
Milvus向量数据库是什么?
官网是这样说的:
Milvus创建于2019年,目标单一:存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大量嵌入向量。
作为一个专门用于处理输入向量查询的数据库,它能够对万亿规模的向量进行索引。与现有的关系数据库不同,Milvus主要按照预定义的模式处理结构化数据,它是自下而上设计的,用于处理从非结构化数据转换而来的嵌入向量。
随着互联网的发展和演变,非结构化数据变得越来越普遍,包括电子邮件、论文、物联网传感器数据、Facebook照片、蛋白质结构等等。为了让计算机理解和处理非结构化数据,使用嵌入技术将这些数据转换为向量。Milvus存储并索引这些向量。Milvus能够通过计算两个向量的相似距离来分析它们之间的相关性。如果两个嵌入向量非常相似,则意味着原始数据源也相似。
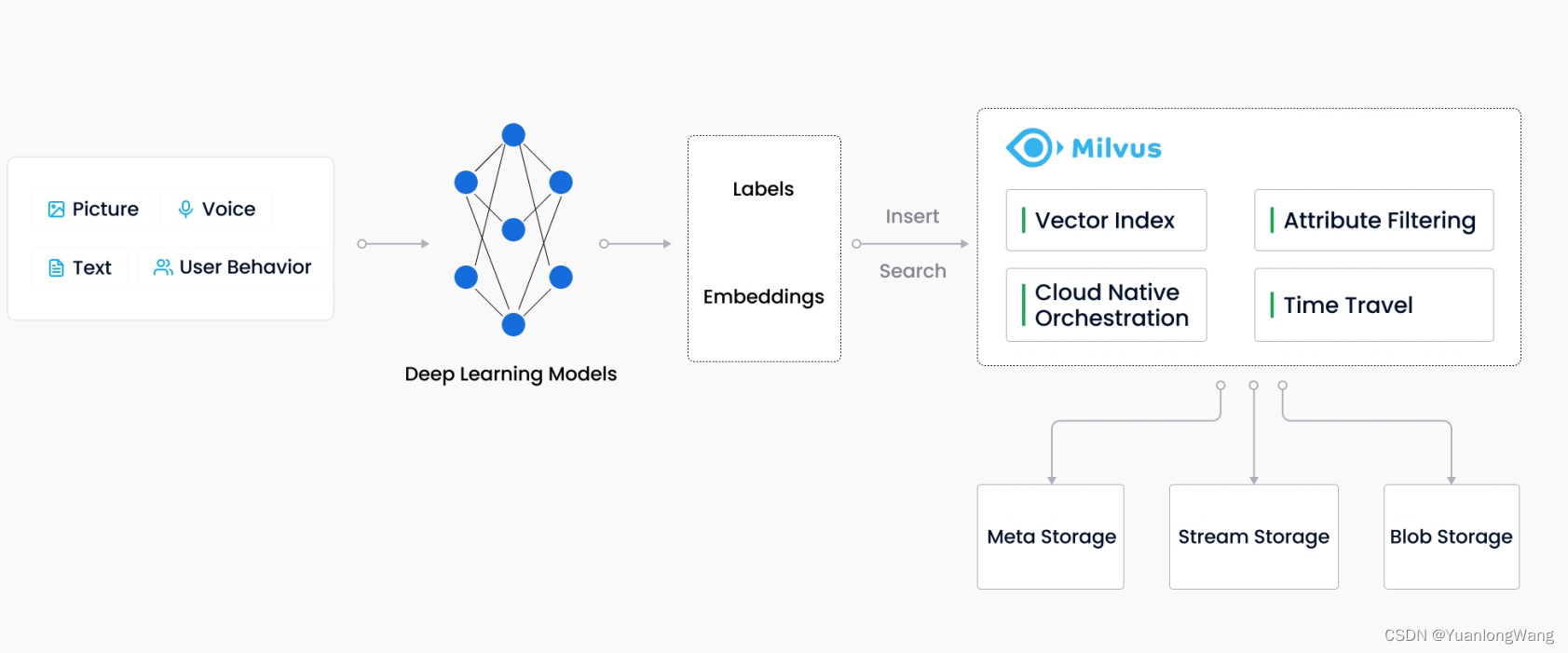
Milvus产品亮点:
- 针对万亿级向量的毫秒级搜索
- 简化的非结构化数据管理
- 稳定可靠的用户体验
- 高度可扩展,弹性伸缩
- 混合查询
- 基于 Lambda 架构的流批一体式数据存储
- 广受社区支持和业界认可
快速开始
使用docker安装Milvus单机版:
一般在linux下安装,先安装docker,接着安装 docker-compose,具体安装方法就不说了,自己百度一下。
1、下载
YAML文件
下载milvus-standalone-docker-compose.yml并手动或使用以下命令将其保存为docker-compose.yml。
wget https://github.com/milvus-io/milvus/releases/download/v2.0.2/milvus-standalone-docker-compose.yml -O docker-compose.yml
2、启动Milvus
在与docker-compose.yml文件相同的目录中,通过运行以下命令启动Milvus:
sudo docker-compose up -d
注意:
如果您的系统安装了Docker Compose V2而不是V1,请使用“Docker Compose”而不是“Docker-Compose”。“$docker compose version”检查版本号
检查容器是否已启动并正在运行:
sudo docker-compose ps
Milvus单机版启动后,将有三个docker容器在运行,其中包括Milvus独立服务及其两个依赖项。

3、停止Milvus
要停止Milvus单机版,运行:
sudo docker-compose down
要在停止Milvus后删除数据,运行:
sudo rm -rf volumes
安装Milvus可视化工具Attu
Attu是Milvus的一个高效的开源管理工具
以下代码安装Attu镜像并运行:
docker run -p 8000:3000 -e MILVUS_URL={你的IP地址}:19530 zilliz/attu:latest
启动docker后,在浏览器中访问http://你的IP地址:8000,然后单击“连接”以进入Attu服务。同时还支持TLS连接、用户名和密码。
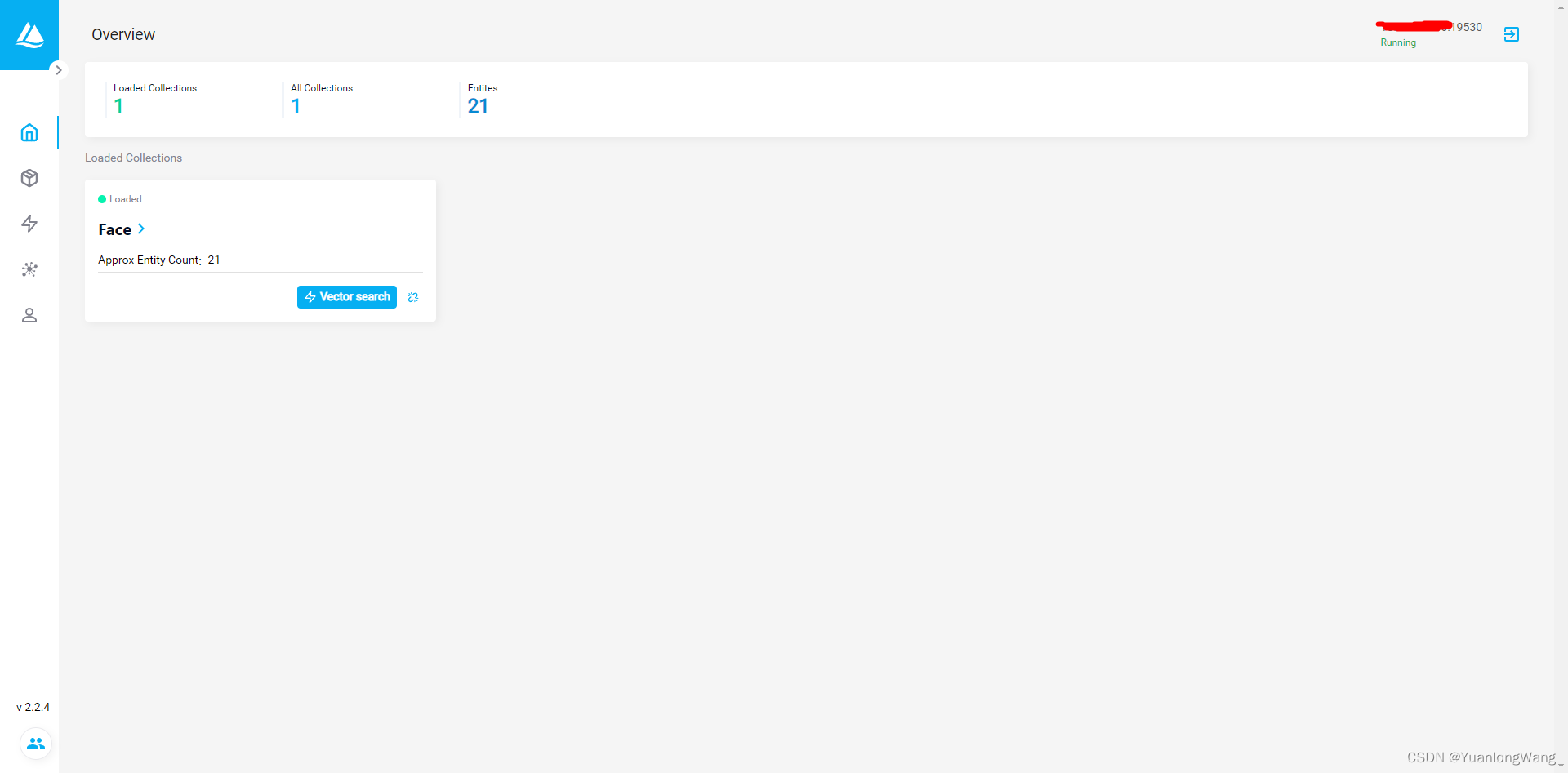
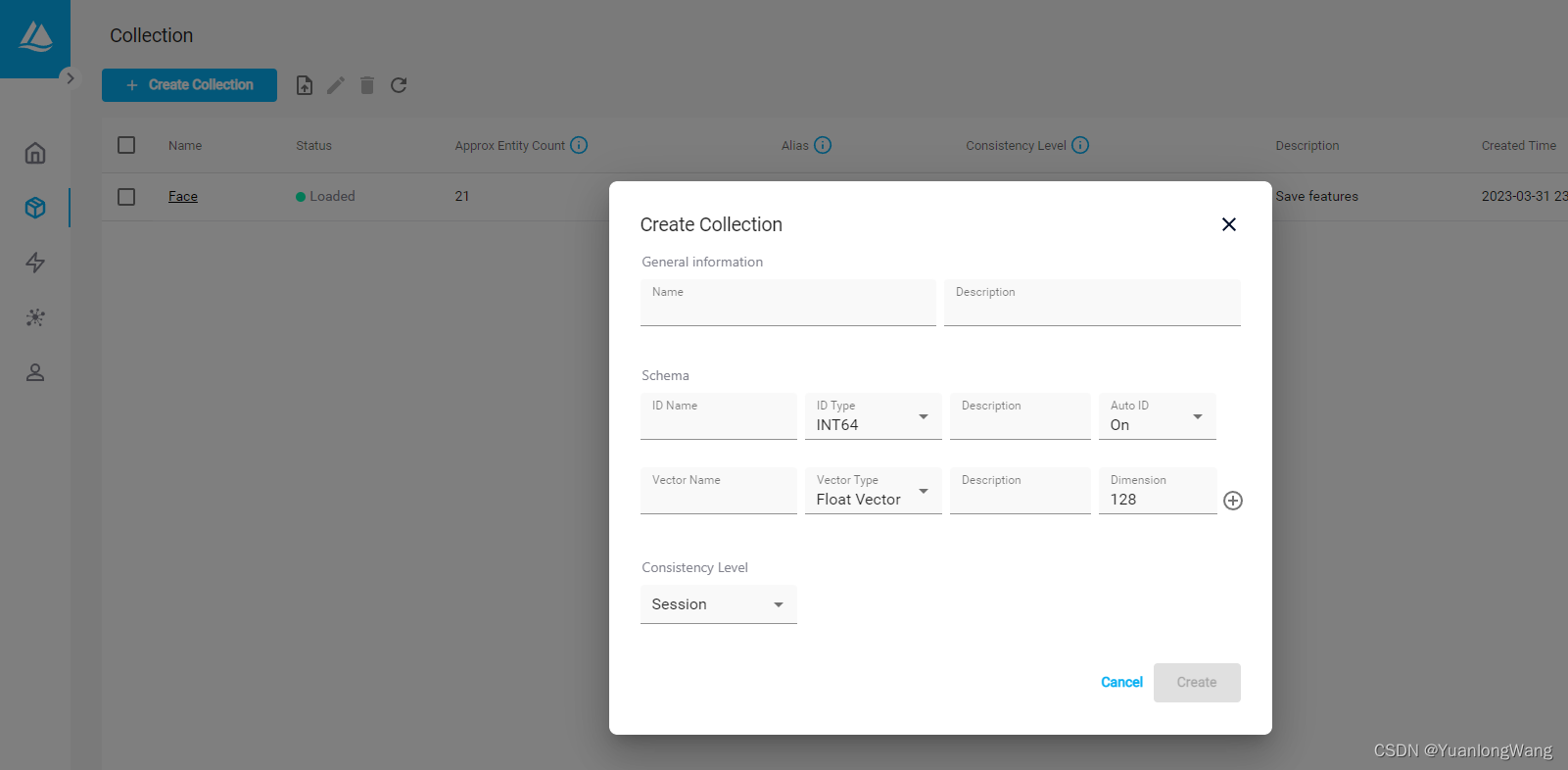
我这里已经建立了一个Collection(相当于一个数据库表)Face
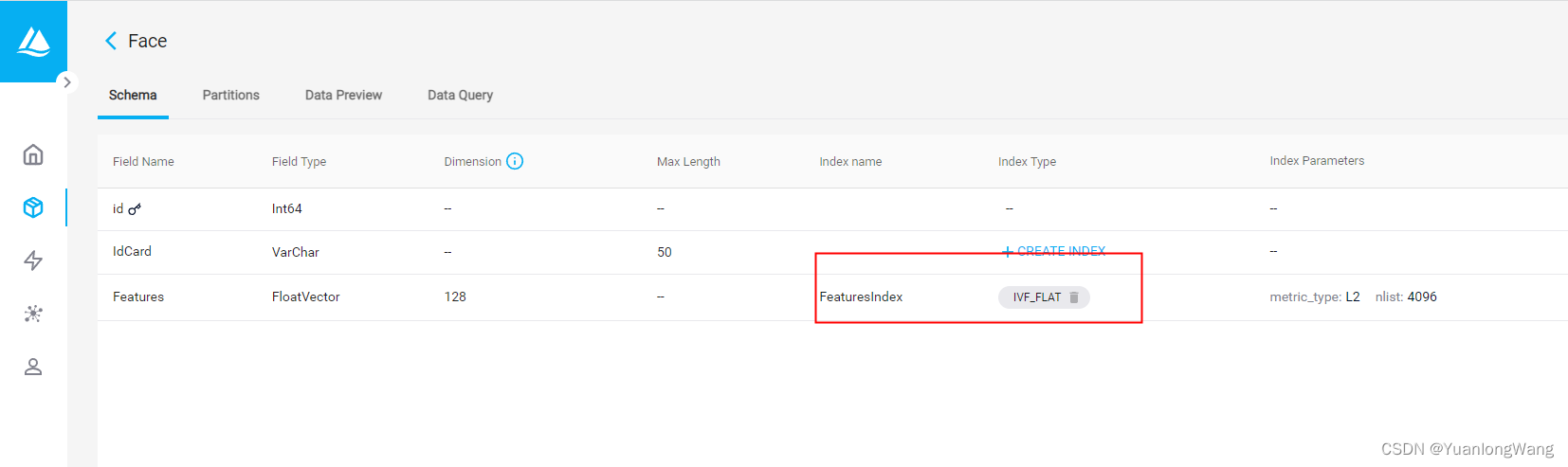
你可以通过点击Create Collection来创建一个Collection,至少包含一个id和一个Vector字段,可对向量字段添加索引
版权归原作者 YuanlongWang 所有, 如有侵权,请联系我们删除。