
1. 前言
Flink 版本 : 1.13
开发语言 : Scala 2.12

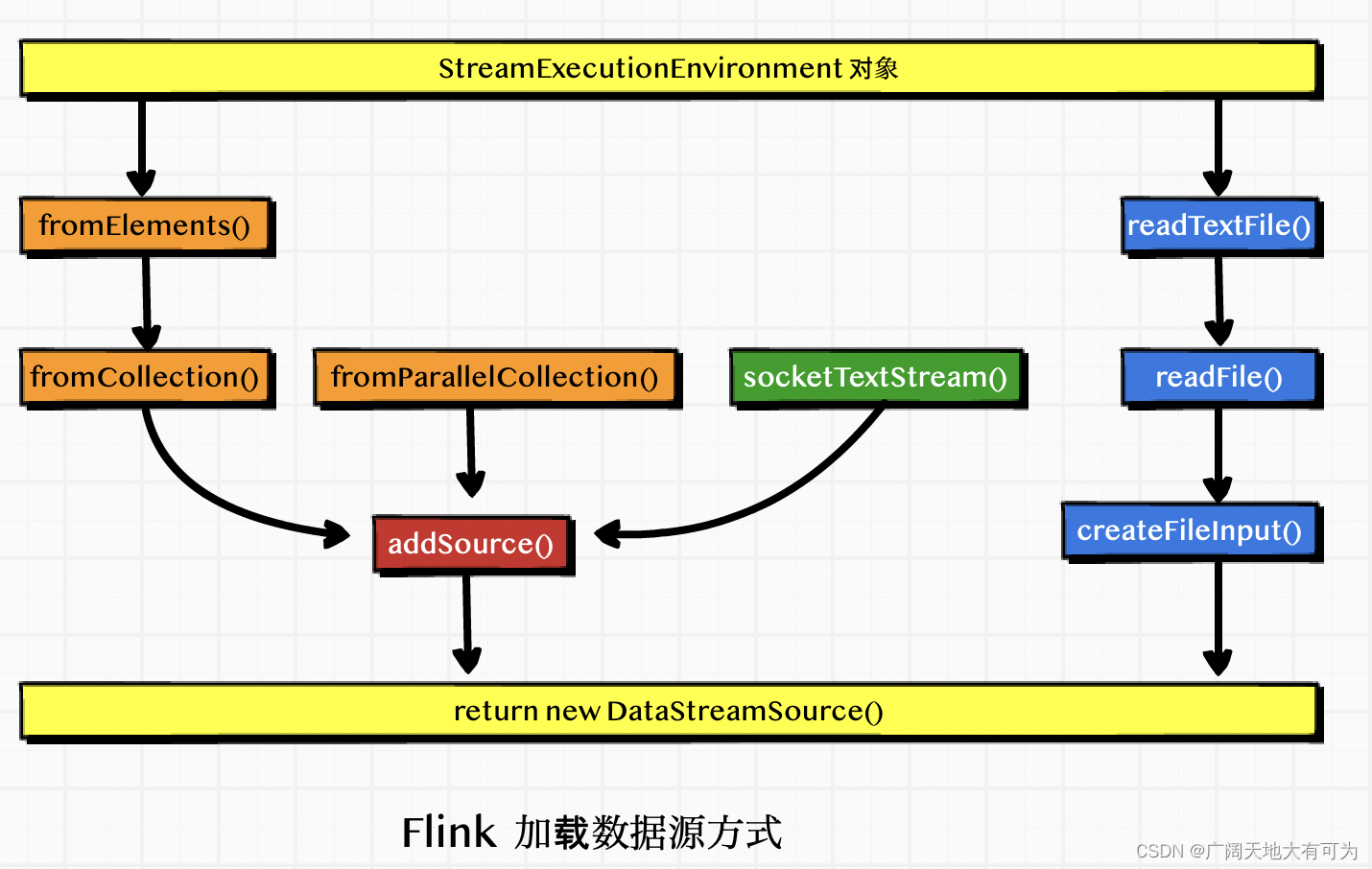
1.1 加载数据源的方式
StreamExecutionEnvironment 对象提供了多种方法来加载 数据源对象
// 通用方法
def addSource[T: TypeInformation](function: SourceFunction[T]): DataStream[T]
// 预定义方法
def readTextFile(filePath: String): DataStream[String]
def fromCollection[T: TypeInformation](data: Seq[T]): DataStream[T]
def socketTextStream(hostname: String, port: Int, delimiter: Char = '\n', maxRetry: Long = 0):DataStream[String]
...
1.2 数据源的类型
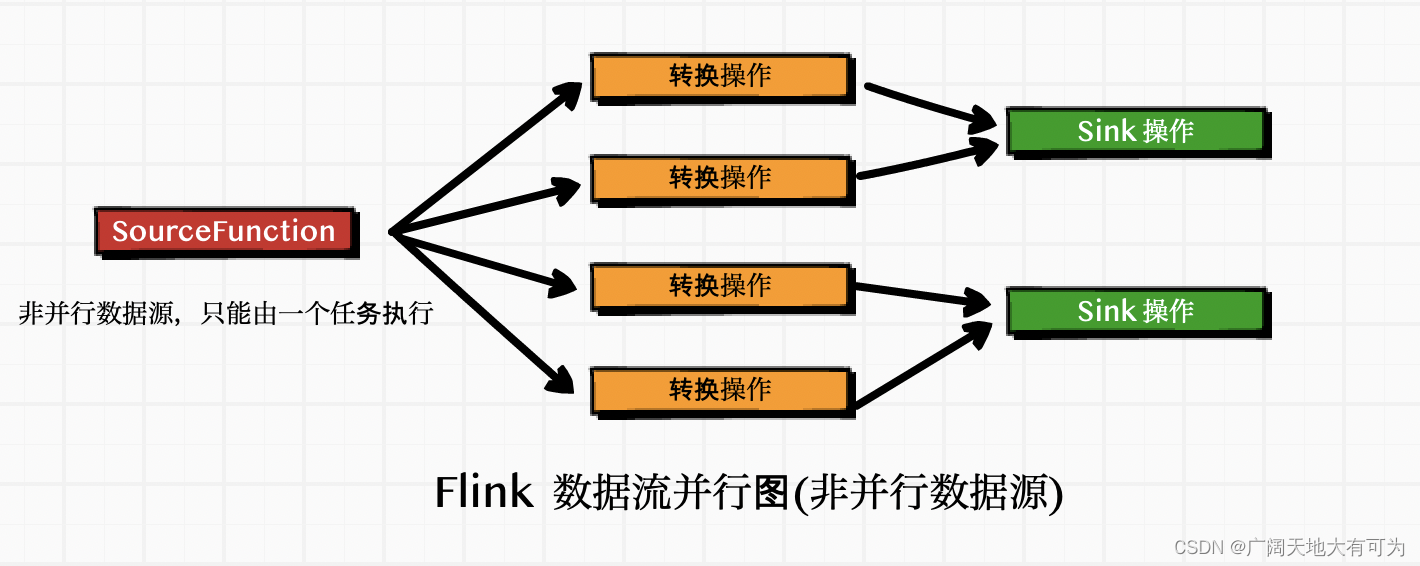
Flink 中的数据源分为 非并行数据源 和 并行数据源 两大类
并行数据源 : 可以将数据源拆分成多个 子任务,并行执行( 并行度允许大于1)
非并行数据源 : 不可以将数据源拆分,只能有单独的任务处理数据 (并行度必须1)
我们可以通过 StreamExecutionEnvironment.addSource(SourceFunction) 将一个 source对象 关 联到编写的 flink应用程序中
Flink API中 自带了许多 SourceFunction的实现类
我们也可以 通过实现 SourceFunction接口 来编写 自定义的非并行的source对象
通过实现 ParallelSourceFunction 接口
继承 RichParallelSourceFunction 类 来编写 自定义的并行source对象

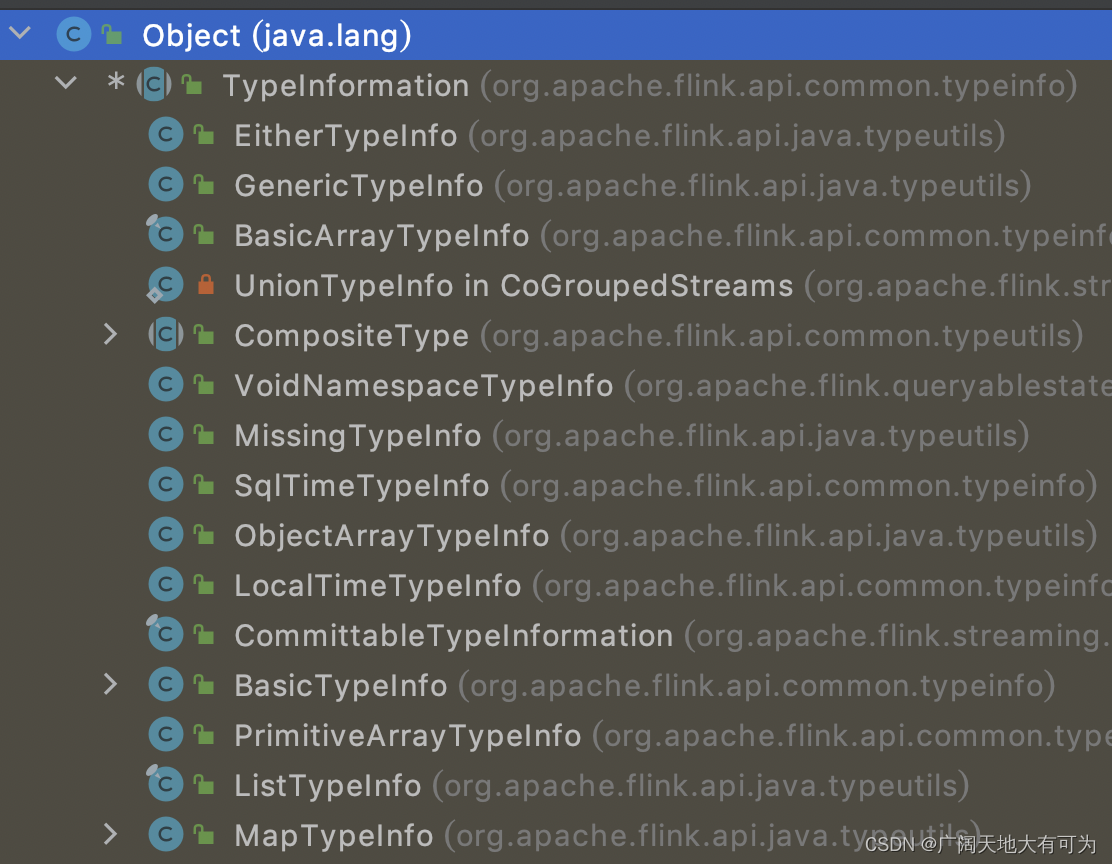
1.3 Flink 中的数据类型(TypeInformation)
Flink 会将外部的数据加载到 DataStreamSource 对象中,加载过程中会将外部的数据的类型转换为 Flink 定义的数据类型
为了方便 数据序列化和反序列化,Flink定义了自己的数据类型系统
2. 从集合中读取数据
非并行数据源
def fromElements[T: TypeInformation](data: T*): DataStream[T]
def fromCollection[T: TypeInformation](data: Seq[T]): DataStream[T]
def fromCollection[T: TypeInformation] (data: Iterator[T]): DataStream[T]
并行数据源
def fromParallelCollection[T: TypeInformation] (data: SplittableIterator[T])
代码示例:
// --------------------------------------------------------------------------------------------
// TODO 从集合中读取数据
// --------------------------------------------------------------------------------------------
test("fromCollection 方法") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将本地集合作为数据源
val list = List("刘备", "张飞", "关羽", "赵云", "马超", "...")
val ds: DataStream[String] = env.fromCollection(list).setParallelism(1)
/*
* tips: 如果这里将 并行度设置为4,将报错
* java.lang.IllegalArgumentException: The parallelism of non parallel operator must be 1.
* */
println(s"并行度: ${ds.parallelism}")
// 3. 打印DataStream
ds.print()
// 4. 出发程序执行
env.execute()
}
test("fromParallelCollection 方法") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将本地集合作为数据源
val iterator: NumberSequenceIterator = new NumberSequenceIterator(1, 10)
val ds: DataStream[lang.Long] = env.fromParallelCollection(iterator).setParallelism(6)
println(s"并行度: ${ds.parallelism}")
// 3. 打印DataStream
ds.print()
// 4. 出发程序执行
env.execute()
}
3. 从文件中读取数据
思考: 读取文件时可以设置哪些规则呢?
1. 文件的格式(txt、csv、二进制...)
2. 文件的分隔符(按\n 分割)
3. 是否需要监控文件变化(一次读取、持续读取)
基于以上规则,Flink为我们提供了非常灵活的 读取文件的方法
3.1 readTextFile
语法说明:
定义:
def readTextFile(filePath: String): DataStream[String]
def readTextFile(filePath: String, charsetName: String)
功能:
1.读取文本格式的文件
2.按行读取(\n为分隔符),每行数据被封装为 DataStream 的一个元素
3.可以指定字符集(默认为UDF-8)
4.文件只会读取一次
源码分析:
public DataStreamSource<String> readTextFile(String filePath, String charsetName) {
// 初始化 TextInputFormat对象
TextInputFormat format = new TextInputFormat(new Path(filePath));
// 指定路径过滤器(使用默认过滤器)
format.setFilesFilter(FilePathFilter.createDefaultFilter());
// 指定Flink中的数据类型
TypeInformation<String> typeInfo = BasicTypeInfo.STRING_TYPE_INFO;
// 指定字符集
format.setCharsetName(charsetName);
// 调用 readFile 方法
return readFile(format, filePath, FileProcessingMode.PROCESS_ONCE, -1, typeInfo);
}
代码示例:
// --------------------------------------------------------------------------------------------
// TODO 从文件中读取数据
// --------------------------------------------------------------------------------------------
test("readTextFile 方法") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将文本文件作为数据源
val ds: DataStream[String] = env.readTextFile("src/main/resources/data/1.txt").setParallelism(4)
// 3. 打印DataStream
ds.print()
// 4. 出发程序执行
env.execute()
}
// --------------------------------------------------------------------------------------------
// TODO 从hdfs_文本文件中读取数据
// --------------------------------------------------------------------------------------------
test("从hdfs_文本文件中读取数据") {
//System.setProperty("HADOOP_USER_NAME", "root")
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将文本文件作为数据源
val ds: DataStream[String] = env.readTextFile("hdfs://worker01:8020/tmp/1.txt")
// 3. 打印DataStream
ds.print()
// 4. 出发程序执行
env.execute()
}
3.2 readFile
语法说明:
定义:
def readFile[T: TypeInformation](
inputFormat: FileInputFormat[T],
filePath: String,
watchType: FileProcessingMode,
interval: Long): DataStream[T] = {
val typeInfo = implicitly[TypeInformation[T]] // 隐私转换(将java 数据类型 转换为 Flink数据类型)
asScalaStream(javaEnv.readFile(inputFormat, filePath, watchType, interval, typeInfo))
}
参数:
inputFormat : 指定 FileInputFormat 实现类(根据文件类型 选择相适应的实例)
filePath : 指定 文件路径
watchType : 指定 读取模式(提供了2个枚举值)
PROCESS_ONCE :只读取一次
PROCESS_CONTINUOUSLY :按照指定周期扫描文件
interval : 指定 扫描文件的周期(单位为毫秒)
功能:
按照 指定的 文件格式 和 读取方式 读取数据
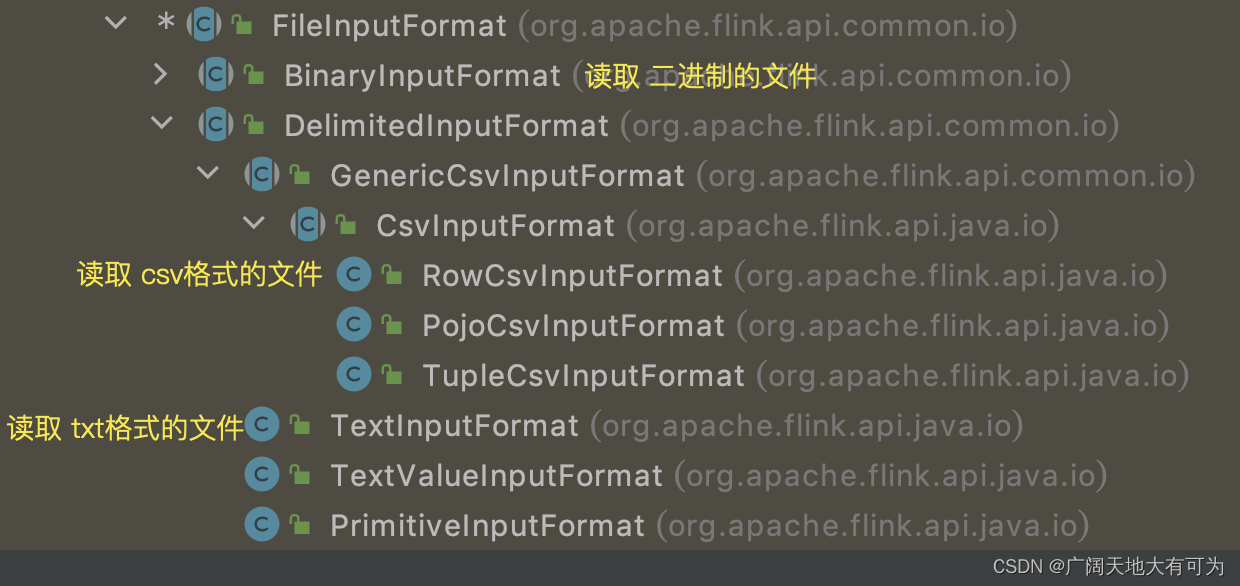 FileInputFormat 的实现类
FileInputFormat 的实现类
代码示例:
test("readFile 方法") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将文本文件作为数据源
val filePath = "src/main/resources/data/1.txt"
// 初始化 TextInputFormat 对象
val format = new TextInputFormat(new Path(filePath))
format.setFilesFilter(FilePathFilter.createDefaultFilter) // 指定过滤器
format.setCharsetName("UTF-8") // 指定编码格式
val ds: DataStream[String] = env.readFile(
format
, filePath
, FileProcessingMode.PROCESS_CONTINUOUSLY // 周期性读取 指定文件
, 1000 // 1s读取一次
)
// 3. 打印DataStream
ds.print()
// 4. 出发程序执行
env.execute()
}
4. 从Socket中读取数据
语法说明:
语法:
def socketTextStream(hostname: String, port: Int, delimiter: Char = '\n', maxRetry: Long = 0):
DataStream[String] =
asScalaStream(javaEnv.socketTextStream(hostname, port))
功能:
执行监控,socket中的文本流,按行读取数据(默认分隔符为 \n)
参数:
hostname : socket服务ip
prot : socket服务端口号
Char : 行分隔符
maxRetry : 当 socket服务 停止时,flink程序 重试连接时间(单位为秒)
=0 时,表示 连接不到 socket服务后,立刻停止 flink程序
=-1 时,表示 永远保持重试连接
tips:
scala API 只提供了一种 socketTextStream方法的实现
如果想使用其他参数,需要使用java api
代码示例:
/*
* TODO 从 Socket 文本流中读取数据
* 开启socket端口: nc -lk 9999
*
* */
test("从 Socket 文本流中读取数据") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将文本文件作为数据源
//val ds: DataStream[String] = env.socketTextStream("localhost", 9999)
val ds: DataStream[String] = env.socketTextStream("localhost", 9999,'#')
// 3. 打印DataStream
ds.print()
// 4. 出发程序执行
env.execute()
}
5. 从Kafka中读取数据
**语法说明: **
语法:
public FlinkKafkaConsumer(String topic, DeserializationSchema<T> valueDeserializer, Properties props)
public FlinkKafkaConsumer(List<String> topics, DeserializationSchema<T> deserializer, Properties props)
参数:
topic : 指定 topic(多个topic时,使用List)
valueDeserializer : 指定 value的序列化类型(kafka数据类型 to flink数据类型)
props : 指定 kafka集群的配置信息
tips:
FlinkKafkaConsumer 是Flink 提供的kafka消费者的实现类
** 消费者可以在多个并行示例中运行,每个实例将从一个或多个Kafka分区中提取数据**
代码示例:
object FlinkReadKafka {
def main(args: Array[String]): Unit = {
// 0. 创建配置对象 并添加消费者相关配置信息
val properties = new Properties
/*
* bootstrap.servers
* 指定broker连接信息 (为保证高可用,建议多指定几个节点)
* 示例: host1:port1,host2:port2
* */
properties.put("bootstrap.servers", "worker01:9092")
/*
* key.deserializer value.deserializer
* 指定 key、value反序列化类型(全类名)
* 示例: key.deserializer=org.apache.kafka.common.serialization.IntegerDeserializer
* 示例: value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
* */
properties.put("key.deserializer","org.apache.kafka.common.serialization.IntegerDeserializer")
properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")
properties.put("auto.offset.reset", "latest")
/*
* group.id
* 指定 消费者组id(不存在时会因创建)
*
* */
properties.put("group.id", "FlinkConsumer")
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将kafka作为数据源
val ds: DataStream[String] = env.addSource(
new FlinkKafkaConsumer(
"20230327", new SimpleStringSchema(), properties
)
)
// 3. 打印DataStream
ds.print()
// 4. 出发程序执行
env.execute()
}
}
6. 自定义数据源
6.1 自定义非并行数据源
** 代码示例:**
/*
* TODO 自定义非并行数据源
* 实现步骤:
* 1.实现 SourceFunction接口
* 2.实现 run方法
* 调用 collect方法 发送数据
* 3.实现 cancel方法
* 注意事项:
* 1.接口的泛型为 数据源的数据类型
* */
class CustomNonParallelSource extends SourceFunction[String] {
// 标志位,用来控制循环的退出
var isRunning = true
override def run(ctx: SourceFunction.SourceContext[String]): Unit = {
val list = List("刘备1", "关羽2", "张飞3", "赵云4", "马超5")
while (isRunning) {
// 调用 collect 方法向下游发送数据
list.foreach(
e => {
ctx.collect(e)
Thread.sleep(1000)
}
)
}
}
// 通过将 isRunning 设置为false,来终止消息的发送
override def cancel(): Unit = isRunning = false
}
/*
* TODO 从 自定义数据源中 读取数据
*
* */
test("从 自定义非并行数据源中 读取数据") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将 自定义数据源 作为数据源
val ds: DataStream[String] = env.addSource(new CustomNonParallelSource).setParallelism(1)
// 3. 打印DataStream
ds.print().setParallelism(1)
// 4. 出发程序执行
env.execute()
}
执行结果:

6.2 自定义并行数据源
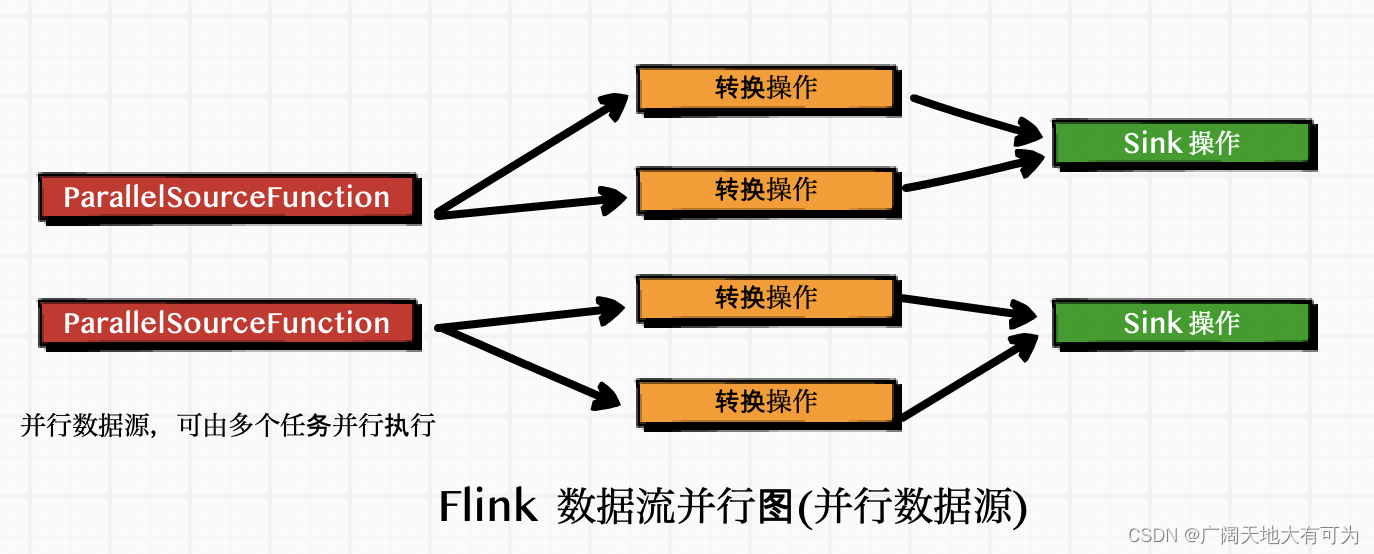
代码示例:
/*
* TODO 自定义并行数据源
* 实现步骤:
* 1.实现 ParallelSourceFunction接口 或者 继承RichParallelSourceFunction
* 2.实现 run方法
* 调用 collect方法 发送数据
* 3.实现 cancel方法
* 注意事项:
* 1.接口的泛型为 数据源的数据类型
* */
class CustomParallelSource extends RichParallelSourceFunction[String] {
// 标志位,用来控制循环的退出
var isRunning = true
override def run(ctx: SourceFunction.SourceContext[String]): Unit = {
val list = List("刘备1", "关羽2", "张飞3", "赵云4", "马超5")
while (isRunning) {
// 调用 collect 方法向下游发送数据
// 调用 collect 方法向下游发送数据
list.foreach(
e => {
ctx.collect(e)
Thread.sleep(1000)
}
)
}
}
// 通过将 isRunning 设置为false,来终止消息的发送
override def cancel(): Unit = isRunning = false
}
test("从 自定义并行数据源中 读取数据") {
// 1. 获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 将 自定义数据源 作为数据源
val ds: DataStream[String] = env.addSource(new CustomParallelSource).setParallelism(4)
// 3. 打印DataStream
ds.print().setParallelism(1)
// 4. 出发程序执行
env.execute()
}
执行结果:

版权归原作者 广阔天地大有可为 所有, 如有侵权,请联系我们删除。