
使用递归神经网络(RNN)序列建模业务已有很长时间了。但是RNN很慢因为他们一次处理一个令牌无法并行化处理。此外,循环体系结构增加了完整序列的固定长度编码向量的限制。为了克服这些问题,诸如CNN-LSTM,Transformer,QRNNs之类的架构蓬勃发展。
在本文中,我们将讨论论文“拟递归神经网络”(https://arxiv.org/abs/1611.01576)中提出的QRNN模型。从本质上讲,这是一种将卷积添加到递归和将递归添加到卷积的方法。
LSTM

LSTM是RNN最著名的变体。红色块是线性函数或矩阵乘法,蓝色块是无参数元素级块。LSTM单元应用门控功能(输入,遗忘,输出)以获得输出和称为隐藏状态的存储元素。此隐藏状态包含整个序列的上下文信息。由于单个向量编码完整序列,因此LSTM无法记住长期依赖性。而且,每个时间步长的计算取决于前一个时间步长的隐藏状态,即LSTM一次计算一个时间步长。因此,计算不能并行进行。
CNN
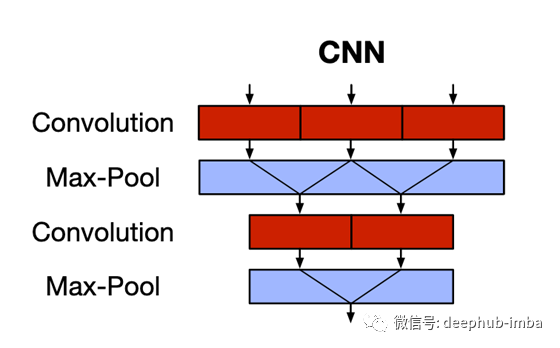
CNN可以捕获空间特征(主要用于图像)。红色块是卷积运算,蓝色块是无参数池化运算。CNN使用内核(或过滤器)通过滑动窗口捕获要素之间的对应关系。这克服了固定长度的隐藏表示形式(以及由此带来的长期依赖问题)以及RNN缺乏并行性限制的问题。但是,CNN不显示序列的时间性质,即时间不变性。池化层只是在不考虑序列顺序信息的情况下降低了通道的维数。
Quasi-Recurrent Neural Networks (QRNN)

QRNN解决了两种标准架构的缺点。它允许并行处理并捕获长期依赖性,例如CNN,还允许输出依赖序列中令牌的顺序,例如RNN。
因此,首先,QRNN体系结构具有2个组件,分别对应于CNN中的卷积(红色)和池化(蓝色)组件。
卷积分量
卷积组件的操作如下:
- 形状的输入序列:(batch_size,sequence_length,embed_dim)
- 每个“ bank”的形状为“ hidden_dim”的内核:(batch_size,kernel_size,embed_dim)。
- 输出是一个形状序列:(batch_size,sequence_length,hidden_dim)。这些是序列的隐藏状态。
卷积运算在序列以及小批量上并行应用。
为了保留模型的因果关系(即,只有过去的标记才可以预测未来),使用了一种称为遮罩卷积(masked-convolutions)的概念。也就是说,输入序列的左边是“ kernel_size-1”零。因此,只有'sequence_length-kernel_size + 1'过去的标记可以预测给定的标记。为了更好理解,请参考下图:

接下来,我们基于池化功能(将在下一节中讨论)使用额外的内核库,以获取类似于LSTM的门控向量:
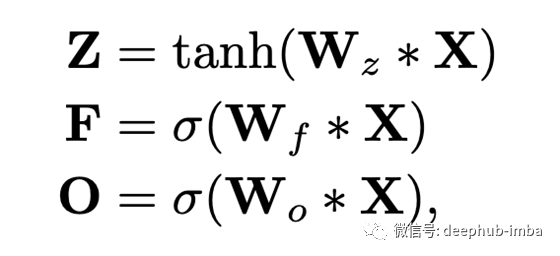
这里,*是卷积运算;Z是上面讨论的输出(称为“输入门”输出);F是使用额外的内核库W_f获得的“忘记门”输出;O是使用额外的内核库W_o获得的“输出门”输出。
如上所述,这些卷积仅应用于过去的“ sequence_length-kernel_size + 1”令牌。因此,如果我们使用kernel_size = 2,我们将得到类似LSTM的方程式:
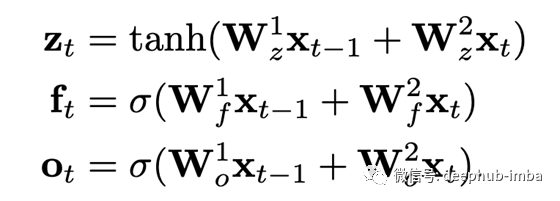
池化组件
通常,合并是一种无参数的函数,可捕获卷积特征中的重要特征。对于图像,通常使用最大池化和平均池化。但是,在序列的情况下,我们不能简单地获取特征之间的平均值或最大值,它需要有一些循环。因此,QRNN论文提出了受传统LSTM单元中元素级门控体系结构启发的池化功能。本质上,它是一个无参数函数,它将跨时间步混合隐藏状态。
最简单的选项是“动态平均池化”,它仅使用了“忘记门”(因此称为f-pooling):
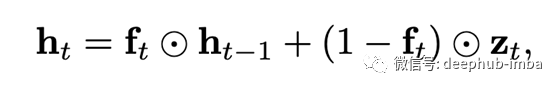
⊙是逐元素矩阵乘法。它以忘记门为参数,几乎等于输出的“移动平均值”。
另一种选择是使用忘记门以及输出门(所以被称作,fo-pooling):
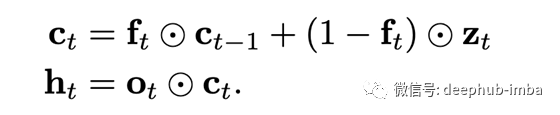
除此以外,池化可能另外具有专用的输入门(ifo-pooling):
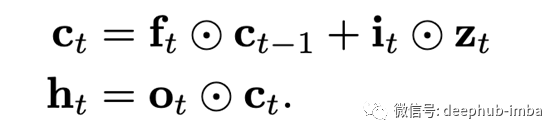
正则化
在检查了各种递归退出方案之后,QRNN使用了一种扩展方案,称为“区域退出”(‘zone out),它本质上是在每个时间步选择一个随机子集来退出,对于这些通道,它只是将当前通道值复制到下一次 步骤,无需任何修改。
这等效于将QRNN的“忘记门”通道的子集随机设置为1,或在1-F上进行dropout -- QRNN Paper
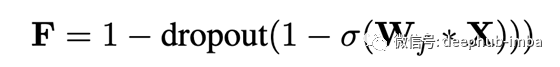
来自DenseNet的想法
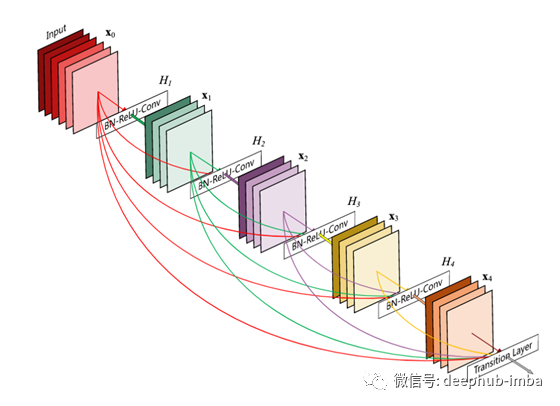
DenseNet体系结构建议在每一层与其前面的每一层之间都具有跳过连接,这与在后续层上具有跳过连接的惯例相反。因此,对于具有L个层的网络,将存在L(L-1)个跳过连接。这有助于梯度流动和收敛,但要考虑二次空间。
使用QRNN构建seq2seq

在基于RNN的常规seq2seq模型中,我们只需使用编码器的最后一个隐藏状态初始化解码器,然后针对解码器序列对其进行进一步修改。我们无法对循环池层执行此操作,因为在这里,编码器状态无法为解码器的隐藏状态做出很大贡献。因此,作者提出了一种改进的解码器架构。
将编码器的最后一个隐藏状态(最后一个令牌的隐藏状态)线性投影(线性层),并在应用任何激活之前,将其添加到解码器层每个时间步长的卷积输出中(广播,因为编码器矢量较小):
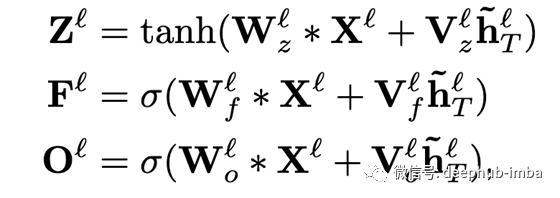
V是应用于最后一个编码器隐藏状态的线性权重。
注意力机制
注意力仅应用于解码器的最后隐藏状态。

其中s是编码器的序列长度,t是解码器的序列长度,L表示最后一层。
首先,将解码器的未选通的最后一层隐藏状态的点积与最后一层编码器隐藏状态相乘。这将导致形状矩阵(t,s)。将Softmax替代s,并使用该分数获得形状(t,hidden_dim)的注意总和k_t。然后,将k_t与c_t一起使用,以获取解码器的门控最后一层隐藏状态。
性能测试

与LSTM架构相比,QRNN可以达到相当的准确度,在某些情况下甚至比LSTM架构略胜一筹,并且运算速度提高了17倍。
最近,基于QRNN的模型pQRNN在序列分类上仅用1.3M参数就取得了与BERT相当的结果(与440M参数的BERT相对):

结论
我们深入讨论了新颖的QRNN架构。我们看到了它如何在基于卷积的模型中增加递归,从而加快了序列建模的速度。QRNN的速度和性能也许真的可以替代Transformer。
作者:Rohan Jagtap
deephub翻译组