
目录
1 什么是nn.Module?
在实际应用过程中,经典网络结构(如卷积神经网络)往往不能满足我们的需求,因而大多数时候都需要自定义模型,比如:多输入多输出(MIMO)、多分支模型、跨层连接模型等。
nn.Module
就是
Pytorch
中用于自定义模型的核心方法。在
Pytorch
中,自定义层、自定义块、自定义模型,都是通过继承
nn.Module
类完成的。
nn.Module
的定义如下
classModule(object):def__init__(self):defforward(self,*input):def__call__(self,*input,**kwargs):defparameters(self, recurse=True):defnamed_parameters(self, prefix='', recurse=True):defchildren(self):defnamed_children(self):defmodules(self):defnamed_modules(self, memo=None, prefix=''):deftrain(self, mode=True):defeval(self):defzero_grad(self):...
注意:自定义网络需要继承
nn.Module
类,并重点实现上面的构造函数
__init__
构造函数和
forward()
这两个方法。
2 从一个例子说起
下面是一个自定义感知机的实例
# 感知机classPerception(nn.Module):def__init__(self, inDim, hidDim, outDim):super(Perception, self).__init__()
self.perception = nn.Sequential(
nn.Linear(inDim, hidDim),
nn.Sigmoid(),
nn.Linear(hidDim, outDim),
nn.Sigmoid())defforward(self, x):return self.perception(x)
测试模块
perception = Perception(5,20,10)print(perception(torch.Tensor([1,2,3,4,5])))# 自动调用forward()前向传播
其中
nn.Sequential()
可以序列化封装若干个相连的组件,在希望快速搭建模型且无需考虑中间过程的情形下,推荐使用
nn.Sequential()
进行局部模块化。
从上面的实例可以看出:
- 一般把网络中的特定结构(如全连接层、卷积层等)以序列的形式放在构造函数
__init__()中 - 将模型自定义的各个层的连接关系和数据通路设计放在
forward()函数中,以实现模型功能并保证数据结构正常 - 不具有可学习参数的层(如
ReLU、dropout、BatchNormanation层等)可并入__init__()内部的某个层,或在forward()函数中进行层间连接
库
nn.functional
同样提供了大量网络模块和组件,与
nn.Module
类不同在于其更偏向底层——
nn.Module
封装了对学习参数的维护,更注重模型结构;
nn.functional
需要手动指定参数和结构,例如下面线性模型
Linear
的核心源码,其前向过程仍然调用了底层的
nn.functional
实现。
classLinear(Module):def__init__(self, in_features:int, out_features:int)->None:super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
self.bias = Parameter(torch.Tensor(out_features))defforward(self,input: Tensor)-> Tensor:return F.linear(input, self.weight, self.bias)
一般在设计通过已有
nn.Module
无法组装的网络结构时,可以调用底层的
nn.functional
实现;或是存在无需优化学习参数的结构(如损失函数、激活函数等),可以调用
nn.functional
(即作为单纯函数使用)避免实例化
nn.Module
,轻量化网络
# 使用nn.Module需要实例化后调用
lossFunc = nn.CrossEntropyLoss()
loss = lossFunc(output, label)# 使用nn.functional则只作为函数即可
loss = F.cross_entropy(output, label)
3 nn.Module主要方法
nn.Module的主要属性与方法列举如表所示。
序号属性/方法含义1
forward()
模型前向传播2
train()
训练模式3
eval()
评估模式4
named_parameters()
返回模型各可学习参数的名称和参数组成的列表5
parameters()
返回模型各可学习参数组成的列表6
children()
返回一个迭代器,其中每个元素是
Sequential
序列类型,可以使用下标索引来进一步获取每一个
Sequenrial
里面的具体层,比如
conv
层、
dense
层等7
named_children()
返回一个迭代器,其中每个元素是一个二元组,第一元是名称,第二元是该名称对应的层或
Sequential
序列
4 自定义网络一般步骤
自定义网络一般步骤总结如下:
- 自定义一个继承自Module的类
- 实现构造函数
_init__,在其中参数化网络层,比如卷积神经网络的卷积核大小、池化层尺寸,全连接网络的输入输出大小等; - 实现前向传播
forward()接口,定义网络的连接情况或其他运算方式(如向量拼接、向量变维、数据处理等)
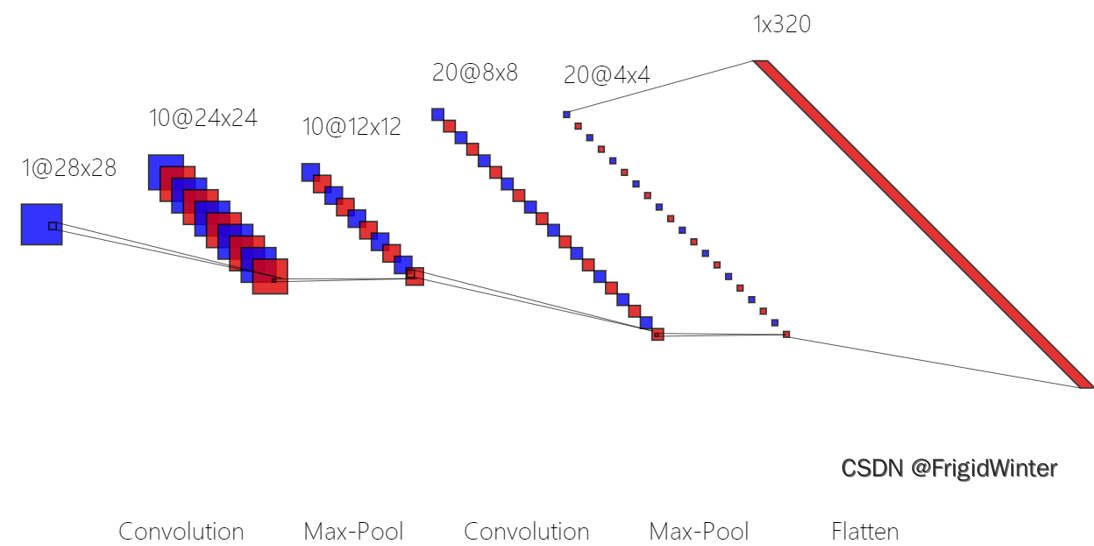
下面再给出一个卷积神经网络的实例加深理解
classCNN(nn.Module):def__init__(self):super().__init__()
self.convPoolLayer_1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU())
self.convPoolLayer_2 = nn.Sequential(
nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.ReLU())
self.fcLayer = nn.Linear(320,10)def__str__(self)->str:return"cnn_model"defforward(self, x):
batchSize = x.size(0)
x = self.convPoolLayer_1(x)
x = self.convPoolLayer_2(x)
x = x.reshape(batchSize,-1)
x = self.fcLayer(x)return x
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《Pytorch深度学习实战》
- 《机器学习强基计划》
- 《运动规划实战精讲》
- …
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇
本文转载自: https://blog.csdn.net/FRIGIDWINTER/article/details/129352729
版权归原作者 Mr.Winter` 所有, 如有侵权,请联系我们删除。
版权归原作者 Mr.Winter` 所有, 如有侵权,请联系我们删除。