
1. 窗口的API概念
窗口的API使用分为按键分区和非按键分区,在定义窗口操作之前,首先就要确定好是基于按键分区
Keyed
的数据流
KeyedStream
来开窗还是基于没有按键分区的
DataStream
上开窗。
1.1 按键分区窗口(Keyed Windows)
按键分区窗口就是按照key分为多条逻辑流
logical streams
,这就是KeyedStream。基于KeyedStream进行窗口操作时,窗口计算会在多个并行子任务上同时执行。相同key的数据会被发送到同一个并行子任务,而窗口操作会基于每个key进行单独的计算。
代码实现:
stream.keyBy(...).window(...)
1.2 非按键分区(Non-Keyed Windows)
如果没有进行
keyBy
,那么原始的
DataStream
就不会分成多条逻辑流。这时窗口逻辑只能在一个任务(task)上执行,就相当于并行度变成了
1
。所以在实际应用中一般不推荐使用这种方式。
代码实现:
stream.windowAll(...)
这里需要注意的是,对于非按键分区的窗口操作,手动调大窗口算子的并行度也是无效的,
windowAll
本身就是一个非并行的操作。
1.3 代码中窗口 API 的调用
简单来说,窗口操作主要有两个部分:窗口分配器
(Window Assigners)
和窗口函数
(Window Functions)
。
代码实现:
stream.keyBy(<key selector>).window(<window assigner>).aggregate(<window function>)
其中.window()方法需要传入一个窗口分配器,它指明了窗口的类型;而后面的.aggregate()方法传入一个窗口函数作为参数,它用来定义窗口具体的处理逻辑。窗口分配器有各种形式,
而窗口函数的调用方法也不只.aggregate()一种
,我们接下来就详细展开讲解。另外,在实际应用中,一般都需要并行执行任务,非按键分区很少用到,所以我们之后都以按键分区窗口为例;如果想要实现非按键分区窗口,只要前面不做 keyBy,后面调用.window()时直接换成.windowAll()就可以了。
2. 窗口分配器(Window Assigners)
定义窗口分配器
(Window Assigners)
是构建窗口算子的第一步,它的作用就是定义数据应该被“分配”到哪个窗口。窗口分配数据的规则,其实就对应着不同的窗口类型。所以,窗口分配器其实就是在指定窗口的类型。
窗口分配器最通用的定义方式,就是调用
.window()
方法。这个方法需要传入一个
WindowAssigner
作为参数,返回的
WindowedStream
。如果是非按键分区窗口,那么直接调用
.windowAll()
方法,同样传入一个
WindowAssigner
,返回的是
AllWindowedStream
。
窗口按照驱动类型可以分成
时间窗口
和
计数窗口
,而按照具体的分配规则,又有
滚动窗口
、
滑动窗口
、
会话窗口
、
全局窗口
四种。除去需要自定义的全局窗口外,其他常用的类型 Flink中都给出了内置的分配器实现,我们可以方便地调用实现各种需求。
2.1 时间窗口
时间窗口
是最常用的窗口类型,又可以细分为
滚动
、
滑动
和
会话
三种。
在使用中直接调用
.window()
,在里面传入对应时间语义下的窗口分配器。这样一来,我们不需要专门定义时间语义,默认就是
事件时间
;如果想用
处理时间
,那么在这里传入
处理时间
的
窗口分配器
就可以了。
2.1.1 滚动处理时间窗口(TumblingProcessingTimeWindows)
窗口分配器由类
TumblingProcessingTimeWindows
提供,需要调用它的静态方法
.of()
。
代码实现:
stringDataStreamSource.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(...);
这里
.of()
方法需要传入一个
Time
类型的参数
size
,表示
滚动窗口的大小
,我们这里创建了一个长度为
5 秒
的滚动窗口。
另外
.of()
还有一个重载方法
public static TumblingProcessingTimeWindows of(Time size, Time offset)
,可以传入两个 Time 类型的参数:
size
和
offset
。第一个参数表示窗口大小,第二个参数表示窗口起始点的偏移量。这个偏移量主要是解决时区问题,比如我们定义 1 天滚动窗口时,如果用默认的起始点,那么得到就是伦敦时间每天 0点开启窗口,这时是北京时间早上 8 点。那怎样得到北京时间每天 0 点开启的滚动窗口呢?只要设置-8 小时的偏移量就可以了:
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
2.1.2 滑动处理时间窗口(SlidingProcessingTimeWindows)
窗口分配器由类
SlidingProcessingTimeWindows
提供,同样需要调用它的静态方法
.of()
。
代码实现:
stringDataStreamSource.keyBy(...).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5))).aggregate(...)
这里
.of()
方法需要传入两个
Time
类型的参数:
size
和
slide
,前者表示
滑动窗口的大小
,后者表示
滑动窗口的滑动步长
。我们这里创建了一个长度为 10 秒、滑动步长为 5 秒的滑动窗口。同样滑动窗口也可以追加第三个参数
offset -偏移量
,用于指定窗口起始点的偏移量,用法与滚动窗口完全一致。
2.1.3 处理时间会话窗口(ProcessingTimeSessionWindows)
窗口分配器由类
ProcessingTimeSessionWindows
提供,需要调用它的静态方法
.withGap()
或者
.withDynamicGap()
。
代码实现:
stream.keyBy(...).window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))).aggregate(...)
这里
.withGap()
方法需要传入一个
Time
类型的参数
size
,表示会话的
超时时间
,也就是
最小间隔 session gap
。我们这里创建了静态会话超时时间为 10 秒的会话窗口。
我们也可以使用
.withDynamicGap()
方法动态定义
session gap
时间,这就需要传入一个
SessionWindowTimeGapExtractor
作为参数,用来定义
session gap
的动态提取逻辑。在这里,我们提取了数据元素的第一个字段,用它的长度乘以 1000 作为会话超时的间隔。
.window(ProcessingTimeSessionWindows.withDynamicGap(newSessionWindowTimeGapExtractor<Tuple2<String,Long>>(){@Overridepubliclongextract(Tuple2<String,Long> element){// 提取 session gap 值返回, 单位毫秒return element.f0.length()*1000;}}))
2.1.4 滚动事件时间窗口(TumblingEventTimeWindows)
窗口分配器由类 TumblingEventTimeWindows 提供,用法与滚动处理事件窗口完全一致。
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.seconds(5))).aggregate(...)
这里
.of()
方法也可以传入第二个参数
offset
,用于设置窗口起始点的偏移量。
2.1.5 滑动事件时间窗口(SlidingEventTimeWindows)
窗口分配器由类
SlidingEventTimeWindows
提供,用法与滑动处理事件窗口完全一致。
stream.keyBy(...).window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5))).aggregate(...)
2.1.6 事件时间会话窗口(EventTimeSessionWindows)
窗口分配器由类
EventTimeSessionWindows
提供,用法与处理事件会话窗口完全一致。
stream.keyBy(...).window(EventTimeSessionWindows.withGap(Time.seconds(10))).aggregate(...)
2.2 计数窗口
计数窗口本身底层是基于全局窗口(Global Window)实现的。直接调用
.countWindow()
方法。根据分配规则的不同,又可以分为
滚动计数窗口
和
滑动计数窗口
两类。
2.2.1 滚动计数窗口
滚动计数窗口只需要传入一个长整型的参数 size,表示窗口的大小。
stream.keyBy(...).countWindow(10)
我们定义了一个长度为 10 的滚动计数窗口,当窗口中元素数量达到 10 的时候,就会触发计算执行并关闭窗口。
2.2.2 滑动计数窗口
与滚动计数窗口类似,不过需要在
.countWindow()
调用时传入两个参数:
size
和
slide
,前者表示窗口大小,后者表示滑动步长。
stream.keyBy(...).countWindow(10,3)
我们定义了一个长度为 10、滑动步长为 3 的滑动计数窗口。每个窗口统计 10 个数据,每隔 3 个数据就统计输出一次结果。
2.3 全局窗口
全局窗口是计数窗口的底层实现,一般在需要自定义窗口时使用。它的定义同样是直接用
.window()
,分配器由
GlobalWindows
类提供。
stream.keyBy(...).window(GlobalWindows.create());
**需要注意使用全局窗口,必须
自行定义触发器
才能实现窗口计算,否则起不到任何作用。**
3. 窗口函数(Window Functions)
定义窗口分配器只是知道了数据属于哪个窗口,可以将数据收集起来;但是如果想让收集的数据到底做什么就需要在接上一个定义窗口计算的窗口函数
(window functions)
。
经过窗口分配器处理之后,数据可以分配到对应窗口中,而数据流经过转换得到的数据类型是
WindowedStream
。不是
DataStream
,所以并不能直接进行其他转换,必须进一步调用窗口函数,对收集的数据进行处理计算之后,才能最终得到
DataStream
,如下图:
窗口函数定义了要对窗口中收集的数据做的计算处理,根据处理方式分为两类:
增量聚合函数
和
全窗口函数
。
3.1 增量聚合函数(incremental aggregation functions)
窗口将数据收集起来,最基本的处理操作就是聚合。窗口对无限流的切分,可以看作得到了一个有界数据集。如果如果等到所有数据都到了在窗口到了结束时间再去聚合就很不高效——这就相当于真的在用批处理的思路来做实时流处理。
为了提高实时性,流处理就像 DataStream 的简单聚合一样,每来一条数据就立即进行计算,中间只要保持一个简单的聚合状态就可以了;区别只是在于不立即输出结果,而是要等到窗口结束时间。等到窗口到了结束时间需要输出计算结果的时候,我们只需要拿出之前聚合的状态直接输出即可,这就提高了程序运行的效率和实时性。
典型的增量聚合函数有两个:
ReduceFunction
和
AggregateFunction
3.1.1 归约函数(ReduceFunction)
最简单的聚合就是归约
(reduce)
,就是将窗口中收集到的数据两两进行归约。当我们进行流处理时,就是要保存一个状态;每来一个新的数据,就和之前的聚合状态做归约,这样就实现了增量式的聚合。基于
WindowedStream
调用
.reduce()
方法,然
后传入
ReduceFunction
作为参数,就可以指定以归约两个元素的方式去对窗口中数据进行聚合了。这里的
ReduceFunction
与简单聚合时用到的
ReduceFunction
是同一个函数类接口,所以使用方式也是完全一样的。
代码实例:
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 创建自定义数据源的实时流DataStream<Event> stringDataStreamSource = env.addSource(newCustomSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.getTimestamp();}}));
stringDataStreamSource.map(newMapFunction<Event,Tuple2<String,Long>>(){@OverridepublicTuple2<String,Long>map(Event value)throwsException{// 将数据转换成二元组,方便计算returnTuple2.of(value.getUser(),1L);}}).keyBy(data -> data.f0)// 设置滚动事件时间窗口 5秒一个.window(TumblingEventTimeWindows.of(Time.seconds(5))).reduce(newReduceFunction<Tuple2<String,Long>>(){@OverridepublicTuple2<String,Long>reduce(Tuple2<String,Long> value1,Tuple2<String,Long> value2)throwsException{// 定义累加规则,窗口闭合时,向下游发送累加结果returnTuple2.of(value1.f0, value1.f1 + value2.f1);}}).print();
env.execute();}
CustomSource
代码:
publicclassCustomSourceimplementsParallelSourceFunction<Event>{// 声明一个布尔变量,作为控制数据生成的标识位privateBoolean running =true;@Overridepublicvoidrun(SourceContext<Event> ctx)throwsException{Random random =newRandom();// 在指定的数据集中随机选取数据String[] users ={"Mary","Alice","Bob","Cary"};String[] urls ={"./home","./cart","./fav","./prod?id=1","./prod?id=2"};while(running){Event event =newEvent(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],Calendar.getInstance().getTimeInMillis());
ctx.collect(event);System.out.printf("我开始生成数据了,[%s], [%d]%n", event.getUser(),event.getTimestamp());// 隔 1 秒生成一个点击事件,方便观测Thread.sleep(1000);}}@Overridepublicvoidcancel(){
running =false;}}
打印结果: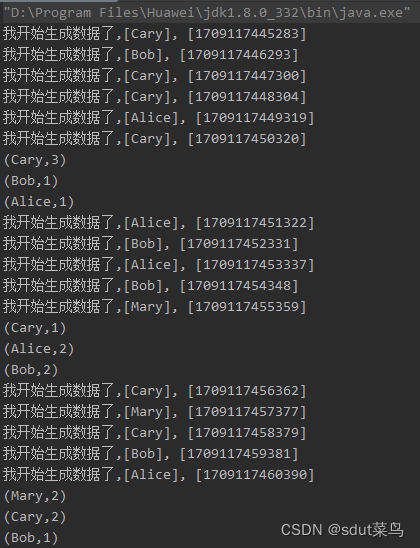
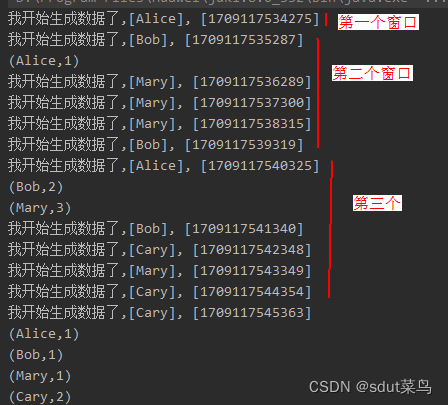
这个是凑巧了正好5个数据都在第一个窗口,如果5个数据不在第一个窗口就是这样的:
3.1.1 聚合函数(AggregateFunction)
ReduceFunction
可以解决大多数归约聚合的问题,但是这个接口有一个限制,就是聚合状态的类型、输出结果的类型都必须和输入数据类型一样。导致需要在聚合前,先将数据转换
(map)
成预期结果类型但是这样遇到某些场景就很麻烦。
例如,如果我们希望计算一组数据的平均值,应该怎样做聚合呢?很明显,这时我们需要计算两个状态量:数据的总和
(sum)
,以及数据的个数
(count)
,而最终输出结果是两者的商
(sum/count)
。如果用
ReduceFunction
,那么我们应该先把数据转换成二元组
(sum, count)
的形式式,然后进行归约聚合,最后再将元组的两个元素相除转换得到最后的平均值。本来应该只是一个任务,可我们却需要
map-reduce-map
三步操作,这显然不够高效。
Flink
的
Window API
中的
aggregate
就提供了这样的操作。直接基于
WindowedStream
调用
.aggregate()
方法,就可以定义更加灵活的窗口聚合操作。这个方法需要传入一个
AggregateFunction
的实现类作为参数。
AggregateFunction
在源码中的定义如下:
publicinterfaceAggregateFunction<IN, ACC, OUT>extendsFunction,Serializable{ACCcreateAccumulator();ACCadd(IN value,ACC accumulator);OUTgetResult(ACC accumulator);ACCmerge(ACC a,ACC b);}
AggregateFunction
可以看作是
ReduceFunction
的通用版本,这里有三种类型:
输入类型(IN)
、
累加器类型(ACC)
和
输出类型(OUT)
。
输入类型 IN
就是输入流中元素的数据类型;
累加器类型 ACC
则是我们进行聚合的中间状态类型;而
输出类型
当然就是最终计算结果的类型了。
接口中有四个方法:
createAccumulator():创建一个累加器,这就是为聚合创建了一个初始状态,每个聚合任务只会调用一次。add():将输入的元素添加到累加器中。这就是基于聚合状态,对新来的数据进行进一步聚合的过程。方法传入两个参数:当前新到的数据 value,和当前的累加器accumulator;返回一个新的累加器值,也就是对聚合状态进行更新。每条数据到来之后都会调用这个方法。getResult():从累加器中提取聚合的输出结果。也就是说,我们可以定义多个状态,然后再基于这些聚合的状态计算出一个结果进行输出。比如之前我们提到的计算平均值,就可以把sum和count作为状态放入累加器,而在调用这个方法时相除得到最终结果。这个方法只在窗口要输出结果时调用。merge():合并两个累加器,并将合并后的状态作为一个累加器返回。这个方法只在需要合并窗口的场景下才会被调用;最常见的合并窗口(Merging Window)的场景就是会话窗口(Session Windows)。
AggregateFunction
的工作原理是:首先调用
createAccumulator()
为任务初始化一个
状态(累加器)
;而后每来一个数据就调用一次
add()
方法,对数据进行聚合,得到的结果保存在状态中;等到了窗口需要输出时,再调用
getResult()
方法得到计算结果。很明显,与
ReduceFunction
相同,
AggregateFunction
也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
代码实例:
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 创建自定义数据源的实时流DataStream<Event> stringDataStreamSource = env.addSource(newCustomSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.getTimestamp();}}));
stringDataStreamSource.keyBy(data -> data.getUser())// 设置滚动事件时间窗口.window(TumblingEventTimeWindows.of(Time.seconds(5)))// 输入 Event 累加器是 Tuple3<String, Long, Integer> 用户名,时间戳,个数,输出Tuple3<String, Integer, String> 用户名,个数,平均值.aggregate(newAggregateFunction<Event,Tuple3<String,Long,Integer>,Tuple3<String,Integer,String>>(){// 初始化累加器@OverridepublicTuple3<String,Long,Integer>createAccumulator(){returnTuple3.of("",0L,0);}// 当数据来了处理一个数据@OverridepublicTuple3<String,Long,Integer>add(Event value,Tuple3<String,Long,Integer> accumulator){returnTuple3.of(value.getUser(), accumulator.f1 + value.getTimestamp(), accumulator.f2 +1);}// 返回结果@OverridepublicTuple3<String,Integer,String>getResult(Tuple3<String,Long,Integer> accumulator){Timestamp timestamp =newTimestamp(accumulator.f1 / accumulator.f2);returnTuple3.of(accumulator.f0, accumulator.f2, timestamp.toString());}// merge操作一般是会话窗口才会用到@OverridepublicTuple3<String,Long,Integer>merge(Tuple3<String,Long,Integer> a,Tuple3<String,Long,Integer> b){returnTuple3.of(a.f0, a.f1 + b.f1, a.f2 + b.f2);}}).print();
env.execute();}
输出结果: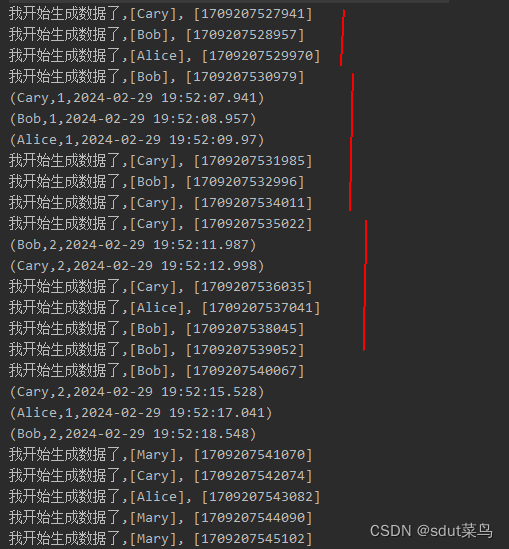
AggregateFunction
的工作原理是:
- 首先调用
createAccumulator()为任务初始化一个状态(累加器); - 而后每来一个数据就调用一次
add()方法,对数据进行聚合,得到的结果保存在状态中; - 等到了窗口需要输出时,再调用
getResult()方法得到计算结果。 - 很明显,与
ReduceFunction相同,AggregateFunction也是增量式的聚合;而由于输入、中间状态、输出的类型可以不同,使得应用更加灵活方便。
3.2 全窗口函数(full window functions)
窗口操作中的另一大类就是全窗口函数。与增量聚合函数不同,全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候再取出数据进行计算。
全窗口函数就是典型的批处理思路——等到所有数据都到齐了在处理数据。这种处理效率很慢,但为什么还会存在全窗口函数?是因为有些场景下,必须需要基于全部数据的计算结果才有效,这是聚合函数做不到的。
在 Flink 中,全窗口函数也有两种:
WindowFunction
和
ProcessWindowFunction
。
3.2.1 窗口函数(WindowFunction)
WindowFunction
字面上就是“窗口函数”,它其实是老版本的通用窗口函数接口。我们可以基于
WindowedStream
调用
.apply()
方法,传入一个
WindowFunction
的实现类。
stream
.keyBy(<key selector>).window(<window assigner>).apply(newMyWindowFunction());
这个类中可以获取到包含窗口所有数据的
可迭代集合(Iterable)
,还可以拿到
窗口(Window)
本身的信息。
WindowFunction
接口在源码中实现如下:
publicinterfaceWindowFunction<IN, OUT, KEY,WextendsWindow>extendsFunction,Serializable{voidapply(KEY key,W window,Iterable<IN> input,Collector<OUT> out)throwsException;}
WindowFunction
能提供的上下文信息较少,也没有更高级的功能。事实上,它的作用可以被
ProcessWindowFunction
全覆盖,所以之后可能会逐渐弃用。一般在实际应用,直接使用
ProcessWindowFunction
就可以了。
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 创建自定义数据源的实时流DataStream<Event> stringDataStreamSource = env.addSource(newCustomSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.getTimestamp();}}));
stringDataStreamSource.keyBy(data ->true)// 设置滚动事件时间窗口.window(TumblingEventTimeWindows.of(Time.seconds(5))).apply(newWindowFunction<Event,String,Boolean,TimeWindow>(){@Overridepublicvoidapply(Boolean aBoolean,TimeWindow window,Iterable<Event> input,Collector<String> out)throwsException{long start = window.getStart();long end = window.getEnd();HashSet<String> users =newHashSet<>();for(Event event : input){
users.add(event.getUser());}
out.collect("窗口:"+newTimestamp(start)+" ~ "+newTimestamp(end)+"的独立访客数量是:"+ users.size());}}).print();
stringDataStreamSource.print("data");
env.execute();}
输出结果: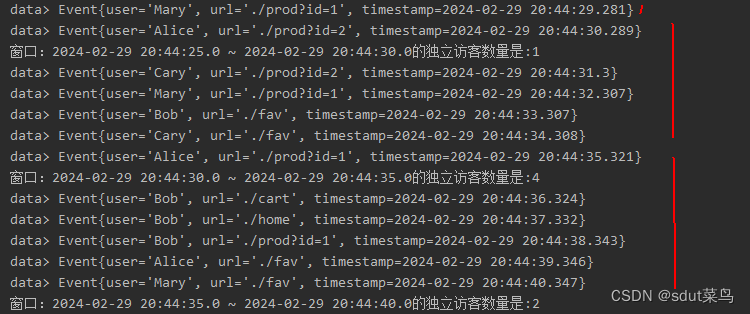
可以看到
TimeWindows
的属性很少
3.2.2 处理窗口函数(ProcessWindowFunction)
ProcessWindowFunction
是
Window API
中最底层的通用窗口函数接口。之所以说它“最底层”,是因为除了可以拿到窗口中的所有数据之外,
ProcessWindowFunction
还可以获取到一个“上下文对象”
(Context)
。这个上下文对象非常强大,不仅能够获取窗口信息,还可以访问当前的时间和状态信息。这里的时间就包括了
处理时间(processing time)
和
事件时间水位线(event time watermark)
。这就使得
ProcessWindowFunction
更加灵活、功能更加丰富。事实上,
ProcessWindowFunction
是 Flink 底层 API——处理函数
(process function)
中的一员。
作为全窗口函数ProcessWindowFunction 同样需要将所有数据缓存下来,等到窗口触发计算时才使用,其实就是增强版的
WindowFunction
比如求一个网站的每小时用户量:
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 创建自定义数据源的实时流DataStream<Event> stringDataStreamSource = env.addSource(newCustomSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.getTimestamp();}}));
stringDataStreamSource.keyBy(data ->true)// 设置滚动事件时间窗口.window(TumblingEventTimeWindows.of(Time.seconds(5))).process(newUvCountByWindow()).print();
stringDataStreamSource.print("data");
env.execute();}publicstaticclassUvCountByWindowextendsProcessWindowFunction<Event,String,Boolean,TimeWindow>{@Overridepublicvoidprocess(Boolean aBoolean,ProcessWindowFunction<Event,String,Boolean,TimeWindow>.Context context,Iterable<Event> elements,Collector<String> out)throwsException{HashSet<String> users =newHashSet<>();// 遍历所有数据获取去重的用户名单for(Event element : elements){
users.add(element.getUser());}// 获取窗口信息long start = context.window().getStart();long end = context.window().getEnd();
out.collect(" 窗 口 : "+newTimestamp(start)+" ~ "+newTimestamp(end)+" 的独立访客数量是:"+ users.size());}}
输出结果: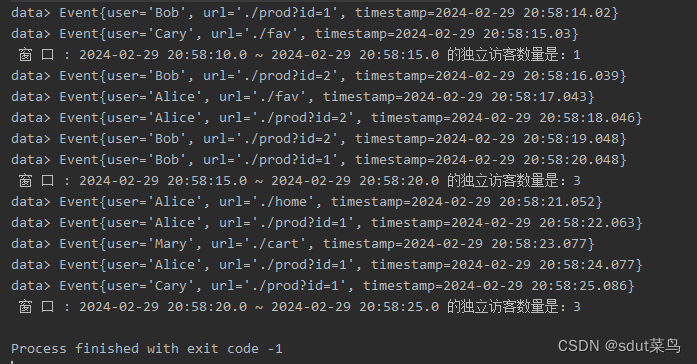
3.3 增量聚合和全窗口函数的结合使用、
增量聚合函数处理计算会更高效。举一个最简单的例子,对一组数据求和。大量的数据连续不断到来,全窗口函数只是把它们收集缓存起来,并没有处理;到了窗口要关闭、输出结果的时候,再遍历所有数据依次叠加,得到最终结果。而如果我们采用增量聚合的方式,那么只需要保存一个当前和的状态,每个数据到来时就会做一次加法,更新状态;到了要输出结果的时候,只要将当前状态直接拿出来就可以了。
增量聚合相当于把计算量“均摊”到了窗口收集数据的过程中,自然就会比全窗口聚合更加高效、输出更加实时。而全窗口函数的优势在于提供了更多的信息,可以认为是更加“通用”的窗口操作。它只负责收集数据、提供上下文相关信息,把所有的原材料都准备好,至于拿来做什么我们完全可以任意发挥。这就使得窗口计算更加灵活,功能更加强大。所以在实际应用中,我们往往希望兼具这两者的优点,把它们结合在一起使用。Flink 的Window API 就给我们实现了这样的用法。
调用
WindowedStream
的
.reduce()
和
.aggregate()
方法时,只是简单地直接传入了一个
ReduceFunction
或
AggregateFunction
进行增量聚合。除此之外,其实还可以传入第二个参数:一个全窗口函数,可以是
WindowFunction
或者
ProcessWindowFunction
。
// ReduceFunction 与 WindowFunction 结合public<R>SingleOutputStreamOperator<R>reduce(ReduceFunction<T> reduceFunction,WindowFunction<T,R,K,W> function)// ReduceFunction 与 ProcessWindowFunction 结合public<R>SingleOutputStreamOperator<R>reduce(ReduceFunction<T> reduceFunction,ProcessWindowFunction<T,R,K,W>
function)// AggregateFunction 与 WindowFunction 结合public<ACC,V,R>SingleOutputStreamOperator<R>aggregate(AggregateFunction<T, ACC,V> aggFunction,WindowFunction<V,R,K,W>
windowFunction)// AggregateFunction 与 ProcessWindowFunction 结合public<ACC,V,R>SingleOutputStreamOperator<R>aggregate(AggregateFunction<T, ACC,V> aggFunction,ProcessWindowFunction<V,R,K,W> windowFunction)
调用的处理机制是:
基于第一个参数(增量聚合函数)来处理窗口数据,每来一个数据就做一次聚合;等到窗口需要触发计算时,则调用第二个参数(全窗口函数)的处理逻辑输出结果。需要注意的是,这里的全窗口函数就不再缓存所有数据了,而是直接将增量聚合函数的结果拿来当作了 Iterable 类型的输入
。一般情况下,这时的可迭代集合中就只有一个元素了。
举一个具体的实例来说明。在网站的各种统计指标中,一个很重要的统计指标就是热门的链接;想要得到热门的 url,前提是得到每个链接的“热门度”。一般情况下,可以用url 的浏览量(点击量)表示热门度。我们这里统计 10 秒钟的 url 浏览量,每 5 秒钟更新一次;另外为了更加清晰地展示,还应该把窗口的起始结束时间一起输出。我们可以定义滑动窗口,并结合增量聚合函数和全窗口函数来得到统计结果。
publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);// 创建自定义数据源的实时流DataStream<Event> stringDataStreamSource = env.addSource(newCustomSource()).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO).withTimestampAssigner(newSerializableTimestampAssigner<Event>(){@OverridepubliclongextractTimestamp(Event element,long recordTimestamp){return element.getTimestamp();}}));
stringDataStreamSource.keyBy(data ->true)// 设置滚动事件时间窗口 10秒.window(TumblingEventTimeWindows.of(Time.seconds(10)))// 同时传入增量聚合函数和全窗口函数 增量聚合函数的输出就是全局窗口的输入.aggregate(newUvAgg(),newUvCountResult()).print();
stringDataStreamSource.print("data");
env.execute();}// 自定义实现AggregateFunction ,增量聚合计算uv值,来一条数据就加一个数据publicstaticclassUvAggimplementsAggregateFunction<Event,HashSet<String>,Integer>{@OverridepublicHashSet<String>createAccumulator(){returnnewHashSet<>();}@OverridepublicHashSet<String>add(Event value,HashSet<String> accumulator){
accumulator.add(value.getUser());return accumulator;}@OverridepublicIntegergetResult(HashSet<String> accumulator){return accumulator.size();}@OverridepublicHashSet<String>merge(HashSet<String> a,HashSet<String> b){returnnull;}}// 自定义全局窗口处理函数 处理增量聚合窗口的值publicstaticclassUvCountResultextendsProcessWindowFunction<Integer,String,Boolean,TimeWindow>{@Overridepublicvoidprocess(Boolean aBoolean,Context context,Iterable<Integer> elements,Collector<String> out)throwsException{long start = context.window().getStart();long end = context.window().getEnd();// 增量聚合窗口的返回值就只有一个long uv = elements.iterator().next();
out.collect(" 窗 口 : "+newTimestamp(start)+" ~ "+newTimestamp(end)+" 的独立访客数量是:"+ uv);}}
输出结果: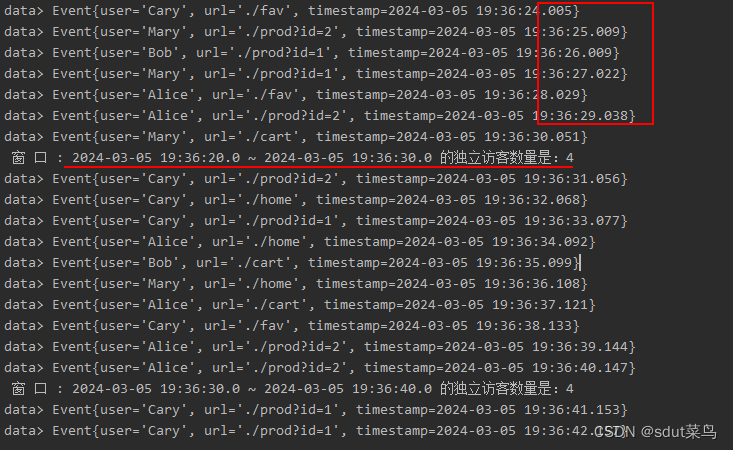
版权归原作者 sdut菜鸟 所有, 如有侵权,请联系我们删除。