增长策略
private Long id; //id
@Column(nullable = false, length = 20,name = "name")
private String name;//姓名
@OneToMany(mappedBy = "author",cascade=CascadeType.ALL,fetch=FetchType.LAZY)
//级联保存、更新、删除、刷新;延迟加载。当删除用户,会级联删除该用户的所有文章
//拥有mappedBy注解的实体类为关系被维护端
//mappedBy="author"中的author是Article中的author属性
private List<Article> articleList;//文章列表
}
@Data
@Entity //表示这个类是一个实体类
@Table(name = "article") //对应的数据库中表名称
public class Article {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 自增长策略
@Column(name = "id", nullable = false)
private Long id;
@Column(nullable = false, length = 50) // 映射为字段,值不能为空
private String title;
@Lob // 大对象,映射 MySQL 的 Long Text 类型
@Basic(fetch = FetchType.LAZY) // 懒加载
@Column(nullable = false) // 映射为字段,值不能为空
private String content;//文章全文内容
@ManyToOne(cascade={CascadeType.MERGE,CascadeType.REFRESH},optional=false)//可选属性optional=false,表示author不能为空。删除文章,不影响用户
@JoinColumn(name="author_id")//设置在article表中的关联字段(外键)
private Author author;//所属作者
}
新增
@Autowired
AuthorRepository authorRepository;
@Autowired
ArticleRepository articleRepository;
@Test
public void testFind13() {
Author author=new Author();
author.setName("itlils");
Author author1 = authorRepository.save(author);
Article article1=new Article();
article1.setTitle("1");
article1.setContent("123");
article1.setAuthor(author1);
articleRepository.save(article1);
Article article2=new Article();
article2.setTitle("2");
article2.setContent("22222");
article2.setAuthor(author1);
articleRepository.save(article2);
}
删除
@Test
public void testFind14() {
articleRepository.deleteById(2L);
}
查询
@Transactional
@Test
public void testFind15() {
Optional<Author> byId = authorRepository.findById(1L);
if (byId.isPresent()){
Author author = byId.get();
List<Article> articleList = author.getArticleList();
System.out.println(articleList);
}
}
注意点:
懒加载会导致不能显示出作者,我们只需要把:作者 fetch=FetchType.EAGER,把懒加载取消掉就可以了
但是还会出现有个循环依赖的问题,tostring文章的时候需要有作者,作者的又要文章的,解决方案:循环toString 破坏一方的toString即可。文章加上@ToString(exclude = {"author"})
七、多对多的关系
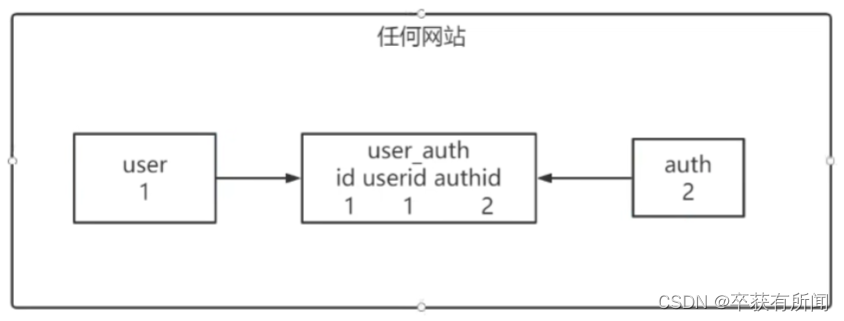
用户和权限,一个权限可以有多个用户,一个用户又可以有多个权限。这种多对多要怎么处理呢,这个时候需要一个中间关联表来做。
JPA使用@ManyToMany来注解多对多的关系,由一个关联表来维护。这个关联表的表名默认是:主表名+下划线+从表名。(主表是指关系维护端对应的表,从表指关系被维护端对应的表)。这个关联表只有两个外键字段,分别指向主表ID和从表ID。字段的名称默认为:主表名+下划线+主表中的主键列名,从表名+下划线+从表中的主键列名。
需要注意的:
1、多对多关系中一般不设置级联保存、级联删除、级联更新等操作。
2、可以随意指定一方为关系维护端,在这个例子中,我指定 User 为关系维护端,所以生成的关联表名称为: user_authority,关联表的字段为:user_id 和 authority_id。
3、多对多关系的绑定由关系维护端来完成,即由 User.setAuthorities(authorities) 来绑定多对多的关系。关系被维护端不能绑定关系,即User不能绑定关系。
4、多对多关系的解除由关系维护端来完成,即由Authority.getUser().remove(user)来解除多对多的关系。关系被维护端不能解除关系,即Authority不能解除关系。
5、如果 User 和 Authority 已经绑定了多对多的关系,那么不能直接删除 Authority,需要由 User 解除关系后,才能删除 Authority。但是可以直接删除 User,因为 User 是关系维护端,删除 User 时,会先解除 User 和 Authority 的关系,再删除 Authority。
@Data
@Entity //这是实体类
@Table(name = "users") //对应哪张表
public class Users {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false, length = 20, unique = true)
private String username; // 用户账号,用户登录时的唯一标识
@Column(length = 100)
private String password; // 登录时密码
@ManyToMany
@JoinTable(name = "user_authority",joinColumns = @JoinColumn(name = "user_id"),
inverseJoinColumns = @JoinColumn(name = "authority_id"))
//1、关系维护端,负责多对多关系的绑定和解除
//2、@JoinTable注解的name属性指定关联表的名字,joinColumns指定外键的名字,关联到关系维护端(User)
//3、inverseJoinColumns指定外键的名字,要关联的关系被维护端(Authority)
//4、其实可以不使用@JoinTable注解,默认生成的关联表名称为主表表名+下划线+从表表名,
//即表名为user_authority
//关联到主表的外键名:主表名+下划线+主表中的主键列名,即user_id
//关联到从表的外键名:主表中用于关联的属性名+下划线+从表的主键列名,即authority_id
//主表就是关系维护端对应的表,从表就是关系被维护端对应的表
private List<Authority> authorityList;
}
@Data
@Entity //这是实体类
@Table(name = "authority") //对应哪张表
public class Authority {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(nullable = false)
private String name; //权限名
@ManyToMany(mappedBy = "authorityList")
private List<Users> userList;
}
添加
@Autowired
private UsersRepository usersRepository;
@Autowired
private AuthorityRepository authorityRepository;
@Test
public void testFind16() {
Authority authority = new Authority();
authority.setId(1);
authority.setName("ROLE_ADMIN");
authorityRepository.save(authority);
}
@Test
public void testFind17() {
Users users = new Users();
users.setUsername("itlils");
users.setPassword("123456");
Authority authority = authorityRepository.findById(1).get();
List<Authority> authorityList = new ArrayList<>();
authorityList.add(authority);
users.setAuthorityList(authorityList);
usersRepository.save(users);
}
先运行 saveAuthority 添加一条权限记录,
然后运行 saveUser 添加一条用户记录,与此同时,user_authority 表中也自动插入了一条记录
删除
@Test
public void testFind18() {
usersRepository.deleteById(1L);
}
user 表中删除一条记录,同时 user_authority 能够级联删除一条记录,中间表和users表数据都删除了
版权归原作者 卒获有所闻 所有, 如有侵权,请联系我们删除。