
线程互斥,它是对的,但是不合理(饥饿问题)——同步
不合理:互斥有可能导致饥饿问题——由于执行流1优先级高,他就不断的申请锁,释放锁,则另一个执行流2会长时间得不到某种资源
在保证临界资源安全的前提下(互斥等),让线程访问某种资源,具有一定的顺序性,称之为同步。
同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步
竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。在线程场景下,这种问题也不难理解
同步能够解决线程互斥不合理性的问题:防止饥饿,线程协同
一.条件变量
1.条件变量概念
当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。
例如一个线程访问队列时,发现队列为空,它只能等待,直到其它线程将一个节点添加到队列中。这种情况就需要用到条件变量。
条件(对应的共享资源的状态,程序员要判断资源是否满足自己操作的要求,为满/为空就不满足),条件变量(条件满足或者不满足的时候,进行wait或signal--种方式)
条件变量:通过判断条件是否满足要求来决定是否让当前线程等待。
2.条件变量接口
(1)pthread_cond_init 创建/释放 条件变量
man 3 pthread_cond_init
初始化条件变量
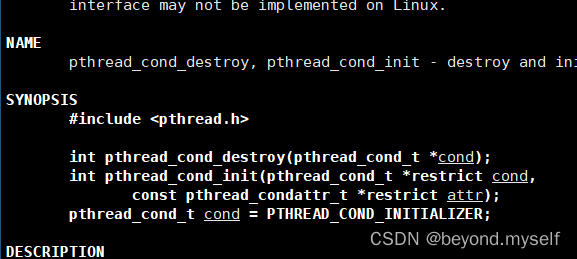
① pthread_cond_t cond = PTHREAD_COND_INITIALIZER; 定义全局/静态的条件变量,可以用这个宏初始化
② int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict attr); 定义局部条件变量—— cond:条件变量的地址。attr:条件变量的属性设为空
③ int pthread_cond_destroy(pthread_cond_t *cond); 销毁条件变量
(2)pthread_cond_wait 阻塞线程
man 3 pthread_cond_wait
pthread_cond_wait(&cond, &mutex); 让对应的线程进行等待,等待被唤醒。即调用这个接口线程会被阻塞。

int pthread_cond_wait(pthread_cond_t restrict cond,pthread_mutex_t restrict mutex);
条件变量要和mutex互斥锁,一并使用,为什么?——条件变量的wait中需要传入锁的意义是:在阻塞线程的时候,会自动释放mutex_锁(解锁)**详解见:大标题二—>小标题4.(1)
int pthread_cond_timedwait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime); abstime设定时间(暂时不用这个接口)
(3)pthread_cond_signal 唤醒线程
man 3 pthread_cond_signal
int pthread_cond_broadcast(pthread_cond_t *cond); 唤醒一个在指定条件变量下等待的所有线程
int pthread_cond_signal(pthread_cond_t *cond); 唤醒一个在指定条件变量下等待的线程,一个一个唤醒时,所有线程以队列方式排列的
3.例子
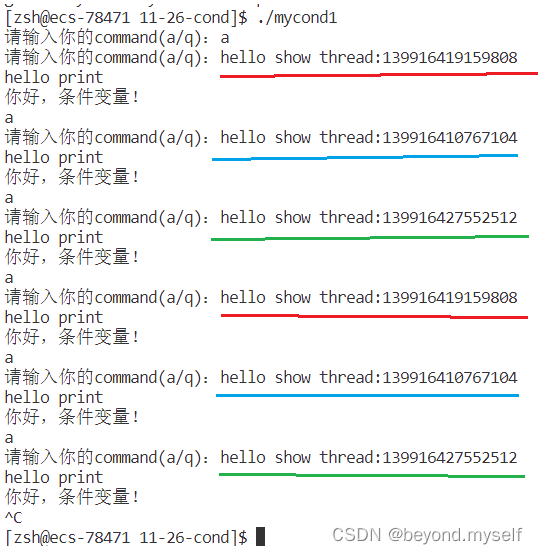
示例1:线程阻塞后被唤醒时是排队执行的。(这里是输入a就唤醒线程执行打印,q就退出)
#include<functional>
#include<vector>
#include<pthread.h>
#include<iostream>
using namespace std;
pthread_cond_t cond;
pthread_mutex_t mutex=PTHREAD_MUTEX_INITIALIZER;
vector<function<void()>> funcs;
void show()
{
cout<<"hello show"<<" thread:"<<pthread_self()<<endl;
}
void print()
{
cout<<"hello print"<<endl;
}
void* waitCommand(void* arg)
{
pthread_detach(pthread_self());
//cout<<"!!!!!!!111111"<<endl;
while(true)
{
pthread_cond_wait(&cond,&mutex);
for(auto& f:funcs)
{
f();
}
}
cout<<"thread id: "<<pthread_self()<<" end... "<<endl;
return nullptr;
}
int main()
{
funcs.push_back(show);
funcs.push_back(print);
funcs.push_back([](){
cout<<"你好,条件变量!"<<endl;
});
pthread_cond_init(&cond,nullptr);
pthread_t t1,t2,t3;
pthread_create(&t1,nullptr,waitCommand,nullptr);
pthread_create(&t2,nullptr,waitCommand,nullptr);
pthread_create(&t3,nullptr,waitCommand,nullptr);
//cout<<"2222222222222222"<<endl;
while(true)
{
char n='a';
cout<<"请输入你的command(a/q):";
cin>>n;
if(n=='a')
{
pthread_cond_signal(&cond);
}
else
{
break;
}
}
pthread_cond_destroy(&cond);
return 0;
}
示例2:线程阻塞后被唤醒时是排队执行的。(这里是不用输入一直循环唤醒线程执行打印)
#include<functional>
#include<unistd.h>
#include<vector>
#include<pthread.h>
#include<iostream>
using namespace std;
pthread_cond_t cond;
pthread_mutex_t mutex=PTHREAD_MUTEX_INITIALIZER;
vector<function<void()>> funcs;
void show()
{
cout<<"hello show"<<" thread:"<<pthread_self()<<endl;
}
void print()
{
cout<<"hello print"<<endl;
}
void* waitCommand(void* arg)
{
pthread_detach(pthread_self());
//cout<<"!!!!!!!111111"<<endl;
while(true)
{
pthread_cond_wait(&cond,&mutex);
for(auto& f:funcs)
{
f();
}
}
cout<<"thread id: "<<pthread_self()<<" end... "<<endl;
return nullptr;
}
int main()
{
funcs.push_back(show);
funcs.push_back(print);
funcs.push_back([](){
cout<<"你好,条件变量!"<<endl;
});
pthread_cond_init(&cond,nullptr);
pthread_t t1,t2,t3;
pthread_create(&t1,nullptr,waitCommand,nullptr);
pthread_create(&t2,nullptr,waitCommand,nullptr);
pthread_create(&t3,nullptr,waitCommand,nullptr);
//cout<<"2222222222222222"<<endl;
while(true)
{
sleep(1);
pthread_cond_broadcast(&cond);
}
pthread_cond_destroy(&cond);
return 0;
}

二.生产者消费者模型
1.介绍
生产者消费者模型——同步与互斥的最典型的应用场景——重新认识条件变量
①生产者和生产者(互斥),消费者和消费者(互斥),生产者和消费者( 互斥/同步)——3种关系
②生产者和消费者——由线程承担的 2种角色
③超市:内存中特定的一种内存结构(数据结构)——1个交易场所
为了便于理解,我们就叫他 < **321原则** >
写代码,就是要完成321原则

这里的超市就是缓冲区,也是临界资源:①提高效率。②解耦生产者和消费者之间的耦合关系。
(一般就是内存中的一段空间,可以有自己的组织方式)
1.消费者有多个,消费者之间是竞争关系——互斥关系
2.生产者有多个,生产者之间也是竞争关系——互斥关系
3.消费者和生产者之间又是什么关系呢?
①互斥关系:生产者把"123456789"写入缓冲区时(正在生产),消费者突然来拿,可能只拿走了"12345"就错误了,所以消费者和生产者之间也要有互斥关系。
②同步关系:要有一定的顺序去执行——消费完了要生产,生产满了要消费
1.如何让多个消费者线程等待呢?又如何让消费者线程被唤醒呢?
2.如何让多个生产者线程等待呢?又如何让生产者线程被唤醒呢?
3.如何衡量消费者和生产者所关心的条件是否就绪呢??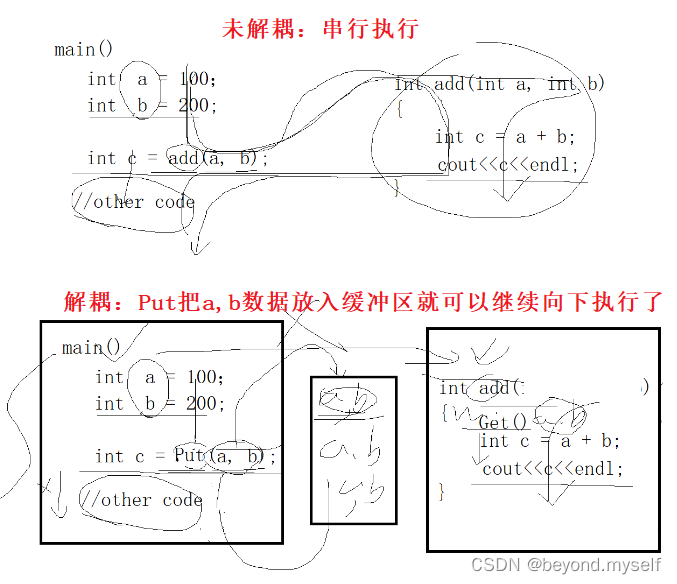
2.**生产者消费者模型优点 **
解耦
支持并发
支持忙闲不均。
3.*基于BlockingQueue*的生产者消费者模型 **
阻塞队列概念
在多线程编程中阻塞队列(Blocking Queue)是一种常用于实现生产者和消费者模型的数据结构。其与普通的队列区别在于,当队列为空时,从队列获取元素的操作将会被阻塞,直到队列中被放入了元素;当队列满时,往队列里存放元素的操作也会被阻塞,直到有元素被从队列中取出(以上的操作都是基于不同的线程来说的,线程在对阻塞队列进程操作时会被阻塞),管道就是一种阻塞队列

4.BlockingQueue阻塞队列代码
注意:
(1)pthread_cond_wait(&conCond_, &mutex_); 解释
挂起时生产者一定是在临界区中的,因为你要先上锁,不上锁就没有资格访问临界资源(如果不上锁就访问临界资源,则不符合同步的规则,那就是代码写的有问题)。此时上锁后被挂起,生产者和消费者用的同一把锁,如果 生产者/消费者 不释放锁(解锁)那么对方的线程就永远无法访问,所以条件变量的wait中需要传入锁的意义是:在阻塞线程的时候,会自动释放mutex_锁(解锁)

(2)生产者push时用while循环判断 解释
while (isFull()):原因是 proBlockWait();调用的 pthread_cond_wait(&proCond_, &mutex_); 有可能返回失败,或被 伪唤醒(伪唤醒可能是系统造成的或者写的代码有错误造成)。如果是 if (isFull()) 则返回失败/伪唤醒后 就直接向下指向条件满足的代码,可是此时阻塞队列还是满的,再添加数据就错了;所以用while (isFull()) 返回失败/伪唤醒后需要继续判断是否为满,为满就是返回失败/伪唤醒导致的—>重新等待;不满就是等待成功,消费者也消费了—>就可以添加数据了
(3)易错
①pop是public。②BlockQueueTest.cc的consumer的get不知道怎么写/忘写。
//生产接口
void push(const T &in) // const &: 纯输入
{
// 加锁
// 判断->是否适合生产->bq是否为满->程序员视角的条件->1. 满(不生产) 2. 不满(生产)
// if(满) 不生产,休眠
// else if(不满) 生产,唤醒消费者
// 解锁
lockQueue();
while (isFull()) // ifFull就是我们在临界区中设定的条件
{
// before: 当我等待的时候,会自动释放mutex_
proBlockWait(); //阻塞等待,等待被唤醒。 被唤醒 != 条件被满足(概率虽然很小),被唤醒 && 条件被满足
// after: 当我醒来的时候,我是在临界区里醒来的!!
}
// 条件满足,可以生产
pushCore(in); //生产完成
// wakeupCon(); // 唤醒消费者
unlockQueue();
wakeupCon(); // 唤醒消费者
}
(3)并发的体现
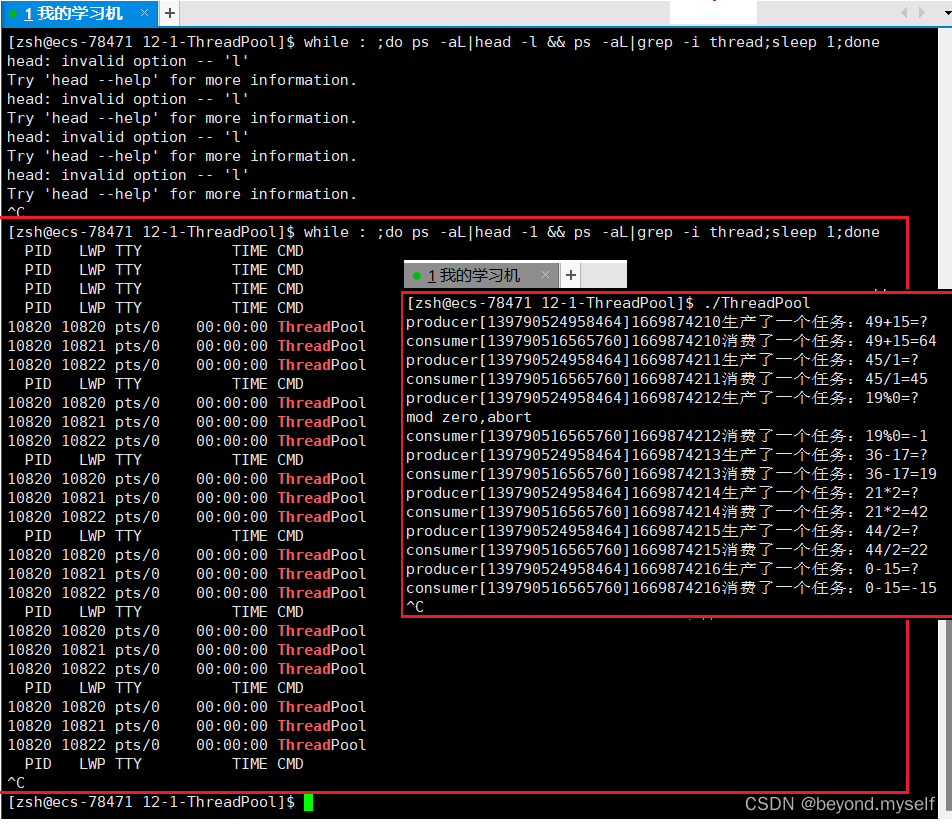
制作任务要花时间,处理任务也是要花时间的。并发体现:一般并不是在临界区中并发,而是生产前(生产者放入阻塞队列之前),消费后(消费者从阻塞队列拿出之后)对应的并发。即:生产者放任务和消费者取任务是串行的,但是生产者制作任务和消费者处理任务是并发的。
makefile 新写法
makefile中定义变量,例如:LD=-lpthread ,=两侧尽量不带空格,下面就可以替换为 $(LD) ,意为取出这个变量
CC=g++
FLAGS=-std=c++11
LD=-lpthread
bin=blockQueue
src=BlockQueueTest.cc
$(bin):$(src)
$(CC) -o $@ $^ $(LD) $(FLAGS)
.PHONY:clean
clean:
rm -f $(bin)
Task.hpp
#pragma once
#include <iostream>
#include <string>
class Task
{
public:
Task() : elemOne_(0), elemTwo_(0), operator_('0')
{
}
Task(int one, int two, char op) : elemOne_(one), elemTwo_(two), operator_(op)
{
}
int operator() ()
{
return run();
}
int run()
{
int result = 0;
switch (operator_)
{
case '+':
result = elemOne_ + elemTwo_;
break;
case '-':
result = elemOne_ - elemTwo_;
break;
case '*':
result = elemOne_ * elemTwo_;
break;
case '/':
{
if (elemTwo_ == 0)
{
std::cout << "div zero, abort" << std::endl;
result = -1;
}
else
{
result = elemOne_ / elemTwo_;
}
}
break;
case '%':
{
if (elemTwo_ == 0)
{
std::cout << "mod zero, abort" << std::endl;
result = -1;
}
else
{
result = elemOne_ % elemTwo_;
}
}
break;
default:
std::cout << "非法操作: " << operator_ << std::endl;
break;
}
return result;
}
int get(int *e1, int *e2, char *op)
{
*e1 = elemOne_;
*e2 = elemTwo_;
*op = operator_;
}
private:
int elemOne_;
int elemTwo_;
char operator_;
};
BlockQueue.hpp
#pragma once
#include <iostream>
#include <queue>
#include <cstdlib>
#include <unistd.h>
#include <pthread.h>
using namespace std;
// 新需求: 我只想保存最新的5个任务,如果来了任务,老的任务,我想让他直接被丢弃
const uint32_t gDefaultCap = 5;
template <class T>
class BlockQueue
{
public:
BlockQueue(uint32_t cap = gDefaultCap) : cap_(cap)
{
pthread_mutex_init(&mutex_, nullptr);
pthread_cond_init(&conCond_, nullptr);
pthread_cond_init(&proCond_, nullptr);
}
~BlockQueue()
{
pthread_mutex_destroy(&mutex_);
pthread_cond_destroy(&conCond_);
pthread_cond_destroy(&proCond_);
}
public:
//生产接口
void push(const T &in) // const &: 纯输入
{
// 加锁
// 判断->是否适合生产->bq是否为满->程序员视角的条件->1. 满(不生产) 2. 不满(生产)
// if(满) 不生产,休眠
// else if(不满) 生产,唤醒消费者
// 解锁
lockQueue();
while (isFull()) // ifFull就是我们在临界区中设定的条件
{
// before: 当我等待的时候,会自动释放mutex_
proBlockWait(); //阻塞等待,等待被唤醒。 被唤醒 != 条件被满足(概率虽然很小),被唤醒 && 条件被满足
// after: 当我醒来的时候,我是在临界区里醒来的!!
}
// 条件满足,可以生产
pushCore(in); //生产完成
// wakeupCon(); // 唤醒消费者
unlockQueue();
wakeupCon(); // 唤醒消费者
}
//消费接口
T pop()
{
// 加锁
// 判断->是否适合消费->bq是否为空->程序员视角的条件->1. 空(不消费) 2. 有(消费)
// if(空) 不消费,休眠
// else if(有) 消费,唤醒生产者
// 解锁
lockQueue();
while (isEmpty())
{
conBlockwait(); //阻塞等待,等待被唤醒,?
}
// 条件满足,可以消费
T tmp = popCore();
unlockQueue();
wakeupPro(); // 唤醒生产者
return tmp;
}
private:
void lockQueue()
{
pthread_mutex_lock(&mutex_);
}
void unlockQueue()
{
pthread_mutex_unlock(&mutex_);
}
bool isEmpty()
{
return bq_.empty();
}
bool isFull()
{
return bq_.size() == cap_;
}
void proBlockWait() // 生产者一定是在临界区中的!
{
// 1. 在阻塞线程的时候,会自动释放mutex_锁
pthread_cond_wait(&proCond_, &mutex_);
}
void conBlockwait() //阻塞等待,等待被唤醒
{
// 1. 在阻塞线程的时候,会自动释放mutex_锁
pthread_cond_wait(&conCond_, &mutex_);
// 2. 当阻塞结束,返回的时候,pthread_cond_wait,会自动帮你重新获得mutex_,然后才返回
// 为什么我们上节课,写的代码,批量退出线程的时候,发现无法退出?
}
void wakeupPro() // 唤醒生产者
{
pthread_cond_signal(&proCond_);
}
void wakeupCon() // 唤醒消费者
{
pthread_cond_signal(&conCond_);
}
void pushCore(const T &in)
{
bq_.push(in); //生产完成
}
T popCore()
{
T tmp = bq_.front();
bq_.pop();
return tmp;
}
private:
uint32_t cap_; //容量
queue<T> bq_; // blockqueue
pthread_mutex_t mutex_; //保护阻塞队列的互斥锁
pthread_cond_t conCond_; // 让消费者等待的条件变量
pthread_cond_t proCond_; // 让生产者等待的条件变量
};
BlockQueueTest.cc
#include "Task.hpp"
#include "BlockQueue.hpp"
#include <ctime>
const std::string ops = "+-*/%";
// 并发,并不是在临界区中并发(一般),而是生产前(before blockqueue),消费后(after blockqueue)对应的并发
void *consumer(void *args)
{
BlockQueue<Task> *bqp = static_cast<BlockQueue<Task> *>(args);
while (true)
{
Task t = bqp->pop(); // 消费任务
int result = t(); //处理任务 --- 任务也是要花时间的!
int one, two;
char op;
t.get(&one, &two, &op);
cout << "consumer[" << pthread_self() << "] " << (unsigned long)time(nullptr)
<< " 消费了一个任务: " << one << op << two << "=" << result << endl;
}
}
void *productor(void *args)
{
BlockQueue<Task> *bqp = static_cast<BlockQueue<Task> *>(args);
while (true)
{
// 1. 制作任务 --- 要不要花时间?? -- 网络,磁盘,用户
int one = rand() % 50;
int two = rand() % 20;
char op = ops[rand() % ops.size()];
Task t(one, two, op);
// 2. 生产任务
bqp->push(t);
cout << "producter[" << pthread_self() << "] " << (unsigned long)time(nullptr)
<< " 生产了一个任务: " << one << op << two << "=?" << endl;
sleep(1);
}
}
int main()
{
srand((unsigned long)time(nullptr) ^ getpid());
// 定义一个阻塞队列
// 创建两个线程,productor, consumer
// productor ----- consumer
// BlockQueue<int> bq;
// bq.push(10);
// int a = bq.pop();
// cout << a << endl;
// 既然可以使用int类型的数据,我们也可以使用自己封装的类型,包括任务
// BlockQueue<int> bq;
BlockQueue<Task> bq;
pthread_t c, p;
pthread_create(&c, nullptr, consumer, &bq);
pthread_create(&p, nullptr, productor, &bq);
pthread_join(c, nullptr);
pthread_join(p, nullptr);
return 0;
}
三.POSIX信号量
1.介绍
POSIX信号量和SystemV信号量作用相同,都是用于同步操作,达到无冲突的访问共享资源目的。 但POSIX可以用于线程间同步。
信号量本质是一个计数器。定义:信号量是一个计数器,这个计数器对应的PV操作(V ++ P --)是原子的。信号量的PV操作:V ++归还资源,P --申请资源。信号量的作用:限制进入临界区的线程个数
申请mutex 访问临界资源之前被切换走了有问题吗?——没问题。资源预定::因为只要我拿到了锁,当前的临界资源就是我的!
1.信号量申请成功了,就一定能保证你会拥有一部分临界资源吗?——能,只要信号量申请成功,那么你一定会获得指定的资源
2.临界资源可以当成整体,可以不可以看做一小部分一小部分呢?——可以,结合场景
信号量: 1
p-- 1—>0---加锁
v++ 0—>1---释放锁
叫做二元信号量,二元信号量 和 互斥锁 是等价的
2.信号量接口
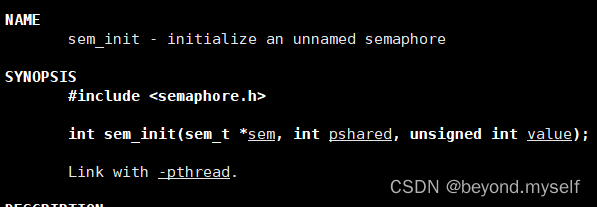
(1)sem_init 初始化一个未命名的信号量
man 3 sem_init
int sem_init(sem_t *sem, int pshared, unsigned int value);
sem:初始化的信号量。pshared:0表示线程间共享,非零表示进程间共享(填0)。
value:信号量初始值

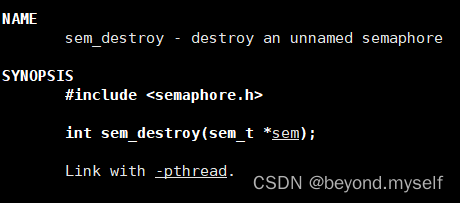
(2)sem_destroy 销毁一个信号量
int sem_destroy(sem_t *sem);
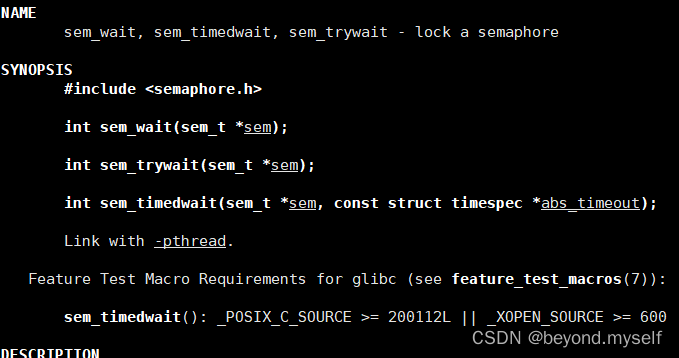
(3)sem_wait --信号量
功能:等待信号量,会将信号量的值减1
int** sem_wait**(sem_t *sem); ——P--
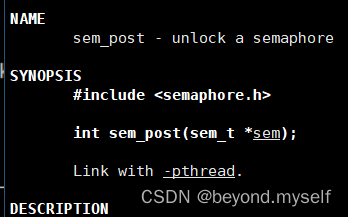
(4)sem_post ++信号量
功能:发布信号量,表示资源使用完毕,可以归还资源了。将信号量值加1。
int** sem_post**(sem_t *sem); ——V++
上面生产者-消费者的例子是基于queue的,其空间可以动态分配,现在基于固定大小的环形队列重写这个程序 (POSIX信号量)
3.环形队列
(1)信号量的作用
后续操作基本原则:(信号量保证满数据情况只能是消费线程先消费数据资源,数据为空的情况下生产线程先申请空间资源)
环形队列有可能访问同一个位置。什么时候会发生?——我们两个指向同一个位置的时候只有满or空的时候! ( 互斥and同步)其他时候,都指向不同的位置! (并发 )
1.数据为空:消费者不能超过生产者一>生产者先运行。
2.数据为满:生产者不能把消费者套一个圈然后继续再往后写入——消费者先运行 解释如下:
生产者:最关心的是什么资源:空间默认是N: [N, 0]
消费者:最关心的是什么资源:数据默认是0 [0,N]
sem_ t roomSem=N; 剩余空间的信号量
sem_ t dataSem=0; 数据的信号量
生产线程生产,P(roomSem)申请一个空间资源 --、V(dataSem)释放一个数据资源++;
消费线程消费,P(dataSem)申请一个数据资源 --、V(roomSem)释放一个空间资源++;
即:(1)哪个线程先运行不能保证,但是数据为空的情况下能保证生产线程先申请空间资源,因为生产者关心的空间资源计数器(信号量)默认是N,消费者关心的数据资源计数器(信号量)默认是0,即使消费者线程先运行,因为数据资源计数器默认是0,无法再P--,消费者也无法消费数据资源,消费者会被挂起。只要生产者生产完之后消费者才能消费。(2)满数据的情况只能是消费线程先消费数据资源,同理
我们是单生产者,单消费者
多生产者,多消费者??代码怎么改?
为什么呢???多生产者,多消费者?
不要只关心把数据或者任务,从ringqueue 放拿的过程,获取数据或者任务,处理数据或者任务,也是需要花时间的!
4.信号量实现环形队列代码
(1)单生产者,单消费者
RingQueue.hpp
#include<sys/types.h>
#include<unistd.h>
#include<queue>
#include<semaphore.h>
#include<iostream>
using namespace std;
const int gCap=5;
template<class T>
class RingQueue
{
public:
RingQueue(int cap=gCap):ringqueue_(cap),pIndex_(0),cIndex_(0)
{
sem_init(&roomSem_,0,ringqueue_.size());
sem_init(&dataSem_,0,0);
}
void push(const T& in)
{
sem_wait(&roomSem_);
ringqueue_[pIndex_]=in;
sem_post(&dataSem_);
pIndex_++;
pIndex_%=ringqueue_.size();
}
T pop()
{
sem_wait(&dataSem_);
T temp=ringqueue_[cIndex_];
sem_post(&roomSem_);
cIndex_++;
cIndex_%=ringqueue_.size();
return temp;
}
~RingQueue()
{
sem_destroy(&roomSem_);
sem_destroy(&dataSem_);
}
private:
vector<T> ringqueue_;
sem_t roomSem_;
sem_t dataSem_;
uint32_t cIndex_;
uint32_t pIndex_;
};
RingQueueTest.cc
#include "RingQueue.hpp"
void *producer(void *args)
{
RingQueue<int> *rqp = static_cast<RingQueue<int> *>(args);
while (true)
{
int data = rand() % 10;
rqp->push(data);
cout << "Propthread[" << pthread_self() << "]"
<< "生产了一个数据:" << data << endl;
sleep(1);
}
}
void *consumer(void *args)
{
RingQueue<int> *rqp = static_cast<RingQueue<int> *>(args);
while (true)
{
int data = rqp->pop();
cout << "Conpthread[" << pthread_self() << "]"
<< "消费了一个数据:" << data << endl;
}
}
int main()
{
srand((unsigned int)time(nullptr) ^ getpid());
RingQueue<int> rq;
pthread_t c1, p1;
pthread_create(&p1, nullptr, producer, &rq);
pthread_create(&c1, nullptr, consumer, &rq);
pthread_join(c1, nullptr);
pthread_join(p1, nullptr);
return 0;
}

(2)多生产者,多消费者
与单线程的区别:要上锁,使生产者与生产者之间生产互斥;消费者与消费者之间消费互斥。如果 sem_wait(&roomSem_);P--操作放在lock后面,sem_post(&dataSem_); 放在unlock前面,每次只能进入一个线程申请信号量,则信号量无法被多次的申请,只能互斥申请。但信号量本身就是资源的预定机制,就应该让多个资源一起申请,然后再一个一个排队执行锁内的生产过程。申请信号量是原子的,生产过程是非原子的,所以生产过程要被保护,消费过程同理。
// 生产
void push(const T &in)
{
sem_wait(&roomSem_);
pthread_mutex_lock(&pmutex_);
//sem_wait(&roomSem_); //如果放在lock后面,则信号量无法被多次的申请
ringqueue_[pIndex_] = in; //生产的过程
pIndex_++; // 写入位置后移
pIndex_ %= ringqueue_.size(); // 更新下标,保证环形特征
//sem_post(&dataSem_); //如果放在unlock前面
pthread_mutex_unlock(&pmutex_);
sem_post(&dataSem_);
}
Makefile
CC=g++
FLAGS=-std=c++11
LD=-lpthread
bin=ringQueue
src=RingQueueTest.cc
$(bin):$(src)
$(CC) -o $@ $^ $(LD) $(FLAGS)
.PHONY:clean
clean:
rm -f $(bin)
RingQueue.hpp
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <semaphore.h>
using namespace std;
const int gCap = 10;
template <class T>
class RingQueue
{
public:
RingQueue(int cap = gCap): ringqueue_(cap), pIndex_(0), cIndex_(0)
{
// 生产
sem_init(&roomSem_, 0, ringqueue_.size());
// 消费
sem_init(&dataSem_, 0, 0);
pthread_mutex_init(&pmutex_ ,nullptr);
pthread_mutex_init(&cmutex_ ,nullptr);
}
// 生产
void push(const T &in)
{
sem_wait(&roomSem_); //无法被多次的申请
pthread_mutex_lock(&pmutex_);
ringqueue_[pIndex_] = in; //生产的过程
pIndex_++; // 写入位置后移
pIndex_ %= ringqueue_.size(); // 更新下标,保证环形特征
pthread_mutex_unlock(&pmutex_);
sem_post(&dataSem_);
}
// 消费
T pop()
{
sem_wait(&dataSem_);
pthread_mutex_lock(&cmutex_);
T temp = ringqueue_[cIndex_];
cIndex_++;
cIndex_ %= ringqueue_.size();// 更新下标,保证环形特征
pthread_mutex_unlock(&cmutex_);
sem_post(&roomSem_);
return temp;
}
~RingQueue()
{
sem_destroy(&roomSem_);
sem_destroy(&dataSem_);
pthread_mutex_destroy(&pmutex_);
pthread_mutex_destroy(&cmutex_);
}
private:
vector<T> ringqueue_; // 唤醒队列
sem_t roomSem_; // 衡量空间计数器,productor
sem_t dataSem_; // 衡量数据计数器,consumer
uint32_t pIndex_; // 当前生产者写入的位置, 如果是多线程,pIndex_也是临界资源
uint32_t cIndex_; // 当前消费者读取的位置,如果是多线程,cIndex_也是临界资源
pthread_mutex_t pmutex_;
pthread_mutex_t cmutex_;
};
RingQueueTest.cc
#include "RingQueue.hpp"
#include <ctime>
#include <unistd.h>
// 我们是单生产者,单消费者
// 多生产者,多消费者??代码怎么改?
// 为什么呢???多生产者,多消费者?
// 不要只关心把数据或者任务,从ringqueue 放拿的过程,获取数据或者任务,处理数据或者任务,也是需要花时间的!
void *productor(void *args)
{
RingQueue<int> *rqp = static_cast<RingQueue<int> *>(args);
while(true)
{
int data = rand()%10;
rqp->push(data);
cout << "pthread[" << pthread_self() << "]" << " 生产了一个数据: " << data << endl;
//sleep(1);
}
}
void *consumer(void *args)
{
RingQueue<int> *rqp = static_cast<RingQueue<int> *>(args);
while(true)
{
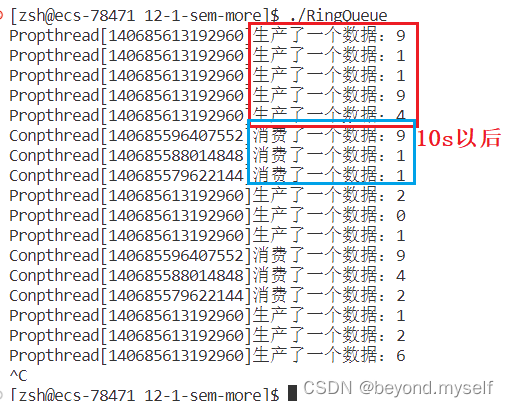
sleep(10);
int data = rqp->pop();
cout << "pthread[" << pthread_self() << "]" << " 消费了一个数据: " << data << endl;
}
}
int main()
{
srand((unsigned long)time(nullptr)^getpid());
RingQueue<int> rq;
pthread_t c1,c2,c3, p1,p2,p3;
pthread_create(&p1, nullptr, productor, &rq);
pthread_create(&p2, nullptr, productor, &rq);
pthread_create(&p3, nullptr, productor, &rq);
pthread_create(&c1, nullptr, consumer, &rq);
pthread_create(&c2, nullptr, consumer, &rq);
pthread_create(&c3, nullptr, consumer, &rq);
pthread_join(c1, nullptr);
pthread_join(c2, nullptr);
pthread_join(c3, nullptr);
pthread_join(p1, nullptr);
pthread_join(p2, nullptr);
pthread_join(p3, nullptr);
return 0;
}
四.线程池
**1. STL,****智能指针和线程安全 **
STL**中的容器是否是线程安全的? **
不是.
原因是, STL 的设计初衷是将性能挖掘到极致, 而一旦涉及到加锁保证线程安全, 会对性能造成巨大的影响.
而且对于不同的容器, 加锁方式的不同, 性能可能也不同(例如hash表的锁表和锁桶).
因此 STL 默认不是线程安全. 如果需要在多线程环境下使用, 往往需要调用者自行保证线程安全.
智能指针是否是线程安全的**? **
对于 unique_ptr, 由于只是在当前代码块范围内生效, 因此不涉及线程安全问题.
对于 shared_ptr, 多个对象需要共用一个引用计数变量, 所以会存在线程安全问题. 但是标准库实现的时候考虑到了这个问题, 基于原子操作(CAS)的方式保证 shared_ptr 能够高效, 原子的操作引用计数.(shared_ptr是线程安全的)
**12. ****其他常见的各种锁 **
悲观锁:在每次取数据时,总是担心数据会被其他线程修改,所以会在取数据前先加锁(读锁,写锁,行锁等),当其他线程想要访问数据时,被阻塞挂起。
乐观锁:每次取数据时候,总是乐观的认为数据不会被其他线程修改,因此不上锁。但是在更新数据前,会判断其他数据在更新前有没有对数据进行修改。主要采用两种方式:版本号机制和CAS操作。
CAS操作:当需要更新数据时,判断当前内存值和之前取得的值是否相等。如果相等则用新值更新。若不等则失败,失败则重试,一般是一个自旋的过程,即不断重试。
自旋锁(phtread_spin_init/lock),公平锁,非公平锁
故事:你请张三吃饭,但是张三说需要再等1个小时,那么你会去上网(挂起),然后等会再来找他;如果张三说需要再等一小会儿,那么你会在楼下等,并且等一会儿就给他打个电话问问好了没,张三说马上,你就再等一会儿,然后再打电话。
是什么决定了你在楼下,是以什么方式等待张三的? ?
在临界区中等待时间决定的
①等待时间短——>轮询测试,是否就绪。pthread_ spin_ lock(phtread_spin_init/lock,使用自旋锁只需要mutex->spin即可
PCB—>S —>阻塞的;pthread—>while(true)—>阻塞的!
②等待时间长——>去上网的路上,上网(挂起),回来的路上->阻塞前,阻塞中,阻塞后。挂起等待锁(在临界区中IO操作,系统调用花时间就长)
概念:本质是对执行流的预先分配,当有任务时直接指定线程完成对应任务,而不需要再现场创建线程。
2.线程池代码
(1)线程池
易错点:① start()中assert忘写
②线程池用智能指针维护
③因为类内的函数threadRoutine多传了一个this指针,所以和pthread_ create(&temp, nullptr, threadRoutine, this);里面的threadRoutine类型不匹配了,所以threadRoutine函数定义成static去掉隐含this才能类型匹配,并且pthread_ create传入this指针
④choiceThreadForHandler(); 选择一个线程去执行
void push(const T &in)
{
lockQueue();
taskQueue_.push(in);
choiceThreadForHandler();
unlockQueue();
}
Log.hpp
#pragma once
#include <iostream>
#include <ctime>
#include <pthread.h>
std::ostream &Log()
{
std::cout << "Fot Debug |" << " timestamp: " << (uint64_t)time(nullptr) << " | " << " Thread[" << pthread_self() << "] | ";
return std::cout;
}
Task.hpp
#pragma once
#include<iostream>
class Task
{
public:
Task() : elemOne_(0), elemTwo_(0), operator_('0')
{
}
Task(int one, int two, char op) : elemOne_(one), elemTwo_(two), operator_(op)
{
}
int operator()()
{
return run();
}
int run()
{
int result = 0;
switch (operator_)
{
case '+':
result = elemOne_ + elemTwo_;
break;
case '-':
result = elemOne_ - elemTwo_;
break;
case '*':
result = elemOne_ * elemTwo_;
break;
case '/':
{
if(elemTwo_==0)
{
std::cout<<"div zero,abort"<<std::endl;
result= -1;
}
else
{
result = elemOne_ / elemTwo_;
}
}
break;
case '%':
{
if(elemTwo_==0)
{
std::cout<<"mod zero,abort"<<std::endl;
result= -1;
}
else
{
result = elemOne_ % elemTwo_;
}
}
break;
default:
std::cout<<"非法操作: " <<operator_<<std::endl;
break;
}
return result;
}
void get(int* e1,int* e2,char* op)
{
*e1=elemOne_;
*e2=elemTwo_;
*op=operator_;
}
private:
int elemOne_;
int elemTwo_;
char operator_;
};
ThreadPool.hpp
#include"Log.hpp"
#include<queue>
#include<string>
#include<cstdlib>
#include<cassert>
#include<pthread.h>
#include<memory>
#include<iostream>
using namespace std;
#include<unistd.h>
int gThreadNum=5;
template<class T>
class ThreadPool
{
public:
ThreadPool(int threadNum=gThreadNum):threadNum_(threadNum),isStart_(false)
{
pthread_mutex_init(&mutex_,nullptr);
pthread_cond_init(&cond_,nullptr);
}
~ThreadPool()
{
pthread_mutex_destroy(&mutex_);
pthread_cond_destroy(&cond_);
}
void push(const T& in)
{
lockQueue();
taskQueue_.push(in);
choiceThreadForHander();
unlockQueue();
//sleep(1);
}
static void* threadRoutine(void* args)
{
pthread_detach(pthread_self());
ThreadPool<T>* tp=static_cast<ThreadPool<T>*>(args);
while(true)
{
tp->lockQueue();
while(!tp->haveTask())
{
tp->waitForTask();
}
T t=tp->pop();
tp->unlockQueue();
int one,two;
char oper;
t.get(&one,&two,&oper);
Log()<<"新线程完成计算任务:"<<one<<oper<<two<<"="<<t.run()<<endl;
//cout<<"pthread["<<pthread_self()<<"]running……"<<endl;
}
}
void start()
{
assert(!isStart_); //防止线程池被重复启动
for(int i=0;i<threadNum_;i++)
{
pthread_t temp;
pthread_create(&temp,nullptr,threadRoutine,(void*)this);
}
isStart_=true;
}
private:
T pop()
{
T temp=taskQueue_.front();
taskQueue_.pop();
return temp;
}
bool haveTask()
{
return !taskQueue_.empty();
}
void waitForTask()
{
pthread_cond_wait(&cond_,&mutex_);
}
void lockQueue()
{
pthread_mutex_lock(&mutex_);
}
void unlockQueue()
{
pthread_mutex_unlock(&mutex_);
}
void choiceThreadForHander()
{
pthread_cond_signal(&cond_);
}
private:
bool isStart_;
int threadNum_;
queue<T> taskQueue_;
pthread_mutex_t mutex_;
pthread_cond_t cond_;
};
ThreadPool.cc
#include"ThreadPool.hpp"
#include"Task.hpp"
int main()
{
const string operators ="+/*/%";
unique_ptr<ThreadPool<Task>> tp(new ThreadPool<Task>());
tp->start();
srand((unsigned int)time(nullptr)^getpid()^pthread_self());
while(true)
{
int one=rand()%50;
int two=rand()%50;
char oper=operators[rand()%operators.size()];
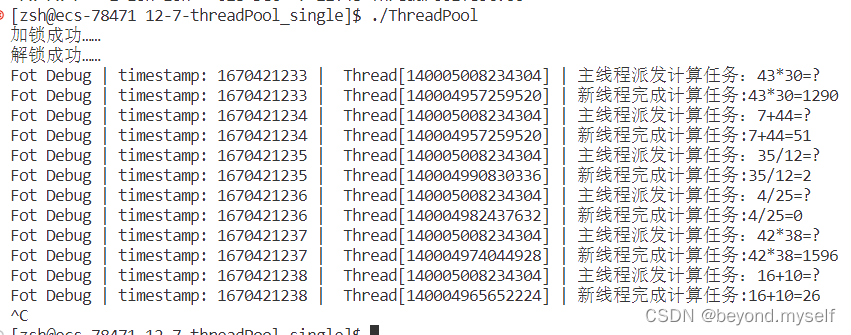
Log()<<"主线程派发计算任务:"<<one<<oper<<two<<"=?"<<endl;
Task t(one,two,oper);
tp->push(t);
//sleep(1);
}
//while(1);
return 0;
}
(2)线程池单例模式
变化:①私有化构造(析构不用私有,设为公有即可,仅仅把构造函数私有化就可以实现单例模式,单例对象也需要) ②delete了 operator=,拷贝构造。③多了静态成员变量instance。
Log.hpp
#pragma once
#include <iostream>
#include <ctime>
#include <pthread.h>
std::ostream &Log()
{
std::cout << "Fot Debug |" << " timestamp: " << (uint64_t)time(nullptr) << " | " << " Thread[" << pthread_self() << "] | ";
return std::cout;
}
Lock.hpp
#pragma once
#include <iostream>
#include <pthread.h>
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&lock_, nullptr);
}
void lock()
{
pthread_mutex_lock(&lock_);
}
void unlock()
{
pthread_mutex_unlock(&lock_);
}
~Mutex()
{
pthread_mutex_destroy(&lock_);
}
private:
pthread_mutex_t lock_;
};
class LockGuard
{
public:
LockGuard(Mutex *mutex) : mutex_(mutex)
{
mutex_->lock();
std::cout << "加锁成功..." << std::endl;
}
~LockGuard()
{
mutex_->unlock();
std::cout << "解锁成功...." << std::endl;
}
private:
Mutex *mutex_;
};
Task.hpp
#pragma once
#include <iostream>
#include <string>
class Task
{
public:
Task() : elemOne_(0), elemTwo_(0), operator_('0')
{
}
Task(int one, int two, char op) : elemOne_(one), elemTwo_(two), operator_(op)
{
}
int operator() ()
{
return run();
}
int run()
{
int result = 0;
switch (operator_)
{
case '+':
result = elemOne_ + elemTwo_;
break;
case '-':
result = elemOne_ - elemTwo_;
break;
case '*':
result = elemOne_ * elemTwo_;
break;
case '/':
{
if (elemTwo_ == 0)
{
std::cout << "div zero, abort" << std::endl;
result = -1;
}
else
{
result = elemOne_ / elemTwo_;
}
}
break;
case '%':
{
if (elemTwo_ == 0)
{
std::cout << "mod zero, abort" << std::endl;
result = -1;
}
else
{
result = elemOne_ % elemTwo_;
}
}
break;
default:
std::cout << "非法操作: " << operator_ << std::endl;
break;
}
return result;
}
int get(int *e1, int *e2, char *op)
{
*e1 = elemOne_;
*e2 = elemTwo_;
*op = operator_;
}
private:
int elemOne_;
int elemTwo_;
char operator_;
};
ThreadPool.hpp
#pragma once
#include <iostream>
#include <cassert>
#include <queue>
#include <memory>
#include <cstdlib>
#include <pthread.h>
#include <unistd.h>
#include <sys/prctl.h>
#include "Log.hpp"
#include "Lock.hpp"
using namespace std;
int gThreadNum = 5;
template <class T>
class ThreadPool
{
private:
ThreadPool(int threadNum = gThreadNum) : threadNum_(threadNum), isStart_(false)
{
assert(threadNum_ > 0);
pthread_mutex_init(&mutex_, nullptr);
pthread_cond_init(&cond_, nullptr);
}
ThreadPool(const ThreadPool<T> &) = delete;
void operator=(const ThreadPool<T>&) = delete;
public:
static ThreadPool<T> *getInstance()
{
static Mutex mutex;
if (nullptr == instance) //仅仅是过滤重复的判断
{
LockGuard lockguard(&mutex); //进入代码块,加锁。退出代码块,自动解锁
if (nullptr == instance)
{
instance = new ThreadPool<T>();
}
}
return instance;
}
//类内成员, 成员函数,都有默认参数this
static void *threadRoutine(void *args)
{
pthread_detach(pthread_self());
ThreadPool<T> *tp = static_cast<ThreadPool<T> *>(args);
prctl(PR_SET_NAME, "follower");
while (1)
{
tp->lockQueue();
while (!tp->haveTask())
{
tp->waitForTask(); //无数据就在条件变量下排队等待
}
//这个任务就被拿到了线程的上下文中
T t = tp->pop();
tp->unlockQueue();
// for debug
int one, two;
char oper;
t.get(&one, &two, &oper);
//规定,所有的任务都必须有一个run方法
Log() << "新线程完成计算任务: " << one << oper << two << "=" << t.run() << "\n";
}
}
void start()
{
assert(!isStart_); //防止线程池被重复启动
for (int i = 0; i < threadNum_; i++)
{
pthread_t temp;
pthread_create(&temp, nullptr, threadRoutine, this);
}
isStart_ = true;
}
void push(const T &in)
{
lockQueue();
taskQueue_.push(in);
choiceThreadForHandler();//指定某个线程去执行,即:唤醒某个线程
unlockQueue();
}
~ThreadPool()
{
pthread_mutex_destroy(&mutex_);
pthread_cond_destroy(&cond_);
}
private:
void lockQueue() { pthread_mutex_lock(&mutex_); }
void unlockQueue() { pthread_mutex_unlock(&mutex_); }
bool haveTask() { return !taskQueue_.empty(); } //有线程就是true
void waitForTask() { pthread_cond_wait(&cond_, &mutex_); }
void choiceThreadForHandler() { pthread_cond_signal(&cond_); }
T pop()
{
T temp = taskQueue_.front();
taskQueue_.pop();
return temp;
}
private:
bool isStart_; //表示当前线程池是否已经启动
int threadNum_; //线程个数
queue<T> taskQueue_;
pthread_mutex_t mutex_;
pthread_cond_t cond_;
static ThreadPool<T> *instance;
// const static int a = 100;
};
template <class T>
ThreadPool<T> *ThreadPool<T>::instance = nullptr;
ThreadPoolTest.cc
#include "ThreadPool.hpp"
#include "Task.hpp"
#include <ctime>
#include <thread>
// 如何对一个线程进行封装, 线程需要一个回调函数,支持lambda
// class tread{
// };
int main()
{
prctl(PR_SET_NAME, "master"); //给线程加名字
const string operators = "+/*/%";
// unique_ptr<ThreadPool<Task> > tp(new ThreadPool<Task>());
unique_ptr<ThreadPool<Task> > tp(ThreadPool<Task>::getInstance());
tp->start();
srand((unsigned long)time(nullptr) ^ getpid() ^ pthread_self());
// 派发任务的线程
while(true)
{
int one = rand()%50;
int two = rand()%10;
char oper = operators[rand()%operators.size()];
Log() << "主线程派发计算任务: " << one << oper << two << "=?" << "\n";
Task t(one, two, oper);
tp->push(t);
sleep(1);
}
}
五.读者写者问题(了解)
1.读写锁概念(rwlock)
在编写多线程的时候,有一种情况是十分常见的。那就是,有些公共数据修改的机会比较少。相比较改写,它们读的机会反而高的多。通常而言,在读的过程中,往往伴随着查找的操作,中间耗时很长。给这种代码段加锁,会极大地降低我们程序的效率。那么有没有一种方法,可以专门处理这种多读少写的情况呢? 有,那就是读写锁。
2.和生产消费者模型一样的321原则
321原则
2:读者和写者
1:1个读写场所
3:写者和写者——互斥;读者和读者——没有关系,可以并发执行;读者和写者——互斥关系
读者写者vs生产者消费者本质区别:消费者会把数据拿走,而读者不会!
读者:写者=n:1
读者 写者
加读锁 加写锁
读取内容 写入修改内容
释放锁 释放锁
3.接口
(把mutex改成rwlock即可)
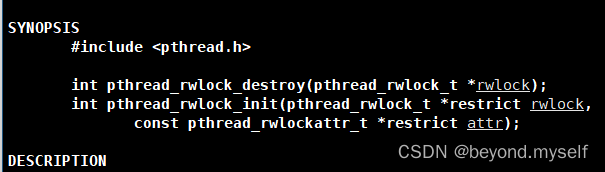
(1)初始化、销毁读写锁
man 3 pthread_rwlock_init
(2)加读者锁
读者写者用的同一把锁,只是身份不同,执行的代码不同
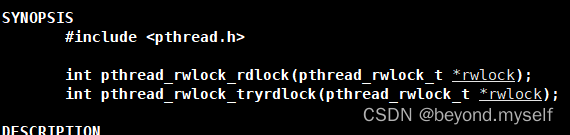
man 3 pthread_rwlock_rdlock
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock); 阻塞加锁
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock); 非阻塞加锁
读者 pthread_ rwlock_ rdlock () 原理:
lock (mutex)
readers++;
unlock (mutex)
read操作
lock (mutex)
readers-- ;
unlock (mutex)
(3)加写者锁
读者写者用的同一把锁,只是身份不同,执行的代码不同
man 3 pthread_rwlock_wrlock
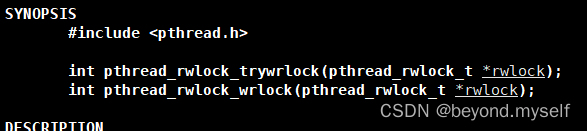
写者pthread_ rwlock_ wrlock()原理:
lock (mutex)
while (readers>0)释放锁,wait(wait会自动释放锁)
write操作
unlock (mutex) ;
(4)释放锁
man 3 pthread_rwlock_unlock
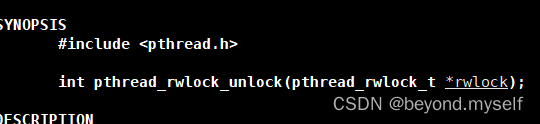
4.特点
读者写者进行操作的时候,读者非常多,频率个别高;写者比较少,频率不高。
两种简单的策略:读者优先(默认策略) 或 写者优先(让当前读者读完,之后的读者阻塞,让写者先进入写)
5.测试代码
makefile
readerAndWriter:readerAndWriter.cc
g++ -o $@ $^ -lpthread -std=c++11
.PHONY:clean
clean:
rm -f readerAndWriter
readerAndWriter.cc
#include <iostream>
#include <unistd.h>
#include <pthread.h>
int board = 0;
pthread_rwlock_t rw;
using namespace std;
void *reader(void* args)
{
const char *name = static_cast<const char *>(args);
cout << "run..." << endl;
while(true)
{
pthread_rwlock_rdlock(&rw);
cout << "reader read : " << board << "tid: " << pthread_self() << endl;
sleep(10);
pthread_rwlock_unlock(&rw);
}
}
void *writer(void *args)
{
const char *name = static_cast<const char *>(args);
sleep(1);
while(true)
{
pthread_rwlock_wrlock(&rw);
board++;
cout << "I am writer" << endl;
sleep(10);
pthread_rwlock_unlock(&rw);
}
}
int main()
{
pthread_rwlock_init(&rw, nullptr);
pthread_t r1,r2,r3,r4,r5,r6, w;
pthread_create(&r1, nullptr, reader, (void*)"reader");
pthread_create(&r2, nullptr, reader, (void*)"reader");
pthread_create(&r3, nullptr, reader, (void*)"reader");
pthread_create(&r4, nullptr, reader, (void*)"reader");
pthread_create(&r5, nullptr, reader, (void*)"reader");
pthread_create(&r6, nullptr, reader, (void*)"reader");
pthread_create(&w, nullptr, writer, (void*)"writer");
pthread_join(r1, nullptr);
pthread_join(r2, nullptr);
pthread_join(r3, nullptr);
pthread_join(r4, nullptr);
pthread_join(r5, nullptr);
pthread_join(r6, nullptr);
pthread_join(w, nullptr);
pthread_rwlock_destroy(&rw);
return 0;
}
版权归原作者 beyond.myself 所有, 如有侵权,请联系我们删除。