
【0基础学爬虫】爬虫基础之scrapy的使用

大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学爬虫】专栏,帮助小白快速入门爬虫,本期为自动化工具 Selenium 的使用。
scrapy简介
Scrapy 是一个用于爬取网站并提取结构化数据的强大且灵活的开源框架。它提供了简单易用的工具和组件,使开发者能够定义爬虫、调度请求、处理响应并存储提取的数据。Scrapy 具有高效的异步处理能力,支持分布式爬取,通过其中间件和扩展机制可以方便地定制和扩展功能,广泛应用于数据挖掘、信息聚合和自动化测试等领域。
scrapy 工作流程
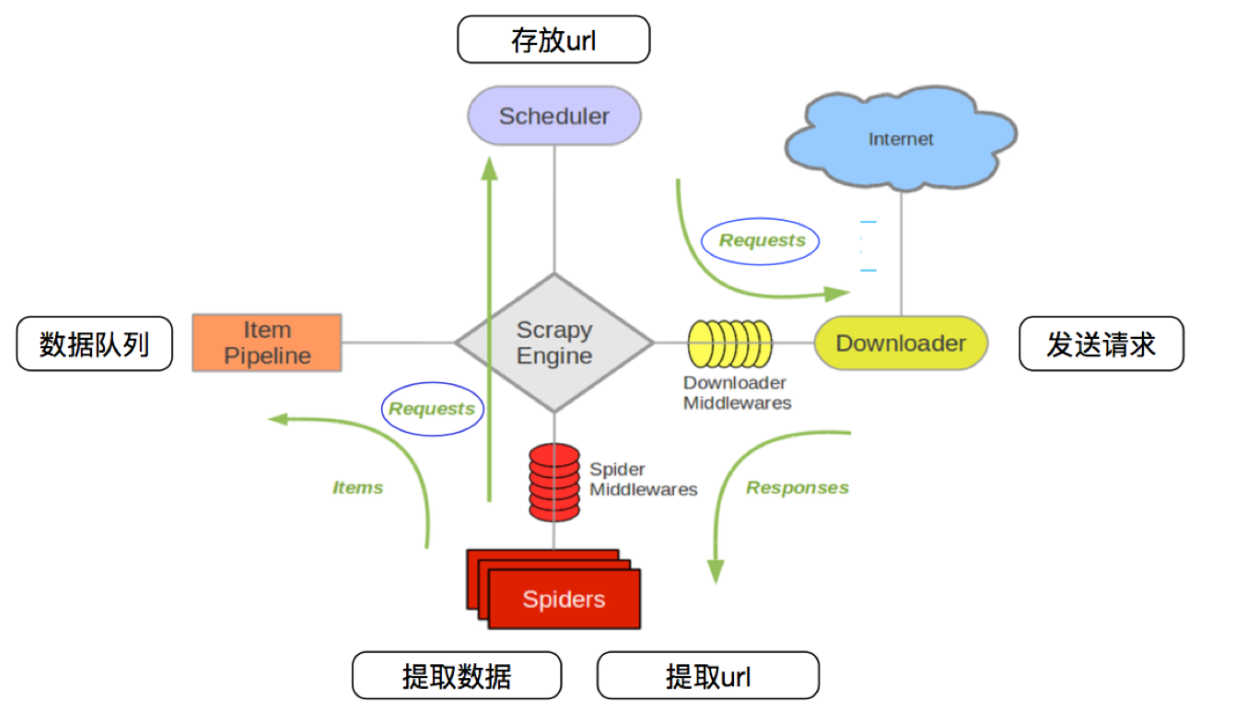
1、启动爬虫:Scrapy 启动并激活爬虫,从初始URL开始爬取。
2、调度请求:爬虫生成初始请求,并将其发送给调度器。
3、下载页面:调度器将请求发送给下载器,下载器从互联网获取页面。
4、处理响应:下载器将响应返回给引擎,传递给爬虫。
5、提取数据:爬虫从响应中提取数据(items)和更多的URL(新的请求)。
6、处理数据:提取的数据通过项目管道进行处理,清洗并存储。
7、继续爬取:新的请求被调度器处理,继续下载和提取数据,直到所有请求处理完毕。
scrapy 每个模块的具体作用

安装scrapy
pip install scrapy
安装成功后,直接在命令终端输入 scrapy ,输出内容如下:
新建scrapy项目
使用 scrapy startproject + 项目名 创建新项目。
这里我们使用
scrapy startproject scrapy_demo
创建项目示例:

然后通过下面命令创建我们的爬虫模板,这里就按照scrapy 给出的实例创建:
cd scrapy_demo
scrapy genspider example example.com
使用pycharm 打开我们的项目,项目格式如下:

各个文件夹的含义:
spiders:存放爬虫文件
items:定义爬取的数据结构
middlewares:定义下载中间件和爬虫中间件。中间件是处理请求和响应的钩子,可以修改请求、响应、异常等
pipelines:定义管道,用于处理爬虫提取的数据,例如数据清洗、验证和存储等操作。
settings:定义了项目的基本配置
使用scrapy
这里以我们熟悉的某瓣为例来说明
scrapy
的用法。
修改 example.py 文件:
import scrapy
classExampleSpider(scrapy.Spider):
name ="example"# allowed_domains = ["example.com"] # 允许爬取的网站范围,可以不要
start_urls =["https://movie.douban.com/top250"]defparse(self, response):print(response.text)
在终端输入
scrapy crawl example
运行结果如下:
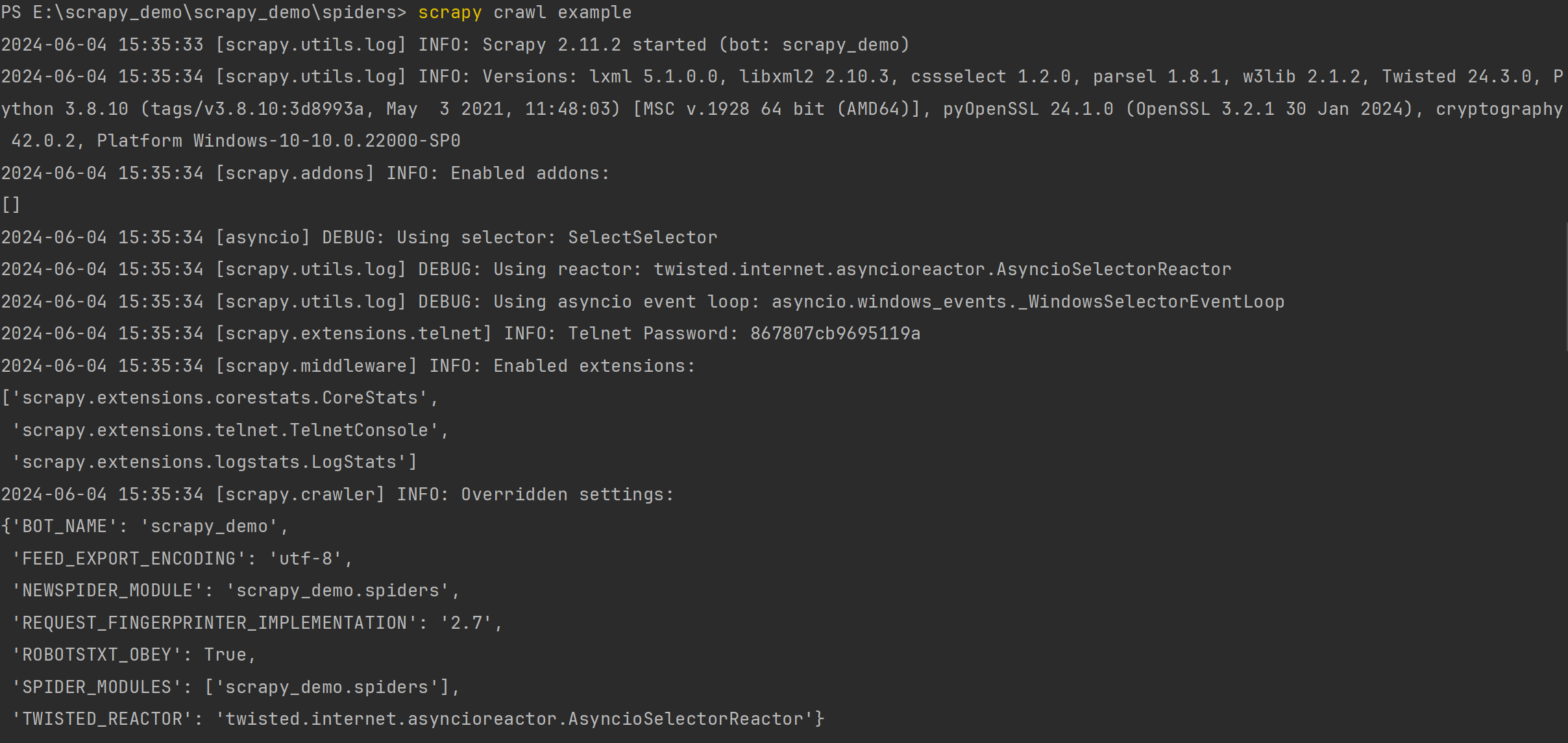
输出了很多信息,包含版本号、插件、启用的中间件等信息。
Versions:版本信息,包括scrapy和其它库的版本信息
Overridden settings: 重写的相关配置
Enabled downloader middlewares:开启的下载器中间件
Enabled spider middlewares:开启的爬虫中间件
Enabled item pipelines:开启的管道
Telnet Password:Telnet 平台密码(Scrapy附带一个内置的telnet控制台,用于检查和控制Scrapy运行过程)
Enabled extensions :开启的拓展功能
Dumping Scrapy stats:所以的信息汇总
我们重点看这里:
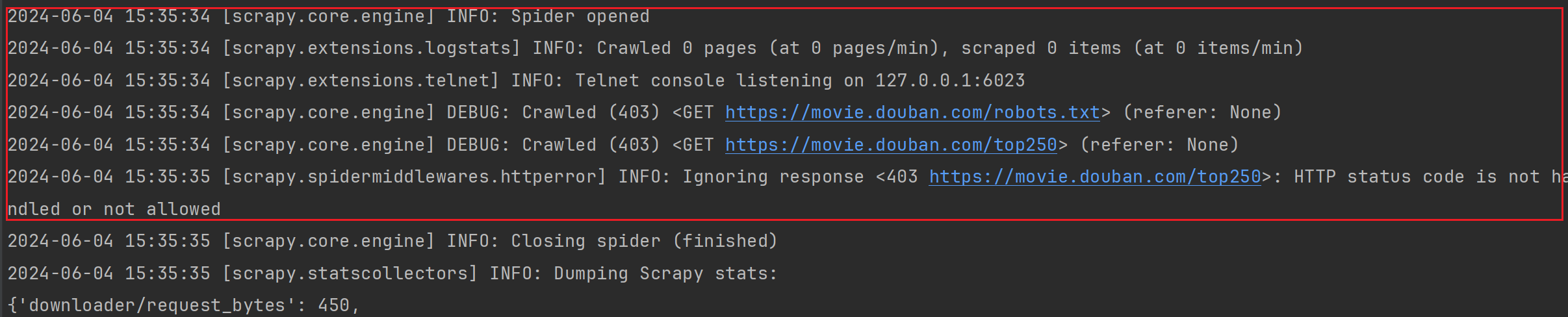
可以发现,我们返回了403状态码,原因是因为我们少了请求头和有robots协议。
在 setting.py 增加请求头、修改 robots 协议:
# Obey robots.txt rules
ROBOTSTXT_OBEY =False# 这里改成False,表示不遵守robots协议# Override the default request headers:
DEFAULT_REQUEST_HEADERS ={"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language":"en","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0"}# 然后把这个放开,这个表示该项目的默认请求头
运行之后,可以发现能正常返回 html 页面数据。
scrapy 运行项目的两种方式
上面我们是通过终端运行的,下面我们使用 python 运行。
修改 example.py 文件代码:
import scrapy
from scrapy import cmdline
classExampleSpider(scrapy.Spider):
name ="example"# allowed_domains = ["example.com"] # 允许爬取的网站范围,可以不要
start_urls =["https://movie.douban.com/top250"]defparse(self, response):print(response.text)if __name__ =='__main__':
cmdline.execute("scrapy crawl example".split())# cmdline.execute("scrapy crawl example --nolog".split()) 不输出提示信息
如果不想输出与爬虫无关的信息,可以在后面加上 --nolog 命令,这样就不会打印提示信息了。
数据翻页抓取
scrapy实现翻页请求
我们可以直接利用scrapy 内置的数据解析方法对数据进行抓取:
代码如下:
import scrapy
from scrapy import cmdline
classExampleSpider(scrapy.Spider):
name ="example"# allowed_domains = ["example.com"] # 允许爬取的网站范围,可以不要
start_urls =["https://movie.douban.com/top250"]defparse(self, response):print(response.text)
ol_list = response.xpath('//ol[@class="grid_view"]/li')for ol in ol_list:
item ={}# 利用scrapy封装好的xpath选择器定位元素,并通过extract()或extract_first()来获取结果
item['title']= ol.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
item['rating']= ol.xpath('.//div[@class="bd"]/div/span[2]/text()').extract_first()
item['quote']= ol.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first()print(item)if __name__ =='__main__':
cmdline.execute("scrapy crawl example --nolog".split())# cmdline.execute("scrapy crawl example".split())
上面只抓取到了第一页,那么我们怎么抓取后面的每一页呢?
这里介绍两种方式:
1、利用callback 参数,进入项目源码,找到Request请求对象:
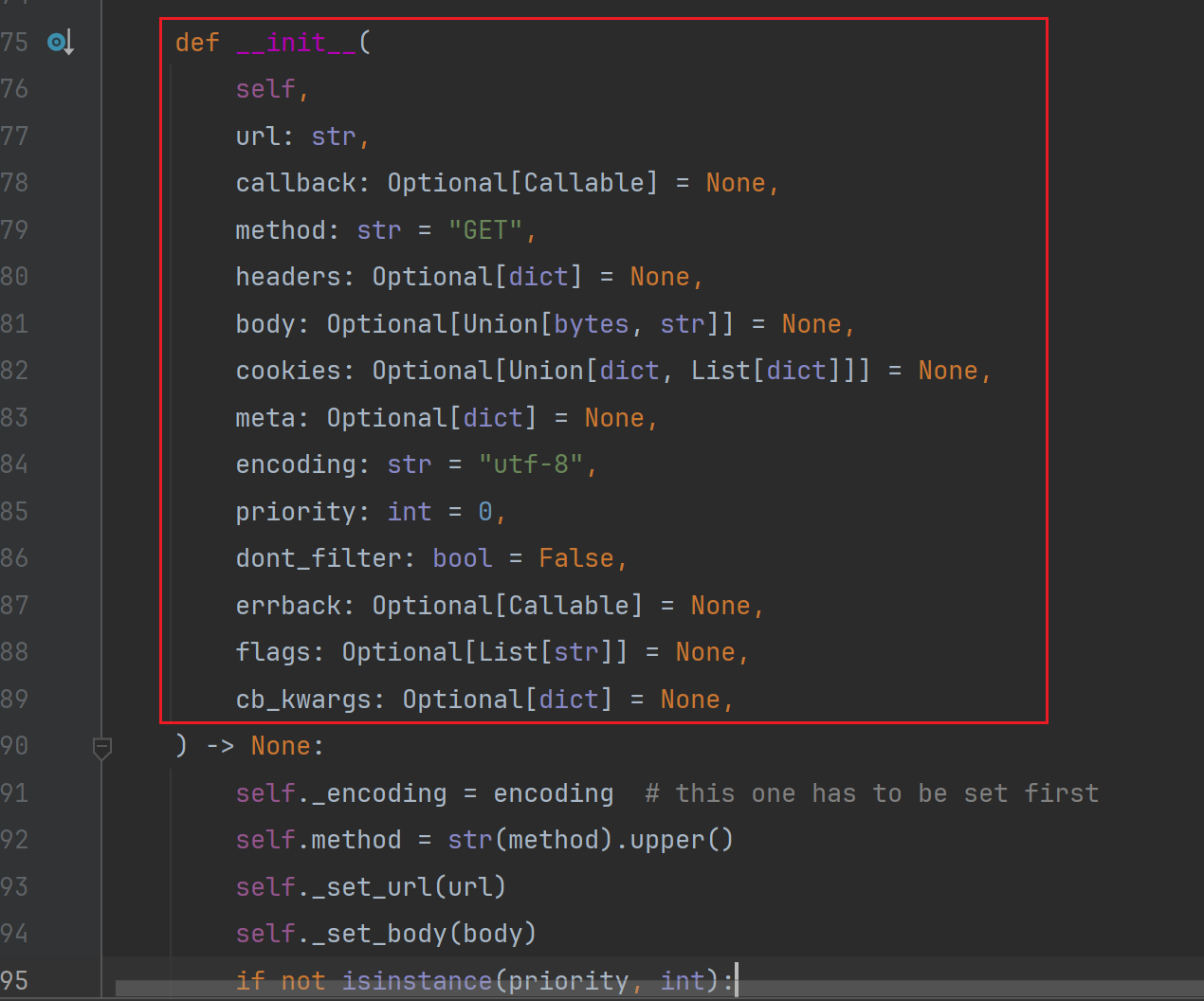
Request 对象含义如下:
参数描述url (str)请求的 URL。callback (callable)用于处理该请求的回调函数。默认是
parse
方法。method (str)HTTP 请求方法,如
'GET'
,
'POST'
等。默认为
'GET'
。headers (dict)请求头信息。body (bytes or str)请求体,通常在 POST 请求中使用。cookies (dict or list)请求携带的 Cookies,可以是一个字典或字典的列表。meta (dict)该请求的元数据字典,用于在不同请求之间传递数据。encoding (str)请求的编码格式。默认为
'utf-8'
。priority (int)请求的优先级,默认值为 0。优先级值越高,优先级越高。
callback 就是回调函数,接收一个函数名为参数。
实现如下:
defparse(self, response):print(response.text)
ol_list = response.xpath('//ol[@class="grid_view"]/li')for ol in ol_list:
item ={}# extract_first() 提取第一个元素
item['title']= ol.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
item['rating']= ol.xpath('.//div[@class="bd"]/div/span[2]/text()').extract_first()
item['quote']= ol.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first()print(item)if response.xpath("//a[text()='后页>']/@href").extract_first()isnotNone:
next_url = response.urljoin(response.xpath("//a[text()='后页>']/@href").extract_first())print(next_url)yield scrapy.Request(url=next_url, callback=self.parse)
2、重写 start_requests 方法:

代码如下:
defstart_requests(self):for i inrange(0,5):
url ='https://movie.douban.com/top250?start={}&filter='.format(i *25)yield scrapy.Request(url)defparse(self, response):
ol_list = response.xpath('//ol[@class="grid_view"]/li')for ol in ol_list:
item ={}# extract_first() 提取第一个元素
item['title']= ol.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
item['rating']= ol.xpath('.//div[@class="bd"]/div/span[2]/text()').extract_first()
item['quote']= ol.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first()print(item)
Responses 对象含义如下:
参数描述url (str)响应的 URL。status (int)HTTP 响应状态码。headers (dict)响应头信息。body (bytes)响应体内容,二进制格式。flags (list)响应的标志列表。request (Request)生成此响应的请求对象。meta (dict)该请求的元数据字典,用于在不同请求之间传递数据。encoding (str)响应的编码格式。通常由 Scrapy 自动检测,但可以手动设置。text (str)响应体内容,解码为字符串格式。css (callable)选择器,用于通过 CSS 表达式提取数据。xpath (callable)选择器,用于通过 XPath 表达式提取数据。json (callable)解析 JSON 响应体并返回字典或列表。
数据定义
数据爬取下来之后,我们通过scrapy 的 items 进行操作。item就是即提前规划好哪些字段需要抓取,比如上面的标题、评分这些字段就需要使用 item 提前定义好。
Scrapy Item 的作用
- 结构化数据:通过定义 Item,可以明确抓取数据的结构。例如,一个商品的信息可能包含名称、价格、库存等字段。
- 数据验证:可以在 Item 中定义字段的类型和验证规则,确保抓取的数据符合预期。
- 代码可读性:通过定义 Item,可以使代码更具可读性和可维护性,清晰地了解抓取的数据结构。
定义item
item.py 编写如下:
import scrapy
classScrapyDemoItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()
title = scrapy.Field()
rating = scrapy.Field()
quote = scrapy.Field()
使用item
使用 item 需要先实例化,使用方法和 python 字典方式一样
在example.py 导入我们需要使用的 item 类,这里我们就用默认的 ScrapyDemoItem 类
import scrapy
from scrapy import cmdline
from scrapy_demo.items import ScrapyDemoItem
classExampleSpider(scrapy.Spider):
name ="example"defstart_requests(self):for i inrange(0,5):
url ='https://movie.douban.com/top250?start={}&filter='.format(i *25)yield scrapy.Request(url)defparse(self, response):
ol_list = response.xpath('//ol[@class="grid_view"]/li')for ol in ol_list:
item = ScrapyDemoItem()# extract_first() 提取第一个元素
item['title']= ol.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
item['rating']= ol.xpath('.//div[@class="bd"]/div/span[2]/text()').extract_first()
item['quote']= ol.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first()print(item)if __name__ =='__main__':
cmdline.execute("scrapy crawl example --nolog".split())
数据存储
Scrapy Pipeline 的作用
- 数据清洗和验证:你可以在 pipeline 中编写代码来清洗和验证数据。例如,去除空白字符、处理缺失值、验证数据格式等。
- 去重:可以检查和去除重复的数据项,确保最终的数据集是唯一的。
- 存储:将处理过的数据存储到不同的存储后端,如数据库(MySQL、MongoDB)
- 进一步处理:执行复杂的转换、聚合等操作,以便在存储之前对数据进行进一步处理。
编写Pipeline
这里我们使用mysql 进行数据保存。
pipeline.py
import pymysql
from itemadapter import ItemAdapter
classMysqlPipeline:def__init__(self):
self.connection = pymysql.connect(
user='root',# 换上你自己的账密和数据库
password='root',
db='scrapy_demo',)
self.cursor = self.connection.cursor()
self.create_table()defcreate_table(self):
table ="""
CREATE TABLE IF NOT EXISTS douban (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
rating FLOAT NOT NULL,
quote TEXT
)CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
"""
self.cursor.execute(table)
self.connection.commit()defprocess_item(self, item, spider):try:
self.cursor.execute("INSERT INTO douban(id,title, rating, quote) VALUES (%s,%s, %s, %s)",(0, item['title'], item['rating'], item['quote']))
self.connection.commit()except pymysql.MySQLError as e:
spider.logger.error(f"Error saving item: {e}")print(e)return item
defclose_spider(self, spider):
self.cursor.close()
self.connection.close()
settings.py
ITEM_PIPELINES ={"scrapy_demo.pipelines.MysqlPipeline":300,}# 放开Item
配置好后,运行example 就能看到我们的数据被正确入库了。
数据不止能存储mysql,还存储到mongo、csv等等,感兴趣的小伙伴可以查看官方文档,有很详细的教程。
scrapy 中间件
scrapy中间件的分类和作用
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
Scrapy 中间件 (middlewares) 的作用是处理 Scrapy 请求和响应的钩子(hook),允许你在它们被scrapy引擎处理前或处理后对它们进行处理和修改。中间件为用户提供了一种方式,可以在请求和响应的不同阶段插入自定义逻辑。
一般我们常用的是下载中间件,所以下面我们用下载中间件来说明用法。
middlewares.py
Downloader Middlewares默认的方法:
- process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:继续请求
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象交给调度器进行后续的请求
- process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:交给process_response来处理
- 返回Request对象:交给调取器继续请求
- from_crawler(cls, crawler):- 类似于init初始化方法,只不过这里使用的classmethod类方法
- 可以直接crawler.settings获得参数,也可以搭配信号使用
自定义随机ua
我们借助 feapder 给我们封装好的 ua 来进行测试:
middlewares.py
from feapder.network import user_agent
classScrapyDemoDownloaderMiddleware:defprocess_request(self, request, spider):
request.headers['User-Agent']= user_agent.get()returnNone
settings.py
DOWNLOADER_MIDDLEWARES ={"scrapy_demo.middlewares.ScrapyDemoDownloaderMiddleware":543,}#放开下载中间件
example.py
import scrapy
from scrapy import cmdline
classExampleSpider(scrapy.Spider):
name ="example"
start_urls =["https://movie.douban.com/top250"]defparse(self, response):print(response.request.headers)if __name__ =='__main__':
cmdline.execute("scrapy crawl example --nolog".split())
可以发现每次输出的 ua 不一样。
自定义代理
通过Request 对象的 mata 参数来设置代理,这里以本地的 7890 端口为例:
middlewares.py
defprocess_request(self, request, spider):
request.headers['User-Agent']= user_agent.get()
request.meta['proxy']="http://127.0.0.1:7890"returnNone
中间件权重
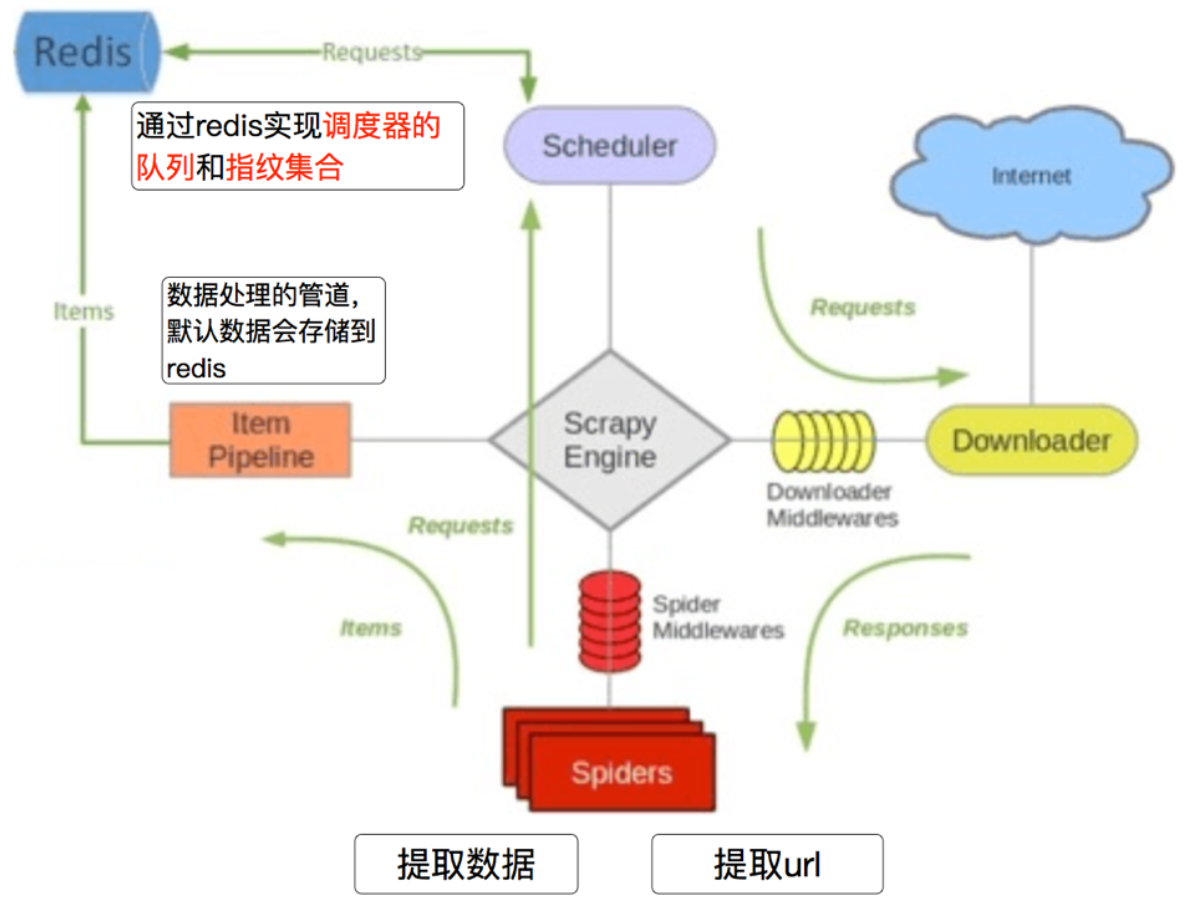
当涉及到多个中间件的时候,请求时数字越小权重越高,越先执行 ,响应时数字越大越先执行。这里我们可以借助scrapy 流程图来理解,谁离scrapy engine 引擎越近,表明权重越高。
这里我们创建两个类来测试一下:
middlewares.py
classOneMiddleware(object):defprocess_request(self, request, spider):print('one 请求')defprocess_response(self, request, response, spider):print('one 响应')# return NoneclassTwoMiddleware(object):defprocess_request(self, request, spider):print('two 请求')defprocess_response(self, request, response, spider):print('two 响应')return response
settings.py
DOWNLOADER_MIDDLEWARES ={"scrapy_demo.middlewares.OneMiddleware":543,"scrapy_demo.middlewares.TwoMiddleware":544}
运行 example.py 输出如下结果:

scrapy-redis 组件
Scrapy-Redis 是 Scrapy 的一个扩展,允许你使用 Redis 作为爬虫队列,并共享爬虫状态:
安装
pip install scrapy-redis
注意:这里scrapy 版本需要替换成 2.9.0版本或者2.0.0以下,不然会报错:
TypeError: crawl() got an unexpected keyword argument 'spider'
因为新版本已经不支持了。
然后新建 一个 redis_demo 爬虫
scrapy genspider redis_demo redis_demo.com
配置 scrapy-redis
settings.py
加入下面代码
# 设置 Redis 主机和端口
REDIS_URL ='redis://127.0.0.1:6379/0'# 使用 Scrapy-Redis 的调度器
SCHEDULER ="scrapy_redis.scheduler.Scheduler"# 使用 Scrapy-Redis 的去重器
DUPEFILTER_CLASS ="scrapy_redis.dupefilter.RFPDupeFilter"
开启redis管道
ITEM_PIPELINES ={"scrapy_redis.pipelines.RedisPipeline":301}
redis_demo.py
from scrapy_redis.spiders import RedisSpider
from scrapy import cmdline
# 继承scrapy——redis 类,实现分布式classRedisDemoSpider(RedisSpider):
name ="redis_demo"
redis_key ="redis_demo:start_urls"# redis keydefparse(self, response):
ol_list = response.xpath('//ol[@class="grid_view"]/li')for ol in ol_list:
item ={}# extract_first() 提取第一个元素
item['title']= ol.xpath('.//div[@class="hd"]/a/span[1]/text()').extract_first()
item['rating']= ol.xpath('.//div[@class="bd"]/div/span[2]/text()').extract_first()
item['quote']= ol.xpath('.//div[@class="bd"]//p[@class="quote"]/span/text()').extract_first()print(item)yield item
if __name__ =='__main__':
cmdline.execute("scrapy crawl redis_demo".split())
运行后会发现已经在监听端口了:
这时我们新建一个demo 文件:
import redis
r = redis.Redis(db=0)
r.lpush('redis_demo:start_urls',"https://movie.douban.com/top250")#r.lpush('redis_demo:start_urls',"https://movie.douban.com/top250?start=25&filter=")
然后运行这个demo.py文件,会发现数据已经成功入库了:
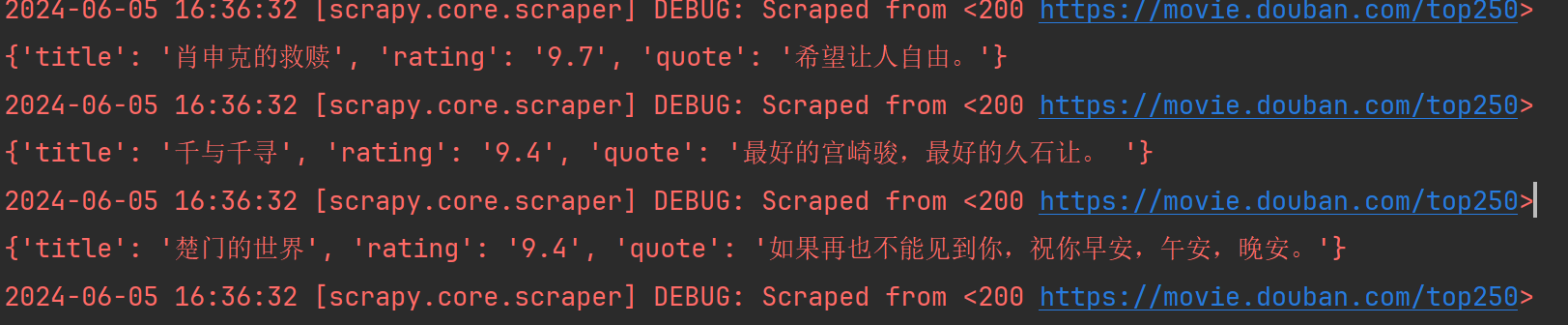
我们打开redis 可视化工具进行查看:

但是现在当我们每次跑一个地址的时候,原来的数据就没有了,要想解决这个问题,我们就得运用到scrapy-redis的持久化存储了。
redis 持久化存储
Scrapy-Redis 默认会在爬取全部完成后清空爬取队列和去重指纹集合。初始第一个网址一定会进行请求,后面的重复方式不会进行请求。
如果不想自动清空爬取队列和去重指纹集合,我们在 settings.py 增加如下配置:
SCHEDULER_PERSIST =True#如果需要持久化爬取状态,可以开启
再次运行 redis_demo.py ,然后运行两次demo.py文件可以测试一下:
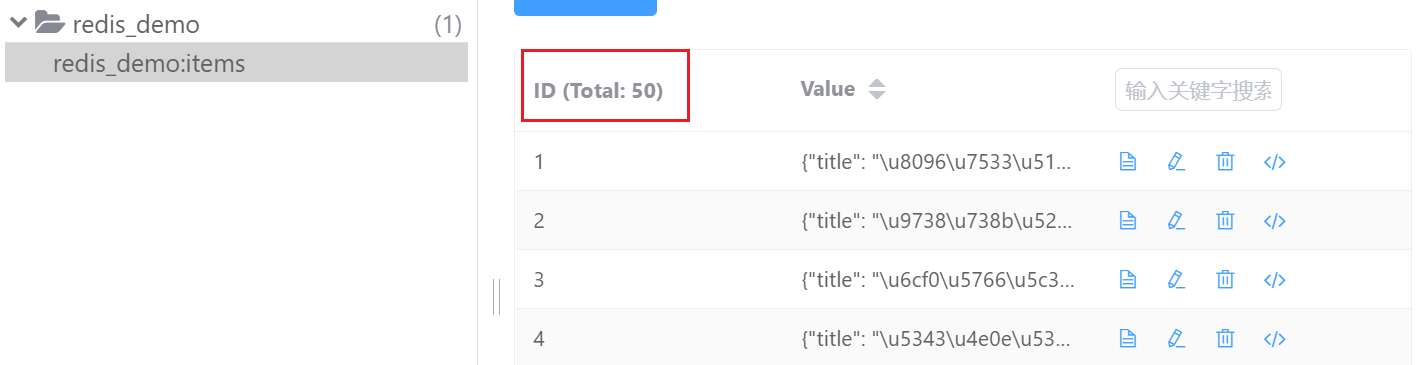
至此,完成了持久化存储。
redis 分布式
要想在多台电脑跑同一个程序,只需要把其它电脑的 redis 连接到一台就行。
settings.py
# 设置 Redis 主机和端口
REDIS_URL ='这里写你的远程电脑ip地址'# 使用 Scrapy-Redis 的调度器
SCHEDULER ="scrapy_redis.scheduler.Scheduler"# 使用 Scrapy-Redis 的去重器
DUPEFILTER_CLASS ="scrapy_redis.dupefilter.RFPDupeFilter"
开启redis管道
ITEM_PIPELINES ={"scrapy_redis.pipelines.RedisPipeline":301}
版权归原作者 K哥爬虫 所有, 如有侵权,请联系我们删除。