
猫狗识别
项目数据分为带标签和不带标签
带标签:25000张
不带标签:12500张
文章目录
数据分类处理
数据集可以从kaggle下载
https://www.kaggle.com/c/dogs-vs-cats
也可以从我网盘下载
链接:https://pan.baidu.com/s/1_A3H4nsL8xX4cmMEMtpACg?pwd=mpvi
提取码:mpvi
–来自百度网盘超级会员V7的分享
下载的数据存放在data文件夹下
创建用于创建文件夹的函数
# 如果文件夹不存在就创建defmkdir(path):ifnot os.path.exists(path):
os.makedirs(path)
# 获取当前路径
runPath = os.getcwd()
data_dir =runPath +'/data/'
mkdir(data_dir)
- train是25000张带标签的猫狗图片
- test1是12500张无标签的猫狗图片
我们将这25000张带标签的猫狗图片进行分类
分为训练集和验证集
训练集 20000张 验证集 5000张
猫的训练数据保存在
train/cat
下 一共是10000张
猫的校验数据保存在
valid/cat
下一共是2500张
狗的训练数据保存在
train/dog
下 一共是10000张
狗的校验数据保存在
valid/dog
下一共是2500张
# 训练素材路径
train_dir = data_dir +'train/'
mkdir(train_dir)# 校验素材路径
valid_dir = data_dir +'valid/'
mkdir(valid_dir)# 猫训练素材文件夹
cat_dir = train_dir +'cat/'
mkdir(cat_dir)# 猫校验素材文件夹
cat_val_dir = valid_dir +'cat/'
mkdir(cat_val_dir)# 狗训练素材文件夹
dog_dir = train_dir +'dog/'
mkdir(dog_dir)# 狗校验素材文件夹
dog_val_dir = valid_dir +'dog/'
mkdir(dog_val_dir)
使用代码进行将这25000张带标签的猫狗图片进行分类
# 移动文件到指定文件夹defmove_file(file_path, target_path):# 路径分离出文件名
fileName = os.path.split(file_path)[1]# 拼接目标路径名
target_path+='/'+fileName
print(target_path)if os.path.exists(file_path):
shutil.move(file_path, target_path)else:print('文件不存在')# 分离图片到指定文件夹defchangeFile(filetype):
test_file =[]for i inrange(0,12500,1):
filename = train_dir+filetype+"."+str(i)+'.jpg'print(filename)# 训练数据10000if i <10000:
move_file(filename,train_dir +filetype)# 验证数据2500else:
move_file(filename,valid_dir +filetype)# 分离猫
changeFile('cat')# 分离狗
changeFile('dog')
检查分类情况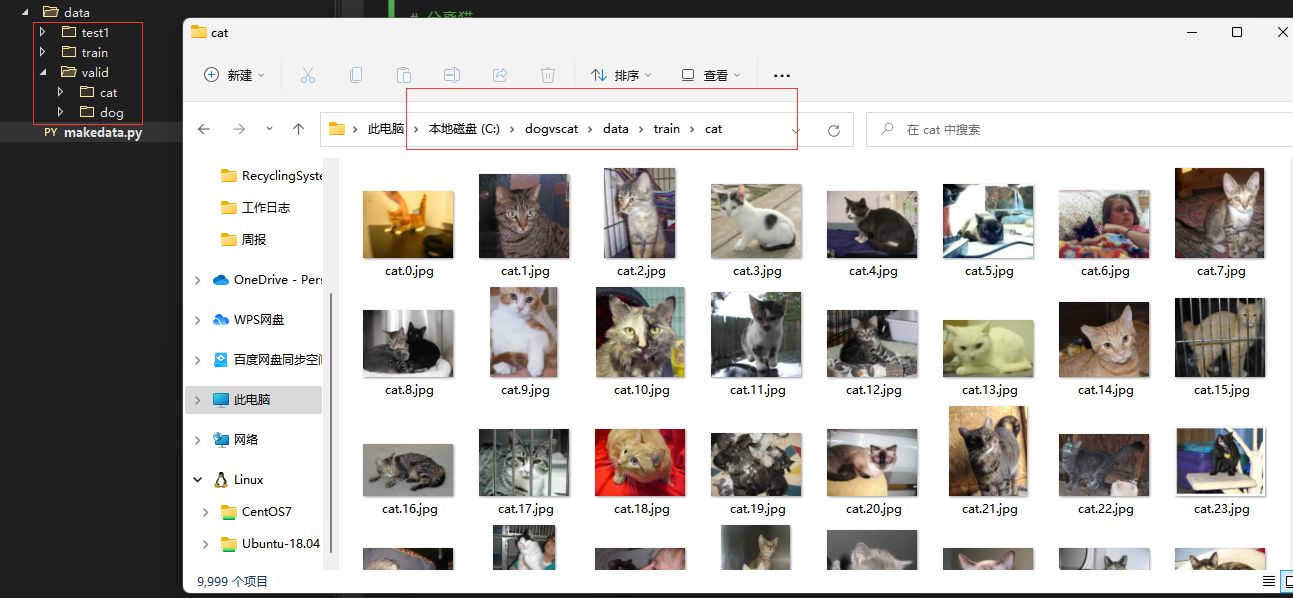
目录情况
图像增强预处理
训练前,我们将全部的图像输入ImageDataGenerator进行图像增强预处理
参数可以自行修改
# 图像增强数据预处理# 返回训练集和校验集预处理模板defimg_transforms():# 创建训练数据预处理模板
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,# 所有数据集将乘以该数值(归一化,数据范围控制在0到1之间)
rotation_range=40,# 随机旋转的范围
width_shift_range=0.2,# 随机宽度偏移量
height_shift_range=0.2,# 随机高度偏移量
shear_range=0.2,# 随机错切变换
zoom_range=0.2,# 随机缩放范围
horizontal_flip=True,# 随机将一半图像水平翻转
fill_mode='nearest',# 填充模式为最近点填充)# 从文件夹导入训练集
train_generator = train_datagen.flow_from_directory(
train_dir,# 训练数据文件夹
target_size=(128,128),# 处理后的图片大小128*128
batch_size=64,# 每次训练导入多少张图片
seed=7,# 随机数种子
shuffle=True,# 随机打乱数据
class_mode='categorical'# 返回2D的one-hot编码标签)# 创建校验数据预处理模板
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,# 数据范围控制在0到1之间)# # 从文件夹导入校验集
valid_generator = valid_datagen.flow_from_directory(
valid_dir,# 校验数据文件夹
target_size=(128,128),# 处理后的图片大小128*128
batch_size=64,# 每次训练导入多少张图片
seed=7,# 随机数种子
shuffle=False,# 随机打乱数据
class_mode="categorical"# 返回2D的one-hot编码标签)return train_generator,valid_generator
# 图像预处理
train_generator,valid_generator = img_transforms()
编写神经网络结构
构建一个8层的神经网络,卷积层6层,全连接层2层,每两个卷积层添加一个池化层防止过拟合
# 编写神经网络# 参数1:样本宽# 参数2:样本高# 参数3:样本深度# 参数4:输出个数defcnn(width,height,depth,outputNum):# 按顺序添加神经层# 神经网络的层数指的是有权重计算的层,池化层不算层数# 该模型卷积层6层 全连接层2层 共8层
model = tf.keras.models.Sequential([# Conv2D 向两个维度进行卷积https://blog.csdn.net/qq_37774098/article/details/111997250# 卷积层 输入样本为宽:128 高:128 深度:3
tf.keras.layers.Conv2D(filters=32,# 32个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu',# 激活函数:relu
input_shape=[width, height, depth]),# 输入形状 宽:128 高:128 深度:3 不定义那就是默认输入的形状# 卷积层
tf.keras.layers.Conv2D(filters=32,# 32个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu'),# 激活函数:relu# 池化层 https://blog.csdn.net/Chen_Swan/article/details/105486854# 池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合
tf.keras.layers.MaxPool2D(pool_size=2),# 池化核大小2x2# 卷积层
tf.keras.layers.Conv2D(filters=64,# 64个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu'),# 激活函数:relu# 卷积层
tf.keras.layers.Conv2D(filters=64,# 64个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu'),# 激活函数:relu# 池化层
tf.keras.layers.MaxPool2D(pool_size=2),# 池化核大小2x2# 卷积层
tf.keras.layers.Conv2D(filters=128,# 128个过滤器
kernel_size=3,# 核大小3x3
padding='same',# 边缘用0填充
activation='relu'),# 激活函数:relu# 卷积层
tf.keras.layers.Conv2D(filters=128,# 128个过滤器
kernel_size=3,# 核大小3x3
padding='same',# 边缘用0填充
activation='relu'),# 激活函数:relu# 池化层
tf.keras.layers.MaxPool2D(pool_size=2),# 池化核大小2x2# 输入层的数据压成一维的数据
tf.keras.layers.Flatten(),# 全连接层
tf.keras.layers.Dense(128, activation='relu'),# 输出的维度大小128个特征点 激活函数:relu
tf.keras.layers.Dense(outputNum, activation='softmax')# 输出猫狗类型 2类 猫或者狗 激活函数:softmax 用于逻辑回归])# 模型处理# compile的用法:https://blog.csdn.net/yunfeather/article/details/106461754
model.compile(loss='categorical_crossentropy',# 损失函数 https://blog.csdn.net/qq_40661327/article/details/107034575
optimizer='adam',# 优化器
metrics=['accuracy'])# 准确率# 打印模型每层的情况
model.summary()return model
model = cnn(128,128,3,2)
设置模型保存路径
将模型保存在model文件夹下的catvsdog_weights.h5中
# 设置模型保存路径
modelPath ='./model'
mkdir(modelPath)
output_model_file = os.path.join(modelPath,"catvsdog_weights.h5")
输入样本进入模型进行训练
设置为回调模式,使用model.fit进行训练
使用EarlyStopping,当准确率没有提高超过一定幅度的话就会停止训练
# 打印学习信息defplot_learning_curves(history, label, epochs, min_value, max_value):
data ={}
data[label]= history.history[label]
data['val_'+ label]= history.history['val_'+ label]
pd.DataFrame(data).plot(figsize=(8,5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()# 定义训练步数
TRAIN_STEP =100# 设置回调模式
callbacks =[
tf.keras.callbacks.TensorBoard(modelPath),
tf.keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only=True,
save_weights_only=True),
tf.keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)]# 开始训练
history = model.fit(
train_generator,
epochs=TRAIN_STEP,
validation_data = valid_generator,
callbacks = callbacks
)# 显示训练曲线
plot_learning_curves(history,'accuracy', TRAIN_STEP,0,1)
plot_learning_curves(history,'loss', TRAIN_STEP,0,5)
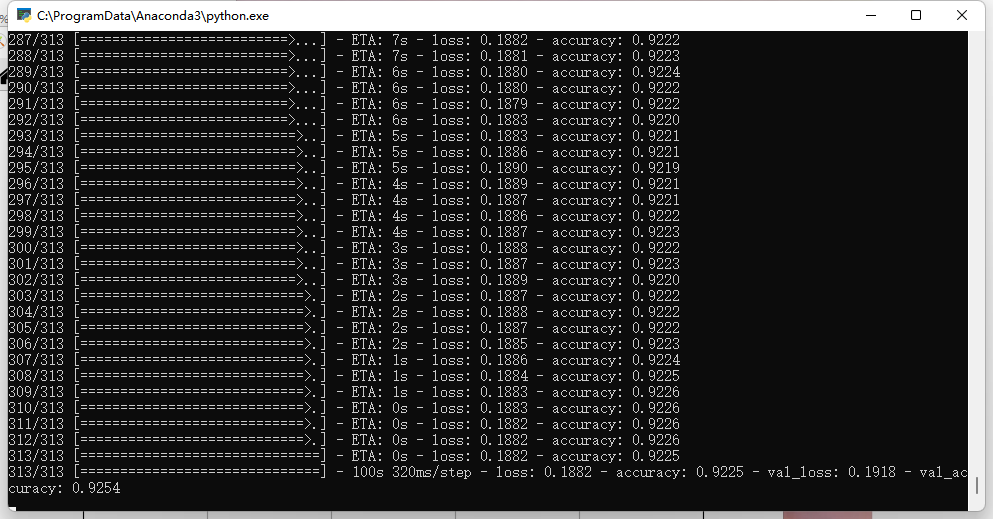
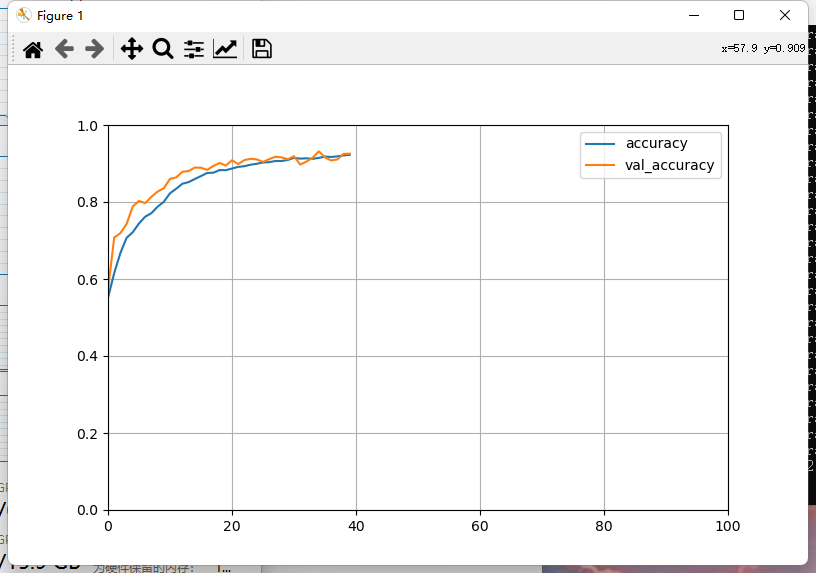
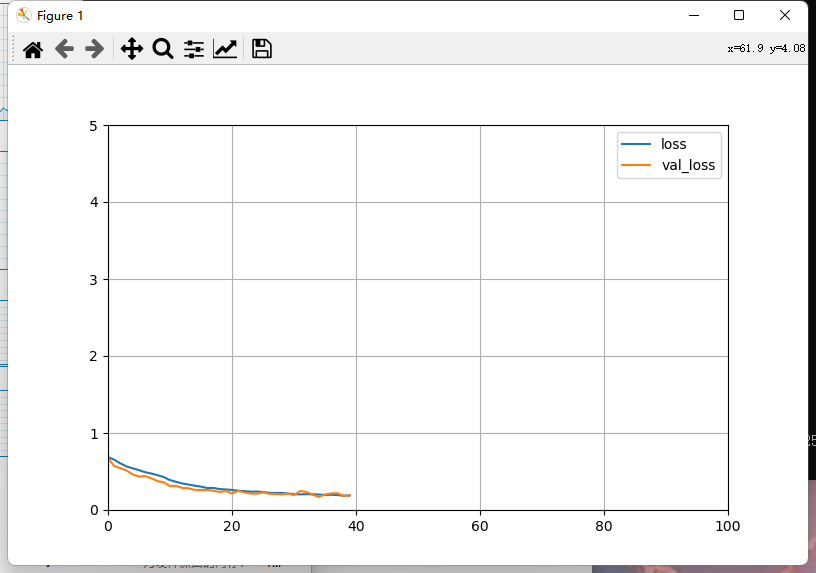
可以看到训练到40步的时候准确率已经变化不大了
加载模型进行预测
准备两张要预测的图片
dog.jpg
cat.jpg
也可以直接使用test1下的图片进行预测,这里只是觉得这两张图可爱
# 预测# 参数1:要预测的图像cv2格式# 参数1:模型# 参数2:模型路径# 参数3:模型名称# 参数4:特征宽# 参数5:特征高# 参数6:特征深度# 参数7:结果1名称# 参数8:结果2名称defpredict(cvImg,model,modelPath,modelName,width,height,depth,result1,result2):
model_file = os.path.join(modelPath,modelName)# 加载模型
model.load_weights(modelName)# 缩放图像减少检测时间
img = cv2.resize(cvImg,(width, height))# 归一化
img_arr = img /255.0# 重构成模型需要输入的格式
img_arr = img_arr.reshape((1, width, height, depth))# 输入模型进行预测
pre = model.predict(img_arr)# 打印预测结果if pre[0][0]> pre[0][1]:print("识别结果是:"+result1+"\n概率:"+str(pre[0][0]))else:print("识别结果是:"+result2+"\n概率:"+str(pre[0][1]))
img = cv2.imread("cat.jpg")
cv2.imshow("img",img)
predict(img,model,modelPath,"catvsdog_weights.h5",128,128,3,"猫","狗")
cv2.waitKey(0)
识别结果为猫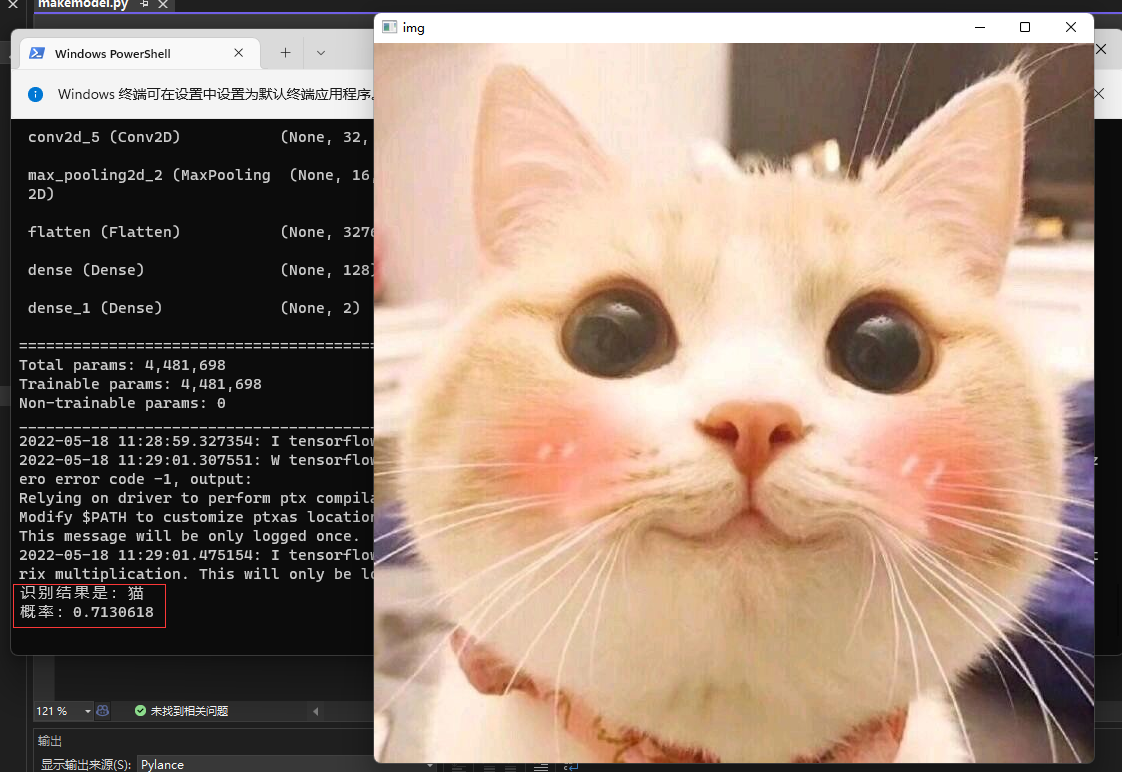
识别结果为狗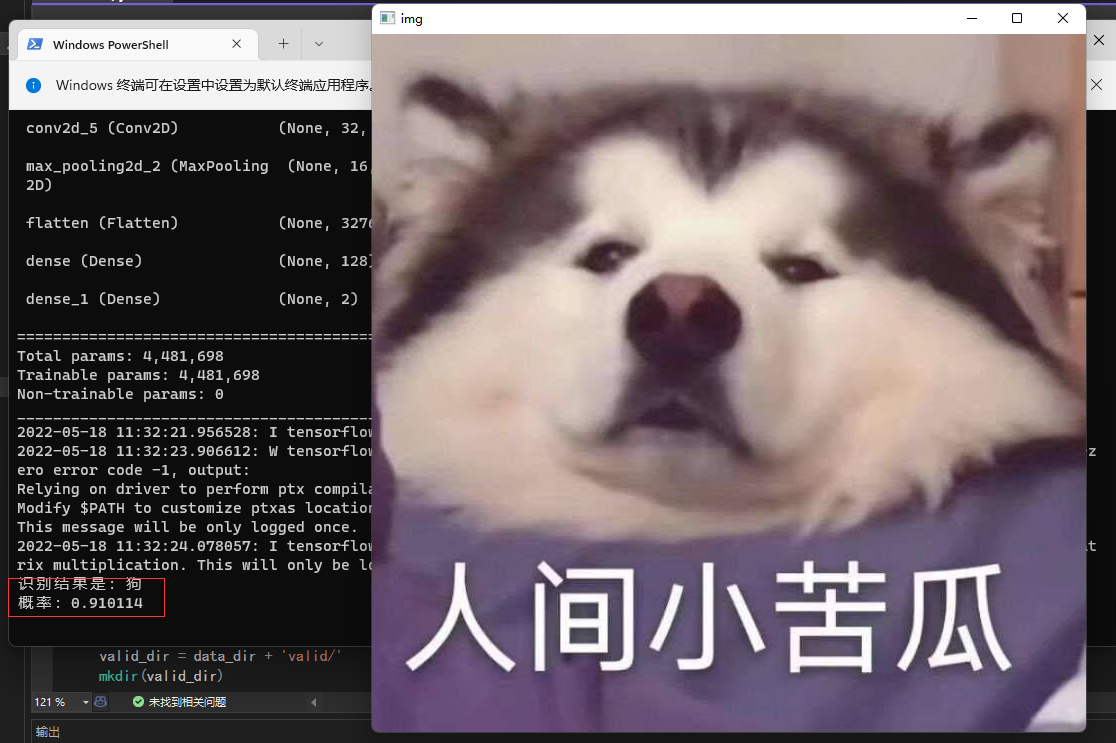
随机从测试集中抽取一张图片进行预测
# 随机从测试集中读取文件
test_dir = data_dir +"test1/"
readImg = test_dir +str(random.randint(0,12499))+".jpg"
img = cv2.imread(readImg)
predict(img,model,modelPath,modelName,simpleWight,simpleHeight,simpleDepth,result1,result2)
cv2.imshow("img",img)
cv2.waitKey(0)
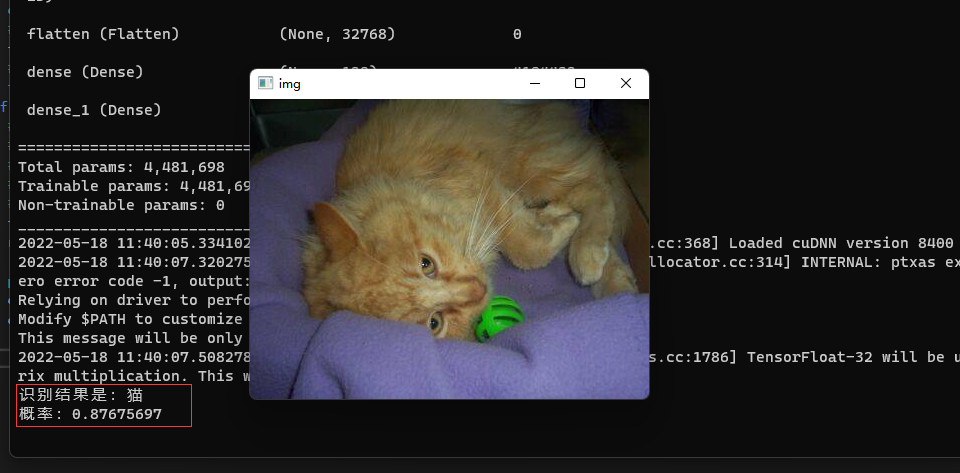
完整代码
import os
# 设置LOG等级为 1 警告 2 错误
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'# 0为使用CPU 1为使用GPU
CPU =1if CPU ==0:
os.environ['CUDA_VISIBLE_DEVICES']='-1'else:
os.environ['CUDA_VISIBLE_DEVICES']='0'import random
import shutil
import cv2
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
# 模式选择:0 训练模型 1 预测图片
mode =1# 移动文件到指定文件夹defmove_file(file_path, target_path):# 路径分离出文件名
fileName = os.path.split(file_path)[1]# 拼接目标路径名
target_path+='/'+fileName
print(target_path)if os.path.exists(file_path):
shutil.move(file_path, target_path)else:print('文件不存在')# 如果文件夹不存在就创建defmkdir(path):ifnot os.path.exists(path):
os.makedirs(path)# 分离图片到指定文件夹defchangeFile(filetype):
test_file =[]for i inrange(0,12500,1):
filename = train_dir+filetype+"."+str(i)+'.jpg'print(filename)# 训练数据10000if i <10000:
move_file(filename,train_dir +filetype)# 验证数据2500else:
move_file(filename,valid_dir +filetype)# 图像增强数据预处理# 参数解释参考:# https://blog.csdn.net/fioletfly/article/details/101345584# https://wenku.baidu.com/view/8f05e708ac45b307e87101f69e3143323968f5c6.html# 返回训练集和校验集预处理模板# 参数1:训练集文件夹路径# 参数2:校验集文件夹路径defimg_transforms(train_dir,valid_dir):# 创建训练数据预处理模板
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,# 所有数据集将乘以该数值(归一化,数据范围控制在0到1之间)
rotation_range=40,# 随机旋转的范围
width_shift_range=0.2,# 随机宽度偏移量
height_shift_range=0.2,# 随机高度偏移量
shear_range=0.2,# 随机错切变换
zoom_range=0.2,# 随机缩放范围
horizontal_flip=True,# 随机将一半图像水平翻转
fill_mode='nearest',# 填充模式为最近点填充)# 从文件夹导入训练集
train_generator = train_datagen.flow_from_directory(
train_dir,# 训练数据文件夹
target_size=(128,128),# 处理后的图片大小128*128
batch_size=64,# 每次训练导入多少张图片
seed=7,# 随机数种子
shuffle=True,# 随机打乱数据
class_mode='categorical'# 返回2D的one-hot编码标签)# 创建校验数据预处理模板
valid_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,# 数据范围控制在0到1之间)# # 从文件夹导入校验集
valid_generator = valid_datagen.flow_from_directory(
valid_dir,# 校验数据文件夹
target_size=(128,128),# 处理后的图片大小128*128
batch_size=64,# 每次训练导入多少张图片
seed=7,# 随机数种子
shuffle=False,# 随机打乱数据
class_mode="categorical"# 返回2D的one-hot编码标签)return train_generator,valid_generator
# 编写神经网络# 参数1:样本宽# 参数2:样本高# 参数3:样本深度# 参数4:输出个数defcnn(width,height,depth,outputNum):# 按顺序添加神经层# 神经网络的层数指的是有权重计算的层,池化层不算层数# 该模型卷积层6层 全连接层2层 共8层
model = tf.keras.models.Sequential([# Conv2D 向两个维度进行卷积https://blog.csdn.net/qq_37774098/article/details/111997250# 卷积层 输入样本为宽:128 高:128 深度:3
tf.keras.layers.Conv2D(filters=32,# 32个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu',# 激活函数:relu
input_shape=[width, height, depth]),# 输入形状 宽:128 高:128 深度:3 不定义那就是默认输入的形状# 卷积层
tf.keras.layers.Conv2D(filters=32,# 32个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu'),# 激活函数:relu# 池化层 https://blog.csdn.net/Chen_Swan/article/details/105486854# 池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合
tf.keras.layers.MaxPool2D(pool_size=2),# 池化核大小2x2# 卷积层
tf.keras.layers.Conv2D(filters=64,# 64个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu'),# 激活函数:relu# 卷积层
tf.keras.layers.Conv2D(filters=64,# 64个过滤器
kernel_size=3,# 核大小3x3
padding='same',# same:边缘用0填充 valid:边缘不填充
activation='relu'),# 激活函数:relu# 池化层
tf.keras.layers.MaxPool2D(pool_size=2),# 池化核大小2x2# 卷积层
tf.keras.layers.Conv2D(filters=128,# 128个过滤器
kernel_size=3,# 核大小3x3
padding='same',# 边缘用0填充
activation='relu'),# 激活函数:relu# 卷积层
tf.keras.layers.Conv2D(filters=128,# 128个过滤器
kernel_size=3,# 核大小3x3
padding='same',# 边缘用0填充
activation='relu'),# 激活函数:relu# 池化层
tf.keras.layers.MaxPool2D(pool_size=2),# 池化核大小2x2# 输入层的数据压成一维的数据
tf.keras.layers.Flatten(),# 全连接层
tf.keras.layers.Dense(128, activation='relu'),# 输出的维度大小128个特征点 激活函数:relu
tf.keras.layers.Dense(outputNum, activation='softmax')# 输出猫狗类型 2类 猫或者狗 激活函数:softmax 用于逻辑回归])# 模型处理# compile的用法:https://blog.csdn.net/yunfeather/article/details/106461754
model.compile(loss='categorical_crossentropy',# 损失函数 https://blog.csdn.net/qq_40661327/article/details/107034575
optimizer='adam',# 优化器
metrics=['accuracy'])# 准确率# 打印模型每层的情况
model.summary()return model
# 训练# 参数1:模型# 参数2:模型路径# 参数3:模型名称# 参数4:训练步数# 参数5:训练集# 参数6:校验集# 参数5:是否打印训练曲线deftrain(model,modelPath,modelName,step,train_generator,valid_generator,isplot=False):# 打印学习信息defplot_learning_curves(history, label, epochs, min_value, max_value):
data ={}
data[label]= history.history[label]
data['val_'+ label]= history.history['val_'+ label]
pd.DataFrame(data).plot(figsize=(8,5))
plt.grid(True)
plt.axis([0, epochs, min_value, max_value])
plt.show()
output_model_file = os.path.join(modelPath,modelName)# 设置回调模式
callbacks =[
tf.keras.callbacks.TensorBoard(modelPath),
tf.keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only=True,
save_weights_only=True),
tf.keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)]# 开始训练
history = model.fit(
train_generator,
epochs=step,
validation_data = valid_generator,
callbacks = callbacks
)if isplot:# 显示训练曲线
plot_learning_curves(history,'accuracy', TRAIN_STEP,0,1)
plot_learning_curves(history,'loss', TRAIN_STEP,0,5)# 预测# 参数1:要预测的图像cv2格式# 参数1:模型# 参数2:模型路径# 参数3:模型名称# 参数4:特征宽# 参数5:特征高# 参数6:特征深度# 参数7:结果1名称# 参数8:结果2名称defpredict(cvImg,model,modelPath,modelName,width,height,depth,result1,result2):
model_file = os.path.join(modelPath,modelName)# 加载模型
model.load_weights(model_file)# 缩放图像减少检测时间
img = cv2.resize(cvImg,(width, height))# 归一化
img_arr = img /255.0# 重构成模型需要输入的格式
img_arr = img_arr.reshape((1, width, height, depth))# 输入模型进行预测
pre = model.predict(img_arr)# 打印预测结果if pre[0][0]> pre[0][1]:print("识别结果是:"+result1+"\n概率:"+str(pre[0][0]))else:print("识别结果是:"+result2+"\n概率:"+str(pre[0][1]))# 获取当前路径
runPath = os.getcwd()
data_dir =runPath +'/data/'
mkdir(data_dir)# 训练素材路径
train_dir = data_dir +'train/'
mkdir(train_dir)# 校验素材路径
valid_dir = data_dir +'valid/'
mkdir(valid_dir)# 猫训练素材文件夹
cat_dir = train_dir +'cat/'
mkdir(cat_dir)# 猫校验素材文件夹
cat_val_dir = valid_dir +'cat/'
mkdir(cat_val_dir)# 狗训练素材文件夹
dog_dir = train_dir +'dog/'
mkdir(dog_dir)# 狗校验素材文件夹
dog_val_dir = valid_dir +'dog/'
mkdir(dog_val_dir)# 设置模型保存路径
modelPath ='./model'
mkdir(modelPath)# 测试模型名称
modelName ="catvsdog_weights.h5"# 设置样本参数
simpleWight =128
simpleHeight =128
simpleDepth =3# 设置输出类型
outputNum =2
result1 ="猫"
result2 ="狗"# 定义训练步数
TRAIN_STEP =100# 搭建神经网络
model = cnn(simpleWight,simpleHeight,simpleDepth,outputNum)if mode ==0:# 分离猫
changeFile('cat')# 分离狗
changeFile('dog')# 图像预处理
train_generator,valid_generator = img_transforms(train_dir,valid_dir)# 训练模型
train(model,modelPath,modelName,TRAIN_STEP,train_generator,valid_generator)elif mode ==1:#img = cv2.imread("dog.jpg")#predict(img,model,modelPath,modelName,simpleWight,simpleHeight,simpleDepth,result1,result2)#cv2.imshow("img",img)#cv2.waitKey(0)# 随机从测试集中读取文件
test_dir = data_dir +"test1/"
readImg = test_dir +str(random.randint(0,12499))+".jpg"
img = cv2.imread(readImg)
predict(img,model,modelPath,modelName,simpleWight,simpleHeight,simpleDepth,result1,result2)
cv2.imshow("img",img)
cv2.waitKey(0)
本文转载自: https://blog.csdn.net/lx7820336/article/details/124768769
版权归原作者 三千院喵 所有, 如有侵权,请联系我们删除。
版权归原作者 三千院喵 所有, 如有侵权,请联系我们删除。