
一、爬虫工具
- selenium 是一个模拟浏览器操作的工具,背后有google 维护源代码,支持全部主流浏览器,支持主流的编程语言,包括:java,Python,C#,PHP,Ruby,等,在本项目上使用的Java语言。 官网:https://www.selenium.dev/documentation/
- ChromeDriver 使用selenium是需要浏览器的配合, chromeDriver,是谷歌浏览器的一个驱动, selenium借助chromeDriver,实现模拟对浏览器的各种操作。·
二、环境搭建
1、下载chromeDriver
http://chromedriver.storage.googleapis.com/index.html
下载的驱动要和自己安装的谷歌浏览器版本相互匹配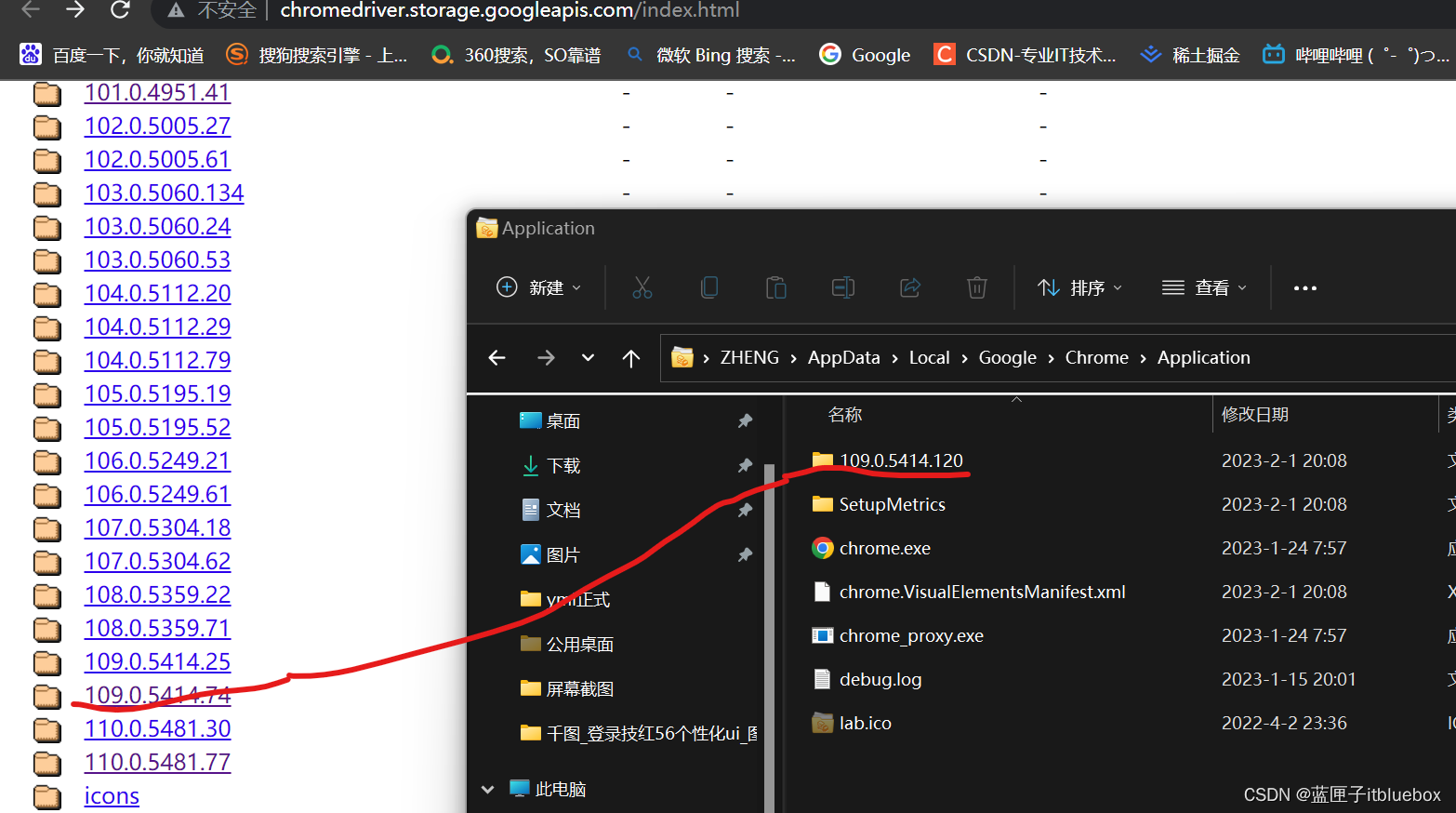
解压以后找个位置放一下
2、创建idea项目
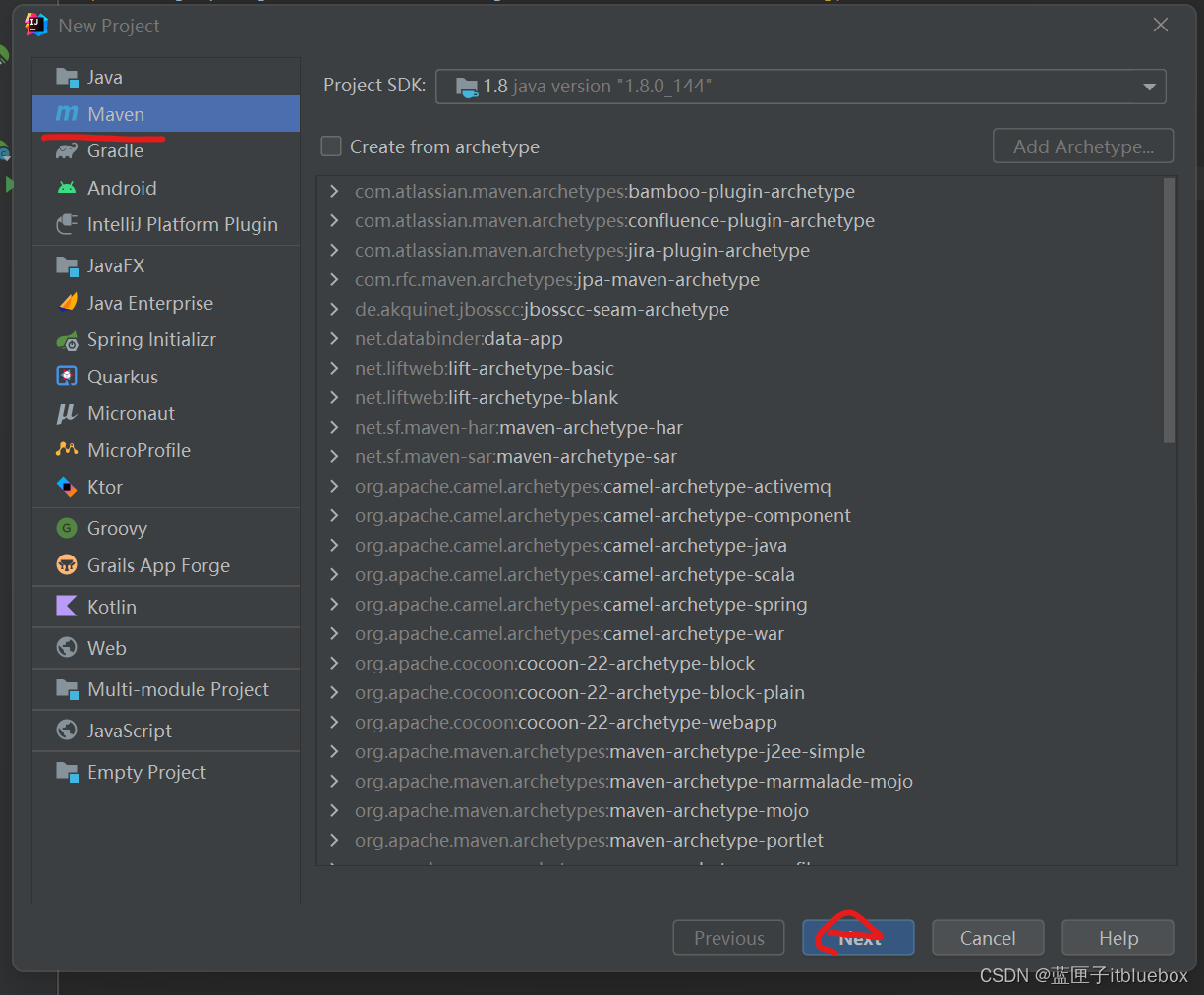
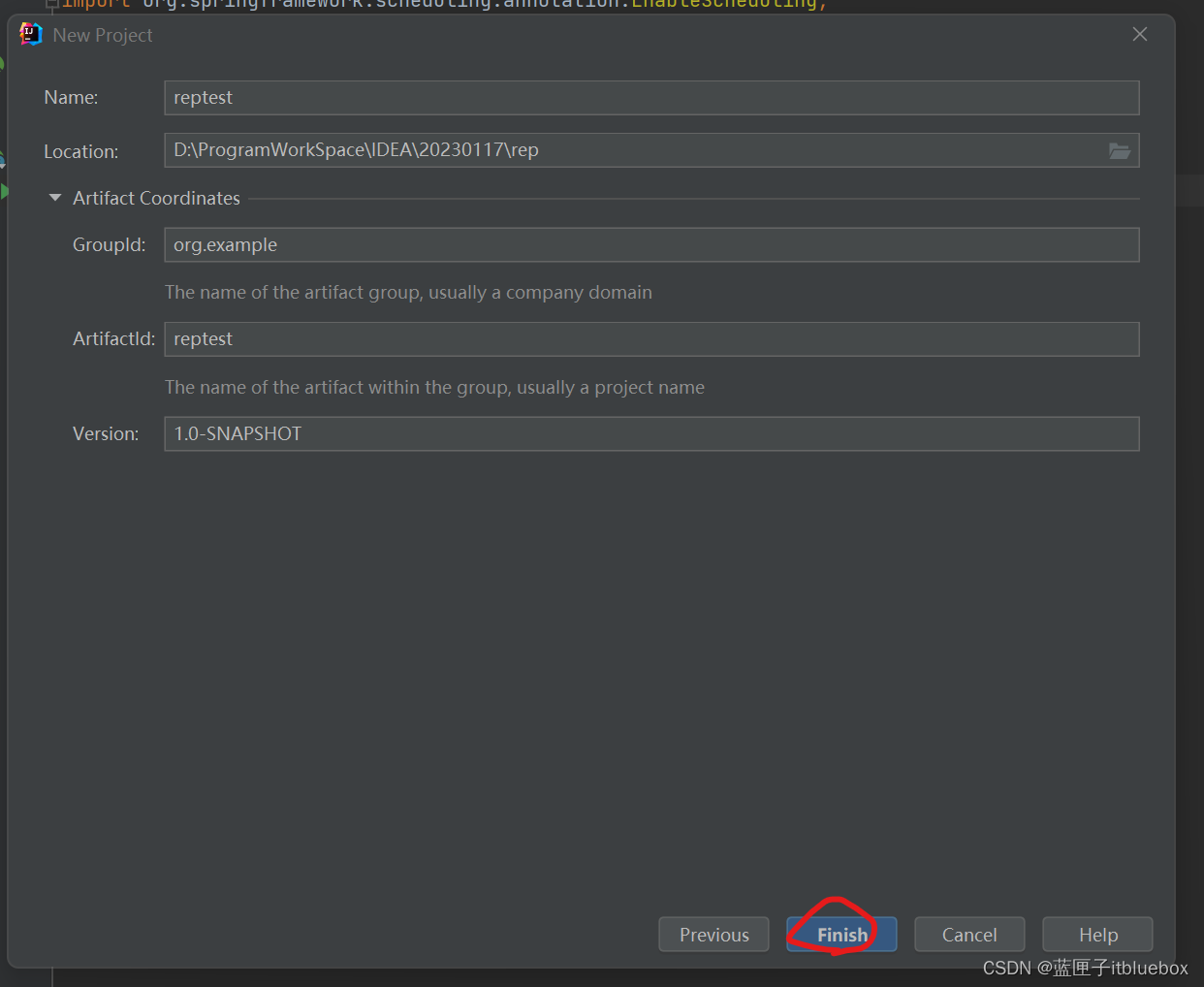
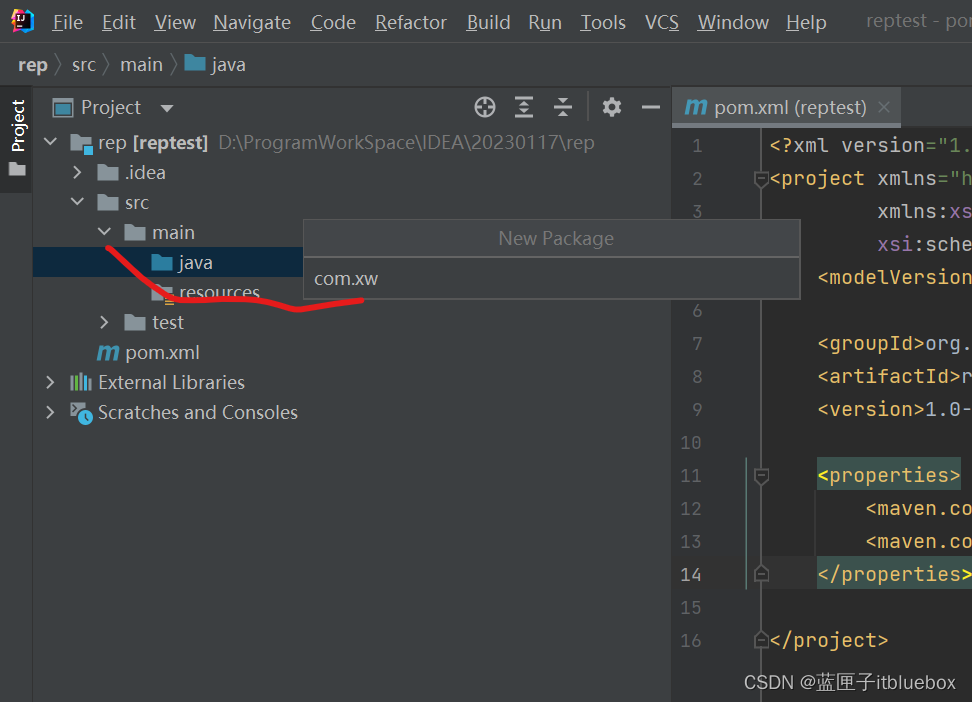
3、导入maven依赖
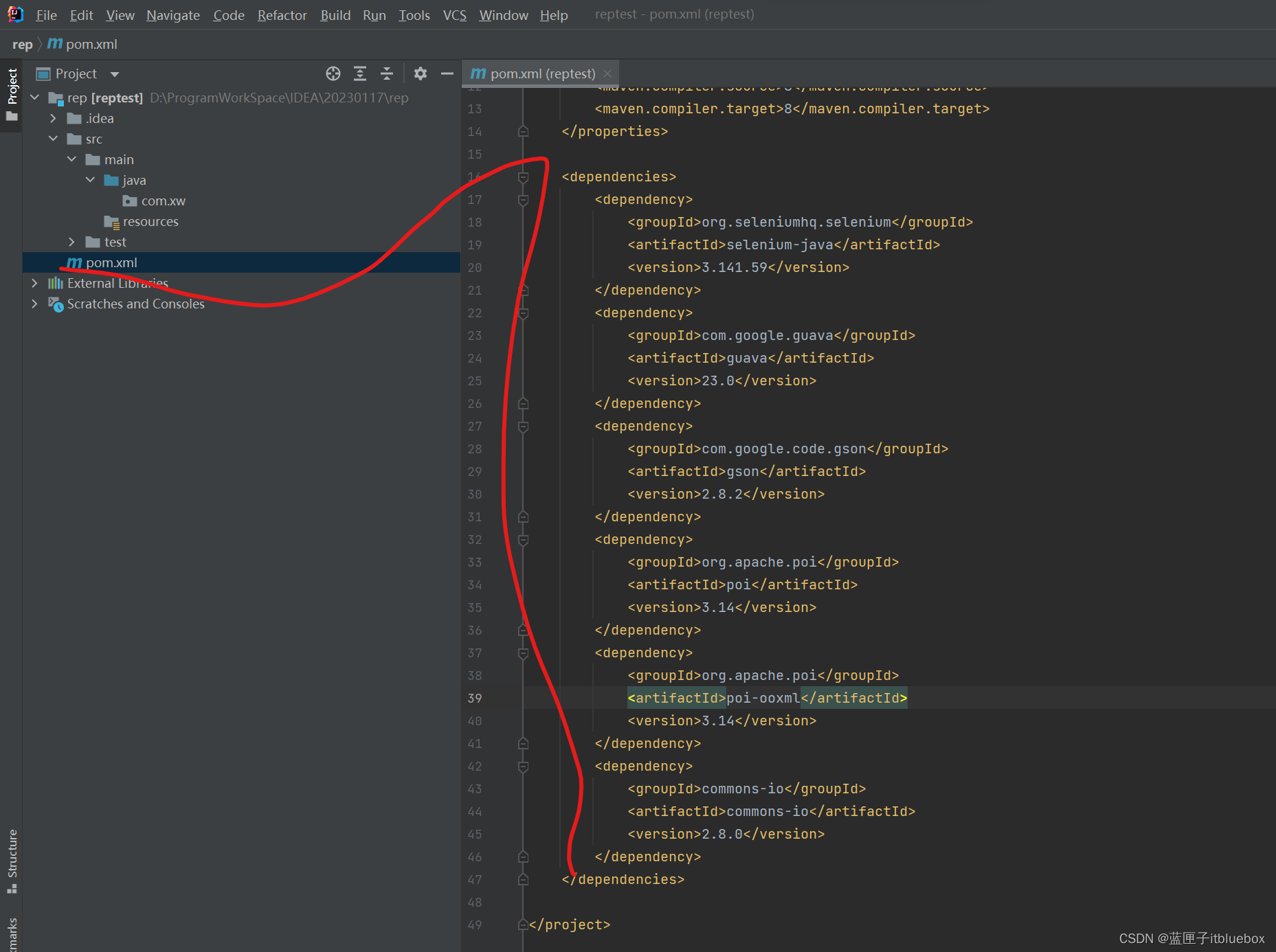
<dependencies><dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>3.141.59</version></dependency><dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>23.0</version></dependency><dependency><groupId>com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.14</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>3.14</version></dependency><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.8.0</version></dependency></dependencies>
4、编写测试类
三、运行案例
案例:百度搜索王者荣耀,
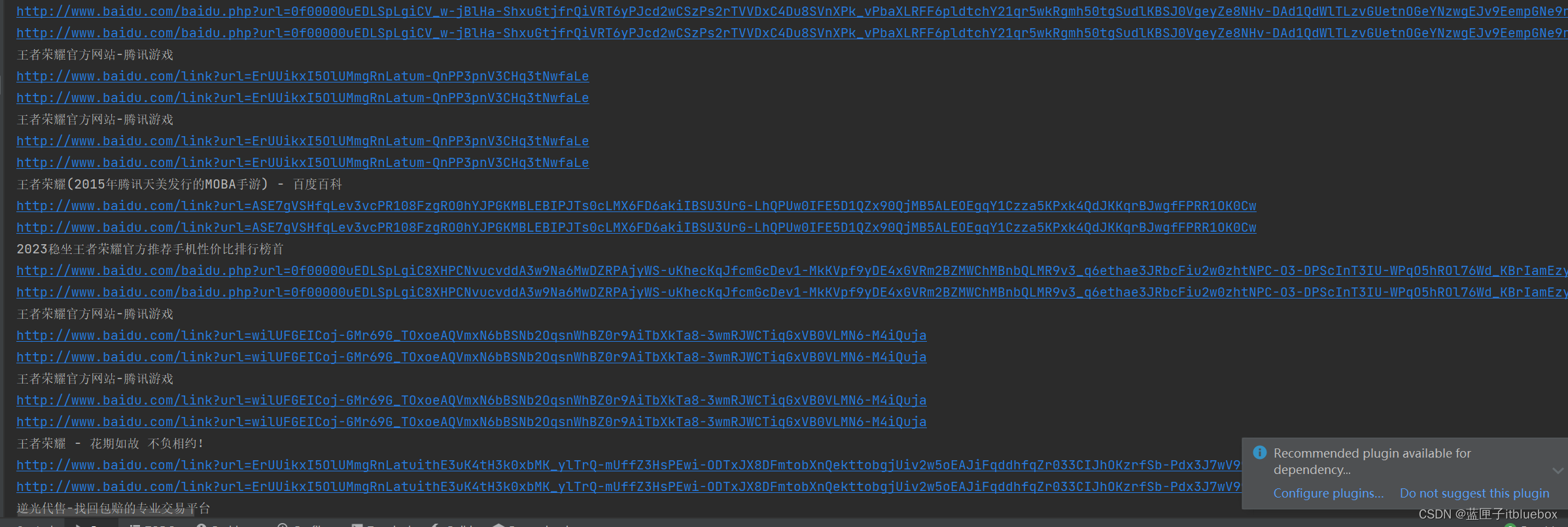
将搜索出的内容列表保存成excel文件,
内容主要包含内容名称和url
packagecom.xw;importorg.openqa.selenium.By;importorg.openqa.selenium.JavascriptExecutor;importorg.openqa.selenium.Keys;importorg.openqa.selenium.WebElement;importorg.openqa.selenium.chrome.ChromeDriver;importorg.openqa.selenium.interactions.Actions;importjava.util.List;importjava.util.concurrent.TimeUnit;publicclassTest{publicstaticvoidmain(String[] args){//加载谷歌浏览器驱动System.getProperties().setProperty("webdriver.chrome.driver","D:\\ProgramSoftware\\chromedriver_win32\\chromedriver_win32 (2)\\chromedriver.exe");ChromeDriver chromeDriver =newChromeDriver();try{Thread.sleep(3000);}catch(Exception e){
e.printStackTrace();}//设置访问地址String url ="https://www.baidu.com/";
chromeDriver.get(url);//在id为kw的输入框当中输入内容WebElement kw = chromeDriver.findElement(By.id("kw"));
kw.sendKeys("王者荣耀");//在id为su的按钮上点击WebElement su = chromeDriver.findElement(By.id("su"));
su.click();try{//设置等待
chromeDriver.manage().timeouts().implicitlyWait(60,TimeUnit.SECONDS);}catch(Exception e){
e.printStackTrace();}//找到搜索后左边的内容WebElement content_left = chromeDriver.findElement(By.id("content_left"));List<WebElement> elements = content_left.findElements(By.cssSelector(".c-container"));//遍历出来需要的元素和内容for(WebElement page : elements){WebElement h3_a = page.findElement(By.cssSelector("h3 a"));String text = h3_a.getText();String href = h3_a.getAttribute("href");System.out.println(text);System.out.println(href);WebElement a = page.findElement(By.cssSelector("a"));String hrefa = a.getAttribute("href");System.out.println(hrefa);}try{Thread.sleep(5000);}catch(Exception e){
e.printStackTrace();}
chromeDriver.quit();}}
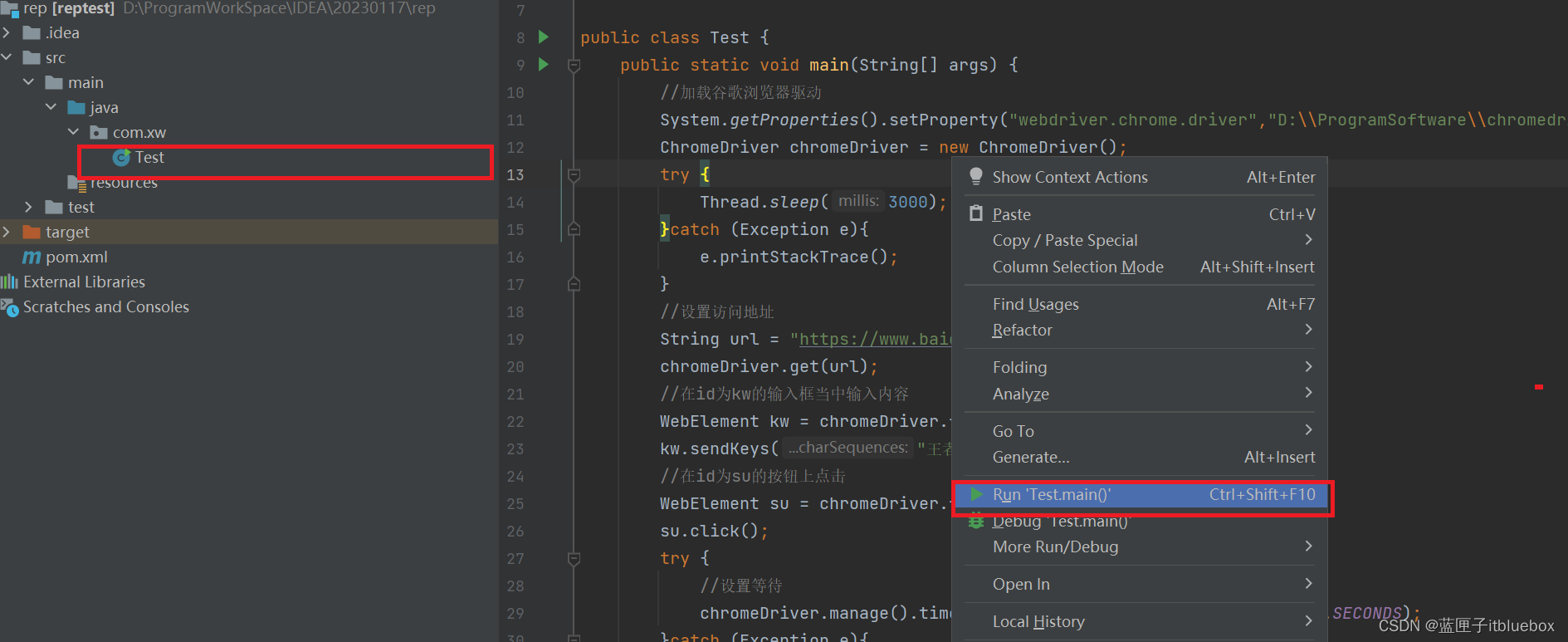
运行成功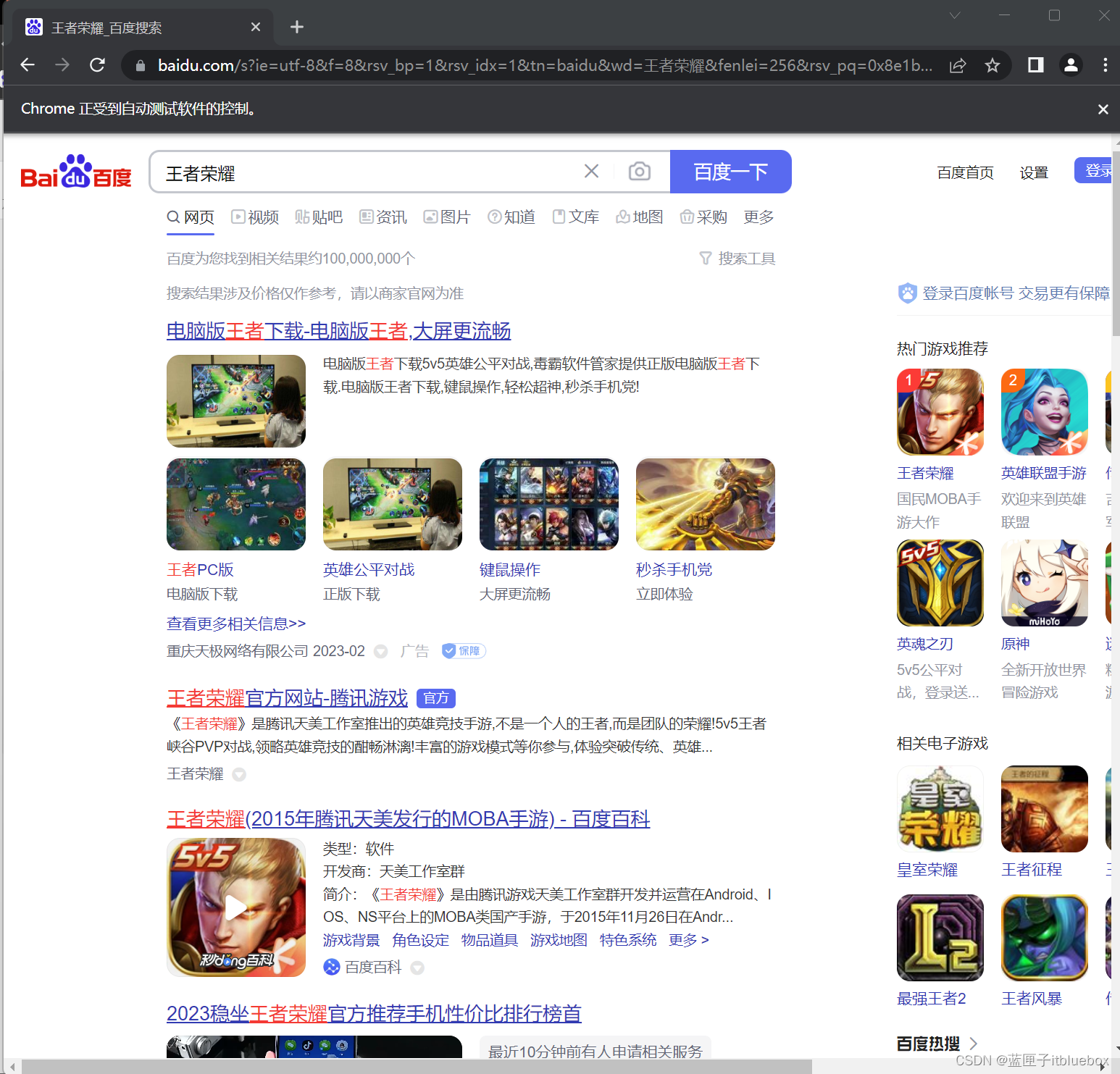
本文转载自: https://blog.csdn.net/qq_44757034/article/details/128902719
版权归原作者 蓝匣子itbluebox 所有, 如有侵权,请联系我们删除。
版权归原作者 蓝匣子itbluebox 所有, 如有侵权,请联系我们删除。