
在这篇文章中,我将介绍一个与回归相关的常见技术面试问题,我自己也经常会提到这个问题:
描述回归建模中的L1和L2正则化方法。
在处理复杂数据时,我们往往会创建复杂的模型。太复杂并不总是好的。过于复杂的模型就是我们所说的“过拟合”,它们在训练数据上表现很好,但在看不见的测试数据上却表现不佳。
有一种方法可以对损失函数的过拟合进行调整,那就是惩罚。通过惩罚或“正则化”损失函数中的大系数,我们使一些(或所有)系数变小,从而使模型对数据中的噪声不敏感。
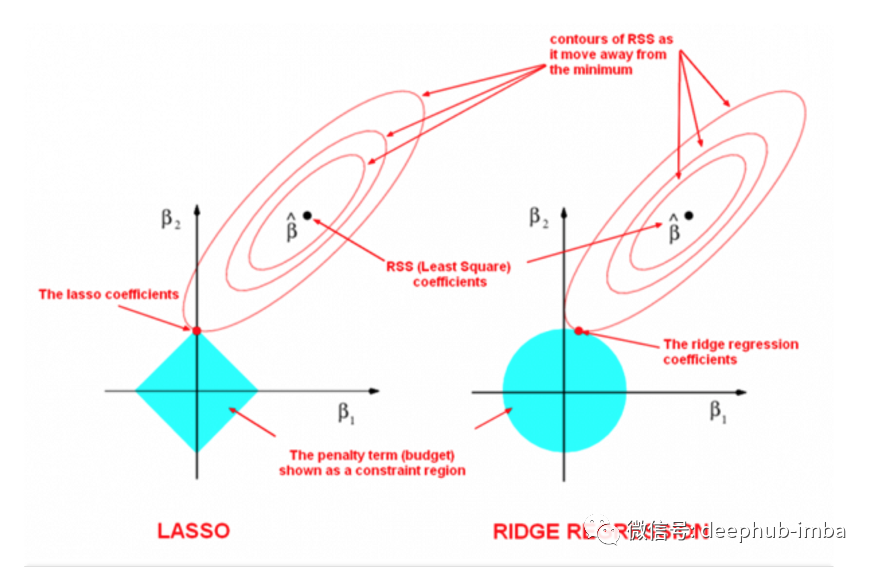
在回归中使用的两种流行的正则化形式是L1又名Lasso回归,和L2又名Ridge回归。在线性回归中我们使用普通最小二乘(OLS)是用于拟合数据的:我们对残差(实际值与预测值之间的差异)进行平方,以得到均方误差(MSE)。最小的平方误差,或最小的平方,是最适合的模型。
让我们来看看简单线性回归的成本函数:

对于多元线性回归,成本函数应该是这样的,其中𝑘是预测因子或变量的数量。

因此,随着预测器(𝑘)数量的增加,模型的复杂性也会增加。为了缓解这种情况,我们在这个成本函数中添加了一些惩罚形式。这将降低模型的复杂性,有助于防止过拟合,可能消除变量,甚至减少数据中的多重共线性。
L2 -岭回归
L2或岭回归,将𝜆惩罚项添加到系数大小的平方𝑚。𝜆是一个超参数,这意味着它的值是自由定义的。你可以在成本函数的末端看到它。
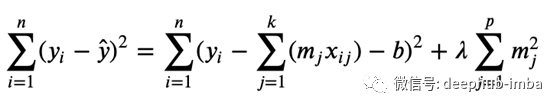
加上𝜆惩罚,𝑚系数受到约束,惩罚系数大的代价函数。
L1 -Lasso回归
L1或Lasso回归,几乎是一样的东西,除了一个重要的细节-系数的大小不是平方,它只是绝对值。

在这里,成本函数的最后是𝑚的绝对值,一些系数可以被精确地设置为零,而其他的系数则直接降低到零。当一些系数变为零时,Lasso回归的效果是特别有用的,因为它可以估算成本并同时选择系数。。
还有最重要的一点,在进行任何一种类型的正则化之前,都应该将数据标准化到相同的规模,否则罚款将不公平地对待某些系数。