
一.介绍Hadoop生态圈相关组件
Hadoop生态圈是围绕Hadoop构建的一系列开源软件组件和工具,用于处理大数据的存储、处理、管理和分析。以下是Hadoop生态圈中一些常见的组件:
1. HDFS(Hadoop分布式文件系统):用于存储大规模数据的分布式文件系统,提供高容错性和高可靠性。
2. MapReduce:Hadoop的计算框架,用于并行处理大规模数据集。

3. YARN(Yet Another Resource Negotiator):Hadoop的集群资源管理器,用于管理和调度集群上的资源。
4. Hive:基于Hadoop的数据仓库基础设施,提供类SQL查询语言(HiveQL)来进行数据分析和查询。
5. Pig:用于大规模数据分析的高级编程语言和平台,可以将复杂的数据处理流程转化为简单的脚本。
6. HBase:分布式、可扩展的列式数据库,适用于大规模结构化数据的实时读写操作。
7. ZooKeeper:用于分布式应用程序的协调服务,提供配置管理、命名服务、分布式同步和组服务等功能。
8. Spark:高速大数据处理框架,支持内存计算和更广泛的数据处理模型,比传统的MapReduce更快速。
9. Kafka:高吞吐量的分布式消息系统,用于发布和订阅流数据。
10. Flume:用于可靠地收集、聚合和移动大规模日志和事件数据的分布式系统。
11. Storm:用于处理实时流数据的分布式计算系统,提供容错性和可扩展性。
12. Sqoop:用于在Hadoop和关系型数据库之间进行数据传输的工具。
13. Oozie:用于协调和管理Hadoop作业流程的工作流调度系统。

14. Mahout:用于实现大规模机器学习和数据挖掘的库。
15. Zeppelin:交互式数据分析和可视化的Web界面,支持多种数据处理引擎。
二.详细介绍MapReduce的特点及运行架构
MapReduce是一个分布式运算程序的编程框架,主要用于开发基于Hadoop的数据分析应用。它的核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并能在Hadoop集群上并行运行。MapReduce的设计初衷是使程序能够部署在廉价的PC机器上,因此它具有很高的容错性,即使其中一台机器挂掉,也能将计算任务转移到其他节点上执行,无需人工干预。
MapReduce的特点包括:
1.易于编程:用户可以通过实现简单的接口来完成一个分布式程序,这个程序可以分布到大量廉价的PC机器上运行。
2.良好的扩展性:当计算资源不能满足需求时,可以通过添加机器来扩展计算能力。
3.高容错性:设计上要求程序能够在廉价PC机器上运行,并具有很高的容错能力,能够自动处理节点故障。
4.适合PB级以上海量数据的离线处理:能够实现上千台服务器集群并发工作,提供强大的数据处理能力。
然而,MapReduce也有其局限性:
不擅长实时计算:无法像MySQL那样在毫秒或秒级内返回结果。
不擅长流式计算:输入数据必须是静态的,而流式计算的输入数据是动态的。
不擅长DAG(有向无环图)计算:在多个应用程序存在依赖关系的情况下,MapReduce的性能可能会因为每个作业的输出结果写入磁盘而降低。
MapReduce的运行架构采用Master/Slave架构,其中Master负责整个作业的调度和管理,而Slave节点则执行实际的Map和Reduce任务。这种架构使得MapReduce能够高效地处理大规模数据集。
三.详细介绍spark的特点,并与MapReduce作对比说明区别
1.spark的特点
(1)运行速度快,如果数据由磁盘读取,速度是hadoop mapreduce的10倍以上,如果数据从内存读取,速度是hadoop mapreduce的100倍以上。主要原因是因为基于内存计算和引入DAG执行引擎。
(2)易用性好,spark不仅支持scala编程呢个,还支持java和python编写。
(3)通用性好
(4)随处运行
2.spark和mapreduce的比较
(1)spark把中间数据放在内存中,迭代运算效率高。mapreduce中的计算结果保存在磁盘上,而spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
(2)spark容错性高。引进了RDD,如果数据集一部分丢失,则可以重建。另外,在RDD计算时可以通过checkpoint来实现容错。
(3)spark更加通用。不像hadoop只提供map和reduce两种操作。spark提供的数据集操作类型有很多种,大致分为转换操作和行动操作。转换操作包括
map,filter,flatmap,sample,groupbykey,reducebykey,union,join,cogroup,mapvalues,sort和partionby等多种操作类型,行动操作包括collect,reduce,lookup和save等操作类型。另外,各个处理节点之间的通信模型不再像Hadoop只有shuffle一种模式,用户可以命名,物化,控制中间结果的存储,分区等。
四.熟练掌握Linux操作命令并演示说明
一、基本操作命令
首先先来几个热键,非常方便,一定要记住
Tab按键—命令补齐功能
Ctrl+c按键—停掉正在运行的程序
Ctrl+d按键—相当于exit,退出
Ctrl+l按键—清屏
1.1 关机和重启
1.关机命令:shutdown
在linux领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊情况下,不得已才会关机。
正确的关机流程为:sync > shutdown > reboot > halt
例如你可以运行如下命令关机:
1 sync 将数据由内存同步到硬盘中。shutdown 关机指令
2 shutdown –h 20:25 系统会在今天20:25关机
3 shutdown –h +10 十分钟后关机
4 shutdown –r now 系统立马重启
5 shutdown –r +10 系统十分钟后重启
6 reboot 就是重启,等同于 shutdown –r now
7 halt 关闭系统,等同于shutdown –h now 和 poweroff
下面是一个简单的样例。

取消定时关机命令:shutdown -c
最后总结一下,不管是重启系统还是关闭系统,首先要运行 sync 命令,把内存中的数据写到磁盘中。
关机的命令有 shutdown –h now halt poweroff 和 init 0 , 重启系统的命令有 shutdown –r now reboot init 6。
2.重启命令:reboot

1.2 帮助命令
–-help命令
shutdown --help:ifconfig --help:查看网卡信息
二、目录操作命令
我们知道Linux的目录结构为树状结构,最顶级的目录为根目录 /。
其他目录通过挂载可以将它们添加到树中,通过解除挂载可以移除它们。
首先我们需要先知道什么是绝对路径与相对路径。
绝对路径:
路径的写法,由根目录 / 写起,例如:/usr/share/doc 这个目录。
相对路径:
路径的写法,不是由 / 写起,例如由/usr/share/doc 要到 /usr/share/man 底下时,可以写成:cd ../man 这就是相对路径的写法。
2.1 目录切换 cd
命令:cd 目录
cd是Change Directory的缩写,这是用来变换工作目录的命令。
1 cd / 切换到根目录
2 cd /usr 切换到根目录下的usr目录
3 cd ../ 切换到上一级目录 或者 cd ..
4 cd ~ 切换到home目录
5 cd - 切换到上次访问的目录
2.2 目录查看 ls [-al]
命令:ls [-al]
语法:
1 ls [-aAdfFhilnrRSt] 目录名称
2 ls [--color={never,auto,always}] 目录名称
3 ls [--full-time] 目录名称
ls 查看当前目录下的所有目录和文件
ls -a 查看当前目录下的所有目录和文件(包括隐藏的文件)
ls -l 或 ll 列表查看当前目录下的所有目录和文件(列表查看,显示更多信息)
ls /dir 查看指定目录下的所有目录和文件 如:ls /usr
将家目录下的所有文件列出来(含属性与隐藏档)
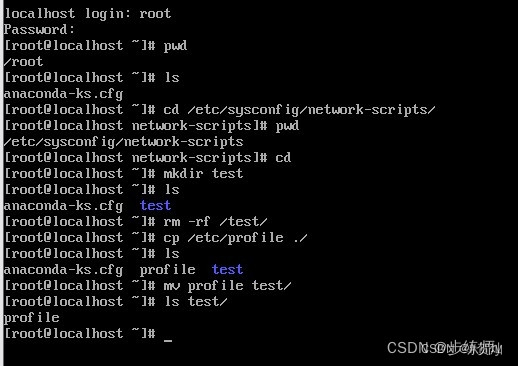

五、冷备、温备、热备
按备份系统的准备程度,可将其分为冷备份、温备份和热备份三大类 。
1、冷备份 : 备份系统未安装或未配置成与当前使用的系统相同或相似的运行环境,应用系统数据没有及时装入备份系统。一旦发生灾难,需安装配置所需的运行环境,用数据备份介质(磁带或光盘) 恢复应用数据,手工逐笔或自动批量追补孤立数据,将终端用户通过通讯线路切换到备份系统,恢复业务运行。
优点 : 设备投资较少,节省通信费用,通信环境要求不高
缺点 : 恢复时间较长,一般要数天至1周,数据完整性与一致性较差
2、温备份 : 将备份系统已安装配置成与当前使用的系统相同或相似的系统和网络运行环境,安装应用系统业务定期备份数据。一旦发生灾难,直接使用定期备份数据,手工逐笔或自动批量追补孤立数据或将终端用户通过通讯线路切换到备份系统,恢复业务运行。
优点 : 设备投资较少,通信环境要求不高
缺点 : 恢复时间长,一般要十几个小时至数天,数据完整性与一致性较差
3、热备份 : 备份处于联机状态,当前应用系统通过高速通信线路将数据实时传送到备份系统,保持备份系统与当前应用系统数据的同步;也可定时在备份系统上恢复应用系统的数据。一旦发生灾难,不用追补或只需追补很少的孤立数据,备份系统可快速接替生产系统运行,恢复营业。
优点 : 恢复时间短,一般几十分钟到数小时,数据完整性与一致性最好,数据丢失可能性最小
缺点 : 设备投资大,通信费用高,通信环境要求高,平时运行管理较复杂。
版权归原作者 #贺灿 所有, 如有侵权,请联系我们删除。