
推荐阅读按照自己需要的顺序,不需要从头开始。
简单介绍
playwright是一款新型的自动化测试工具,功能非常强大,使用下来有很多的优点 👍 :
- 支持异步。
- 内置浏览器驱动。
- 支持移动端。
- 代码生成。
- 安装和使用都非常简单。
缺点:
- 使用的人比较少。
- 教程少👉(推荐崔大的教程)
- 没有中文文档。
安装
pip
pip install --upgrade pip
pip install playwright # 安装playwright
playwright install # 安装驱动
conda
conda config --add channels conda-forge
conda config --add channels microsoft
conda install playwright # 安装playwright
playwright install # 安装驱动
基本使用方法
同步模式
from playwright.sync_api import sync_playwright
with sync_playwright()as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('http://www.baidu.com')print(page.title)
browser.close()
异步模式
asyncdefmain():asyncwith async_playwright()as p:
browser =await p.chromium.launch(headless=False)
page =await browser.new_page()await page.goto("http://www.baidu.com")print(await page.title())await browser.close()
asyncio.run(main())
方法简介
创建浏览器对象
可以选择不同的浏览器版本,msedge就是Microsoft Edge浏览器,同时还支持beta版本。在大部分情况下,使用默认的chrome浏览器足够了。
# 同步# Can be "msedge", "chrome-beta", "msedge-beta", "msedge-dev", etc.
browser = playwright.chromium.launch(channel="chrome")
# 异步# Can be "msedge", "chrome-beta", "msedge-beta", "msedge-dev", etc.
browser =await playwright.chromium.launch(channel="chrome")
浏览器上下文
浏览器上下文对象是浏览器实例中一个类似于隐身模式的会话,简单说就是该上下文资源是完全独立的,与其他的上下文互不干扰,所以在自动化测试中,可以对每一个测试用例都单独开一个浏览器上下文。这对于多用户,多场景的测试非常有用。
# 同步
browser = playwright.chromium.launch()
context = browser.new_context()
page = context.new_page()# 异步
browser =await playwright.chromium.launch()
context =await browser.new_context()
page =await context.new_page()
食用栗子
# 同步模式from playwright.sync_api import sync_playwright
defrun(playwright):# 创建一个浏览器实例
chromium = playwright.chromium
browser = chromium.launch()# 创建两个浏览器上下文
user_context = browser.new_context()
admin_context = browser.new_context()# 创建选项卡和上下文之间的交互with sync_playwright()as playwright:
run(playwright)# 异步模式import asyncio
from playwright.async_api import async_playwright
asyncdefrun(playwright):# 创建一个浏览器实例
chromium = playwright.chromium
browser =await chromium.launch()# 创建两个浏览器上下文
user_context =await browser.new_context()
admin_context =await browser.new_context()# 创建各种页面和上下文的交互asyncdefmain():asyncwith async_playwright()as playwright:await run(playwright)
asyncio.run(main())
个人理解 😳
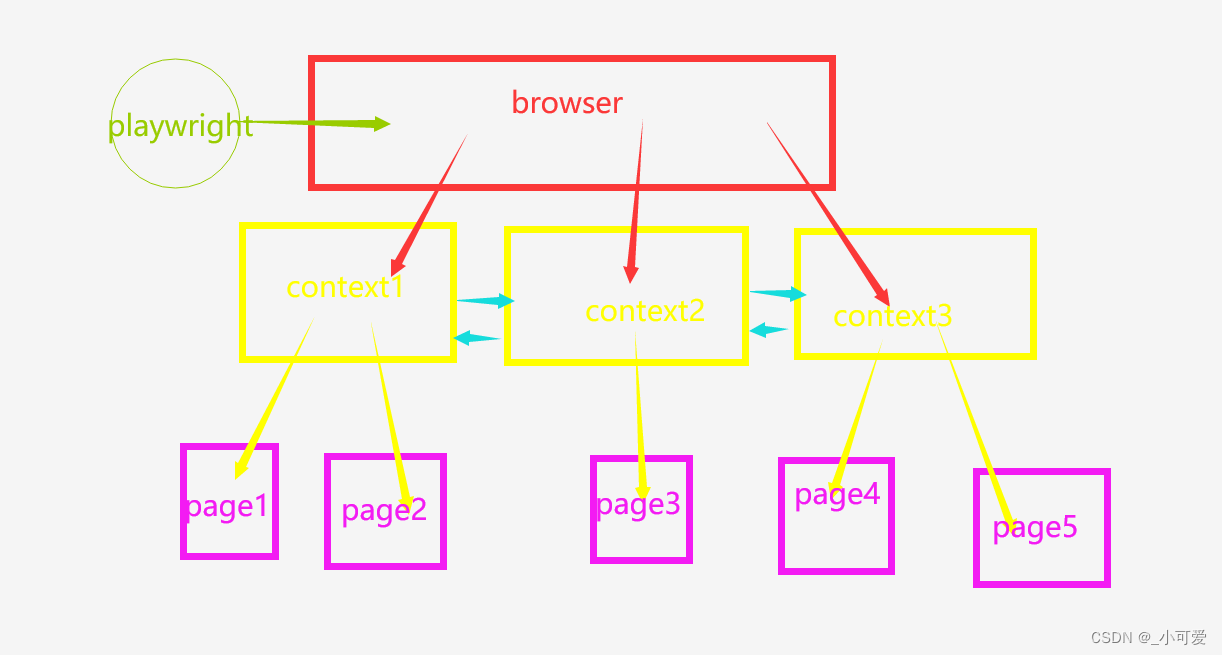
Page对象
一般来说,一个page对应一个浏览器选项卡。而Page对象的作用在于和页面的内容进行交互,以及导航和加载新的页面。
创建对象
page = context.new_page()
管理多页面
page_one = context.new_page()
page_two = context.new_page()
all_pages = context.pages # 获得该上下文的所有的page对象
打开新的选项卡
# 可以预期的with context.expect_page()as new_page_info:
page.locator('a[target="_blank"]').click()# 打开新的选项卡
new_page = new_page_info.value
new_page.wait_for_load_state()print(new_page.title())# 不可以预期的defhandle_page(page):
page.wait_for_load_state()print(page.title())
context.on('page', handle_page)
处理弹窗信息
# 可以预期的with page.expect_popup()as popup_info:
page.locator("#open").click()
popup = popup_info.value
popup.wait_for_load_state()print(popup.title())# 不可以预期的defhandle_popup(popup):
popup.wait_for_load_state()print(popup.title())
page.on('popup', handle_popup)
终端命令使用
1.安装浏览器
playwright install # 安装playwright支持的默认的浏览器驱动
playwright install webkit # 安装webkit
playwright install --help# 查看命令帮助
2.安装系统依赖
playwright install-deps # 安装playwright支持的浏览器的所有依赖
playwright install-deps chromium # 单独安装chromium驱动的依赖
3.代码生成 😃
测试网站:wikipedia.org
playwright codegen wikipedia.org
4.保存认证状态(将会保存所有的cookie和本地存储到文件)
playwright codegen --save-storage=auth.json # 存储到本地
playwright open--load-storage=auth.json my.web.app # 打开存储
playwright codegen --load-storage=auth.json my.web.app # 使用存储运行生成代码(保持认证状态)
5.打开网页,playwright内置了一个跨平台的浏览器webkit内核。
playwright open www.baidu.com # 使用默认的chromium打开百度
playwright wk www.baidu.com # 使用webkit打开百度
6.模拟设备打开(挺有趣的😲)
# iPhone 11.
playwright open--device="iPhone 11" www.baidu.com
# 屏幕大小和颜色主题
playwright open--viewport-size=800,600--color-scheme=dark www.baidu.com
# 模拟地理位置、语言和时区
playwright open--timezone="Europe/Rome"--geolocation="41.890221,12.492348"--lang="it-IT" maps.google.com
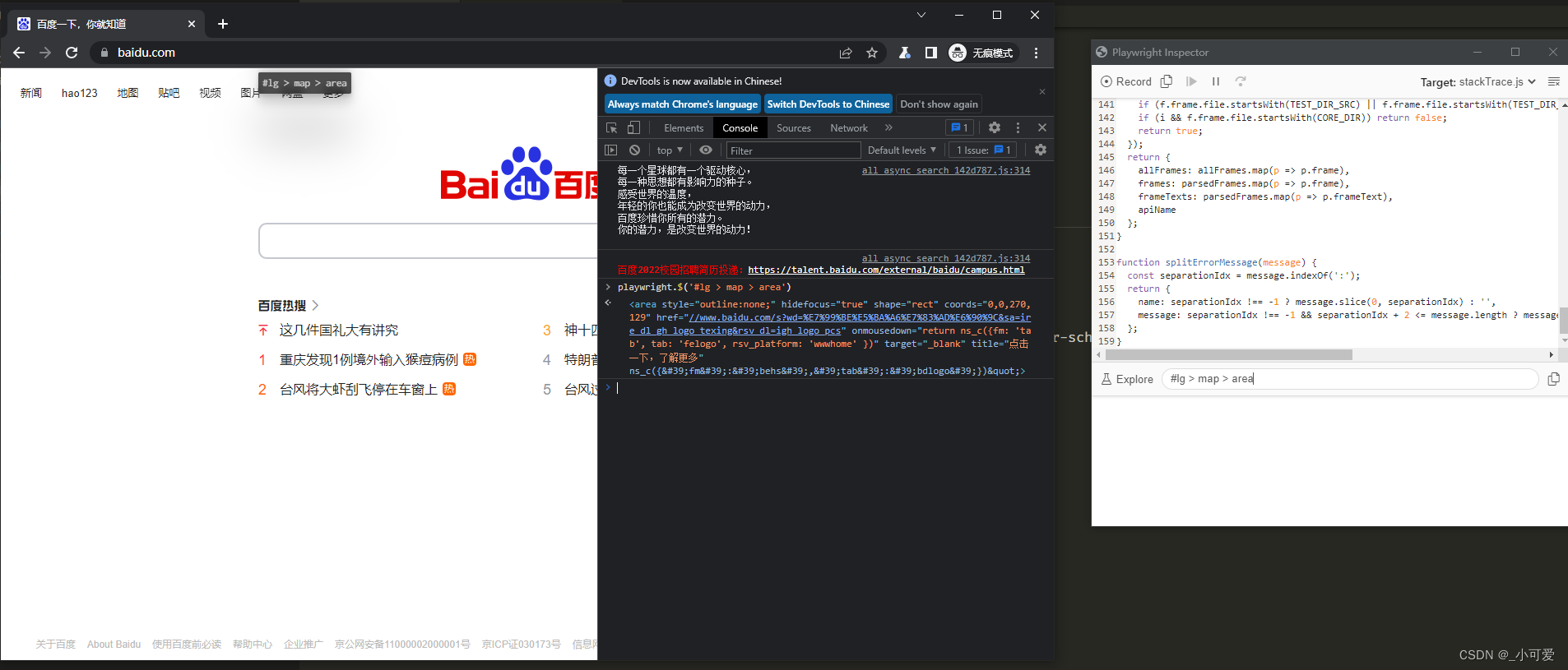
7.Inspect selectors,在浏览器调试工具使用命令。下面是一些例子。
playwright.$(selector)# 定位到匹配的第一个元素
playwright.$$(selector)# 定位到所有匹配的元素
playwright.selector(element)# 给指定的元素生成selector
playwright.inspect(selector)# 在 Elements 面板中显示元素(如果相应浏览器的 DevTools 支持它
playwright.locator(selector)# 使用playwright内置的查询引擎来查询匹配的节点
playwright.highlight(selector)# 高亮显示第一个匹配的元素
playwright.clear()#取消现存的所有的高亮
8.截图
playwright screenshot --help# 查看帮助# 模拟iPhone截图,等待3秒后截图,保存为twitter-iphone.png
playwright screenshot \
--device="iPhone 11" \
--color-scheme=dark \
--wait-for-timeout=3000 \
twitter.com twitter-iphone.png
# 全屏截图
playwright screenshot --full-page www.baidu.com baidu-full.png
使用代码截图
# 全屏截图
page.screenshot(path="screenshot.png", full_page=True)# 对元素截图
page.locator(".header").screenshot(path="screenshot.png")
9.生成PDF(只有在无头模式下才能运行)
# 生成PDF
playwright pdf https://en.wikipedia.org/wiki/PDF wiki.pdf
调试
1.无头和有头模式(默认为无头模式)
headless是否无头,slow_mo放慢执行速度,从而可以容易跟踪操作。
chromium.launch(headless=False, slow_mo=100)# or firefox, webkit 同步await chromium.launch(headless=False, slow_mo=100)# or firefox, webkit 异步
2.打开开发工具
chromium.launch(devtools=True)# 同步await chromium.launch(devtools=True)# 异步
下载文件
同步模式
# 开始下载with page.expect_download()as download_info:# 点击下载的按钮
page.locator("button#delayed-download").click()
download = download_info.value
# 等待下载print(download.path())# 保存文件
download.save_as("/path/to/save/download/at.txt")
异步模式
# 开始下载asyncwith page.expect_download()as download_info:await page.locator("button#delayed-download").click()
download =await download_info.value
# 等待下载print(await download.path())# 保存文件
download.save_as("/path/to/save/download/at.txt")
如果不知道会存在什么下载事件,那么就可以添加一个事件监听器:
page.on("download",lambda download:print(download.path()))# 同步# 异步asyncdefhandle_download(download):print(await download.path())
page.on("download", handle_download)
Handles(句柄)
Playwright 可以为页面 DOM 元素或页面内的任何其他对象创建句柄。 这些句柄存在于 Playwright 进程中,而实际对象存在于浏览器中。 有两种类型的手柄。
- JSHandle:该浏览页中,任意的javascript对象的引用。
- ElementHandle: 该浏览页中,任意DOM元素的引用。
实际上所有的DOM元素也是javascript对象,所有ElementHandle也是JSHandle。
# 获取JSHandle
js_handle = page.evaluate_handle('window')# 获取ElementHandle
element_handle = page.wait_for_selector('#box')# 可以使用assert方法来检测元素的属性
bounding_box = element_handle.bounding_box
assert bounding_box.width ==100
定位器(locator)
playwright的核心功能之一,简单来说,就是一种可以随时在页面上查找元素的方法。
创建定位器: 使用 page.locator(selector, **kwargs)
locator = page.locator("text=Submit")
locator.click()#点击操作
注意:定位器的一个操作严格匹配唯一的元素,否则将引发异常。 👇
page.locator('button').click()# 如果有多个按钮将发生异常# 正确的做法,应该指定位置或者使用定位器的过滤器
locator.first, locator.last, locator.nth(index)
定位器过滤器
# 包含sign up文本的按钮
page.locator("button", has_text ="sign up")# 包含另外一个locator的过滤器,内部的locator是从外部的locator开始的
page.locator('article', has=page.locator('button.subscribe'))# 使用locator.filter(**kwargs)方法
row_locator = page.locator('tr')
row_locator
.filter(has_text="text in column 1").filter(has=page.locator('tr', has_text='column 2 button')).screenshot()
locator和elementHandle的区别
- locator保存的是元素捕获的逻辑。
- elementHandle指向特定的元素。
举个例子,如果一个elementHandle所指向的元素的文本或者属性发生改变,那么elementHandle仍然指向原来那个没有改变的元素,而locator每一个都会根据捕获的逻辑去获取最新的那个元素,也就是改变后的元素。
文本输入
简单使用 fill 函数就好了。
# 文本框输入
page.locator('#name').fill('Peter')# 日期输入
page.locator('#date').fill('2020-02-02')# 时间输入
page.locator('#time').fill('13:15')# 本地时间输入
page.locator('#local').fill('2020-03-02T05:15')# 标签定位输入
page.locator('text=First Name').fill('Peter')
模拟
1.模拟设备
Playwright 带有用于选定移动设备的设备参数注册表,可用于模拟移动设备上的浏览器行为。
同步模式
from playwright.sync_api import sync_playwright
defrun(playwright):
pixel_2 = playwright.devices['Pixel 2']# Pixel 2 是谷歌的一款安卓手机
browser = playwright.webkit.launch(headless=False)# 使用设备Pixel 2的参数注册表来构建上下文
context = browser.new_context(**pixel_2,)with sync_playwright()as playwright:
run(playwright)
异步模式
import asyncio
from playwright.async_api import async_playwright
asyncdefrun(playwright):
pixel_2 = playwright.devices['Pixel 2']
browser =await playwright.webkit.launch(headless=False)
context =await browser.new_context(**pixel_2,)asyncdefmain():asyncwith async_playwright()as playwright:await run(playwright)
asyncio.run(main())
2.模拟UA
# 同步
context = browser.new_context(
user_agent='My user agent')# 异步
context =await browser.new_context(
user_agent='My user agent')
3.调整窗口大小
# 创建上下文
context = browser.new_context(
viewport={'width':1280,'height':1024})# 调整page的视图大小await page.set_viewport_size({"width":1600,"height":1200})
4.调整地理时间,颜色主题
context = browser.new_context(
locale='de-DE',
timezone_id='Europe/Berlin',
color_scheme='dark')
执行JavaScript 👏
page.evaluate(expression,**kwargs)# expression: javascript脚本# kwargs: 参数(可序列化对象,JSHandle实例,ElementHandle实例)
不带参数
href = page.evaluate('() => document.location.href')# 同步
href =await page.evaluate('() => document.location.href')# 异步
带参数
# 一个值
page.evaluate('num => num',32)# 一个数组
page.evaluate('array => array.length',[1,2,3])# 一个对象
page.evaluate('object => object.foo',{'foo':'bar'})# jsHandler
button = page.evaluate('window.button')
page.evaluate('button => button.textContent', button)# 使用elementhandler.evaluate的方法替代上面的写法
button.evaluate('(button, from) => button.textContent.substring(from)',5)# 对象与多个jshandler结合
button1 = page.evaluate('window.button1')
button2 = page.evaluate('.button2')
page.evaluate("""o => o.button1.textContent + o.button2.textContent""",{'button1': button1,'button2': button2 })# 使用析构的对象,注意属性和变量名字必须匹配。
page.evaluate("""
({ button1, button2 }) => button1.textContent + button2.textContent""",{'button1': button1,'button2': button2 })# 数组析构也可以使用,注意使用的括号
page.evaluate("""
([b1, b2]) => b1.textContent + b2.textContent""",[button1, button2])# 可序列化对象的混合使用
page.evaluate("""
x => x.button1.textContent + x.list[0].textContent + String(x.foo)""",{'button1': button1,'list':[button2],'foo':None})
事件
playwright允许监听各种类型的事件,一般来说大部分时间都在等待。
可以预期的事件
# 监听请求with page.expect_request('**/*login*.png')as first:
page.goto('http://www.baidu.com')print(first.value.url)# 异步模式asyncwith page.expect_request('**/*login*.png')as first:await page.goto('http://www.baidu.com')
first_request =await first.value
print(first_request.url)# 监听弹窗with page.expect_popup()as popup:
page.evaluate('window.open()')
popup.value.goto('http://www.baidu.com')# 异步模式asyncwith page.expect_popup()as popup:await page.evaluate('window.open()')
child_page =await popup.value
await child_page.goto('http://www.baidu.com')
但是大部分情况下时间的发生不可预期,所以需要添加事件监听处理(和异常捕获一样)
defprint_request_sent(request):print("request sent: "+ request.url)defprint_request_finished(request):print("request finished:"+ request.url)
page.on("request", print_request_sent)# 添加事件监听
page.on("requestfinished", print_request_finished)
page.goto('http://www.baidu.com')
page.remove_listener("request", print_request_sent)# 移除事件监听
page.goto('http://wikipedia.org')
一次性监听器
page.once('dialog',lambda dialog: dialog.accept('2022'))
page.evaluate('prompt("Enter a number: ")')
扩展
默认情况下,引擎直接在框架的 JavaScript 上下文中运行,例如,可以调用应用程序定义的函数。 要将引擎与框架中的任何 JavaScript 隔离,但保留对 DOM 的访问权限,请使用 {contentScript: true} 选项注册引擎。 内容脚本引擎更安全,因为它可以防止任何对全局对象的篡改,例如更改 Node.prototype 方法。所有内置的选择器引擎都作为内容脚本运行。 请注意,当引擎与其他自定义引擎一起使用时,不能保证作为内容脚本运行。
注册选择器引擎的示例,该引擎根据标签名称查询元素:
tag_selector ="""
{
// 找到第一个匹配的元素
query(root, selector) {
return root.querySelector(selector);
},
// 找到所有的匹配元素
queryAll(root, selector) {
return Array.from(root.querySelectorAll(selector));
}
}"""# 注册引擎
playwright.selectors.register("tag", tag_selector)# 使用自定义的selector
button = page.locator("tag=button")
button.click()# 与 “>>” 结合使用
page.locator("tag=div >> span >> \"click me\"").click()# 在所有支持selector的情况下使用
button_count = page.locator("tag=button").count()
框架
通常来说很多网页有多个框架,html表现为使用<iframe>标签。如果要定位到子框架里面的元素则必须先要指定frame的selector。 😑 😑 😑
# 填充子框架里面的用户名# 同步模式
username = page.from_locator('.frame-class').locator('#username-input')
username.fill('Mike')# 异步模式
username =await page.from_locator('.frame-class').locator('#username-input')await username.fill('Mike')
或者可以直接使用frame对象来完成交互。
# 从名字属性获取frame对象
frame = page.frame('frame-login')# 从url获取frame对象
frame = page.frame(url=r'.*domain.*')# 使用frame对象await frame.fill('#username-input','John')
playwright导航周期
Playwright 将在页面中显示新文档的过程分为导航和加载。导航从更改页面 URL 或与页面交互(例如,单击链接)开始。 导航意图可能会被取消,例如,在点击未解析的 DNS 地址或转换为文件下载时。当响应头被解析并且会话历史被更新时,导航被提交。 只有在导航成功(提交)后,页面才开始加载文档。加载包括通过网络获取剩余的响应体、解析、执行脚本和触发加载事件:
- page.url设置新的url
- 文档的内容通过网络传输加载进入本地,并且被解析为头部,响应体等。
- page.on(“domcontentloaded”) 事件被触发。
- page对象开始执行一些脚本,从本地资源加载静态的资源(样式表,图片等等)
- page.on(“load”) 事件被触发。
- page对象执行动态加载的脚本。
- 当 500 毫秒内没有新的网络请求时触发 networkidle。
等待
默认情况下,playwright会自动等待直到触发load事件。
# 同步模式
page.goto("http://www.baidu.com")# 异步模式await page.goto("http://www.baidu.com")
可以重载等待的事件,比如等待直到触发networkidle
page.goto("http://www.baidu.com", wait_until="networkidle")
也可以为特定的元素添加等待
page.goto("http://www.baidu.com")
page.locator("title").wait_for()# 等待直到title元素被加载完全# 会自动等待按钮加载好再执行点击
page.locator("button", has_text="sign up").click()
一些有用的API(用来模拟导航栏的功能 😃):
page.goto(url,**kwargs)# 定向
page.reload(**kwargs)# 刷新
page.go_back(**kwargs)# 后退
page.go_forward(**kwargs)# 前进
网络
1.HTTP认证
context = browser.new_context(
http_credenttials={"username":"Mike","password":"123456"})
page = context.new_page()
2.HTTP代理
全局代理设置
# 指定代理服务器,和代理所使用的用户和密码
browser = chromium.launch("server":"http://myproxy.com:port","username":"Mike","password":"123456")
局部代理,为每一个上下文都创建一个代理
browser = chromium.launch(proxy={"server":"per-context"})
context = browser.new_context(proxy={"server":"http://myproxy.com:port"})
3.监听所有的请求和响应
from playwright.sync_api import sync_playwright
defrun(playwright):
chromium = playwright.chromium
browser = chromium.launch()
page = browser.new_page()# 监听请求和响应事件
page.on("request",lambda request:print(">>", request.method, request.url))
page.on("response",lambda response:print("<<", response.status, response.url))
page.goto("https://example.com")
browser.close()with sync_playwright()as playwright:
run(playwright)
选择器(selector)
1.文本选择器
基本使用
page.locator('text=Log in').click()# 匹配(包含Log in)
page.locator("text='Log in'").click()# 匹配(等于Log in)
正则表达式(支持JavaScript风格的正则表达式,👉 参考手册)
page.locator("text=/Log\s*in/i").click()# 下面的都可以匹配'''
<button>Login</button>
<button>Log IN</button>
'''
has-text()伪类选择器和text伪类选择器
- has-text():检测包含(返回找到的所有元素)
- text():检测等于(返回第一个找到的元素)
- 使用在一个特定的css选择器里面。
# Wrong, will match many elements including <body>
page.locator(':has-text("Playwright")').click()# Correct, only matches the <article> element
page.locator('article:has-text("All products")').click()# Find the minimum element contain the text of Home
page.locator("#nav-bar :text('Home')").click()
2.CSS选择器
page.locator('button').click()
page.locator('#nav-bar .contact-us-item').click()
page.locator('[data-test=login-button]').click()
page.locator("[aria-label='Sign in']").click()
3.CSS+Text
page.locator("article:has-text('Playwright')").click()
page.locator("#nav-bar :text('Contact us')").click()
4.CSS+CSS
page.locator(".item-description:has(.item-promo-banner)").click()
5.xpath选择器
page.locator("xpath=//button").click()
6.nth选择
# Click first button
page.locator("button >> nth=0").click()# Click last button
page.locator("button >> nth=-1").click()
最佳实践
- 优先考虑面向用户的属性(因为这些元素很少变化,维护方便)- 文本输入- 用户名和密码输入- 用户角色标签- etc
- 避免使用很长的xpath或者css选择路径,会导致选择器过分依赖于DOM结构。
版权归原作者 _小可爱 所有, 如有侵权,请联系我们删除。