
面试题真题
闭包和柯里化
闭包是什么?闭包是能够读取其他函数内部变量的函数
柯里化是什么?柯里化是把一个多个参数的函数转化为单参数函数的方法
闭包的用途:闭包的主要用途是为了不污染全局变量,用闭包的局部变量来做一些库提供给开发者使用,在平时的开发中,也可以用来缓存一些数据,例如你需要对比上一次的值和下一次进入该函数的值决定是否进行操作时,就可以使用闭包。
柯里化的用途:柯里化是闭包的高级应用,柯里化的主要用途是用来减少重复代码的编写,同时使代码更加清晰,例如在对moogodb进行操作时,我们可以利用柯里化来封装我们的crud。例如下面的代码
// db.js 只是负责连接数据库, 向外暴露一个连接信息const mysql =require('mysql')// 创建连接池const db = mysql.createPool({host:'localhost',port:3306,user:'root',password:'root',database:'root'})
exports.db = db
const{ db }=require('./db')constselect=function(sql){returnfunction(params =[]){returnnewPromise((resolve, reject)=>{
db.query(sql, params,(err, data)=>{if(err)returnreject(err)resolve(data)})})}}
const db =require('./db_crud')const selectUser = db.select('SELECT * FROM `student` LIMIT ?, 10')const deleteById = db.delete('DELETE FROM `users` WHERE `id`=?')
module.exports ={selectUser: selectUser,deleteById: deleteById
}
使用时,直接导入该模块
const abc=require(...)
acc.selectUser([参数]).then(res=>{console.log(res}) 即可
简述事件循环原理
事件循环分为javascript的事件循环(也是浏览器的事件循环,因为js本身不实现事件循环机制)和nodejs的事件循环,两者还是有一定区别的。一般来说问的都是js的事件循环,事件循环在开发中也是很常用的。
由来:由于JS是单线程,但是我们的业务通常不可能都是同步进行,一定需要异步的操作,所以就有了事件循环来解决该问题。
在js中将事件循环分为宏任务和微任务(区别于同步任务),都会被挂起异步执行,那么二者有什么区别呢?在js中的任务是要排队的,所以执行栈里面就会排满了任务,同步任务就会从上到下依次执行,而当遇到宏任务和微任务时就会挂起,那么什么时候开始执行呢?宏任务会单独开辟一个任务队列将宏任务塞进去,微任务并不会开辟新的任务队列,而是将微任务放到当前队列的末尾去执行。
补充一句:在js中的异步都是通过回调来进行的,那为什么还有promise async等等,这里就涉及到了回调的一些缺点,如果异步的太多就会形成大量的回调嵌套回调的情况,也就是回调地狱,就会让代码的可读性很差,心智负担也比较大,所以才有了promise等api。
在js中哪些是宏任务,哪些是微任务?
宏任务:定时器,事件绑定,ajax,回调函数
微任务:promise async await process.nextTick MutationObserver
为什么要有微任务? 因为宏任务开销较大
尝试下下面的例题:
console.log(1);
document.addEventListener("14",function(){
console.log(14);});newPromise(function(resolve){resolve();
console.log(2);setTimeout(function(){
console.log(3);},0);
Promise.resolve().then(function(){
console.log(4);setTimeout(function(){
console.log(5);},0);setTimeout(function(){(asyncfunction(){
console.log(6);returnfunction(){
console.log(7);};})().then(function(fn){
console.log(8);fn();});},0);});newPromise(function(resolve){
console.log(9);resolve();}).then(function(){newPromise(function(resolve, reject){
console.log(10);reject();}).then(function(){setTimeout(function(){
console.log(11);},0);
console.log(12);}).catch(function(){
console.log(13);var evt =newEvent("14");
document.dispatchEvent(evt);});});});setTimeout(function(){
console.log(15);
Promise.resolve().then(function(){
console.log(16);});},0);//答案是1 2 9 4 10 13 14 3 15 16 5 6 8 7
项目中,经常会使用settimeout来对一些需要异步的动作进行处理。
补充下nodejs中的事件循环:
NodeJs基于V8引擎,所以在表现形式上,大体上是一致的,当接收到请求时, 就将这个请求作为事件放入队列, 然后继续接收其它请求, 直到没有请求时(主线程空闲时), 开始循环事件队列, 这里要判断, 如果是非I/O任务 就直接处理, 如果是I/O任务 就从 线程池 中拿出一个线程来处理这个事件, 并指定回调函数, 然后继续循环队列其它事件。在每次运行的事件循环之间,Node.js 检查它是否在等待任何异步 I/O 或计时器,如果没有的话,则完全关闭。
Node.js 的 Event Loop 并不是浏览器那种一次执行一个宏任务,然后执行所有的微任务,而是执行完一定数量的 Timers 宏任务,再去执行所有微任务,然后再执行一定数量的 Pending 的宏任务,然后再去执行所有微任务,感兴趣的自行了解吧。
虚拟DOM
虚拟DOM是什么,虚拟DOM本质上就是一串JSON,简单来说就是制定一套规则来描述真实DOM。
浏览器渲染引擎流程:创建DOM树=》创建StyleRules =》创建Render树=》布局Layout=》绘制Painting
Web界面由DOM树(树的意思是数据结构)来构建,当其中一部分发生变化时,其实就是对应某个DOM节点发生了变化。
虚拟DOM就是为了解决浏览器性能问题而被设计出来的。如前,若一次操作中有10次更新DOM的动作,虚拟DOM不会立即操作DOM,而是将这10次更新的diff内容保存到本地一个JS对象中,最终将这个JS对象一次性attch到DOM树上,再进行后续操作,避免大量无谓的计算量。所以用JS对象模拟DOM节点的好处是,页面的更新可以先全部反映在JS对象(虚拟DOM)上,操作内存中的JS对象的速度显然要更快,等更新完成后,再将最终的JS对象映射成真实的DOM,交由浏览器去绘制。
毕竟虚拟DOM到真实DOM的绘制增加了一层,实际上单比较某个节点变化来说虚拟DOM的性能是比直接渲染要差的,所以也就是说虚拟DOM无法极致的性能优化。
Diff算法和Key值的作用
diff算法和Key值的作用
1: 同级元素进行diff
2: 单节点和多节点diff
3: diff算法优先级问题(递归和遍历的区别)
Vue的双向数据绑定
vue.js 则是采用数据劫持结合发布者-订阅者模式的方式,通过
Object.defineProperty()
来劫持各个属性的
setter
,
getter
,在数据变动时发布消息给订阅者,触发相应的监听回调。
Object.defineProperty的问题:这是MVVM的基础,基本思路就是遍历每一个属性,然后使用Object.defineProperty将这个属性设置为响应式的(即我能监听到他的改动)。遇到普通数据属性,直接处理,遇到对象,遍历属性之后递归进去处理属性,遇到数组,递归进去处理数组元素(console.log)。遍历完就到处理了,也就是Object.defineProperty部分了,对于一个对象,我们可以用这个来改写它属性的getter/setter,这样,当你改属性的值我就有办法监听到。但是对于数组就有问题了。
很多时候我们操作数组是采用push、pop、splice、unshift等方法来操作的,光是push你就没办法监听,更不要说pop后你设置的getter/setter就直接没了。
所以,Vue的方法是,改写数组的push、pop等8个方法,让他们在执行之后通知我数组更新了(这种方法带来的后果就是你不能直接修改数组的长度或者通过下标去修改数组。参见官网)。这样改进之后我就不需要对数组元素进行响应式处理,只是遇到数组的时候把数组的方法变异即可。于是在用户使用数组的push、pop等方法会改变数组本身的方法时,可以监听到数组变动。
- 深度监听需要一次性递归
- 无法监听新增属性/删除属性 (Vue.set Vue.delete)
- 无法原生监听数组,需要特殊处理
Vue3的变化:
diff算法静态标记
cacheHandlers 事件侦听器缓存
主要讲一下vue3的双向数据绑定:vue3使用了新的jsApi,Proxy来代替原本的方案。刚才已经说过了vue2的双向绑定的缺点了,Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。proxy无法兼容全部浏览器,无法polyfill
Keep-alive(VUE)
通过虚拟DOM将需要keep-alive的虚拟DOM缓存起来,下次DOM渲染时再扔回去。在 created钩子函数调用时将需要缓存的 VNode 节点保存在 this.cache 中/在 render(页面渲染) 时,如果 VNode 的 name 符合缓存条件(可以用 include 以及 exclude 控制),则会从 this.cache 中取出之前缓存的 VNode实例进行渲染。
手动刷新
手写题:写一个节流,要求最后一次必须执行。
constthrottle=(fn, wait, op ={})=>{let timer =null;let pre =0;return()=>{let now = Date.now();if(now - pre > wait){if(pre ==0&&!op.begin){
pre = now;return}if(timer){clearTimeout(timer);
timer =null;}fn();
pre = now;}elseif(!timer && op.end){
timer =settimeout(()=>{fn();
timer =null;}, wait);}}}
手写题: 实现一个批量请求函数, 能够限制并发量?
constsendRequests=(reqs, max,callback=()=>{})=>{let waitList =[];let currentNum =0;let NumReqDone =0;const results =newArray(reqs.length).fill(false);constinit=()=>{
reqs.forEach((element, index)=>{request(index, element);});}constrequest=async(index, reqUrl)=>{if(currentNum >= max){awaitnewPromise(resolve=> waitList.push(resolve))}reqHandler(index, reqUrl);}constreqHandler=async(index, reqUrl)=>{
currentNum++;try{const result =awaitfetch(reqUrl);
results[index]= result;}catch(err){
results[index]= err;}finally{
currentNum--;
NumReqDone++;if(waitList.length){
waitList[0]();
waitList.shift();}if(NumReqDone === max){callback(results);}}}init()}const allRequest =["https://dog-facts-api.herokuapp.com/api/v1/resources/dogs?index=1","https://dog-facts-api.herokuapp.com/api/v1/resources/dogs?index=2","https://dog-facts-api.herokuapp.com/api/v1/resources/dogs?index=3"];sendRequests(allRequest,2,(res)=> console.log(res))
手写题:数组转树结构
const arr =[{id:2,name:'部门B',parentId:0},{id:3,name:'部门C',parentId:1},{id:1,name:'部门A',parentId:2},{id:4,name:'部门D',parentId:1},{id:5,name:'部门E',parentId:2},{id:6,name:'部门F',parentId:3},{id:7,name:'部门G',parentId:2},{id:8,name:'部门H',parentId:4}];consttransTree=(list, pId)=>{constloop=(pId)=>{let res =[];let i =0;while(i < list.length){let item = list[i];
i++;if(item.pid !== pId)continue
item.children =loop(item.id);
res.push(item);}return res;}returnloop(pId);}consttransTree=(list, pId)=>{constloop=(pId)=>{return list.reduce((pre, cur)=>{if(cur.pid === pId){
cur.children =loop(cur.id);
pre.push(cur);};return pre;},[])}returnloop(pId);}
代码题:去除字符串中出现次数最少的字符,不改变原字符串的顺序
“ababac” —— “ababa”
“aaabbbcceeff” —— “aaabbb”
constchangeStr=(str)=>{let obj ={};const _str = str.split("");
_str.forEach(item=>{if(obj[item]){
obj[item]++;}else{
obj[item]=1;}})var _obj = Object.values(obj).sort();var min = _obj[0];for(let key in obj){if(obj[key]<= min){var reg =newRegExp(key,"g")
str = str.replace(reg,"")}}return str;}
console.log(changeStr("aaabbbcceeff"));
代码题:写出一个函数trans,将数字转换成汉语的输出,输入为不超过10000亿的数字。
//将数字(整数)转为汉字,从零到一亿亿,需要小数的可自行截取小数点后面的数字直接替换对应arr1的读法就行了constconvertToChinaNum=(num)=>{var arr1 =newArray('零','一','二','三','四','五','六','七','八','九');var arr2 =newArray('','十','百','千','万','十','百','千','亿','十','百','千','万','十','百','千','亿');//可继续追加更高位转换值if(!num ||isNaN(num)){return"零";}var english = num.toString().split("")var result ="";for(var i =0; i < english.length; i++){var des_i = english.length -1- i;//倒序排列设值
result = arr2[i]+ result;var arr1_index = english[des_i];
result = arr1[arr1_index]+ result;}//将【零千、零百】换成【零】 【十零】换成【十】
result = result.replace(/零(千|百|十)/g,'零').replace(/十零/g,'十');//合并中间多个零为一个零
result = result.replace(/零+/g,'零');//将【零亿】换成【亿】【零万】换成【万】
result = result.replace(/零亿/g,'亿').replace(/零万/g,'万');//将【亿万】换成【亿】
result = result.replace(/亿万/g,'亿');//移除末尾的零
result = result.replace(/零+$/,'')//将【零一十】换成【零十】//result = result.replace(/零一十/g, '零十');//貌似正规读法是零一十//将【一十】换成【十】
result = result.replace(/^一十/g,'十');return result;}
对前端工程化的理解
前端工程化是一种思想,任何事物的出现都是基于需求的,面对日益复杂的前端项目,工程化就是类似工厂流水线,优化前端的开发工作,例如,解决代码冗余,项目可维护性,提升版本迭代速度等等一系列的问题。前端工程化的概念也就是在这中情况下被提出了,为了更加便捷的完成项目的开发部署等工作,前端工程化可以分成四个方面来说,分别为
模块化
、
组件化
、
规范化
和
自动化
。目前常见的前端工程化有:脚手架,代码模块化,组件库,webpack等打包工具,docker,CICD,github等等
前端性能优化
结合项目来说:
- 常见的优化webpack升级,优化打包体积,打包速度,编译速度
- 内存泄漏优化,例如:表单input多次输入卡顿的一次性能优化案例
- 缓存和CDN缓存(重要!可能会引申到CDN和缓存的问题,自行了解)
- 平时写代码的一些习惯性优化,较少http的请求次数(也就是无效请求不需要),懒加载和瀑布流,节流防抖,使用字体图标代替图片,非要使用图片就压缩使用。
- react和vue本身的一些优化能力,官网推荐写法等,usecallback,usememo,比如最新的react中的Suspense
- 说点冷门的webworker处理大批量数据,以及时间分片 requestIdleCallback(自行了解)
Nodejs 异步IO模型
结合上面的事件循环,其实就是在问你Nodejs的事件循环机制。
看这个吧
还有这个
简单讲讲:利用循环和观察者不断循环 轮询状态执行callback函数。
libuv
libuv 采用了 异步 (asynchronous), 事件驱动 (event-driven)的编程风格, 其主要任务是为开人员提供了一套事件循环和基于I/O(或其他活动)通知的回调函数, libuv 提供了一套核心的工具集, 例如定时器, 非阻塞网络编程的支持, 异步访问文件系统, 子进程以及其他功能.
代码题:给几个数组, 可以通过数值找到对应的数组名称
// 比如这个函数输入一个1,那么要求函数返回AconstA=[1,2,3];constB=[4,5,6];constC=[7,8,9];consttest=(num)=>{const newArr =[A,B,C];let i =0;while(i < newArr.length){if(newArr[i].includes(num))return newArr[i];
i++;}return[];}
console.log(test(5));
了解过vue3吗
了解过。vue3是怎么变快的
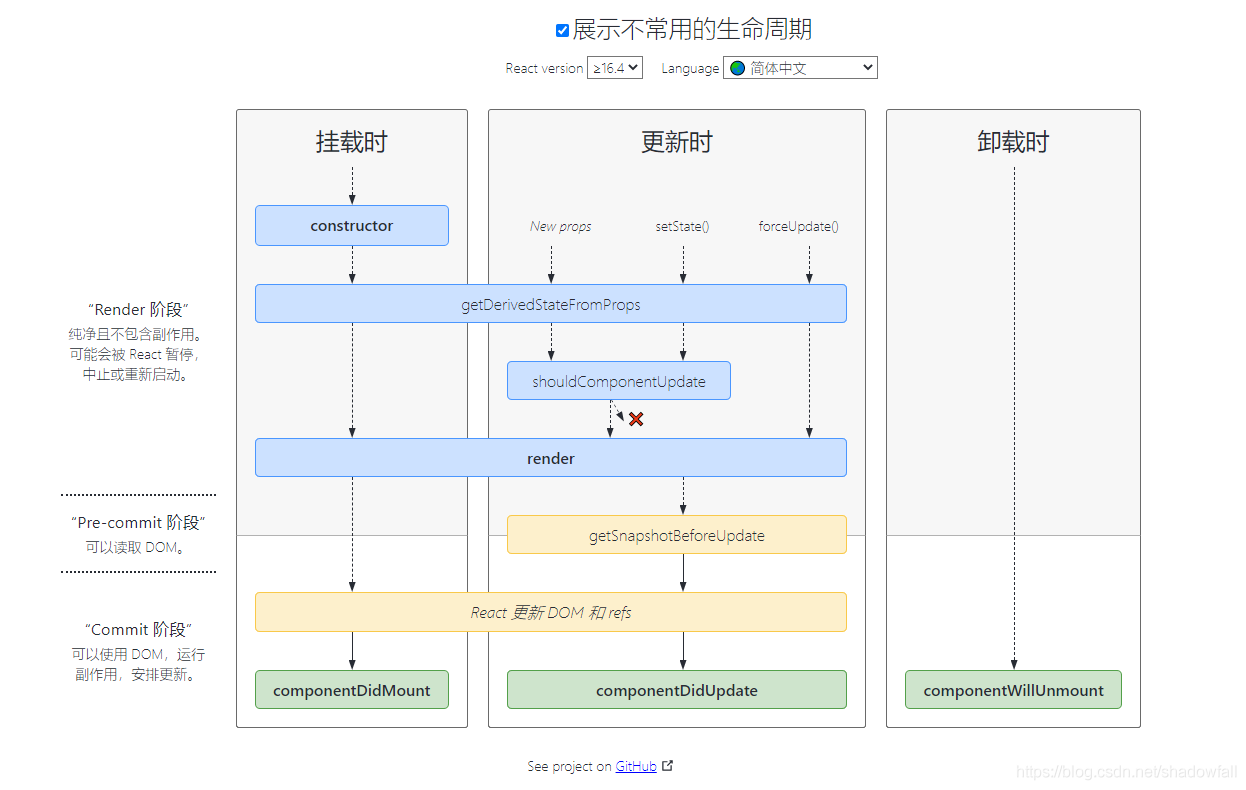
React生命周期
熟练背诵并使用
Redux原理
函数式编程思想,三大原则,Redux
场景设计: 设计一个转盘组件, 需要考虑什么, 需要和业务方协调好哪些技术细节? 前端如何防刷
- 自由发挥, 不太会 ==================================================================
虚拟列表怎么实现?
- 虚拟列表是什么?旨在解决数据量庞大时浏览器渲染性能瓶颈,其实可以理解为类似懒加载,只对可视区域内的内容进行加载。比如:
- 1、导出报表数据不分页,数据量庞大
- 2、移动端使用下拉加载分页列表,一直加载下一页时,数据量越来越大,无数的真实dom生成,对浏览器的渲染造成过大压力
- 3、前端业务中许多树形数据处理,一般全部给到前端,如果一次性渲染出来,便会造成浏览器卡顿,如果把树数据结构看做一维的list来处理,结合虚拟列表就能解决性能瓶颈
虚拟列表的实现,实际上就是在首屏加载的时候,只加载
可视区域
内需要的列表项,当滚动发生时,动态通过计算获得
可视区域
内的列表项,并将
非可视区域
内存在的列表项删除。
- 计算当前
可视区域起始数据索引(startIndex) - 计算当前
可视区域结束数据索引(endIndex) - 计算当前
可视区域的数据,并渲染到页面中 - 计算
startIndex对应的数据在整个列表中的偏移位置startOffset并设置到列表上
<!-- 容器 --><divclass="virtual-list-container"><!-- 为容器内的占位,高度为总列表高度,用于形成滚动条 --><divclass="virtual-list-place"></div><!-- 渲染区域 --><divclass="virtual-list">
...
<!-- item-1 --><!-- item-2 --><!-- item-3 -->
....
</div></div>
接着,监听virtual-list-container的scroll事件,获取滚动位置scrollTop
假定可视区域高度固定,称之为screenHeight
假定列表每项高度固定,称之为itemSize
假定列表数据称之为listData
假定当前滚动位置称之为scrollTop
则可推算出:
列表总高度listHeight = listData.length * itemSize
可显示的列表项数visibleCount = Math.ceil(screenHeight / itemSize)
数据的起始索引startIndex = Math.floor(scrollTop / itemSize)
数据的结束索引endIndex = startIndex + visibleCount
列表显示数据为visibleData = listData.slice(startIndex,endIndex)
当滚动后,由于渲染区域相对于可视区域已经发生了偏移,此时我需要获取一个偏移量startOffset,通过样式控制将渲染区域偏移至可视区域中。
偏移量startOffset = scrollTop - (scrollTop % itemSize);
列表项高度不固定(VUE 版代码实现)
- 以
预估高度先行渲染,然后获取真实高度并缓存。
<template><div ref="listContainerRef"class="virtual-list-container":style="{height}" @scroll="onScroll"><div ref="listPlaceRef"class="virtual-list-place"></div><div ref="listRef"class="virtual-list"><div
ref="itemsRef"class="virtual-list-item"
v-for="(item, itemIndex) in visibleList":key="item._key":id="item._key"><slot name="default":item="item":index="itemIndex"></slot></div></div><slot name="footer"></slot></div></template><script>exportdefault{props:{// 首尾缓存比例 = (首或者尾高度 + 滚动视窗高度) / 滚动视窗高度// 自动高度开启时需要调大缓存区比例(视窗内能容纳的越多该值应该越大)bufferScale:{type: Number,default:0.4,requred:false},// 数据dataSource:{type: Array,requred:true},// 滚动视窗高度height:{type: String,default:'100%',requred:false},// (非必填)列表每一项高度(不填时需开启itemAutoHeight)itemHeight:{type: Number,default:60,requred:false},// 是否自动计算每一项高度itemAutoHeight:{type: Boolean,default:false},// 到达底部回调onReachBottom: Function
},data(){return{screenHeight:0,startIndex:0,endIndex:0,positions:[]}},computed:{_listData(){returnthis.dataSource.map((item, index)=>({...item,_key:`${index}`}))},anchorPoint(){returnthis.positions.length ?this.positions[this.startIndex]:null},visibleCount(){return Math.ceil(this.screenHeight /this.itemHeight)},aboveCount(){return Math.min(this.startIndex, Math.ceil(this.bufferScale *this.visibleCount))},belowCount(){return Math.min(this._listData.length -this.endIndex, Math.ceil(this.bufferScale *this.visibleCount))},visibleList(){const startIndex =this.startIndex -this.aboveCount
const endIndex =this.endIndex +this.belowCount
returnthis._listData.slice(startIndex, endIndex)}},mounted(){this.init()},updated(){// 列表数据长度不等于缓存长度if(this._listData.length !==this.positions.length){this.initPositions()}this.$nextTick(function(){if(!this.$refs.itemsRef ||!this.$refs.itemsRef.length){return}// 获取真实元素大小,修改对应的尺寸缓存if(this.itemAutoHeight){this.updateItemsSize()}// 更新列表总高度const height =this.positions[this.positions.length -1].bottom
this.$refs.listPlaceRef.style.height = height +'px'// 更新真实偏移量this.setStartOffset()})},methods:{init(){this.initPositions()this.screenHeight =this.$refs.listContainerRef.clientHeight
this.startIndex =0this.endIndex =this.visibleCount
this.setStartOffset()},initPositions(){this.positions =this._listData.map((_, index)=>({
index,height:this.itemHeight,top: index *this.itemHeight,bottom:(index +1)*this.itemHeight
}))},updateItemsSize(){const nodes =this.$refs.itemsRef
nodes.forEach((node)=>{const rect = node.getBoundingClientRect()const height = rect.height
const index =+node.id.split('_')[0]const oldHeight =this.positions[index].height
const dValue = oldHeight - height
if(dValue){this.positions[index].bottom =this.positions[index].bottom - dValue
this.positions[index].height = height
this.positions[index].over =truefor(let k = index +1; k <this.positions.length; k++){this.positions[k].top =this.positions[k -1].bottom
this.positions[k].bottom =this.positions[k].bottom - dValue
}}})},setStartOffset(){let startOffset
if(this.startIndex >=1){const size =this.positions[this.startIndex].top -(this.positions[this.startIndex -this.aboveCount]?this.positions[this.startIndex -this.aboveCount].top :0)
startOffset =this.positions[this.startIndex -1].bottom - size
}else{
startOffset =0}this.startOffset = startOffset
this.$refs.listRef.style.transform =`translate3d(0,${startOffset}px,0)`},getStartIndex(scrollTop =0){returnthis.binarySearch(this.positions, scrollTop)},binarySearch(list, value){let start =0let end = list.length -1let tempIndex =nullwhile(start <= end){const midIndex =parseInt((start + end)/2)const midValue = list[midIndex].bottom
if(midValue === value){return midIndex +1}elseif(midValue < value){
start = midIndex +1}elseif(midValue > value){if(tempIndex ===null|| tempIndex > midIndex){
tempIndex = midIndex
}
end = end -1}}return tempIndex
},onScroll(){const scrollTop =this.$refs.listContainerRef.scrollTop
const scrollHeight =this.$refs.listContainerRef.scrollHeight
if(scrollTop >this.anchorPoint.bottom || scrollTop <this.anchorPoint.top){this.startIndex =this.getStartIndex(scrollTop)this.endIndex =this.startIndex +this.visibleCount
this.setStartOffset()}if(scrollTop +this.screenHeight > scrollHeight -50){this.onReachBottom &&this.onReachBottom()}}}}</script><style>.virtual-list-container {overflow: auto;position: relative;}.virtual-list-place {position: absolute;left:0;top:0;right:0;
z-index:-1;}.virtual-list {position: absolute;left:0;top:0;right:0;
z-index:1;}</style>
参考文章:https://blog.csdn.net/qq_42036203/article/details/125990867
react和vue在技术层面的区别
diff算法的区别,响应式的区别(definedProperty,proxy,setter,getter)
常用的hooks
useState useEffect useRef useMemo useCalllback useSelect useDispatch useRequest useReducer useVirtualList(虚拟列表)
import { useVirtualList } from 'ahooks';
const { list, containerProps, wrapperProps } = useVirtualList(Array.from(Array(99999).keys()), {
overscan: 30, // 视区上、下额外展示的 dom 节点数量
itemHeight: 60, // 行高度,静态高度可以直接写入像素值,动态高度可传入函数
});
<div {...containerProps}>
<div {...wrapperProps}>
{ list.map(item => <div key={item.index}>{item.data} </div>) }
</div>
</div>
hooks有哪些坑
useState 不要直接操作state进行push pop等操作
不要在循环中使用hooks
useReducer
useReducer 是用于提高应用性能的,当更新逻辑比较复杂时,我们应该考虑使用useReducer,思想类似redux,和redux的区别是不能全局进行状态管理,多组件共享数据
useReducer 接受两个参数reducer函数和初始化state,返回值为最新的state和dispatch函数(用来触发reducer函数,计算对应的state)。dispatch可以传递
const [state, dispatch] = useReducer(reducer, initialArg, init);
组件外侧let a 1 组件内侧点击事件更改a,渲染的a会发生改变吗?如果let a放在组件内部,有什么变化吗?和useState有什么区别?
组件外和组件内let a = 1;点击事件更改a,渲染的a都不会发生变化,useState可以重新渲染页面
node创建子进程的方法
exec execFile spawn fork
css 三列等宽布局如何实现? flex 1是代表什么意思?分别有哪些属性?
Flex布局 定位布局 浮动布局 都可以实现
flex 1 代表撑满剩下的flex布局的空间
分别有:Flex-growFlex-shrinkFlex-basis
Flex-grow
flex-grow属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大
如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)。如果一个项目的flex-grow属性为2,其他项目都为1,则前者占据的剩余空间将比其他项多一倍。
Flex-shrink
flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
如果所有项目的flex-shrink属性都为1,当空间不足时,都将等比例缩小。如果一个项目的flex-shrink属性为0,其他项目都为1,则空间不足时,前者不缩小。
Flex-basis
flex-basis属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。它的默认值为auto,即项目的本来大小。
它可以设为跟width或height属性一样的值(比如350px),则项目将占据固定空间。
.parent{display:flex;height:300px;justify-content:space-between;}.left{background-color:pink;width:30%;}.center{background-color:black;width:30%;}.right{background-color:red;width:30%;}
前端安全xss和csrf
xss (跨站脚本攻击)CSRF攻击(跨站请求伪造)
csp是什么?nginx 中同源策略 配置允许哪些第三方访问
https是如何安全通信的?
https加密算法
代码题:不定长二维数组的全排列
// 输入 [['A', 'B', ...], [1, 2], ['a', 'b'], ...]// 输出 ['A1a', 'A1b', ....]
let res = arr.reduce((prev, cur)=>{if(!Array.isArray(prev)||!Array.isArray(cur)){return}if(prev.length ===0){return cur
}if(cur.length ===0){return prev
}const emptyVal =[]
prev.forEach(val=>{
cur.forEach(item=>{
emptyVal.push(`${val}${item}`)})})return emptyVal
},[])
console.log(res);
代码题:两个字符串对比, 得出结论都做了什么操作, 比如插入或者删除
- 类似react的diff算法,不太会 ==================================================================
pre ='abcde123'
now ='1abc123'
a前面插入了1,c后面删除了de
线上监控 对于crashed这种怎么监控? 对于内存持续增长,比如用了15分钟之后才会出现问题怎么监控
使用load和BEFOREUNLOAD进行crashed监控
对用户行为和使用chrome工具进行分析
linux 的top命令
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。下面详细介绍它的使用方法。top是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
301 302 304的区别
301 永久重定向
302 临时重定向
304 客户端发送附带条件的请求时(if-matched,if-modified-since,if-none-match,if-range,if-unmodified-since任一个)服务器端允许请求访问资源,但因发生请求未满足条件的情况后,直接返回304Modified(服务器端资源未改变,可直接使用客户端未过期的缓存)。304状态码返回时,不包含任何响应的主体部分。304虽然被划分在3xx类别中,但是和重定向没有关系。
代码题: sleep函数
- 由于js是单线程可以直接用循环阻塞进程
functionsleep(delay){var start =(newDate()).getTime();while((newDate()).getTime()- start < delay){continue;}}functiontest(){
console.log('111');sleep(2000);
console.log('222');}
- 使用定时器执行callback
functionsleep(ms, callback){setTimeout(callback, ms)}sleep(2000,()=>{
console.log("sleep")})
- 使用promise 微任务
constsleep=time=>{returnnewPromise(resolve=>setTimeout(resolve, time))}sleep(1000).then(()=>{ console.log(1)})
- 使用generator
functionsleepGenerator(time){yieldnewPromise(function(resolve, reject){setTimeout(resolve, time);})}sleepGenerator(1000).next().value.then(()=>{console.log(1)})
- 使用asnyc/await
functionsleep(time){returnnewPromise(resolve=>setTimeout(resolve, time))}asyncfunctionoutput(){let out =awaitsleep(1000);
console.log(1);return out;}output();
代码题:节流防抖
// 节流constthrottle=(callback, time)=>{let flag =true;return(...args)=>{if(!flag)return;
flag =false;setTimeout(()=>{callback.apply(this, args);
flag =true;}, time);}}// 节流二constthrottle=(callback, time)=>{let prev = Date.now();return(...args)=>{let now = Date.now();if(now - prev >= time){callback.apply(this, args);
prev = Date.now();}}}// 节流三functionthrottle(func, wait){var timer =null;var startTime = Date.now();returnfunction(){var curTime = Date.now();var remaining = wait-(curTime-startTime);var context =this;var args = arguments;clearTimeout(timer);if(remaining<=0){func.apply(context, args);
startTime = Date.now();}else{
timer =setTimeout(fun, remaining);//保证最后一次一定会被执行}}}// 防抖functiondebounce(func, wait, immediate){var timeout, result;constdebounced=(...args)=>{if(timeout)clearTimeout(timeout);if(immediate){var callNow =!timeout;
timeout =setTimeout(function(){
result =func.apply(this, args)}, wait);if(callNow) result =func.apply(context, args);}else{
timeout =setTimeout(function(){
result =func.apply(context, args)}, wait);}return result;}
debounced.cancel=function(){cleatTimeout(timeout);
timeout =null;}return debounced;}
输出什么?为什么
var b =10;(functionb(){
b =20;
console.log(b);})();// [Function: b] NFE大致规则1.只能在函数体内访问,2.函数名是自由变量,可以理解为常量,不可变。
代码输出顺序
asyncfunctionasync1(){
console.log('1');awaitasync2();
console.log('2');}asyncfunctionasync2(){
console.log('3');}
console.log('4');setTimeout(function(){
console.log('5');},0);async1();newPromise(function(resolve){
console.log('6');resolve();}).then(function(){
console.log('7');});
console.log('8');// 41368275
BFC是什么?哪些属性可以构成一个BFC
BFC
全称:
Block Formatting Context
, 名为 “块级格式化上下文”。
W3C
官方解释为:
BFC
它决定了元素如何对其内容进行定位,以及与其它元素的关系和相互作用,当涉及到可视化布局时,
Block Formatting Context
提供了一个环境,
HTML
在这个环境中按照一定的规则进行布局。
简单来说就是,
BFC
是一个完全独立的空间(布局环境),让空间里的子元素不会影响到外面的布局。那么怎么使用
BFC
呢,
BFC
可以看做是一个
CSS
元素属性
// 可以构成BFC属性overflow: hidden
display: inline-block
position: absolute
position: fixed
display: table-cell
display: flex
webpack原理,plugin和loader等
为什么需要webpack,因为目前浏览器只识别html,css,js,但是在我们开发中基本都是使用vue react等框架以及sass ES6语法等等
那么webpack能做什么,核心功能就是构建包,将代码转换为浏览器可识别的代码,同时webpack可以帮助我们压缩打包的体积,并且在打包过程中做一些事情,同时还可以支持开发中的热更新
打包过程大体上分为4步
- 利用babel完成代码转换,并生成单个文件的依赖
- 从入口开始递归分析,并生成依赖图谱
- 将各个引用模块打包为一个立即执行函数
- 将最终的bundle文件写入bundle.js中
webpack构建流程(原理)
从启动构建到输出结果一系列过程:
(1)初始化参数:解析webpack配置参数,合并shell传入和webpack.config.js文件配置的参数,形成最后的配置结果。
(2)开始编译:上一步得到的参数初始化compiler对象,注册所有配置的插件,插件监听webpack构建生命周期的事件节点,做出相应的反应,执行对象的 run 方法开始执行编译。
(3)确定入口:从配置的entry入口,开始解析文件构建AST语法树,找出依赖,递归下去。
(4)编译模块:递归中根据文件类型和loader配置,调用所有配置的loader对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理。
(5)完成模块编译并输出:递归完事后,得到每个文件结果,包含每个模块以及他们之间的依赖关系,根据entry配置生成代码块chunk。
(6)输出完成:输出所有的chunk到文件系统。
注意:在构建生命周期中有一系列插件在做合适的时机做合适事情,比如UglifyPlugin会在loader转换递归完对结果使用UglifyJs压缩覆盖之前的结果。
常用loader
加载scc
style-loader、css-loader、less-loader和sass-loader
(文件打包解析css less sass)
加载图片和字体等文件
raw-loader、file-loader 、url-loader
加载数据xml和csv
csv-loader xml-loade
r (打包加载解析csv和xml文件数据)
校验测试:
mocha-loader、jshint-loader、eslint-loader
.编译:
babel-loader、coffee-loader、ts-loade
常用plugin
webpack插件,采用不同的plugin完成各类不同的性需求,热更新,css去重之类的问题
1.ProvidePlugin:自动加载模块,代替require和import
2.html-webpack-plugin可以根据模板自动生成html代码,并自动引用css和js文件
3.extract-text-webpack-plugin 将js文件中引用的样式单独抽离成css文件
4.DefinePlugin 编译时配置全局变量,这对开发模式和发布模式的构建允许不同的行为非常有用。
5.HotModuleReplacementPlugin 热更新
6.optimize-css-assets-webpack-plugin 不同组件中重复的css可以快速去重
7.webpack-bundle-analyzer 一个webpack的bundle文件分析工具,将bundle文件以可交互缩放的treemap的形式展示。
8.compression-webpack-plugin 生产环境可采用gzip压缩JS和CSS
9.happypack:通过多进程模型,来加速代码构建
10.clean-wenpack-plugin 清理每次打包下没有使用的文件
继承
javascript中继承的方法和理解
浏览器从输入url开始发生了什么
浏览器从输入url开始发生了什么
浏览器的工作原理
generator 是如何做到中断和恢复的
Generator 函数是协程在 ES6 的实现,最大特点就是可以交出函数的执行权(即暂停执行)。
总结下来就是:
- 一个线程存在多个协程
- Generator函数是协程在ES6的实现
- Yield挂起协程(交给其它协程),next唤起协程
代码输出题
console.log(typeoftypeoftypeofnull);// string
console.log(typeof console.log(1));// 1 undefined
第一个typeofnull 为字符串object 后面所有都是string
第二个console.log 本身是一个函数没有返回值 所以是undefined
this指向问题
var name ='123';var obj ={name:'456',print:function(){functiona(){
console.log(this.name);}a();}}
obj.print();// undefined
**
【代码题】
** 删除链表的一个节点
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*//**
* @param {ListNode} head
* @param {number} val
* @return {ListNode}
*/vardeleteNode=function(head, val){// 定义虚拟节点const res =newListNode(-1);// 虚拟节点连接到head
res.next = head;// 定义p指针,最开始指向虚拟节点let p = res;// 从虚拟节点开始遍历链表while(p?.next){// 如果下一个值等于val,则删除下一个值if(p.next.val === val)
p.next = p.next.next;
p = p.next;}return res.next;};
实现LRU算法(keep-alive的缓存淘汰算法)
缓存淘汰算法:内存容量是有限的,当你要缓存的数据超出容量,就得有部分数据删除,这时候哪些数据删除,哪些数据保留,就是LRU算法和LFU算法,FU强调的是访问次数,而LRU强调的是访问时间。
选择内存中最近最久未使用的页面予以淘汰,如果我们想要实现缓存机制 – 满足最近最少使用淘汰原则,我们就可以使用LRU算法缓存机制。如:vue 中 keep-alive 中就用到了此算法。
⭐LRU:即Least Recently Used(最近最少使用算法)。把长期不使用的数据被认定为无用数据,在缓存容量满了后,会优先删除这些被认定的数据。
varLRUCache=function(capacity){this.cache =newMap();this.capacity = capacity;};LRUCache.prototype.get=function(key){if(this.cache.has(key)){let temp =this.cache.get(key);this.cache.delete(key);this.cache.set(key, temp);return temp;}return-1;}LRUCache.prototype.put=function(key, value){if(this.cache.has(key)){this.cache.delete(key);}elseif(this.cache.size >=this.capacity){this.cache.delete(this.cache.keys().next().value);};this.cache.set(key, value);}
参考文章
【面经】5年前端-历时一个月收获7个offer
版权归原作者 MaxLoongLvs 所有, 如有侵权,请联系我们删除。