
最近一些人问我怎么在BPU上部署yolov5,因为之前的博客[BPU部署教程] 一文带你轻松走出模型部署新手村介绍的网络都是基于Caffe的,自己的网络都是基于pytorch的,所以遇到了很多坑。鉴于这些需求,我自己研究了下部署的方式,把自己的过程整理下来供各位参考(看我这么好的份上,来个三连吧o( ̄▽ ̄)ブ)。
在部署之前,我先说明几点:
- 本教程使用的一些文件都放在百度云(提取码:0a09 )里了,可以自行下载使用
- yolov5的代码我用的是https://github.com/ultralytics/yolov5的master分支,目前应该是版本6.2,后续作者更新后,可以切换到6.2分支来使用。
- 尽管本教程转换模型用的是官方模型,但各位可以训练自己的模型来转换,模型转换几乎没有啥差异,可放心食用。
- 代码版本我应该和官方使用的不一样,X3P给的官方测试时间是45ms左右,但我转换模型时候,发现有较多的层跑在CPU,导致推理时间多很多。
- 很多人说了后处理过程耗时太高,后处理计算在python跑的话,确实速度会慢很多,所以我以这个,顺便教各位如何利用cython来包装自己的C++代码来加速,最后测试时候,python版的后处理耗时越450ms,用cython包装后,后处理仅用9ms。
下面,开始我们的部署之旅。
文章目录
一 环境配置
1.1 安装依赖包
如果在当前python环境下能利用
pip install onnx
轻松安装onnx,那就直接配置yolov5的环境就行了。
我电脑是windows,又不想安装虚拟机,所以环境的安装有一些限制。我最开始的python环境是3.6版本,结果安装onnx时候一堆问题。3.10有onnx的whl包,所以,建议跑模型的python环境为3.10(3.8好像也可,自己试试)。
下面给出我部署的指令流程,对于的pytorch包我也放在百度云了。
# 在指定路径下创建虚拟环境,我的anaconda安装在c盘,但我想把环境放在d盘,所以利用--prefix D:\Anaconda3\envs\yolov5指定路径
conda create --prefix D:\Anaconda3\envs\yolov5 python=3.10# 切换虚拟环境
conda activate D:\Anaconda3\envs\yolov5
# 安装关键包ONNX
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple onnx
# 安装yolov5依赖的pytorch
pip install"torch-1.11.0+cu113-cp310-cp310-win_amd64.whl""torchaudio-0.11.0+cu113-cp310-cp310-win_amd64.whl""torchvision-0.12.0+cu113-cp310-cp310-win_amd64.whl" -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装yolov5需要的包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.1 Pillow>=7.1.2 PyYAML>=5.3.1 requests>=2.23.0 scipy>=1.4.1 tqdm>=4.64.0 tensorboard>=2.4.1 pandas>=1.1.4 seaborn>=0.11.0 ipython psutil thop>=0.1.1
1.2 运行YoloV5
下载百度云中提供的文件,按照如下流程操作:
- 解压
yolov5-master.zip。 - 将
zidane.jpg放到yolov5-master文件夹中。 - 将
yolov5s.pt放到yolov5-master/models文件夹中。 - 进入
yolov5-master文件夹,输入python .\detect.py --weights .\models\yolov5s.pt --source zidane.jpg,代码会输出检测结果保存路径,比如我的就是Results saved to runs\detect\exp9,检测结果如下所示。
1.3 pytorch的pt模型文件转onnx
转换的时候,一定要清楚一点,BPU的工具链没有支持onnx的所有版本的算子,即当前BPU支持onnx的opset版本为10和11。错误的
opset
在模型检查阶段就无法通过,在后面我给各位展示转换失败的结果。
# 错误的转换指令
python .\export.py --weights .\models\yolov5s.pt --include onnx
# 正确的转换指令
python .\export.py --weights .\models\yolov5s.pt --include onnx --opset 11
转换后,控制台会输出一些log信息,转换后的模型文件在
.\\models\\yolov5s.pt
。
export: data=D:\05 - \01 - x3\BPUCodes\yolov5\yolov5-master\data\coco128.yaml, weights=['.\\models\\yolov5s.pt'], imgsz=[640, 640], batch_size=1, device=cpu, half=False, inplace=False, train=False, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=12, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx']
YOLOv5 2022-9-1 Python-3.10.4 torch-1.11.0+cu113 CPU
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients
PyTorch: starting from models\yolov5s.pt with output shape (1, 25200, 85)(14.1 MB)
ONNX: starting export with onnx 1.12.0...
ONNX: export success 3.6s, saved as models\yolov5s.onnx (28.0 MB)
Export complete (4.2s)
Results saved to D:\05 - \01 - x3\BPUCodes\yolov5\yolov5-master\models
Detect: python detect.py --weights models\yolov5s.onnx
Validate: python val.py --weights models\yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'models\yolov5s.onnx')
Visualize: https://netron.app
二 ONNX模型转换
模型转换要在docker中转换,怎么安装docker,怎么进入OE,怎么挂载硬盘,均在博客[BPU部署教程] 一文带你轻松走出模型部署新手村中详细介绍,任何细节不懂的,可以去这里面寻找。
新建一个文件夹,我这里叫
bpucodes
,把前面转好的
yolov5s.onnx
放进这个文件夹里,百度云里也提供了相关的代码。
在docker中,进入
bpucodes
文件夹,开始我们的模型转换。
2.1 模型检查
模型检测的目的是检测有没有不支持的算子,输入指令
hb_mapper checker --model-type onnx --march bernoulli2 --model yolov5s.onnx
,开始检查模型,显示如下内容表示模型检查通过。(我们可以发现网络的后端部分存在一些层是运行在CPU上的,这会导致耗时多一些)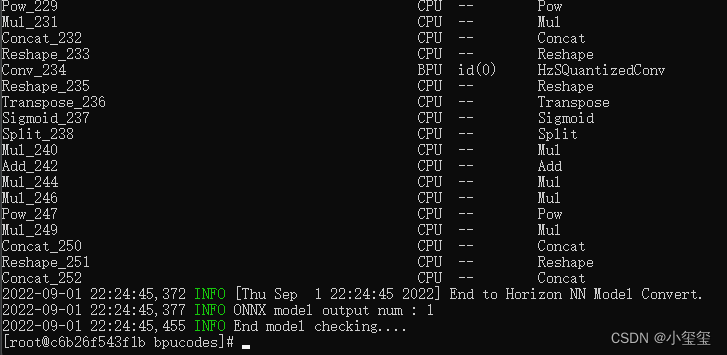
前面提到了,在pt转onnx时,要–opset 11,而我最开始转换的时候,是没有指定的,下面说一下我是怎么找到问题的(这部分为题外话,想继续下一步的话,直接跳2.2节)
我最开始利用
python .\export.py --weights .\models\yolov5s.pt --include onnx
来转onnx,结果发现在BPU的OE工具链里,
hb_mapper checker
检查不通过,显示如下错误。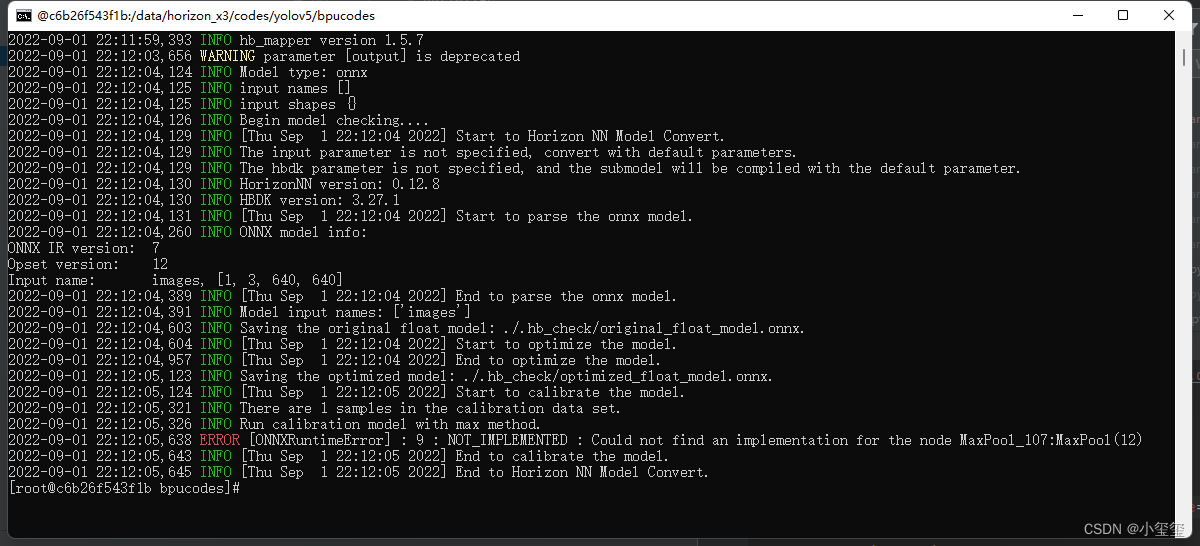
谷歌搜到了onnx支持的算子信息
https://github.com/microsoft/onnxruntime/blob/main/docs/OperatorKernels.md
,在我这个docker里面,onnx库的版本为
1.7.0
,发现MaxPool实际上是支持的啊,为啥不通过,结果我发现后面的数字
8,11,12
,才想起来这个是不是还要指定
opset
呀。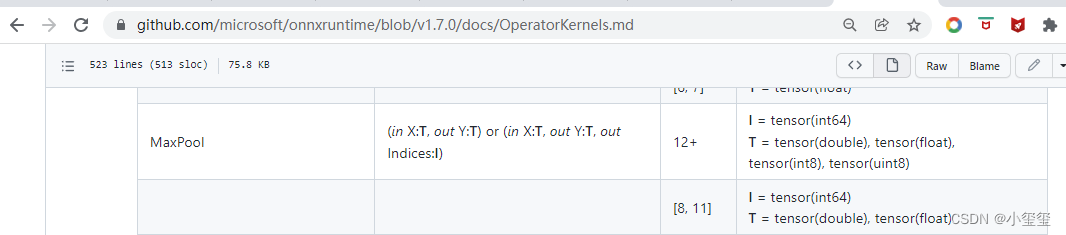
然后,我在yolov5的
export.py
文件里,发现opset默认是12,难怪不通过,最后问了晟哥,得到支持的版本,最终在指令中增加
--opset 11
,来生成onnx,这样就通过了。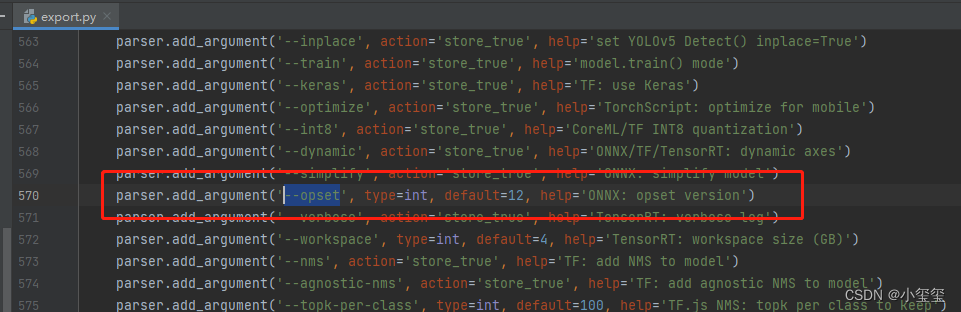
2.2 准备校准数据
校准数据的代码参考[BPU部署教程] 一文带你轻松走出模型部署新手村中的yolov3的校准代码,整体没有太多改变,主要修改了如下两个地方(代码我放百度云了,跟前面的博客内容重复度太高)。
# 修改输入图像大小为640x640
img = imequalresize(img,(640,640))# 指定输出的校准图像根目录
dst_root = '/data/horizon_x3/codes/yolov5/bpucodes/calibration_data
输入
prepare_calibration_data.py
可以得到校准数据
其实在上一节模型检查过程中,log信息已经输出网络输入的图像维度了,我也是直接用这个。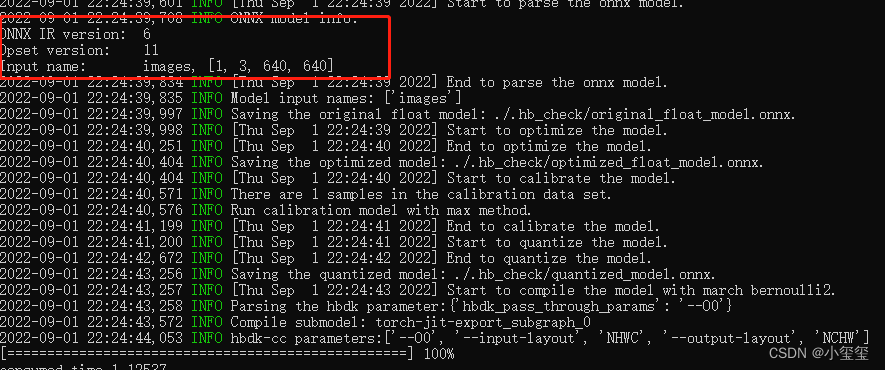
2.3 开始转换BPU模型
转换模型需要yaml参数文件,具体含义参考yolov3的教程,这里我直接放上我的
convert_yolov5s.yaml
文件信息。
model_parameters:onnx_model:'yolov5s.onnx'output_model_file_prefix:'yolov5s'march:'bernoulli2'input_parameters:input_type_train:'rgb'input_layout_train:'NCHW'input_type_rt:'nv12'norm_type:'data_scale'scale_value:0.003921568627451input_layout_rt:'NHWC'calibration_parameters:cal_data_dir:'./calibration_data'calibration_type:'max'max_percentile:0.9999compiler_parameters:compile_mode:'latency'optimize_level:'O3'debug:Falsecore_num:2# x3p是双核BPU,所以指定为2可以速度更快
输入命令
hb_mapper makertbin --config convert_yolov5s.yaml --model-type onnx
开始转换我们的模型!校准过后会输出每一层的量化损失。
转换成功后,得到
model_output/yolov5s.bin
,这个文件拿出来,拷贝到旭日X3派上使用,它也是我们上板运行所需要的模型文件。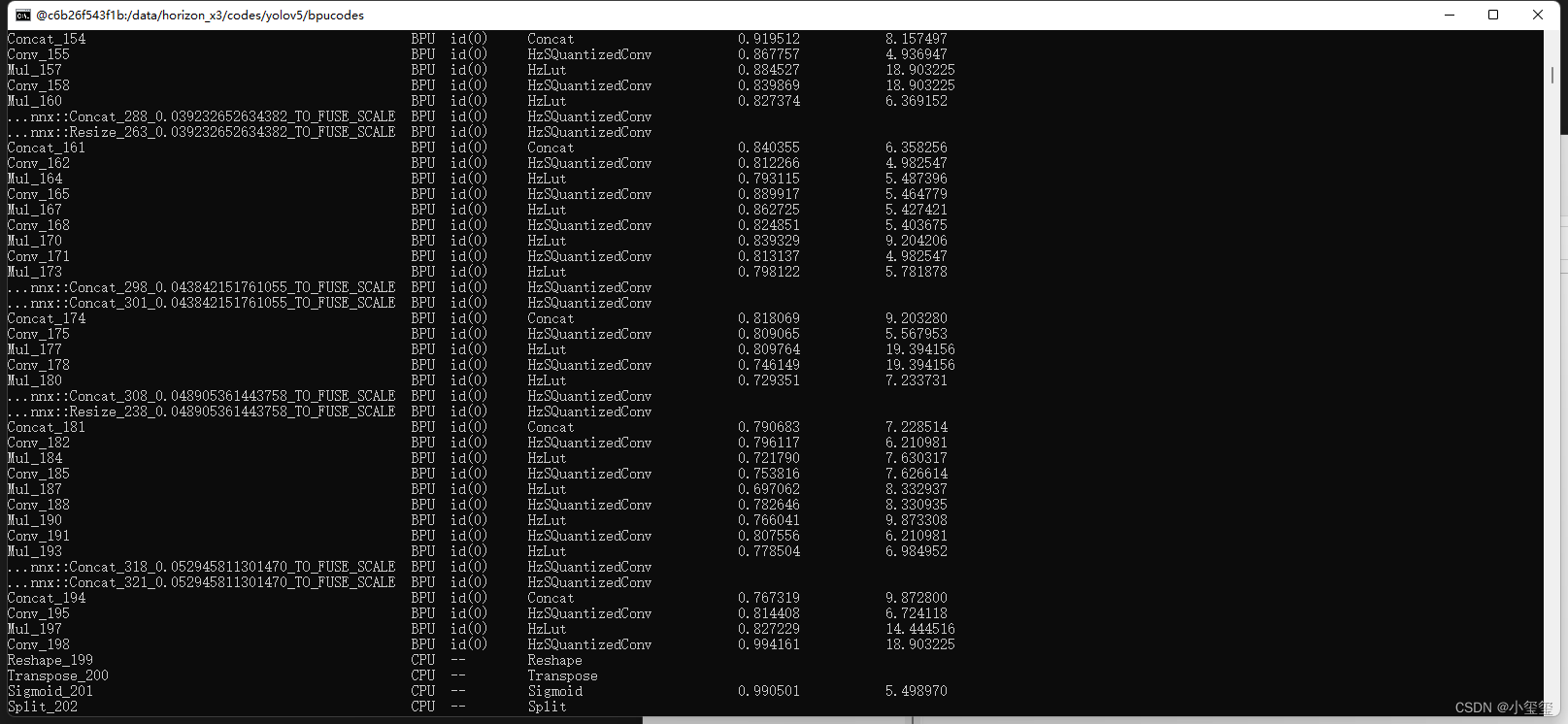
三 上板运行
有小伙伴说后处理部分耗时太高,所以我这里除了给出推理代码,还教各位如何利用cython封装c++来加速你的代码。
3.1 文件准备
下载百度云的文件,拷贝到旭日X3派开发板中,其中
yolov5s.bin
就是我们转换后的模型,
coco_classes.names
仅用在画框的时候,如果用自己的数据集的话,参考
coco_classes.names
创建个新的名字文件即可。
输入
sudo apt-get install libopencv-dev
安装opencv库,之后进入代码根目录,输入
python3 setup.py build_ext --inplace
,编译后处理代码,得到
lib/pyyolotools.cpython-38-aarch64-linux-gnu.so
文件。
3.2 运行推理代码
模型推理的代码如下所示,其中
yolotools.pypostprocess_yolov5
为C++实现的后处理功能,推理代码在我这里保存为
inference_model_bpu.py
。
import numpy as np
import cv2
import os
from hobot_dnn import pyeasy_dnn as dnn
from bputools.format_convert import imequalresize, bgr2nv12_opencv
# lib.pyyolotools为封装的库import lib.pyyolotools as yolotools
defget_hw(pro):if pro.layout =="NCHW":return pro.shape[2], pro.shape[3]else:return pro.shape[1], pro.shape[2]defformat_yolov5(frame):
row, col, _ = frame.shape
_max =max(col, row)
result = np.zeros((_max, _max,3), np.uint8)
result[0:row,0:col]= frame
return result
# img_path 图像完整路径
img_path ='20220904134315.jpg'# model_path 量化模型完整路径
model_path ='yolov5s.bin'# 类别名文件
classes_name_path ='coco_classes.names'# 设置参数
thre_confidence =0.4
thre_score =0.25
thre_nms =0.45# 框颜色设置
colors =[(255,255,0),(0,255,0),(0,255,255),(255,0,0)]# 1. 加载模型,获取所需输出HW
models = dnn.load(model_path)
model_h, model_w = get_hw(models[0].inputs[0].properties)print(model_h, model_w)# 2 加载图像,根据前面模型,转换后的模型是以NV12作为输入的# 但在OE验证的时候,需要将图像再由NV12转为YUV444
imgOri = cv2.imread(img_path)
inputImage = format_yolov5(imgOri)
img = imequalresize(inputImage,(model_w, model_h))
nv12 = bgr2nv12_opencv(img)# 3 模型推理
t1 = cv2.getTickCount()
outputs = models[0].forward(nv12)
t2 = cv2.getTickCount()
outputs = outputs[0].buffer# 25200x85x1 print('time consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))# 4 后处理
image_width, image_height, _ = inputImage.shape
fx, fy = image_width / model_w, image_height / model_h
t1 = cv2.getTickCount()
class_ids, confidences, boxes = yolotools.pypostprocess_yolov5(outputs[0][:,:,0], fx, fy,
thre_confidence, thre_score, thre_nms)
t2 = cv2.getTickCount()print('post consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))# 5 绘制检测框withopen(classes_name_path,"r")as f:
class_list =[cname.strip()for cname in f.readlines()]
t1 = cv2.getTickCount()for(classid, confidence, box)inzip(class_ids, confidences, boxes):
color = colors[int(classid)%len(colors)]
cv2.rectangle(imgOri, box, color,2)
cv2.rectangle(imgOri,(box[0], box[1]-20),(box[0]+ box[2], box[1]), color,-1)
cv2.putText(imgOri, class_list[classid],(box[0], box[1]-10), cv2.FONT_HERSHEY_SIMPLEX,.5,(0,0,0))
t2 = cv2.getTickCount()print('draw rect consumption {0} ms'.format((t2-t1)*1000/cv2.getTickFrequency()))
cv2.imwrite('res.png', imgOri)
输入
sudo python3 inference_model_bpu.py
,推理结果保存为
res.png
,相关结果如下所示,可以看出,后处理部分耗时为7ms,C++和Python混编有效提升了代码的运行速度。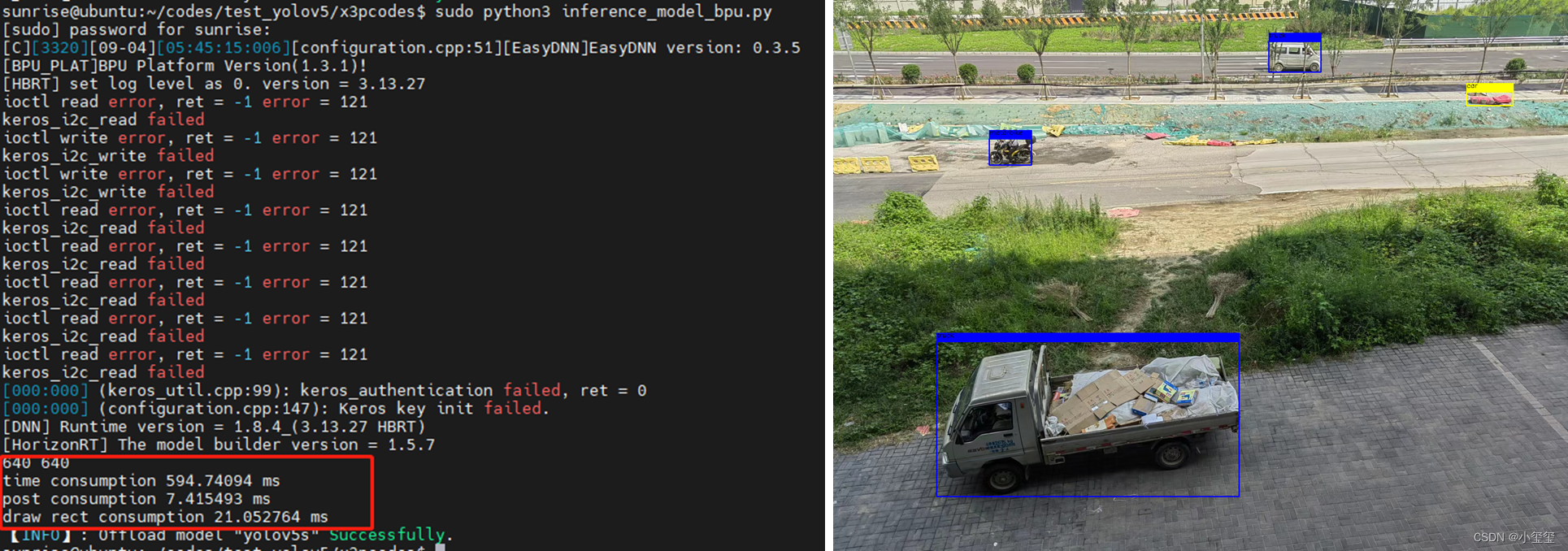
3.3 利用Cython封装后处理代码
这部分介绍了利用Cython封装C++的一些过程,后续各位有什么其他功能要补充的,按照这个流程处理即可。
3.3.1 写后处理的C++代码
首先,我们创建个头文件
yolotools.h
,用来记录函数声明,方便其他代码调用。因为Cython调用时,调用C++的一些类并不方便,所以写成C语言接口更方便调用。
后处理的函数名为
postprocess_yolov5
,下面我对这个函数的输入参数进行说明:
float *_data, int datanum:输入模型推理数据,BPU推理完一张640x640的图像后,会输出一个25200x85x1的矩阵,我们去掉1这一项,得到一个25200x85的矩阵,以它的数据起点指针作为输入,datanum为25200*85。int rows, int classnum:rows表示25200,而classnum表示数据集中的类别总数,我用的这个模型是以COCO为例的,所以一共80类。值得注意的,上述的85=classnum+1(得分)+4(矩形4个参数)float x_factor, float y_factor:图像的缩放因子float thre_cof, float thre_score, float thre_nms:后处理参数int *_detected_num, signed int **_classids, float **_confidences, signed int **_boxes:后处理输出,_detected_num表示预测的矩形框个数,其余的分别为对应得数据,并返回对应的数据指针。
#ifndefYOLOV5_TOOLS_H#defineYOLOV5_TOOLS_Hvoidpostprocess_yolov5(float*_data,int datanum,int rows,int classnum,float x_factor,float y_factor,float thre_cof,float thre_score,float thre_nms,int*_detected_num,signedint**_classids,float**_confidences,signedint**_boxes);// 释放由postprocess_yolov5动态分配的内存 voidfree_postprocess_yolov5(signedint**_classids,float**_confidences,signedint**_boxes);#endif
创建
yolov5postprocess.cpp
来对后处理函数进行实现
#include<iostream>#include<vector>#include<opencv2/opencv.hpp>#include<mutex>#include"yolotools.h"// 这部分的代码参考了https://github.com/ultralytics/yolov5/issues/239voidpostprocess_yolov5(float*_data,int datanum,int rows,int classnum,float x_factor,float y_factor,float thre_cof,float thre_score,float thre_nms,int*_detected_num,signedint**_classids,float**_confidences,signedint**_boxes){float*data =(float*)_data;int dimensions = classnum +5;CV_Assert(datanum == rows * dimensions);
std::vector<cv::Rect> boxes;
std::vector<int> class_ids;
std::vector<float> confidences;// 这里是利用多线程,加速获得目标框,实际上,这部分的多线程,仅加速2-3ms。// 可以利用cv::setNumThreads(1);指定线程数
std::mutex mtx;
cv::parallel_for_(cv::Range(0, rows),[&](const cv::Range& range){for(int r = range.start; r < range.end; r++)//{float*usage_data = data + r *(classnum +5);float confidence = usage_data[4];if(confidence >= thre_cof){float*classes_scores = usage_data +5;
cv::Mat scores(1, classnum, CV_32FC1, classes_scores);
cv::Point class_id;double max_class_score;
cv::minMaxLoc(scores,0,&max_class_score,0,&class_id);if(max_class_score > thre_score){float x = usage_data[0], y = usage_data[1], w = usage_data[2], h = usage_data[3];int left =int((x -0.5* w)* x_factor);int top =int((y -0.5* h)* y_factor);int width =int(w * x_factor);int height =int(h * y_factor);
mtx.lock();
confidences.push_back(confidence);
class_ids.push_back(class_id.x);
boxes.push_back(cv::Rect(left, top, width, height));
mtx.unlock();}}}});
std::vector<int> nms_result;
cv::dnn::NMSBoxes(boxes, confidences, thre_score, thre_nms, nms_result);*_detected_num = nms_result.size();*_classids =newsignedint[*_detected_num];*_confidences =newfloat[*_detected_num];*_boxes =newsignedint[*_detected_num *4];for(int i =0; i <*_detected_num; i++){int idx = nms_result[i];(*_classids)[i]= class_ids[idx];(*_confidences)[i]= confidences[idx];(*_boxes)[i *4]= boxes[idx].x;(*_boxes)[i *4+1]= boxes[idx].y;(*_boxes)[i *4+2]= boxes[idx].width;(*_boxes)[i *4+3]= boxes[idx].height;}}voidfree_postprocess_yolov5(signedint**_classids,float**_confidences,signedint**_boxes){if(*_classids){delete[]*_classids;*_classids =nullptr;}if(*_confidences){delete[]*_confidences;*_confidences =nullptr;}if(*_boxes){delete[]*_boxes;*_boxes =nullptr;}}
3.3.2 写Cython所需的Pyx文件
同级目录下创建
pyyolotools.pyx
,切记文件名不要跟某个CPP重复了,因为cython会将
pyyolotools.pyx
转为
pyyolotools.cpp
,如果有重复的话可能会导致文件被覆盖掉。
import numpy as np
cimport numpy as np
from libc.string cimport memcpy
# 函数声明
cdef extern from"yolotools.h":
void postprocess_yolov5(float*,int,int,int,float,float,float,float,float,int*, signed int**,float**, signed int**)
void free_postprocess_yolov5(signed int**,float**, signed int**)# 定义Python函数,主要补充的就是将python数据转换为C++指针,然后利用计算出的结果再转换回去defpypostprocess_yolov5(np.ndarray[np.float32_t, ndim=2] yolov5output,float fx,float fy,float thre_cof,float thre_score,float thre_nms):
cdef int rows = yolov5output.shape[0]
cdef int dimensions = yolov5output.shape[1]
cdef int classnum = dimensions -5assert classnum >5
cdef int datanum = rows * dimensions
cdef int detected_num =0
cdef signed int*pclassids
cdef float*pconfidences
cdef signed int*pboxes
postprocess_yolov5(&yolov5output[0,0], datanum,
rows, classnum, fx, fy,
thre_cof, thre_score, thre_nms,&detected_num,&pclassids,&pconfidences,&pboxes)if detected_num ==0:returnNone
cdef np.ndarray[np.int32_t, ndim=1] classids = np.zeros((detected_num,), dtype = np.int32)
cdef np.ndarray[np.float32_t, ndim=1] confidence = np.zeros((detected_num,), dtype = np.float32)
cdef np.ndarray[np.int32_t, ndim=2] boxes = np.zeros((detected_num,4), dtype = np.int32)
memcpy(&classids[0], pclassids, sizeof(int)* detected_num)
memcpy(&confidence[0], pconfidences, sizeof(float)* detected_num)
memcpy(&boxes[0,0], pboxes, sizeof(int)* detected_num *4)
free_postprocess_yolov5(&pclassids,&pconfidences,&pboxes);return(classids, confidence, boxes)
3.3.3 写编译Pyx所需的python代码
创建
setup.py
文件,将下面代码放进去,配置好opencv的头文件目录、库目录、以及所需的库文件。
在
Extension
中配置封装的函数所依赖的文件,然后在控制台输入
python3 setup.py build_ext --inplace
即可。
from setuptools import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
import numpy as np
opencv_include ='/usr/include/opencv4/'
opencv_lib_dirs ="/usr/lib/aarch64-linux-gnu/"
opencv_libs =['opencv_core','opencv_highgui','opencv_imgproc','opencv_imgcodecs','opencv_dnn']print('opencv_include: ', opencv_include)print('opencv_lib_dirs: ', opencv_lib_dirs)print('opencv_libs: ', opencv_libs)# python3 setup.py build_ext --inplaceclasscustom_build_ext(build_ext):defbuild_extensions(self):
build_ext.build_extensions(self)# Obtain the numpy include directory. This logic works across numpy versions.try:
numpy_include = np.get_include()except AttributeError:
numpy_include = np.get_numpy_include()
ext_modules =[
Extension("lib.pyyolotools",["./yolov5postprocess.cpp","./pyyolotools.pyx",],
include_dirs =[numpy_include, opencv_include],
language='c++',
libraries=opencv_libs,
library_dirs=[opencv_lib_dirs]),]
setup(
name='pyyolotools',
ext_modules=ext_modules,
cmdclass={'build_ext': custom_build_ext},)print('Build done')
四 总结
上一个部署教程,主要是介绍如何利用Caffe来部署模型,这个部分,就是利用ONNX来部署。后续如果自己基于这个代码进行修改的话,也可以按照这个教程对自己的模型进行量化上板。
此外,X3派作为个嵌入式板子,学会开发C++是非常重要的。但我个人认为所有的任务都是C++是不现实的,我们可以利用Python高效完成项目开发,对其中耗时较高的,封装C++即可。
PS:各位千万不要被推理耗时吓到了,感觉耗时太高了,因为这个版本的模型转换时候,后面一堆层是跑在CPU上的,各位在设计自己的网络的时候也要注意下哈。
版权归原作者 小玺玺 所有, 如有侵权,请联系我们删除。