
一、基础配置
我们公司yarn node节点的可用资源配置为:单台node节点可用资源数:核数33cores、内存110G。Hive on Spark任务的基础配置,主要配置对象包括:Executor和Driver内存,Executor配额,任务并行度。

1、Executor内存和核数
配置参数为spark.executor.memory和spark.executor.cores。如果要最大化使用core,建议将core设置为4、5、6,且满足core的个数尽量可以整除yarn资源核数。yarn资源可用33核,建议spark.executor.cores设置为4,最多剩下一个core,如果设置为5,6都会有3个core剩余。 spark.executor.cores=4,由于总共有33个核,那么最大可以申请的executor数是8。总内存处以8,也即是 110/8,可以得到每个executor约13.75GB内存。
建议 spark.executor.memoryOverhead(spark的executor堆外内存)站总内存的 15%-20%。 那么最终 spark.executor.memoryOverhead=2.75 G 和spark.executor.memory=11 G
注意:默认情况下 spark.executor.memoryOverhead = max(executorMemory * 0.10, 384M),正常情况下不需要手动设置spark堆外内存,如果spark任务出现如下报错,可以手动提高堆外内存大小。
注意:默认情况下 spark.executor.memoryOverhead = max(executorMemory * 0.10, 384M),正常情况下不需要手动设置spark堆外内存,如果spark任务出现如下报错,可以手动提高堆外内存大小。
Container killed by YARN for exceeding memory limits. 16.9 GB of 16 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
2、Driver内存
对于drvier的内存配置,主要有两个参数:
- spark.driver.memoryOverhead 每个driver能从yarn申请的堆外内存的大小。
- spark.driver.memory 当运行hive on spark的时候,每个spark driver能申请的最大jvm 堆内存。该参数结合 spark.driver.memoryOverhead共同决定着driver的内存大小。
Driver的内存通常来说不设置,或者设置1G左右应该就够了。需要注意的是,如果需要使用collect算子将RDD的数据全部拉取到Driver端进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
3、Executor个数
配置参数为spark.executor.instances。该参数用于设置Spark作业总共要用多少个Executor进程来执行。
executor的数目是由每个节点运行的executor数目和集群的节点数共同决定。我们离线集群27个节点,那么离线spark任务使用的最大executor数就是 216(27*8). 最大数目可能比这个小点,因为driver也会消耗核数和内存。
该参数可以结合spark.executor.cores设置,默认单个spark任务最大不超过60cores,spark.executor.cores设置为4,则spark.executor.instances不超过15。
4、并行度
设置spark任务的并行度参数为spark.default.parallelism。spark任务每个stage的task个数=max(spark.default.parallelism, HDFS的block数量)。如果不设置该参数,Spark自己根据底层HDFS的block数量来设置task的数量,默认是一个HDFS block对应一个task。spark默认spark.default.parallelism配置较少,如果task个数比较少的话,前面spark资源配置没有意义。官网建议:该参数设置为 num-executors * executor-cores的2~3倍较为合适。
5、参数配置
SET hive.execution.engine=spark;
-- 修改spark on yarn的资源队列
SET spark.yarn.queue=root.dw_offline_day;
-- 设置Driver内存
SET spark.driver.memory=1G;
-- 设置Executor核数
SET spark.executor.cores=4;
-- 设置Executor内存
SET spark.executor.memory=11G;
-- 设置Executor个数
SET spark.executor.instances=10;
-- 设置spark任务并行度
SET spark.default.parallelism=120;
二、动态资源分配
当一个运行时间比较长的spark任务,如果分配给他多个Executor,可是却没有task分配给它,而此时有其他的yarn任务资源紧张,这就造成了很大的资源浪费和资源不合理的调度。动态资源调度就是为了解决这种场景,根据当前应用任务的负载情况,实时的增减Executor个数,从而实现动态分配资源,使整个Spark系统更加健康。
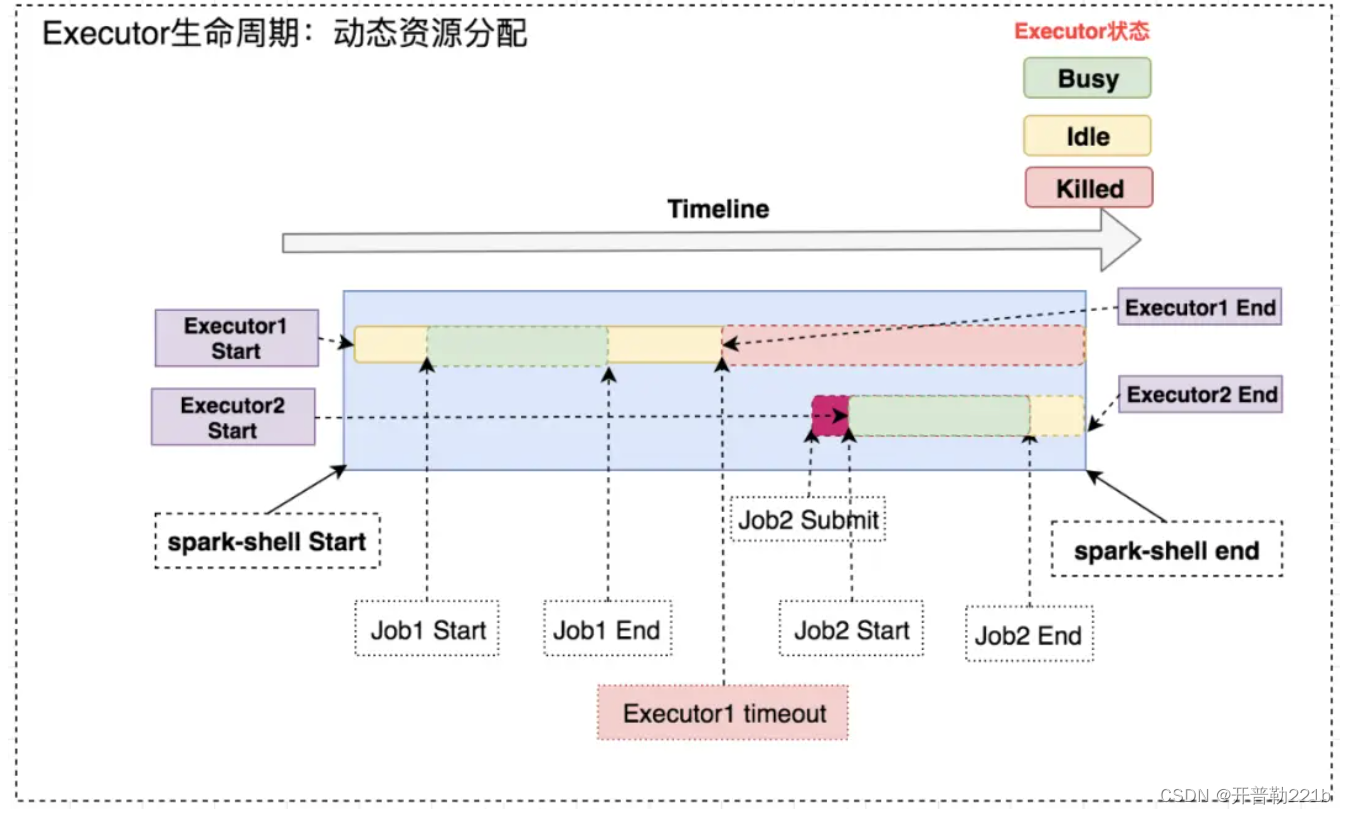
1、资源分配策略
开启spark动态资源分配后,application会在task因没有足够资源被挂起的时候去动态申请资源。当任务挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)的时间后,会开始动态资源分配;之后每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
2、资源回收策略
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
3、参数配置
SET hive.execution.engine=spark;
-- 修改spark on yarn的资源队列
SET spark.yarn.queue=root.dw_offline_day;
-- 设置Driver内存
SET spark.driver.memory=1G;
-- 设置Executor核数
SET spark.executor.cores=4;
-- 设置Executor内存
SET spark.executor.memory=8G;
-- 开启动态资源分配
SET spark.dynamicAllocation.enabled=true;
-- 每个Application最小分配的executor数
SET spark.dynamicAllocation.minExecutors=1;
-- 如果所有的executor都移除了,重新请求时启动的初始executor数
SET spark.dynamicAllocation.initialExecutors=1;
-- 每个Application最大并发分配的executor数
SET spark.dynamicAllocation.maxExecutors=15;
-- 有新任务处于等待状态,并且等待时间超过该时间段,会依次启动executor, 每次启动1,2,4,8...个executor
SET spark.dynamicAllocation.schedulerBacklogTimeout=1s;
-- 动态启动executor的间隔
SET spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s;
三、小文件合并
1、参数配置
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=false;
SET hive.merge.sparkfiles=true;
-- 当输出文件的平均大小小于该值时,启动单独的任务进行文件merge
SET hive.merge.smallfiles.avgsize=16000000;
-- 合并文件的大小(默认256M)
SET hive.merge.size.per.task=256000000;
四、动态分区使用
使用场景:同一个SQL语句需要同时更新多个分区,类似于如下SQL语句:
INSERT OVERWRITE TABLE table_name PARTITION (dt)
SELECT id, name, dt
FROM ...
1、参数说明
(1)hive.exec.dynamic.partition
- 默认值:false
- 说明:是否启动动态分区
(2)hive.exec.dynamic.partition.mode
- 默认值:strict
- 说明:打开动态分区后,动态分区的模式,有strict和nonstrict两种模式,strict要求至少包含一个静态分区列,nonstrict则无此要求。
(3)hive.exec.max.dynamic.partitions
- 默认值:100000
- 说明:允许的最大的动态分区的个数。可以手动增加分区。
(4)hive.exec.max.dynamic.partitions.pernode
- 默认值:100
- 说明:在每个执行任务的节点上,最大可以创建多少个动态分区。
(5)hive.exec.default.partition.name
- 默认值: HIVE_DEFAULT_PARTITION
- 说明:在hive里面表可以创建成分区表,但是当分区字段的值是’’ 或者 null时,hive会自动将分区命名为默认分区名称。默认情况下,默认分区的名称为HIVE_DEFAULT_PARTITION,默认分区名称是可配置的。
2、参数配置
SET hive.exec.dynamic.partition=TRUE;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=100000;
SET hive.exec.max.dynamic.partitions.pernode=100000;
五、Hive参数配置
1、参数配置
-- 如果一个简单查询只包括一个group by和order by,此处可以设置为1或2。适用于模型层维度表处理
SET hive.optimize.reducededuplication.min.reducer=4;
-- 如果数据已经根据相同的key做好聚合,那么去除掉多余的map/reduce作业
SET hive.optimize.reducededuplication=true;
-- Map Join优化, 不太大的表直接通过map过程做join
SET hive.auto.convert.join=true;
SET hive.auto.convert.join.noconditionaltask=true;
-- Map Join任务HashMap中key对应value数量
SET hive.smbjoin.cache.rows=10000;
-- 可以被转化为HashMap放入内存的表的大小(官方推荐853M)
SET hive.auto.convert.join.noconditionaltask.size=200M;
-- 如果数据按照join的key分桶,hive将简单优化inner join(官方推荐关闭)
SET hive.optimize.bucketmapjoin= false;
SET hive.optimize.bucketmapjoin.sortedmerge=false;
-- 所有map任务可以用作Hashtable的内存百分比, 如果OOM, 调小这个参数(官方默认0.5)
SET hive.map.aggr.hash.percentmemory=0.5;
-- map端聚合(跟group by有关), 如果开启, Hive将会在map端做第一级的聚合, 会用更多的内存,开启这个参数 sum(1)会有类型转换问题
SET hive.map.aggr=false;
-- 将只有SELECT, FILTER, LIMIT转化为FETCH, 减少等待时间
SET hive.fetch.task.conversion=more;
SET hive.fetch.task.conversion.threshold=1073741824;
-- 新创建的表/分区是否自动计算统计数据
SET hive.stats.autogather=true;
SET hive.compute.query.using.stats=true;
SET hive.stats.fetch.column.stats=true;
SET hive.stats.fetch.partition.stats=true;
-- 在order by limit查询中分配给存储Top K的内存为10%
SET hive.limit.pushdown.memory.usage=0.1;
-- 是否开启自动使用索引
SET hive.optimize.index.filter=true;
版权归原作者 开普勒524c 所有, 如有侵权,请联系我们删除。