
根据css表达式进行选择
方法名:find_element(By.CSS_SELECTOR, "元素名")
find_elements找所有
示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
if __name__ == '__main__':
wd = webdriver.Chrome()
wd.get("https://cdn2.byhy.net/files/selenium/sample1.html")
# 根据css选择元素
element = wd.find_element(By.CSS_SELECTOR, ".plant")
print(element.get_attribute("outerHTML"))
input()
执行结果:

代表寻找第一个类名为plant的元素,等效于根据CLASS寻找元素
若要根据tag名寻找,不用加“.”, 直接写tag名称即可,如下:
# 根据tag名
element = wd.find_element(By.CSS_SELECTOR, "div")
print(element.get_attribute("outerHTML"))
结果:

根据id寻找用“#”+id名, 中间不能有空格
# 根据id寻找
element = wd.find_element(By.CSS_SELECTOR, "#searchtext")
print(element.get_attribute("outerHTML"))
结果:

** css选择子元素和后代元素**
子元素是被直接包含的元素
后代元素是被包含的元素
若元素2为元素1的直接子元素,css选择语法:
元素1>元素2
最终选择的元素是元素2, 且要求元素2是元素1的直接子元素
也可以支持多层级的选择,如:
元素1>元素2>元素3>元素4
最终选择元素4, 且元素4是元素3的直接子元素,元素3是元素2的直接子元素,元素2是元素1的直接子元素
若只需要是后代元素, 则用空格隔开即可:
元素1 元素2 元素3 元素4
最终选择的是元素4
根据子元素寻找实例:
# 根据子元素寻找
elements = wd.find_elements(By.CSS_SELECTOR, "#container>div") # 找出id为container下,所有标签名为div的元素
for e in elements:
print(e.get_attribute("outerHTML"))
执行结果:

根据后代元素进行选择
# 根据后代元素寻找
elements = wd.find_elements(By.CSS_SELECTOR, "#container span") # 找到id为container下的所有标签名为span的元素
for e in elements:
print(e.get_attribute("outerHTML"))
执行结果:

css根据普通属性值选择
对于普通的属性,除了CLASS_NAME与ID之外,css可以用[]将属性传入进行选择
# 根据普通的属性选择(除了class_name与id之外的属性)
element = wd.find_element(By.CSS_SELECTOR, '[type="text"]')
print(element.get_attribute("outerHTML"))

如果属性名已经可以找到,可以不加=后面的内容
css表达式可以组合使用
div[class='xxx'] 代表寻找的是tag名为div, 属性名为class且值为xxx的元素
验证选择的正确
可以在浏览器开发者模式下ctrl+f, 写入css表达式查看是否寻找正确
表达式组合使用
'div.animal'代表找到一个元素标签名为div,类名为animal。
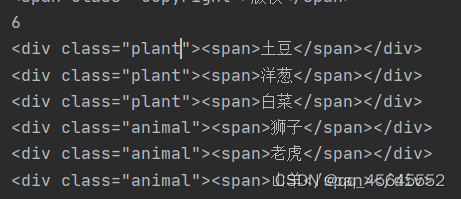
如果要找所有的类名为plant和animal:
'.plant,.animal', 式中“,”就代表“或”的意思,及寻找类名为plant或animal的元素
elements = wd.find_elements(By.CSS_SELECTOR, ".plant,.animal")
print(len(elements))
for e in elements:
print(e.get_attribute("outerHTML"))
各个运算符之间有优先级关系,如果要找id=t1下的所有标签名为h3,p,span的元素,
#t1>span,p,h3是不可以的,因为“,”的优先级较低,无法得到预想的结果。
正确写法如下:#t1>span,#t1>p,#t1>h3
wd.get("https://cdn2.byhy.net/files/selenium/sample1a.html")
elements = wd.find_elements(By.CSS_SELECTOR, "#t1>span,#t1>p,#t1>h3")
print(len(elements))
for e in elements:
print(e.get_attribute("outerHTML"))
选择奇数结点:
nth-of-type(odd)
偶数:
nth-of-type(even)
相邻兄弟结点选择
用+号, 代表紧跟着的元素, 如:h3+span
如果选择后面所有的span, 则h3~span
代码:
# 相邻兄弟结点选择
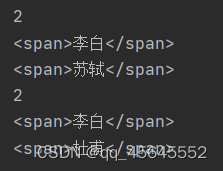
elements = wd.find_elements(By.CSS_SELECTOR, "h3+span") # 标签名为span, 并且是父节点中的该类型的第1个元素
print(len(elements))
for e in elements:
print(e.get_attribute("outerHTML"))
elements = wd.find_elements(By.CSS_SELECTOR, "#t1 h3~span") # id=t1中,h3之后所有的span元素
print(len(elements))
for e in elements:
print(e.get_attribute("outerHTML"))
版权归原作者 qq_45645552 所有, 如有侵权,请联系我们删除。